
Track
Developing Large Language Models
16 hr
Currently, Gemini 2.0 Pro can only be accessed through Google AI Studio, which requires signing in with a Google account. To get started, follow these steps:
Visit the Google AI Studio website and log in using your Google account credentials. Once logged in, you will be redirected to the Google AI Studio dashboard.
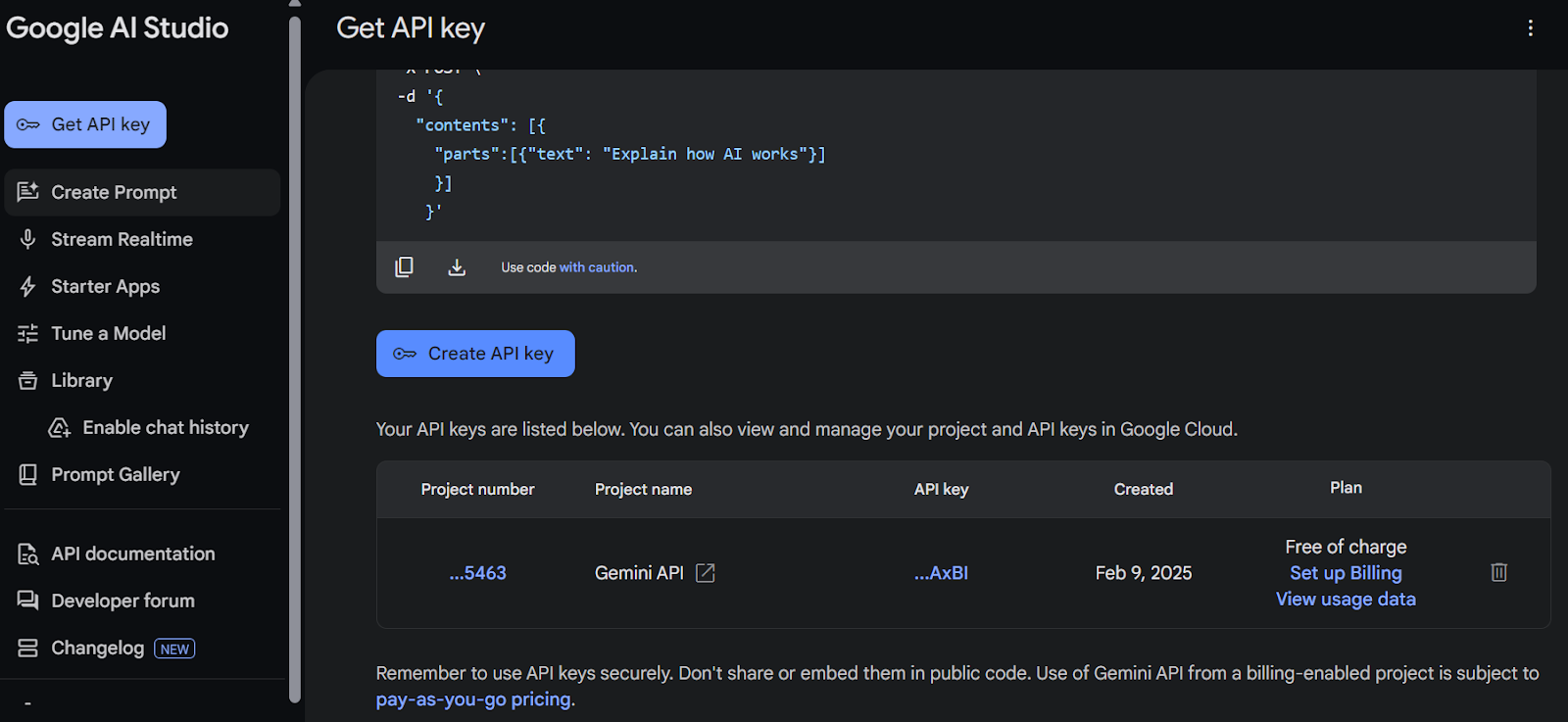
Source: Google AI Studio
Create an environment variable named GEMINI_API_KEY and assign it the value of the API key you just generated.
Install the necessary Python packages by running the following command in your terminal:
pip install google-genai
pip install gradioNow, we will use the Gemini Python client to access various features of the Gemini 2.0 Pro model. These features include text understanding, image processing, audio analysis, and document comprehension.
Additionally, we will test the code execution feature, which allows us to generate code and execute it directly within the cloud Python kernel.
We will load the API key from the environment variable and initialize the client using it. This client will serve as the interface to access various models and features.
Next, we will provide the model with a question and generate a streaming response. This means that as soon as tokens are generated, they will be displayed incrementally in the terminal, offering real-time feedback.
import os
from google import genai
API_KEY = os.environ.get("GEMINI_API_KEY")
client = genai.Client(api_key=API_KEY)
response = client.models.generate_content_stream(
model="gemini-2.0-pro-exp-02-05",
contents=["Explain how Stock Market works"])
for chunk in response:
print(chunk.text, end="")The model generated a detailed and accurate response.
The stock market is a complex system, but here's a breakdown of how it works in a simplified way, covering the key concepts:
**1. What are Stocks (Shares)?**
* **Ownership:** Stocks, also called shares or equities, represent ownership in a company. When you buy a stock, you're buying a tiny piece of that company.
* **Claim on Assets and Earnings:** As a shareholder, you have a claim on the company's assets and earnings. You're entitled to a portion of the company's profits (often distributed as dividends, though not always) and, in theory, a share of the company's value if it were to be liquidated.
* **Voting Rights (Sometimes):** Many stocks (but not all) come with voting rights, allowing you to have a say in certain company decisions (like electing the board of directors).
**2. Why Companies Issue Stock (Go Public)?**For image understanding, we will load the image using the Pillow library in Python and add it to the contents argument. The contents will include questions about the image along with the image object.
from google import genai
from google.genai import types
import PIL.Image
image = PIL.Image.open('image.png')
response = client.models.generate_content_stream(
model="gemini-2.0-pro-exp-02-05",
contents=["Explain the image", image])
for chunk in response:
print(chunk.text, end="")The model has accurately understood the image and provided us with even minor details.
The image is a stylized, abstract graphic. It looks like a simplified diagram or node network, with a black background.
Here's a breakdown:
* **Nodes:** There are four circular nodes. Each node is a different color:
* Light Blue (Top Left)
* Light Green (Bottom Left)
* White (Top Right)
* Red (Bottom Right)
* **Node outline:** There is a thick outline around each of the circles.
* **Shadow:** Each circle appears to be casting a white shadow.Gemini 2.0 Pro can understand audio directly without converting it to text. Just load the audio and provide it to the content argument along with the relevant question.
with open('audio.wav', 'rb') as f:
audio_bytes = f.read()
response = client.models.generate_content_stream(
model='gemini-2.0-pro-exp-02-05',
contents=[
'Describe this audio',
types.Part.from_bytes(
data=audio_bytes,
mime_type='audio/wav',
)
]
)
for chunk in response:
print(chunk.text, end="")Again, it provides a highly accurate description of the audio.
The audio appears to be a collection of short, spoken phrases or sentences. There is only one speaker, a male, and he seems to be reading or reciting these phrases, possibly as part of a list or exercise. The content focuses on food and related concepts like smell and temperature.Instead of using Langchain or any RAG frameworks, we can provide Gemini 2.0 Pro with documents, which it will parse and index, allowing us to start asking questions about them.
We have loaded a PDF file and asked questions based on its content. It's that simple.
from google import genai
from google.genai import types
import pathlib
prompt = "What the document is about"
response = client.models.generate_content_stream(
model="gemini-2.0-pro-exp-02-05",
contents=[
types.Part.from_bytes(
data=pathlib.Path('cv.pdf').read_bytes(),
mime_type='application/pdf',
),
prompt])
for chunk in response:
print(chunk.text, end="")As a result, it has described perfectly what this document is all about.
Based on the OCR output, the document is **Abid Ali Awan's Curriculum Vitae (CV) or resume**. It details his:
* **Contact Information:** Name, address, email, and phone number.
* **Work Experience:** A chronological list of his professional roles, including job titles, companies, locations, dates of employment, and brief descriptions of his responsibilities. This includes experience in data science, freelancing, research, media, and network engineering.
* **Education:** His academic background, listing degrees earned, institutions attended, graduation dates, GPAs, and areas of specialization.
* **Gap Year:** Explaining the time that have taken for medical/personal issues.
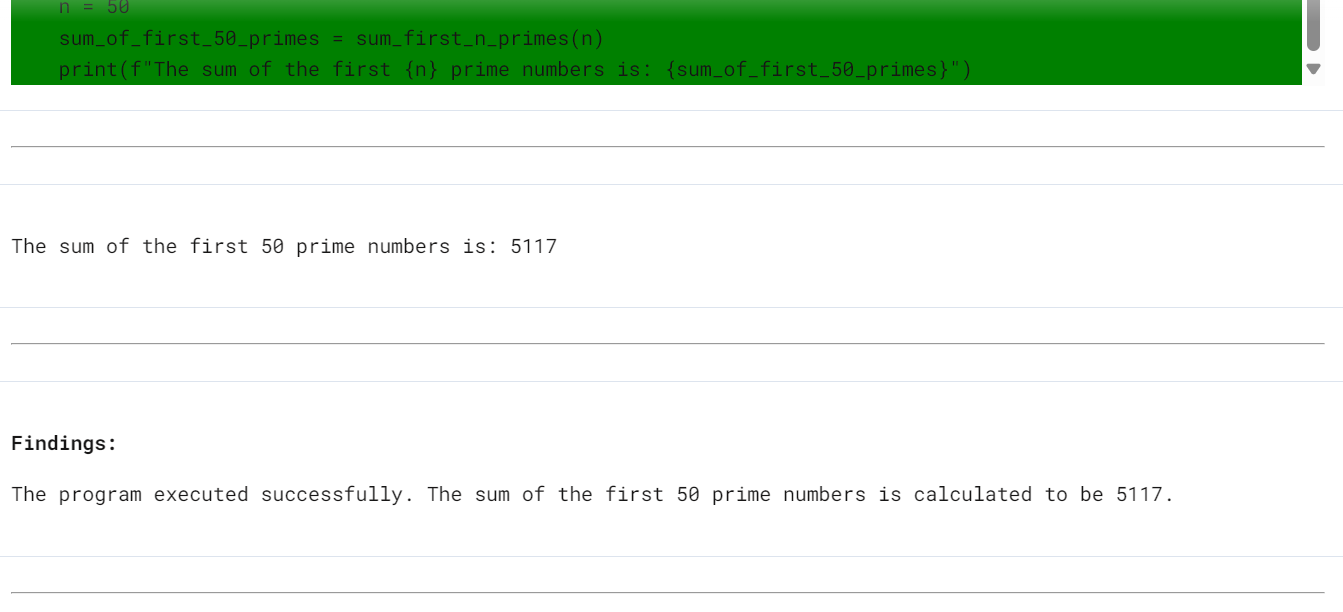
* **Professional Skills:** A list of his technical and soft skills, categorized and ratedThe most outstanding part of the Gemini API is that you can generate code and execute it using the same API. This means that your code will be generated and tested; if there is a bug, the model will fix the bug and rerun the code until the correct response is generated.
We have asked Gemini 2.0 Pro a coding question and requested that it execute the code at the end. If you look at the config argument, you will see that we have included the code execution tool for running the code in the cloud.
from google import genai
from google.genai import types
from IPython.display import Markdown, HTML, Image, display
response = client.models.generate_content(
model='gemini-2.0-pro-exp-02-05',
contents="""
Write a Python program to calculate the sum of the first 50 prime numbers. The program should:
- Use a function to check if a number is prime.
- Use another function to find and sum the first n prime numbers, where n is 50 in this case.
- Ensure the code is efficient and readable.
- Print the result clearly.
After writing the code, execute it to verify that the sum of the first 50 prime numbers is correct.
""",
config=types.GenerateContentConfig(
tools=[types.Tool(
code_execution=types.ToolCodeExecution
)]
)
)
def display_code_execution_result(response):
for part in response.candidates[0].content.parts:
if part.text is not None:
display(Markdown(part.text))
if part.executable_code is not None:
code_html = f'<pre style="background-color: green;">{part.executable_code.code}</pre>' # Change code color
display(HTML(code_html))
if part.code_execution_result is not None:
display(Markdown(part.code_execution_result.output))
if part.inline_data is not None:
display(Image(data=part.inline_data.data, format="png"))
display(Markdown("---"))
display_code_execution_result(response)The model has generated the code but failed to run it. Then, it fixed the issues and, ran the code again, and successfully displayed the results.
We will now build a Gradio web app that integrates all the features we have tested previously. This will allow anyone to test it by uploading files and asking questions about images, audio, documents, and even executing code.
The code for app.py is available in the GitHub repository Gemini-2-Pro-Chat. You can review it to understand how each feature has been implemented.
In short, the app contains:
generate_content_stream method from Google GenAI.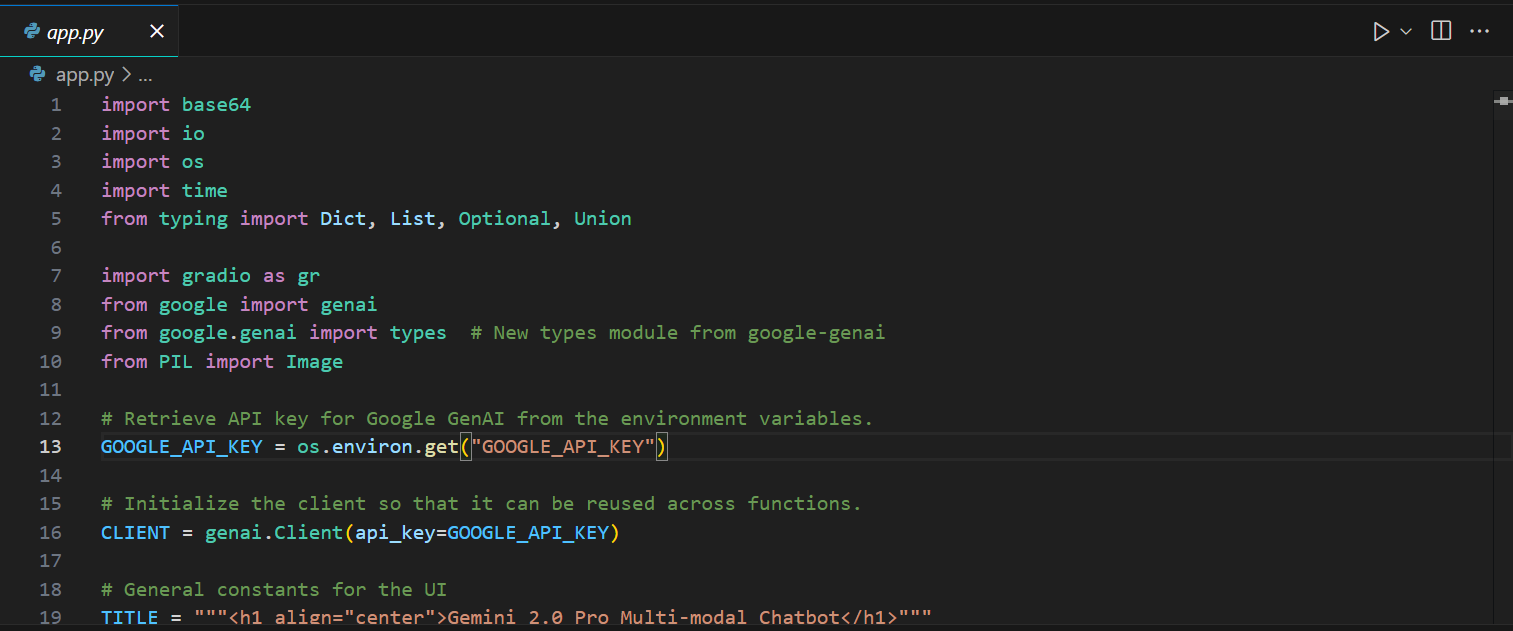
Once you have copied the code from the remote repository into your local project, you can run it locally.
python app.py
We will now test the web application to ensure that everything is functioning properly. We will go through all the features one by one using the web app user interface.
1. Type your question and press the [Enter] key. The response will start generating, and you will have your answer in just a few seconds.
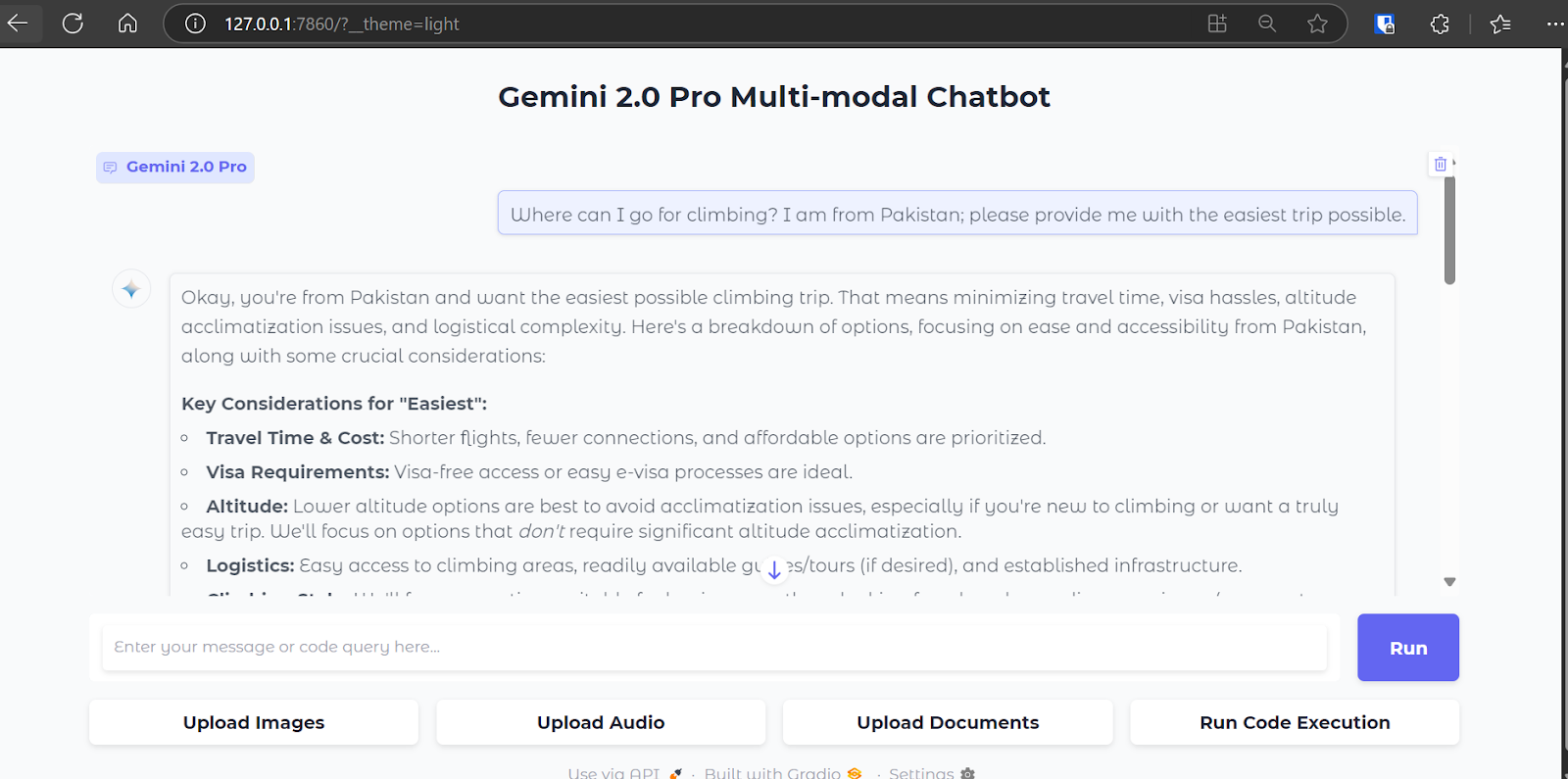
2. To upload an image, click on the “Upload Images” button and select the file from the directory. Then, ask a question about the image, and the Gemini 2.0 Pro will start generating an accurate and highly detailed response.
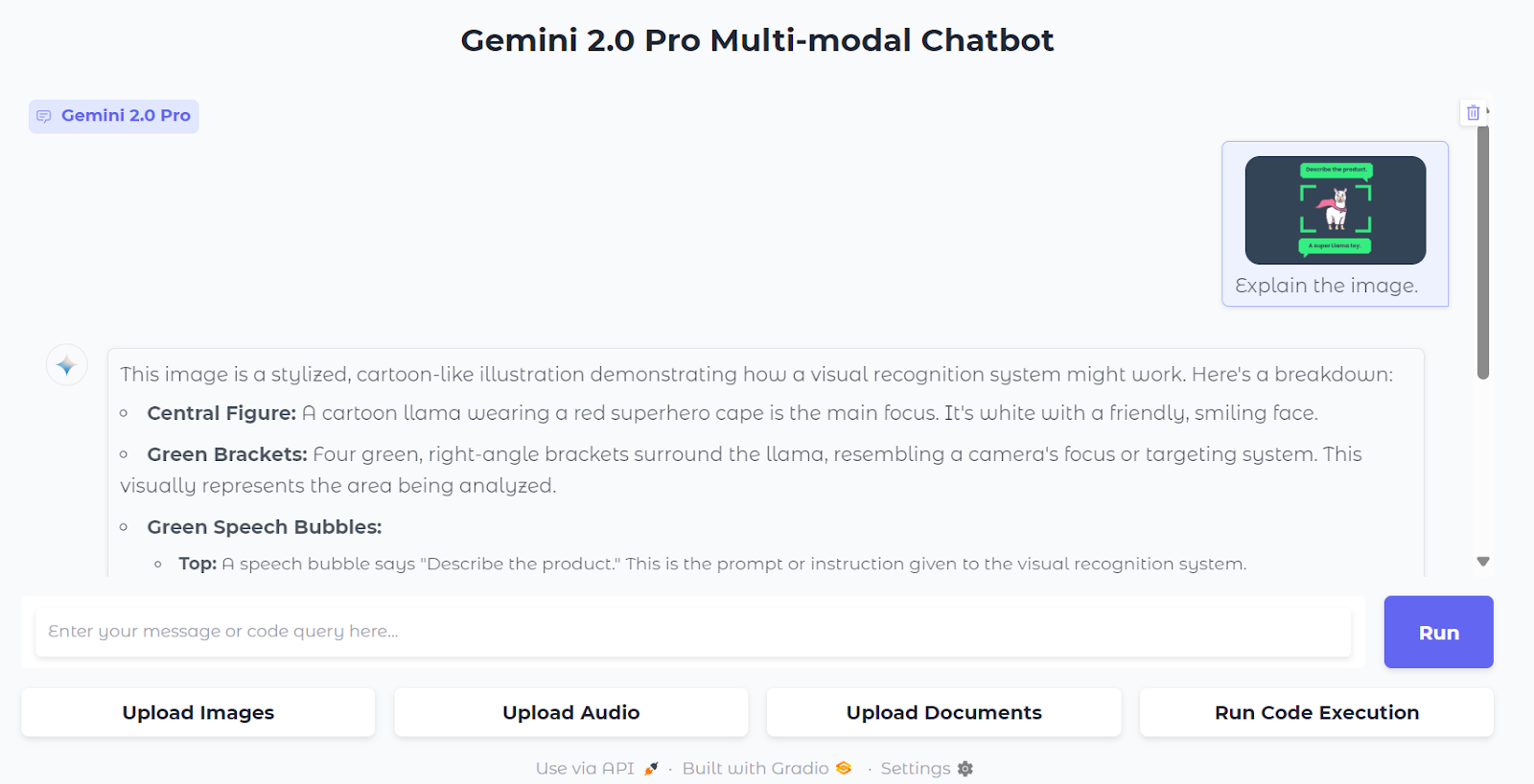
3. Upload audio by clicking on the “Upload Audio” button and selecting the audio file. After that, ask a question about the audio. The model will produce highly accurate responses.
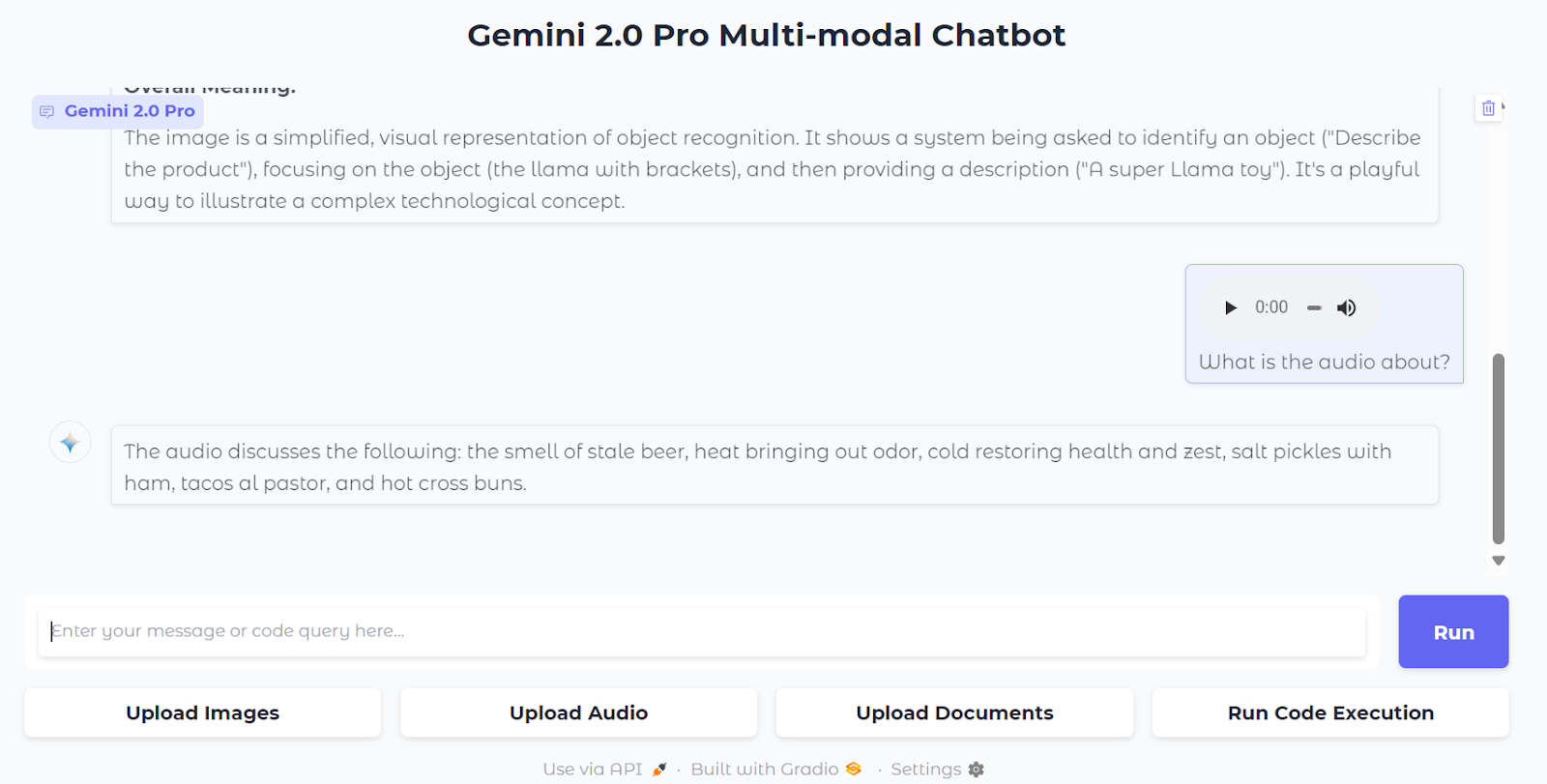
4. You can also upload documents. Load a PDF file by clicking on the “Upload Documents” button and selecting the file. Then, ask a question about the document.
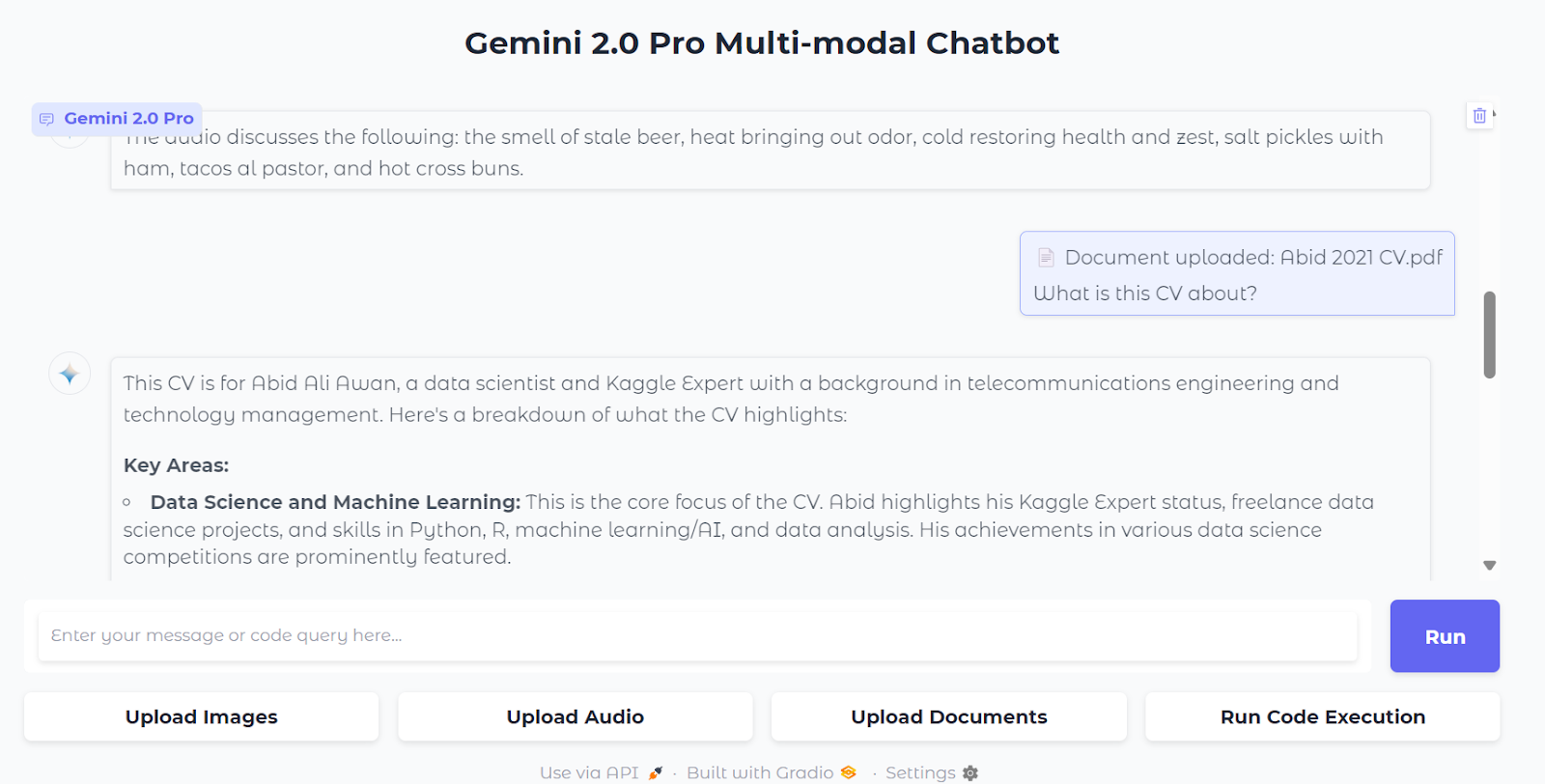
5. Code execution is a bit different. It does not have history to avoid conflicts, meaning you need to ask it to generate the code and execute it in the same prompt.
For example, we asked it to generate and execute sample Python code to create a random image in PNG format, and then we pressed the “Run Code Execution” button.
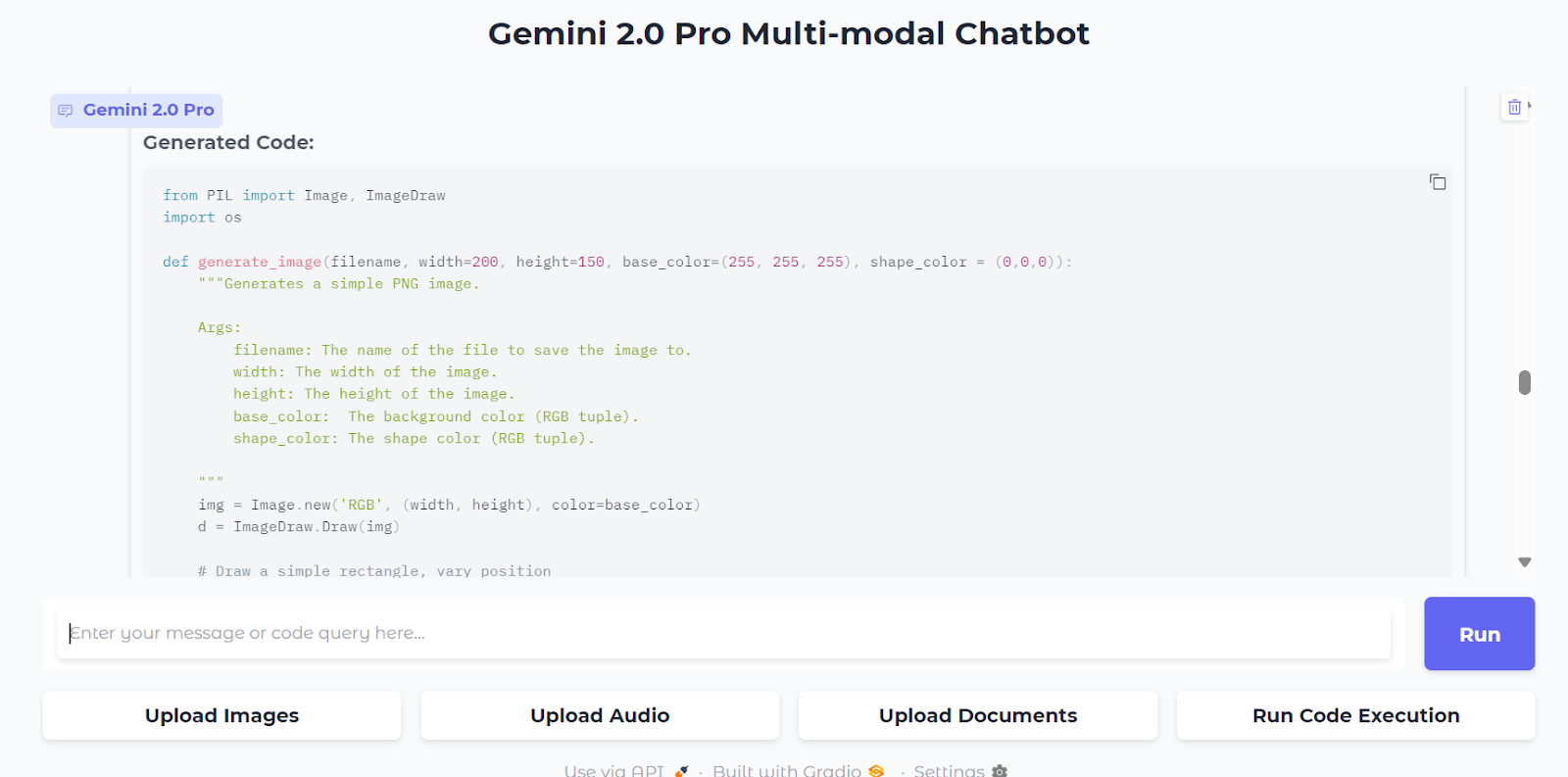
Within seconds, it has generated the code, ran it, and displayed the images in the chat box.
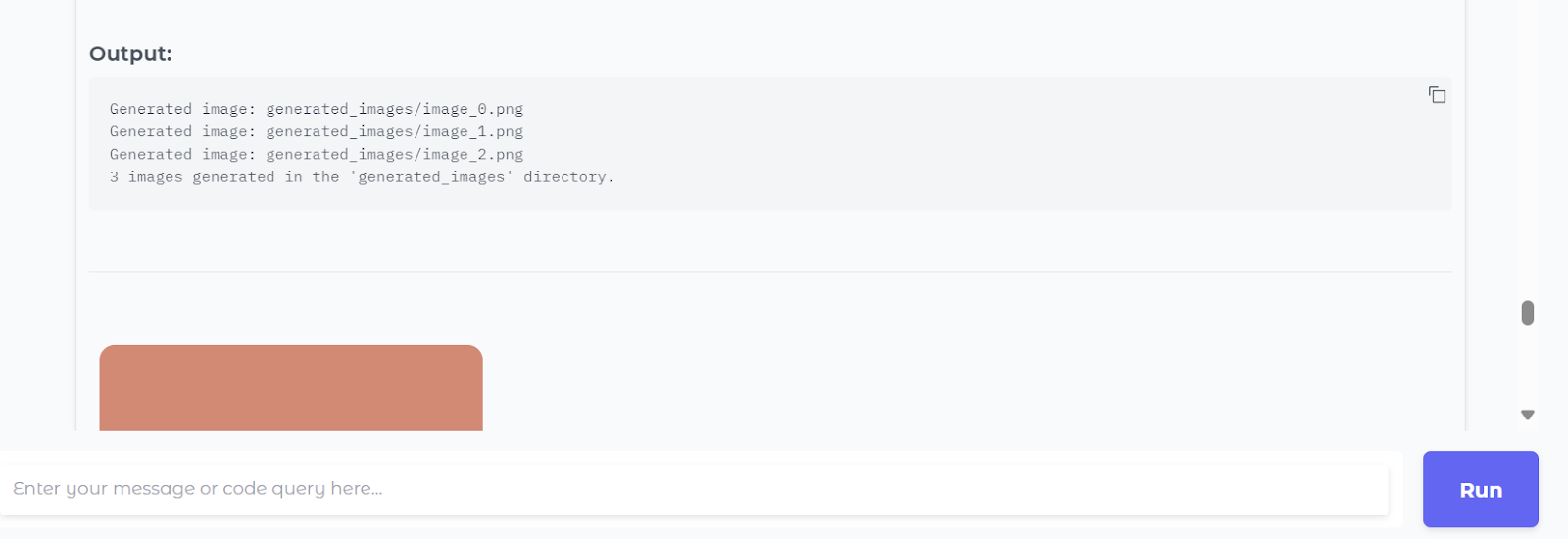
The code execution feature also provides a conclusion at the end.
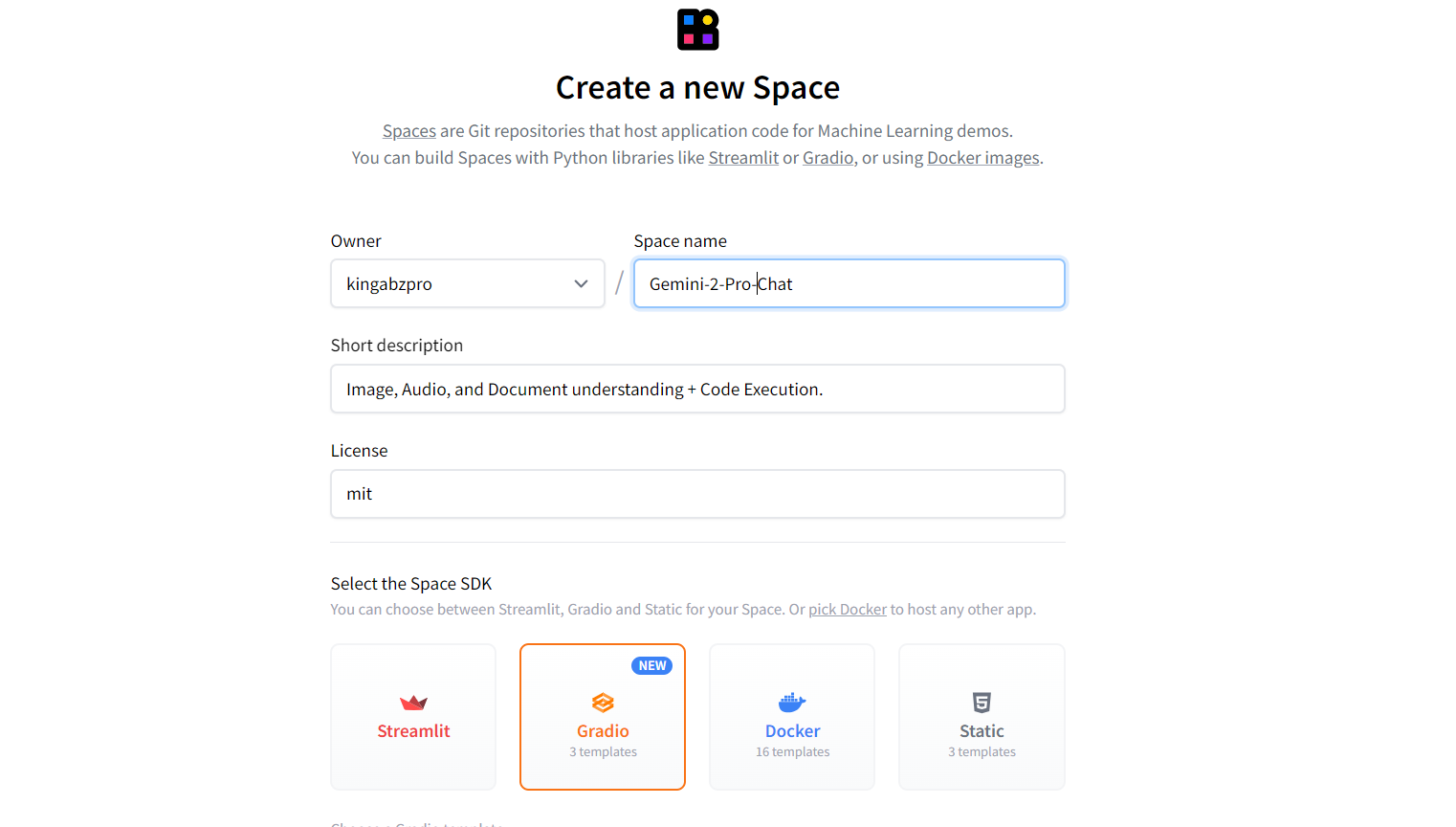
Let’s deploy our app to the cloud using Hugging Face Spaces. Go to Hugging Face Spaces and click on the “+ New Space” button. Enter the name, description, and license of the space, and also select the SDK as Gradio.
Source: Hugging Face
After creating the space, you will receive instructions on how to clone the repository:
git clone https://huggingface.co/spaces/kingabzpro/Gemini-2-Pro-Chat
cd Gemini-2-Pro-ChatWithin the local repository, create a requirements.txt file and add the following Python dependency:
google-genai==1.0.0Next, modify the README.md file to include the following content:
---
title: Gemini 2 Pro Chat
emoji: ♊💬
colorFrom: green
colorTo: pink
sdk: gradio
sdk_version: 5.15.0
app_file: app.py
pinned: false
license: mit
short_description: 'Image, Audio, and Document understanding + Code Execution. '
---Then, add the app.py file to the repository. Stage the changes, commit them, and push the updates to the remote repository:
git add .
git commit -m "deploying the app"
git push Once you push the commits, you will see that your space is building the Docker image and installing the dependencies.
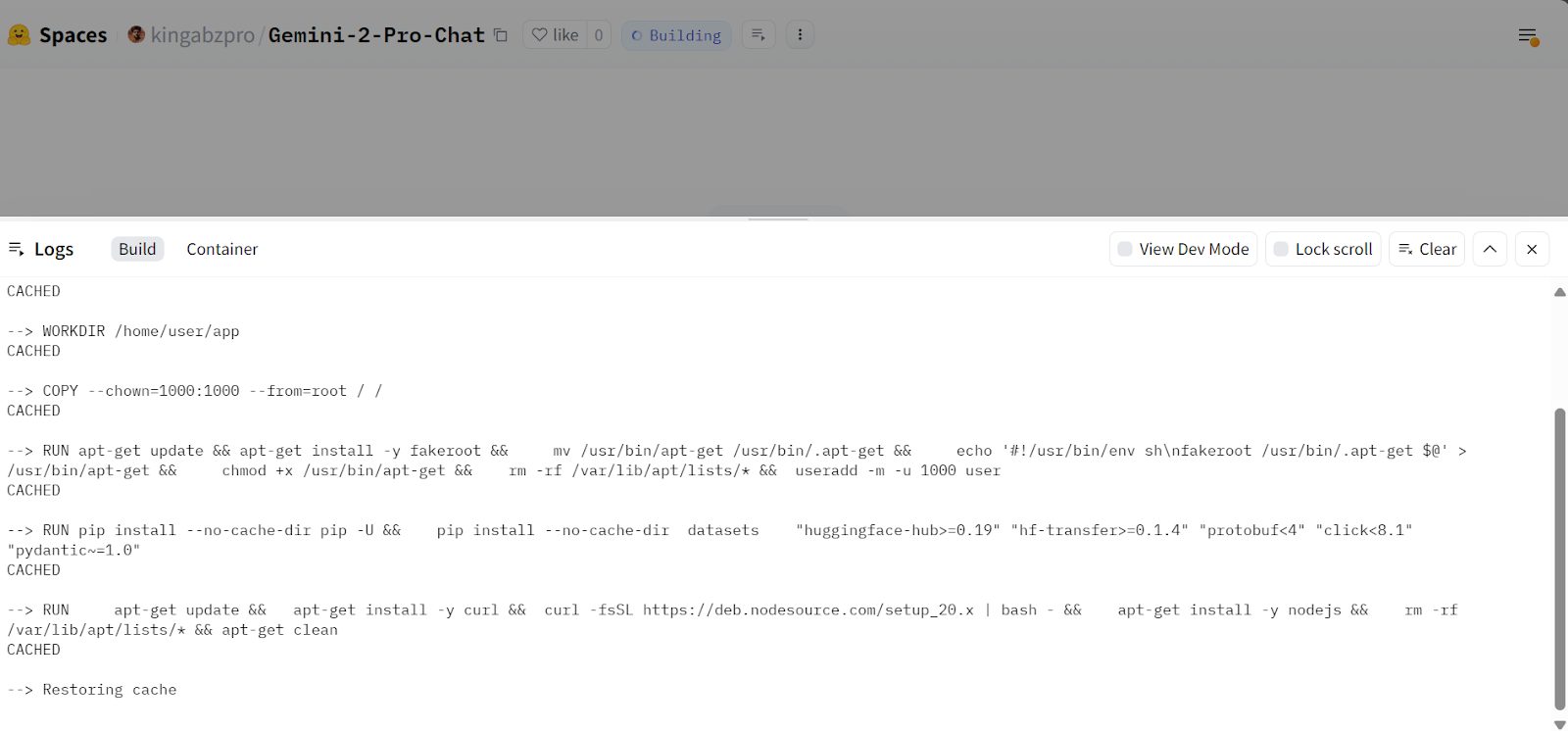
Source: Gemini 2 Pro Chat
After everything is finalized, you may encounter an error message. Don’t worry about it; it relates to missing environment variables that we are going to add in the Spaces.
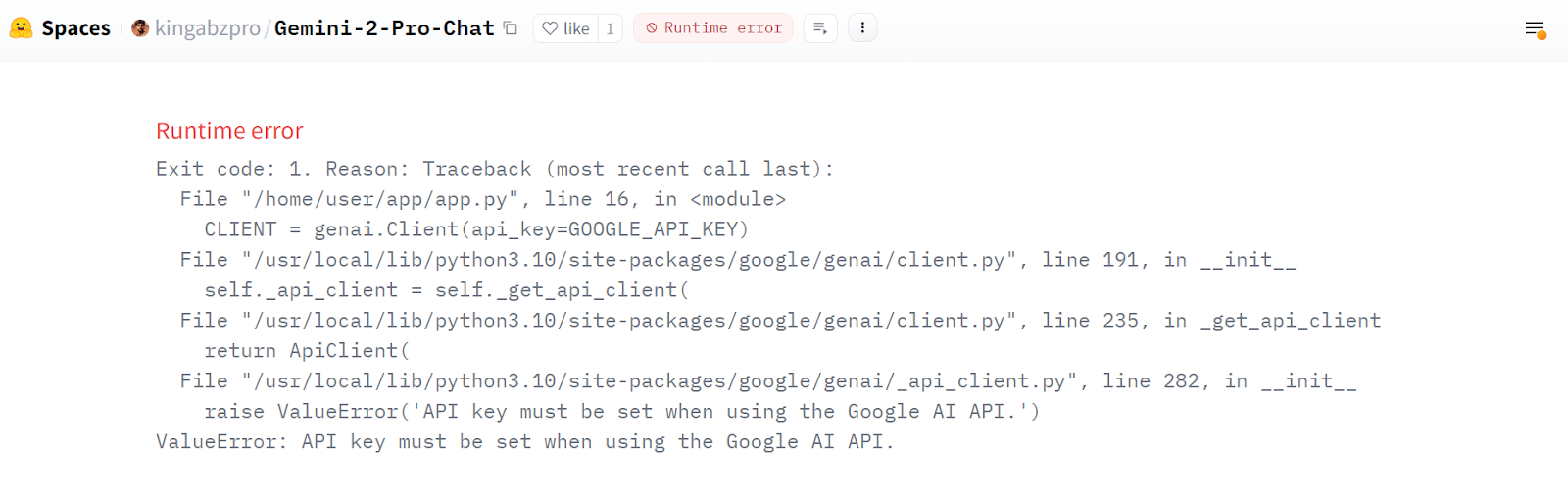
Source: Gemini 2 Pro Chat
Go to your Space settings and scroll down to the "Variables and Secrets" section. Create a new secret by clicking on the “New Secret” button. Provide it with the name and your Gemini API key.
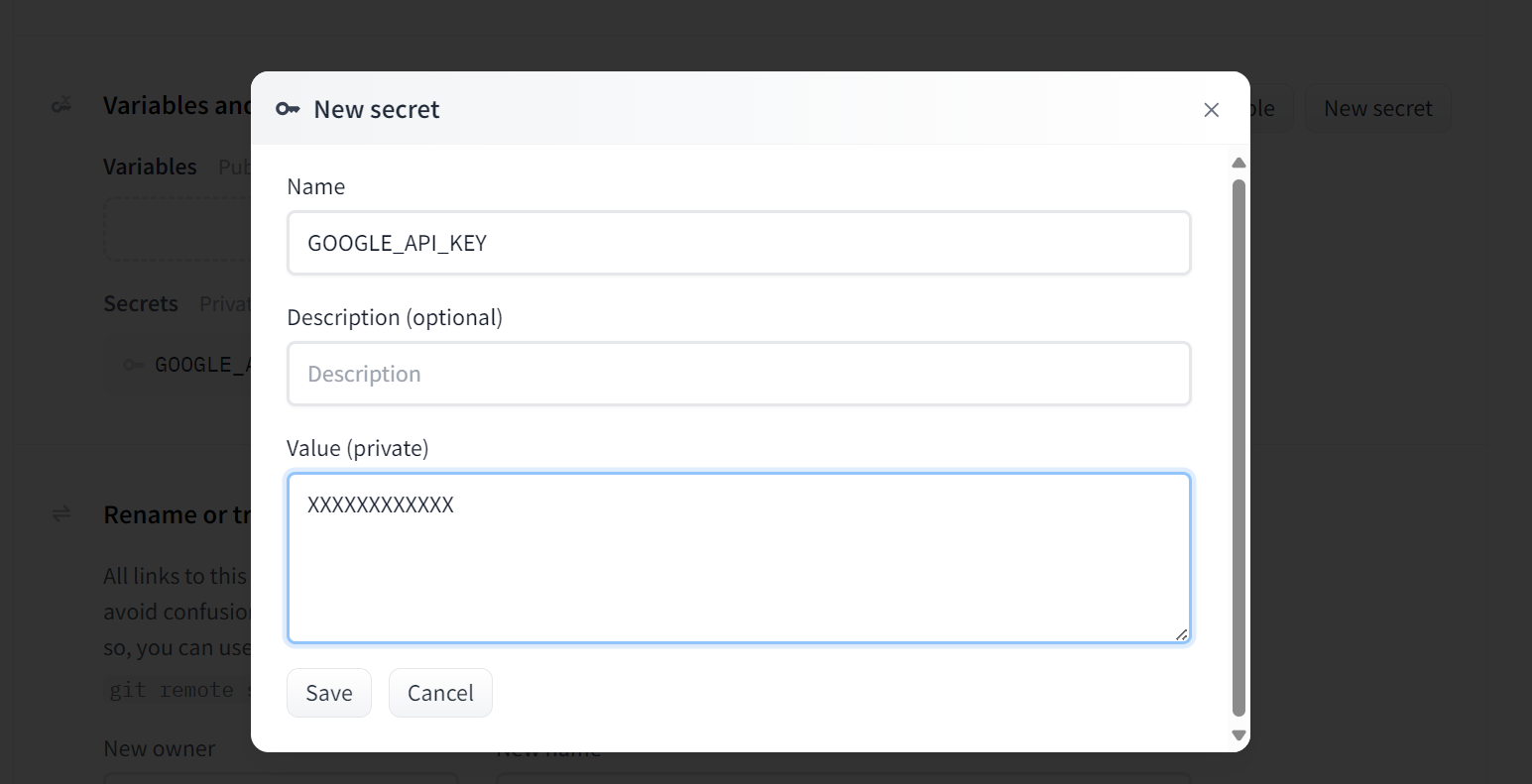
Source: Gemini 2 Pro Chat
After you add the secret, the space will automatically restart, and your app will run smoothly, similar to how it was running locally.
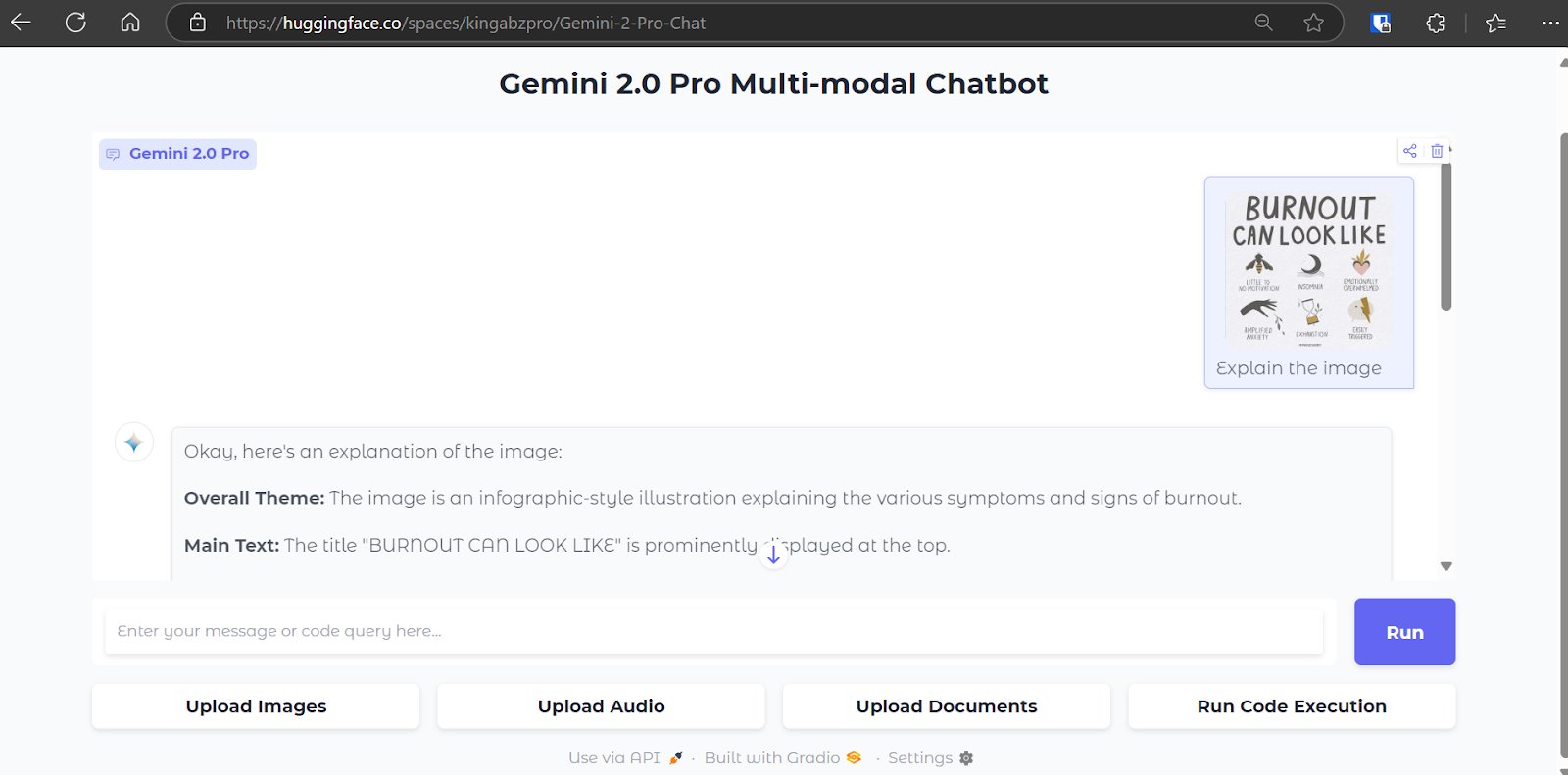
Source: Gemini 2 Pro Chat
Building a high-performance AI application has become significantly easier with the new Gemini 2.0 Pro API and its advanced features. Instead of installing multiple Python packages to process images, audio, or documents, you can simply provide these inputs to the API endpoint. The model will generate results within seconds, making the process seamless and efficient.
Currently, access to Gemini 2.0 Pro is free but limited to 50 requests per day. However, it’s important to note that the API should not be used for commercial purposes to avoid the risk of account suspension.
In this tutorial, we explored the cutting-edge Gemini 2.0 Pro model and its features. We tested these capabilities in Jupyter Notebooks and integrated them into a Gradio application. Finally, we deployed the application to the cloud, making it accessible to the public.
If you want to learn more about creating AI-powered applications, check out our skill track on Developing AI Applications to learn about some of the latest AI developer tools.
Top DataCamp Courses
Track
Track
Course
Tutorial
François Aubry
Tutorial
Kurtis Pykes
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Natasha Al-Khatib
code-along
Korey Stegared-Pace



