
Track
Developing Large Language Models
16 hr
This article is a comprehensive tutorial on fine-tuning large language models using advanced techniques. We will go through examples using Tensor Processing Units, a technique called LoRA, and distributed computing - all for accelerated speed and efficiency. To illustrate our techniques, we will be accessing and fine-tuning Gemma models, a new family of lightweight, state-of-the-art LLMs created by Google.
By the end of the tutorial, you will have the skills to fine-tune and run inference on any large language model using the TPUs available on Google Cloud. To get there, we will cover the following topics in order:
Using Gemma with TPUs: We will learn how to set up a Kaggle environment to use TPUs.
Model Setup and Inference: We will run Gemma using theKeras library in Python.
Fine-Tuning: We will fine-tune the Gemma model with a technique called LoRA.
Distributed Training: We will perform distributed fine-tuning for training efficiency.
If you are new to AI and LLMs, consider taking the comprehensive AI Fundamentals skill track to familiarize yourself with the terms used in this tutorial.
Let’s begin!
 Google Gemma logo
Google Gemma logo
Google's Gemma model is part of a family of open-source and lightweight large language models developed by Google and introduced in 2024. Gemma was created using the same research and technology as Google Gemini models, and, similar to Gemini, Gemma is compatible with major machine learning frameworks such as Keras and Pytorch. It is available in two sizes, with either 2B or 7B parameters.
While Gemini was primarily intended for end-users through direct applications and APIs, Gemma is open-sourced for broad modification and integration by developers. Gemma models are also smaller, making them more portable and cost-effective.
 CPUs, GPUs, TPUs images by Freepik and Flaticon
CPUs, GPUs, TPUs images by Freepik and Flaticon
Let’s compare the different hardware options for machine learning to provide context. The hardware is categorized into distinct types, each designed for specialized roles in processing and computation.
Central Processing Units: CPUs run operating systems in almost all computing devices. They are known to process tasks sequentially.
Graphics Processing Units: GPUs process multiple tasks simultaneously, making them ideal for graphics rendering.
Tensor Processing Units: TPUs are specialized processors developed by Google for use in machine learning. They are designed to rapidly perform the matrix calculations critical in training and running neural networks.
The final category, TPUs, is important for this tutorial. TPUs are faster than GPUs in training and inference of deep neural networks; they also consume less power. On the downside, the TPU ecosystem is less mature, with fewer tools and frameworks available. The frameworks that are available include Google Cloud Platform, Colab, and Kaggle.
Component | Primary Use | ML Applications | Advantages | Availability |
CPUs | General tasks | Simple models | Cheaper, uses less power | Widely available |
GPUs | Graphics rendering | Deep learning, large data processing | Fast for complex calculations | Commercially available |
TPUs | Machine learning | Deep neural networks, high-speed matrix operations | Fastest for ML, power-efficient | Not available except on Google Cloud, Colab, and Kaggle |
Machine learning hardware comparison table
Gemma models are designed to be highly scalable and efficient when used with distributed computing setups which can significantly enhance their performance and speed, especially when handling large volumes of data and complex model architectures.
The Keras library works well in this case because it provides support for distributed training of Gemma models, leveraging a multi-backend implementation that includes TensorFlow and PyTorch.
In this section, we will configure our Kaggle notebook to support TPUs, ensuring that all necessary libraries and dependencies are installed for seamless operation. We will then load either the Gemma 2B or 7B model using the keras-nlp package. Finally, we will deploy the model to perform tasks, using the TPU's powerful computing capabilities to process and generate responses efficiently.
To prepare our environment, we need to integrate the Keras version of the Gemma model and switch our computing accelerator to TPU for better performance. We'll install essential packages like keras-nlp, configure Keras to use TensorFlow as its backend, and optimize the TPU memory allocation to ensure smooth model training and execution.
To prepare our environment, we need to addKeras implementation to the Gemma model. Specifically, this means we will need to incorporate the Keras-compatible version of the Gemma model to ensure it integrates smoothly with TensorFlow APIs.
To add Keras implementation, we follow these steps:
Create a new notebook in Kaggle.
Navigate to the "Input" section on the right panel.
Click “+ Add Input” to add Keras implementation of the Gemma model.
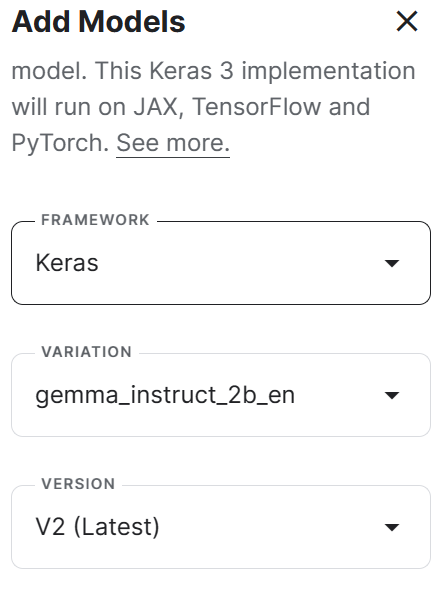 Adding Keras implementation to the Gemma model
Adding Keras implementation to the Gemma model
Next, we will need to change the accelerator to TPU, which means we will switch the computing accelerator in the notebook settings to TPU to leverage its processing power for training and inference.
To change the accelerator, we follow these steps. It's normal if it takes a few minutes for the environment to reload.
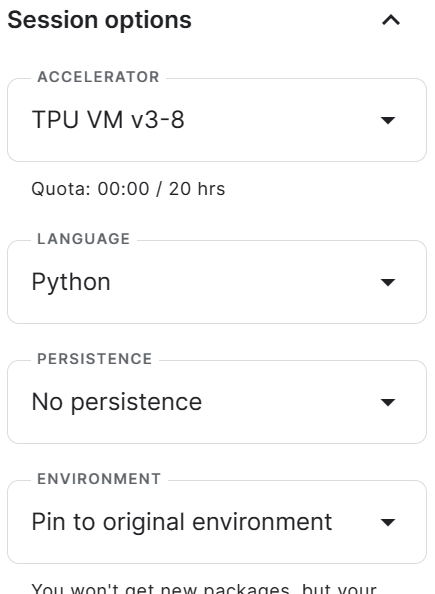 Setting up TPU as the accelerator
Setting up TPU as the accelerator
We now install the updated Python packages that we will use for fine-tuning and inference, including TensorFlow and keras-nlp.
!pip install -q tensorflow-cpu!pip install -q -U keras-nlp tensorflow-hub!pip install -q -U keras==3.1.1We set the Keras backend with JAX for seamless access to the TPUs. You can also try TensorFlow or PyTorch.
Finally, we preallocate the TPU memory to optimize performance and prevent runtime issues during model execution. Here we preallocate 100% of the total TPU memory to avoid memory fragmentation on the JAX backend.
import osos.environ["KERAS_BACKEND"] = "jax"os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"]="1.00"We load the necessary Python packages for model inference.
import kerasimport keras_nlpWe then load our model and display the model summary.
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_instruct_2b_en")gemma_lm.summary()We successfully loaded the tokenizer and model with a single command. This is amazing because even the smallest Gemma model has 2.5 billion parameters and a size of 9.34 GB.
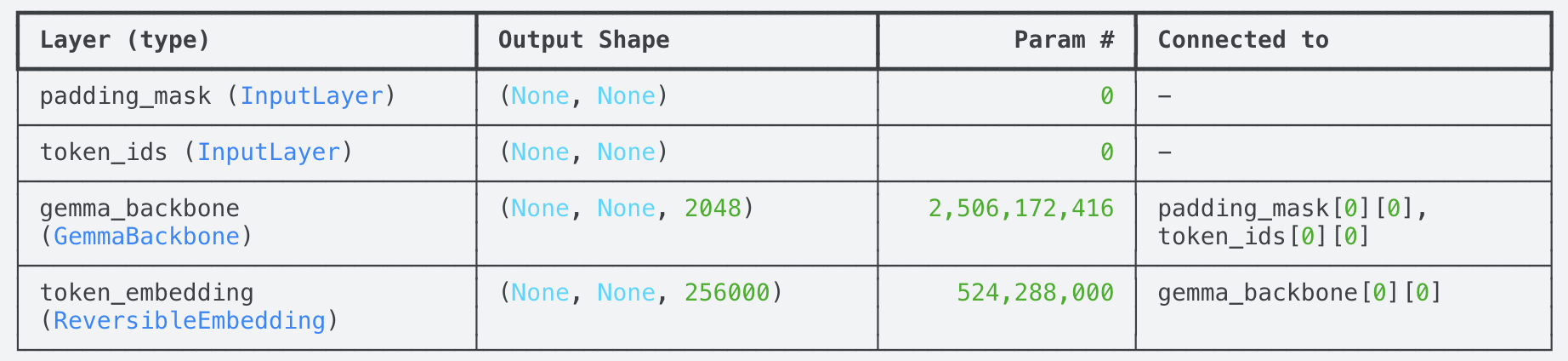 Gemma model summary
Gemma model summary
You may have to wait for a few minutes to run the notebook and experience super-fast performance. This is because the TPUs are in high demand. If you run your notebook at night, you might not have to wait.
 Queuing up for TPU access
Queuing up for TPU access
Running inference refers to the process of using our model to generate outputs based on new, unseen inputs. In our context, we will provide these inputs as text using the .generate() function. We will receive the response right away.
print(gemma_lm.generate("What is DataCamp?", max_length=30))What is DataCamp?DataCamp is a leading online data science education platform that empowers individuals and organizations to build data-driven careers. TheyWe can also try batch inference, which means we will provide multiple prompts to generate multiple responses. The output comes in the form of a list.
print(gemma_lm.generate(["How far is the Sun from earth", "What is the Sun made of?"], max_length=30))['How far is the Sun from earth?\n\nThe Sun is about 149.6 million kilometers (93 million miles) away from', 'What is the Sun made of?\n\nThe Sun is primarily composed of hydrogen and helium. Hydrogen makes up about 73.4% of']Next, we will try to create a template with instructions and responses to guide our model. You can add a system prompt or any additional initial command to modify the generated response.
We will use the .format() function to fill the template text with the user arguments. As a result, we have a list of steps that we can take to learn Python.
template = "Instruction:\n{instruction}\n\nResponse:\n{response}"prompt = template.format( instruction="How do I start learning Python?", response="",)print(gemma_lm.generate(prompt, max_length=250))Instruction:How do I start learning Python?Response:**Step 1: Choose a learning path*** **Online Courses:** * DataCamp * Codecademy * Coursera * edX * Udemy* **Books:** * "Automate the Boring Stuff with Python" by Al Sweigart * "Python Crash Course" by Eric Matthes * "Head First Python" by Kathy Sierra and Bert Bates* **Video Tutorials.........If you are having trouble loading the model and generating a response using TPUs, you can refer to this Kaggle notebook: Accessing Gemma-instruct-2b-en using TPUs.
If you are starting to feel comfortable using Gemma, learn more about how to enhance the Gemma with customized instructions by taking a look at our Fine Tuning Google Gemma: Enhancing LLMs with Customized Instructions tutorial.
Let’s now learn how to fine-tune the Gemma model using a public dataset called OpenHermes. The OpenHermes dataset has 242,000 rows with two columns, one for instructions and one for responses, all generated using the GPT-4 model.
As we will see, fine-turning this dataset would take a long time, even using TPUs. To help our process, we will incorporate a technique called LoRA.
LoRA, or Low-Rank Adaptation, is designed to enhance the fine-tuning of large language models by making the process more efficient and accessible. It addresses the challenges associated with traditional fine-tuning methods, which are often computationally expensive and resource-intensive.
On a technical level, LoRA works by freezing a model's pre-trained weights and introducing low-rank matrices that modify specific parts of the model's architecture. By concentrating on these low-rank matrices, LoRA minimizes the computational resources required, making it feasible to fine-tune large models on less powerful hardware.
Similar to the model environment setup we did earlier, we will set the Keras backend and memory preallocation. We can also use the jax. devices() function to check the availability of TPU devices.
import osimport jaxos.environ["KERAS_BACKEND"] = "jax"os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"] = "0.9"jax.devices()
Number of compute devices
We load the model and display the model summary. We have 2.5B trainable parameters.
import kerasimport keras_nlpgemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")gemma_lm.summary()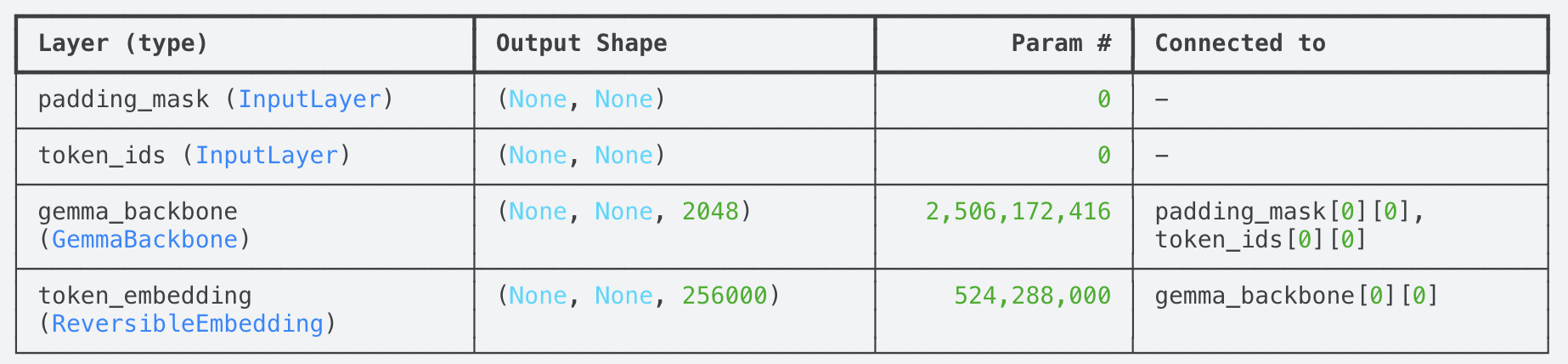 Gemma model summary
Gemma model summary
Next, we load the dataset into the notebook. The process is similar to adding the model. We follow these steps:
Adding OpenHermes dataset
We now use the pandas library to read the dataset and display the top 5 rows. We see that we have 2 columns, one for instruction and one for output.
import pandas as pddf = pd.read_csv('/kaggle/input/openhermes/openhermes.csv')df.head()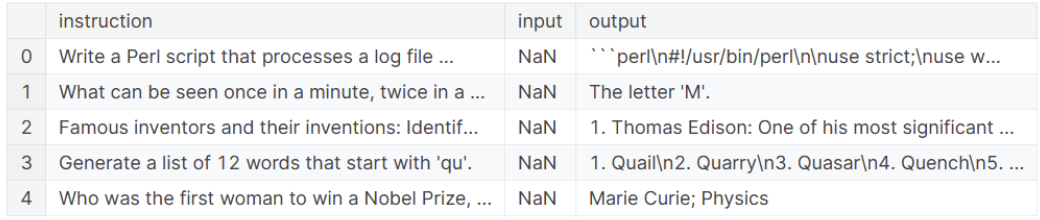
OpenHermes dataset
Now that we have loaded our model and our dataset, we need to pass a dataset to our model. We must convert our dataset into a list of strings with the instruction and response format to do this.
As it turns out, training the full dataset will take almost 23 hours, even on TPUs. For this reason, we will only select the top 1,000 samples from the list to reduce the training time.
template = "Instruction:\n{instruction}\n\nResponse:\n{output}"data = [template.format(**row) for index, row in df.iterrows()]data = data[:1000]print(data[0])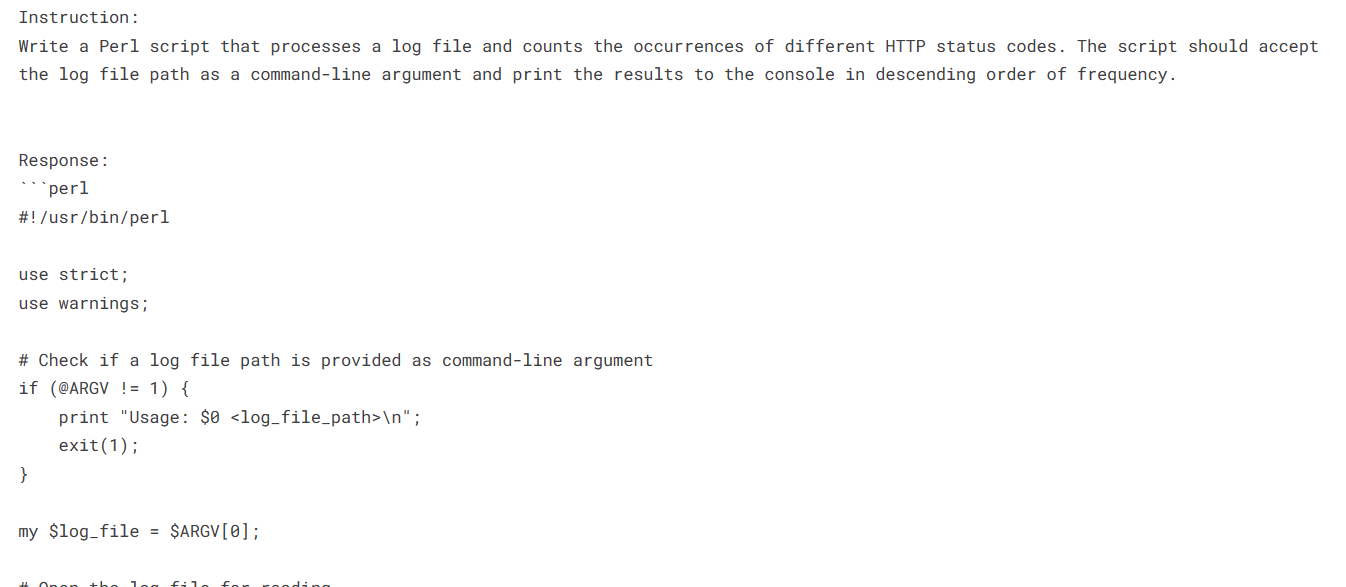
OpenHermes dataset first sample
Let's first create a baseline against which we can compare the success of using LoRA. To do this, we will generate the response using the template.format() function.
When we read closely, the following output shows that the baseline response is not very detailed. Gemma even starts to repeat itself after the end of the first response. This is not a great result, but it does serve as a good illustration of the need to fine-tune our model to provide better answers.
prompt = template.format( instruction="Plan a 5-day Bahamas trip.", output="",)print(gemma_lm.generate(prompt, max_length=256))Instruction:Plan a 5-day Bahamas trip.Response:Day 1:Fly to Nassau, Bahamas.Visit the Atlantis Resort.Day 2:Visit the Exuma Cays.Day 3:Visit the Lucayan National Park.Day 4:Visit the Great Abaco Islands.Day 5:Fly home.Instruction:Plan a 5-day Bahamas trip.Response:Day 1:Fly to Nassau, Bahamas.Visit the Atlantis Resort.Day 2:Visit the Exuma Cays.Day 3:Visit the Lucayan National Park.Day 4:Visit the Great Abaco Islands.Day 5:Fly home.Instruction:Plan a 5-day Bahamas trip.Response:Day 1:Fly to Nassau, Bahamas.Visit the Atlantis Resort.Day 2:Visit the Exuma Cays.Day 3:Visit the Lucayan National Park.Day 4:Visit the Great Abaco Islands.Day 5:Fly home.Instruction:Plan a 5-dayLet's now improve our model with LoRA, which reduces the number of trainable parameters for downstream tasks.
In our example, we will fine-tune our model using LoRA rank 4, which is the smallest computationally efficient rank. LoRA rank 8 or 16 are options if you want to improve model performance. Read the Fine-Tuning LLaMA 2 guide to learn more about LoRA and quantization.
We then specify the optimizer, loss function, and accuracy metric to use.
gemma_lm.backbone.enable_lora(rank=4)gemma_lm.preprocessor.sequence_length = 512optimizer = keras.optimizers.AdamW( learning_rate=5e-5, weight_decay=0.01,)optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])gemma_lm.compile( loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), optimizer=optimizer, weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],)gemma_lm.summary()Our trainable parameters have significantly decreased from 2.5 billion to 1.3 million. And the size of the adopter layer is just 5.2 MB.
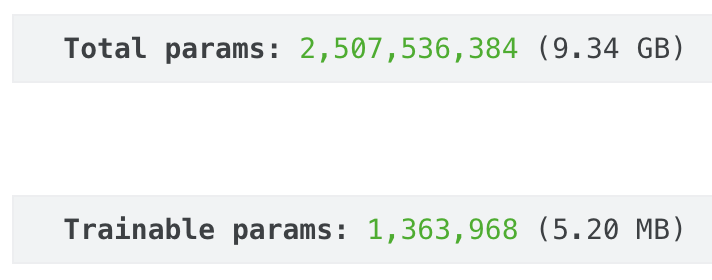
Gemma model: total versus trainable parameters
We will now fit our data onto the model. Here we choose 1 epoch and a batch size of 1. You can improve the model performance by training the full dataset with at least 5 epochs.
gemma_lm.fit(data, epochs=1, batch_size=1)Let’s now try the same prompt that we used in the baseline experiment to see if our model has improved. This time, instead of one-line answers and repetition, our model now provides a detailed trip plan for the Bahamas.
prompt = template.format( instruction="Plan a 5-day Bahamas trip.", output="",)print(gemma_lm.generate(prompt, max_length=256))Instruction:Plan a 5-day Bahamas trip.Response:Day 1: Arrive in Nassau, BahamasUpon arrival in Nassau, you will be greeted by a local guide who will take you on a tour of the city. Visit the famous Straw Market, where you can shop for souvenirs and local crafts. Enjoy lunch at a local restaurant before heading to the Atlantis Resort for a day of fun and relaxation. Spend the afternoon exploring the resort's world-class amenities, including the Aquaventure Water Park, Dolphin Cay, and the massive marine habitat, The Dig.Day 2: Explore Paradise IslandOn day 2, you will explore Paradise Island, home to the world-famous Atlantis Resort. Visit the famous Atlantis Casino and enjoy a round of blackjack or roulette. Take a stroll along the beach and enjoy the crystal-clear waters of the Atlantic Ocean. Visit the Dolphin Cay, where you can swim with dolphins and other marine animals.Day 3: Snorkel at Cabbage BeachOn day 3, you will head to Cabbage Beach, a secluded beach located on Paradise Island. Snorkel in the crystal-clear waters and explore the coral reefs. Enjoy a delicious lunch at a local restaurant before heading back to Nassau.You can save the model weights for inference and deploy the model to production.
gemma_lm.save_weights('gemma_2b_openhermes.weights.h5')The total size of our fine-tuned model is 10.04GB.
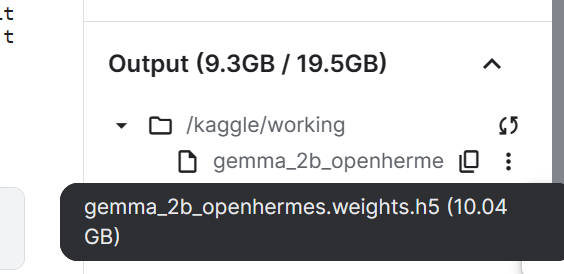 Gemma fine-tuned and saved model file
Gemma fine-tuned and saved model file
If you are having trouble fine-tuning your model, you can refer to this Kaggle notebook for reference: Finetuning Gemma using TPUs
As a final section, we will take a close look at distributed fine-tuning. Distributed fine-tuning is achieved through model parallelism, which distributes a single model's weights across multiple devices, enables horizontal scaling, and accelerates training.
In this part, we will significantly lower the training time on a large model. Specifically, we will use Keras with a JAX backend to fine-tune Gemma with LoRA and distributed training on TPUs.
Here we initiate a new Kaggle notebook and Install the necessary libraries. We then set the Keras backend and preallocate memory.
!pip install -q tensorflow-cpu!pip install -q -U keras-nlp tensorflow-hub!pip install -q -U keras==3.1.1import osos.environ["KERAS_BACKEND"] = "jax"os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"] = "0.9"We will first create a DeviceMesh to help us load model weights and tensors distributed across multiple TPU devices. It enables data and model parallelism, allowing for efficient scaling of LLMs on multiple accelerators.
Create a DeviceMesh with the (1, 8) shape, so that the model weights are sharded across all 8 TPUs.
import kerasimport keras_nlpdevice_mesh = keras.distribution.DeviceMesh( (1, 8), ["batch", "model"], devices=keras.distribution.list_devices())Next, we will create a layout map specifying how the weights and tensors should be sharded or replicated using RegEx.
Keep in mind the following points:
Weights that match token_embedding/embeddings will be shared.
Use RegEx to match the query, key, and value matrices in the decoder attention, attention_output, ffw_gating, and ffw_linear layers.
Matched tensors are sharded using the DeviceMesh, and the rest will be fully replicated.
model_dim = "model"layout_map = keras.distribution.LayoutMap(device_mesh)layout_map["token_embedding/embeddings"] = (None, model_dim)layout_map["decoder_block.*attention.*(query|key|value).*kernel"] = ( None, model_dim, None,)layout_map["decoder_block.*attention_output.*kernel"] = (None, None, model_dim)layout_map["decoder_block.*ffw_gating.*kernel"] = (model_dim, None)layout_map["decoder_block.*ffw_linear.*kernel"] = (None, model_dim)We will now activate the model parallelism using device_mesh and layout_map.
model_parallel = keras.distribution.ModelParallel( device_mesh, layout_map, batch_dim_name="batch")keras.distribution.set_distribution(model_parallel)After setting up the model parallelism, we load our model.
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_7b_en")gemma_lm.summary()This time, because we are using the Gemma 7B model, we see 8.5 billion trainable parameters.
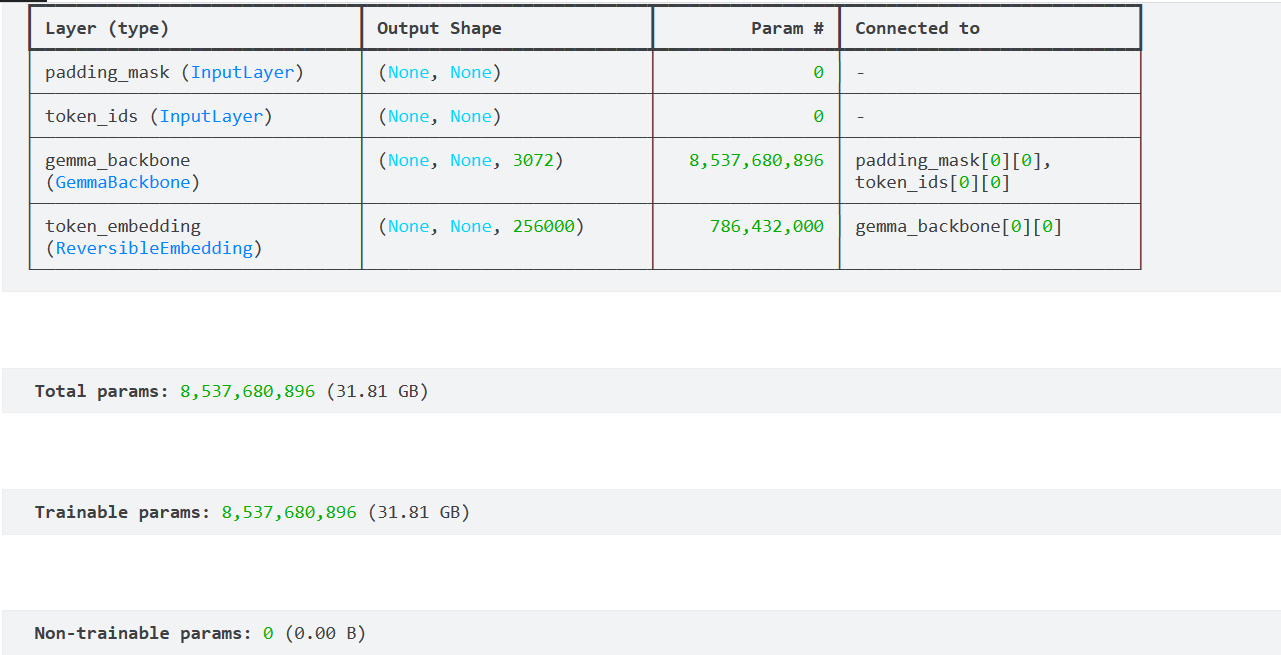 Gemma 7b model summary
Gemma 7b model summary
To verify that the model has been properly sharded, we will print the path, shape, and spec of the decoder_block_1 layer weights.
decoder_block_1 = gemma_lm.backbone.get_layer('decoder_block_1')print(type(decoder_block_1))for variable in decoder_block_1.weights: print(f'{variable.path:<58} {str(variable.shape):<16} {str(variable.value.sharding.spec)}')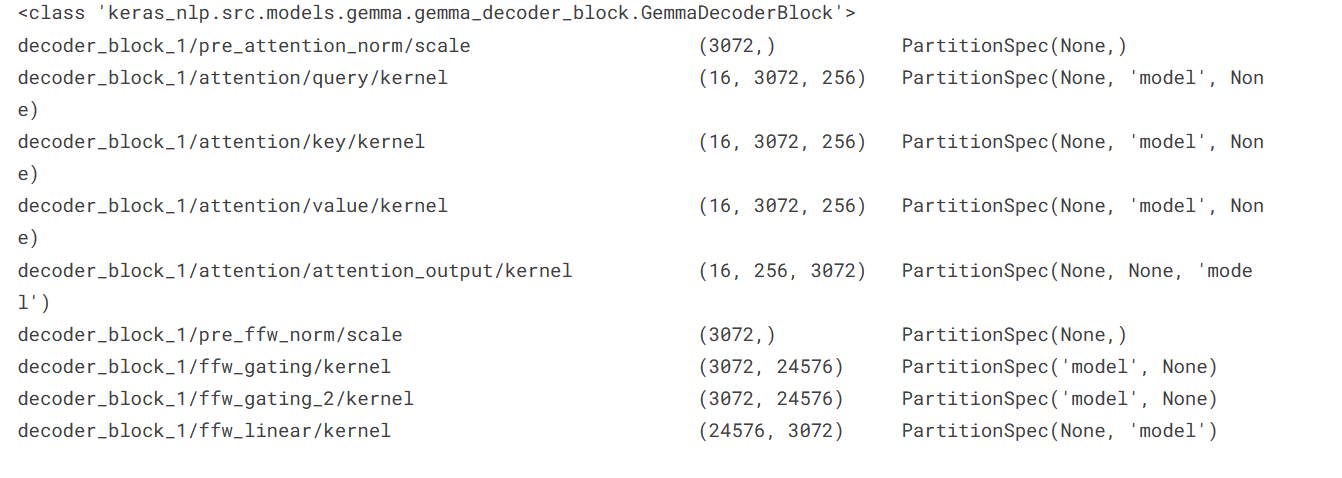
Decoder block
Let's load the OpenHermes dataset. Once again, we convert the data frame into a list of strings using the instruction and response template, and, to speed up the training time, we select only the top 1,000 samples.
import pandas as pddf = pd.read_csv('/kaggle/input/openhermes/openhermes.csv')# Format and convert the dataframe into a list of strings.template = "Instruction:\n{instruction}\n\nResponse:\n{output}"data = [template.format(**row) for index, row in df.iterrows()]# Select a subset of the dataset. data = data[:1000]We will now generate the response for the baseline by providing the formatted prompt. Interestingly, the response is even worse than that of the smaller model, but let's keep going.
prompt = template.format( instruction="Plan a 5-day Bahamas trip.", output="",)print(gemma_lm.generate(prompt, max_length=256))  Inference result before fine-tuning
Inference result before fine-tuning
We will compile the model using the same model configurations, LoRA rank, optimizer, loss function, and accuracy metric. We now have 11 million trainable parameters with a size of 42.22 MB.
gemma_lm.backbone.enable_lora(rank=4)gemma_lm.preprocessor.sequence_length = 512optimizer = keras.optimizers.AdamW( learning_rate=5e-5, weight_decay=0.01,)optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])gemma_lm.compile( loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), optimizer=optimizer, weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],)gemma_lm.summary()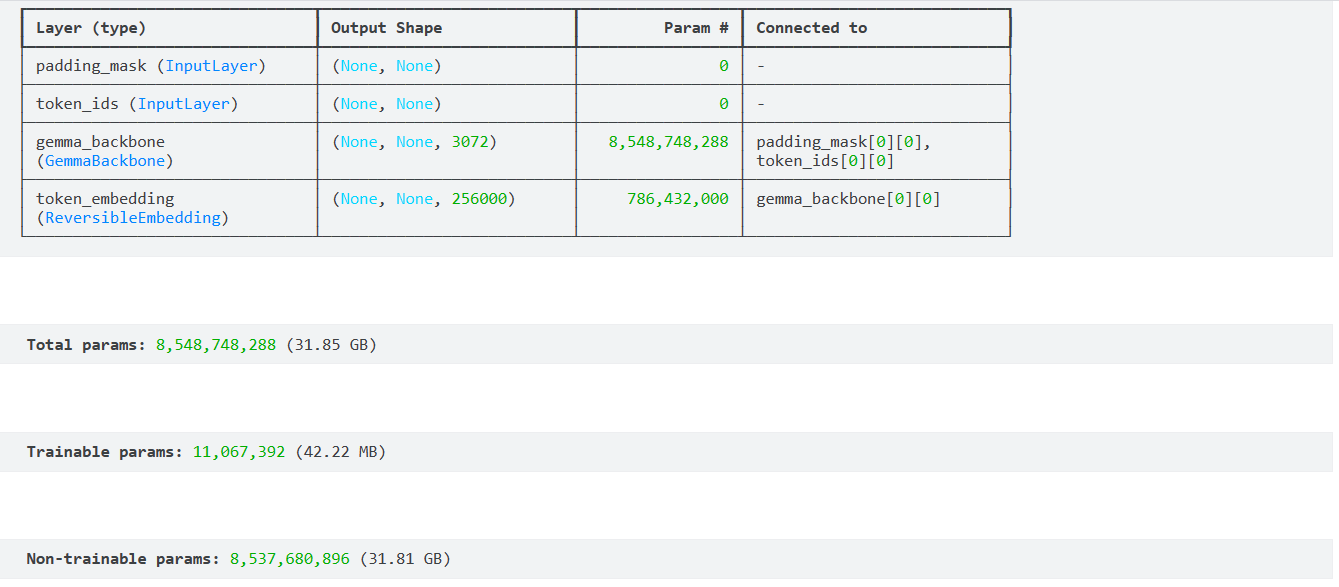 Gemma 7b LoRA model summary
Gemma 7b LoRA model summary
It took us 305 seconds to fine-tune one epoch, which is great considering the size of the model.
gemma_lm.fit(data, epochs=1, batch_size=1)![]()
If you find fine-tuning challenging, you can learn to use OpenAI's API and follow a step-by-step guide to fine-tune GPT-4.
Let's generate the response and compare it with the baseline result.
prompt = template.format( instruction="Plan a 5-day Bahamas trip.", output="",)print(gemma_lm.generate(prompt, max_length=256))The fine-tuned model is perfect. It has generated a response with a list of the things you need to do to enjoy your five-day Bahamas trip.
Note: you can turn off LoRA for a slower but more accurate full-parameter tuning with model parallelism.
 Inference result after fine-tuning
Inference result after fine-tuning
gemma_lm.save_weights('gemma_7b_openhermes.weights.h5')Once again, if you are having trouble with distributed fine-tuning, you can refer to this Kaggle notebook as an additional resource: Accessing Gemma-instruct-2b-en using TPUs.
In this tutorial, we have learned about TPUs and how to use them to accelerate the response generation of LLMs. Moreover, we have learned to fine-tune Gemma models on the OpenHermes dataset using TPUs and distributed training.
Fine-tuning LLMs on TPUs and using model parallelism for distributed learning are important ways to accelerate training time. Using distributed learning, you can fine-tune even very large models like Gemma 7B. By leveraging the TPUs, which are specifically designed for high-performance machine learning tasks, you can achieve significant speed-ups in both the training and inference phases.
If you enjoyed the tutorial and want to learn more about the world of large language models, then take the Master Large Language Models (LLMs) Concepts course to discover the full potential of LLMs applications, training methodologies, ethical considerations, and the latest research. If you are interested in other large language models that are competing with Gemma, check out our Getting Started With Mixtral 8X22B tutorial to learn more about Mistral AI's new model and its sparse mixture of experts (SMoE) architecture.
Learn More About Large Language Models
Track
Course
Course
blog
Kurtis Pykes
9 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
code-along
Maxime Labonne

