
Whisper is a general-purpose automatic speech recognition model that was trained on a large audio dataset. The model can perform multilingual transcription, speech translation, and language detection.
Whisper can be used as a voice assistant, chatbot, speech translation to English, automation taking notes during meetings, and transcription.
Transcription is a process of converting spoken language into text. In the past, it was done manually, and now we have AI-powered tools like Whisper that can accurately understand spoken language.
If you have basic knowledge of Python language, you can integrate OpenAI Whisper API into your application. The Whisper API is a part of openai/openai-python, which allows you to access various OpenAI services and models.
Learn more about building AI applications with LangChain in our Building Multimodal AI Applications with LangChain & the OpenAI API AI Code Along where you'll discover how to transcribe YouTube video content with the Whisper speech-to-text AI and then use GPT to ask questions about the content.
What are good use cases for transcription?
- Transcribing interviews, meetings, lectures, and podcasts for analysis, easy access, and keeping records.
- Real-time speech transcription for subtitles (YouTube), captioning (Zoom meetings), and translation of spoken language.
- Speech transcription for personal and professional use. Transcribing voice notes, messages, reminders, memos, and feedback.
- Transcription for people with hearing impairments.
- Transcription for voice-based applications that requires text input. For example, chatbot, voice assistant, and language translation.
Which languages are supported?
Languages supported for transcriptions and translations by OpenAI Whisper API are:
Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh.
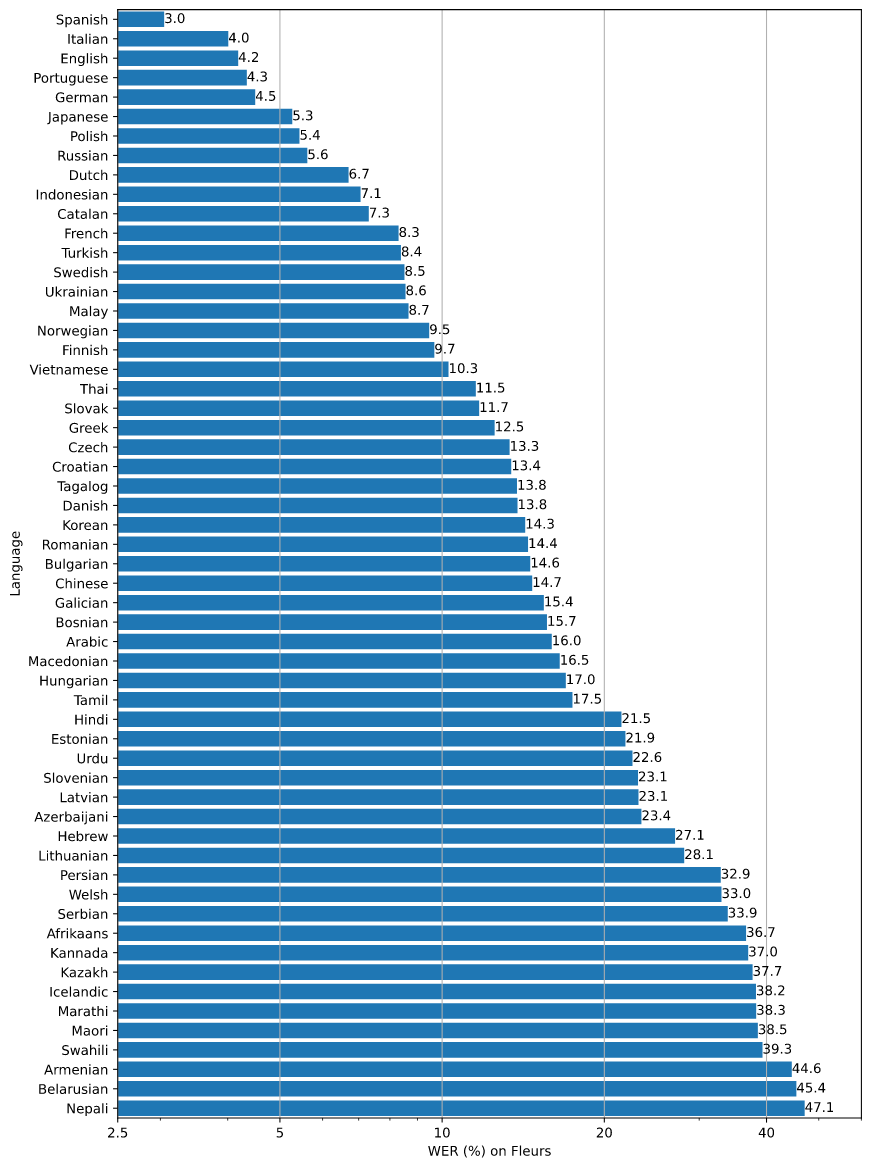
The breakdown of the Word Error Rate (WER) for Fleur's dataset using the large-v2 model is presented in the figure below, categorized by languages. Smaller the WER, the better the transcription accuracy.
Which file formats are supported?
The file formats supported by Whisper API are mp3, mp4, mpeg, mpga, m4a, wav, and webm. Currently, upload file size is limited to 25MB. If you have larger files, you can break them down into smaller chunks using pydub.
Speech to text with OpenAI API
In this section, we will use OpenAI API for transcription and translation. Moreover, we will also look into various types of output formats.
Setup
You can install OpenAI Python API by using pip.
pip install openaiAfter that, we have to generate API keys by accessing OpenAI API webpage, clicking on the display photo, and selecting the "View API keys" option. All of the new OpenAI accounts come with $5 free credits, so no need to worry about adding credit card details.
Next, click on the “Create new security key” button, write the key name, and then copy the generated key.
Setup your API key with an environment variable
We can set up the API key in our local system by typing the below command in the terminal. It will set up an environment variable of API for you to use OpenAI services.
export OPENAI_API_KEY='sk-...kMEM'Setup your API key by using the OpenAI package
You can set up a key within your Python program using openai.api_key. This method is not recommended as it exposes your API to the public.
import openai
openai.api_key = "sk-...kMEM"Setup your API key easily in DataLab
If you are using DataLab, you have to click on Environment > the 'plus' icon and then fill in the names and values of your environment variables.
After that, you have to enable the environment variable by clicking on the Connect button.
Dataset
English
We will use a small part of Marvin Minsky's interview on AI Youtube video and convert it into audio. The file marvin_minsky.mp3 has a one-minute duration and 970 KB size.
Spanish
We have cut a small part from How Are People in Barcelona Using AI? Spanish language YouTube video to create an Easy_spanish_315.mp3 file. It has a 509 KB size and 20-second duration.
English Transcriptions
The transcriptions API is straightforward. You just have to load the audio file with the with statement and add the audio object to openai.Audio.transcribe. The transcribe function only requires a model name and audio object, but you can provide language arguments for better accuracy.
import openai
with open("Audio/marvin_minsky.mp3", "rb") as audio_file:
transcript = openai.Audio.transcribe(
file = audio_file,
model = "whisper-1",
response_format="text",
language="en"
)
print(transcript)of theories called Steps Toward Artificial Intelligence around 1970. That sort of charted several possible lines of research, which pretty much predicted what several communities of researchers would do in the next 20 years. Those predictions started to fall apart around--so that paper was 1970, roughly. By the late 1980s, the world had changed. It was interesting because when I started research in that general area, almost all of my students soon became professors.Check out the OpenAI API Python cheat sheet for a quick review of what each function does. We can use the cheat sheet to learn about various OpenAI API commands for text generation, speech transcription, Image generation, embedding, and more.
Alternate Output Formats
In the previous example, we have set the output response format to be simple text, but you can always change it to subrip subtitles (response_format="srt"), video text track subtitles (response_format="vtt"), and metadata (response_format="verbose_json").
In our examples, we will change response_format to “srt” to get subtitles as output.
with open("Audio/marvin_minsky.mp3", "rb") as audio_file:
transcript2 = openai.Audio.transcribe(
file = audio_file,
model = "whisper-1",
response_format="srt",
language="en"
)
print(transcript2)As we can see, the output text is divided based on the timestamp.
1
00:00:00,000 --> 00:00:10,960
of theories called Steps Toward Artificial Intelligence around 1970.
2
00:00:10,960 --> 00:00:24,320
That sort of charted several possible lines of research, which pretty much predicted what
3
00:00:24,320 --> 00:00:31,920
several communities of researchers would do in the next 20 years.
4
00:00:31,920 --> 00:00:42,040
Those predictions started to fall apart around--so that paper was 1970, roughly.
5
00:00:42,040 --> 00:00:48,200
By the late 1980s, the world had changed.
6
00:00:48,200 --> 00:00:56,760
It was interesting because when I started research in that general area, almost all
7
00:00:56,760 --> 00:01:16,920
of my students soon became professors.Spanish Transcription
The Whisper was trained in 98 languages which allows it to transcribe into multiple languages. For that, you have to change the language argument.
In our case, we are transcribing Spanish language audio, and for that, we have set language="es"
with open("Audio/easy_spanish_315.mp3", "rb") as audio_file:
transcript_es = openai.Audio.transcribe(
file = audio_file,
model = "whisper-1",
response_format="text",
language="es"
)
print(transcript_es)¿Qué crees que es la inteligencia artificial? ¿Qué creo que es? Eh... no sé, no sé cómo describirlo. Algo que no es natural, obviamente. Eh... Pues la inteligencia artificial es mediante... mediante datos, eh... introducirle a un algoritmo.Spanish to English Translations
You can only translate your audio into English transcription.
In the example, we will provide the `translate` function with Spanish audio, and it will translate Spanish language audio into English.
with open("Audio/easy_spanish_315.mp3", "rb") as audio_file:
translate = openai.Audio.translate(
file = audio_file,
model = "whisper-1",
response_format="text",
language="en"
)
print(translate)What do you think artificial intelligence is? What do I think it is? I don't know how to describe it. Something that is not natural, obviously. Artificial intelligence is, through data, introduced to an algorithm.Try this example by heading to this DataLab workbook. It has audio files and a code source. You just have to make a copy of the workbook and set up an environment variable for it to work.
Also, check out Using ChatGPT via the OpenAI API in the Python tutorial. It will teach you how to use OpenAI API for chat completions using the gpt-3.5-turbo model.
How to Improve Transcription Performance?
We can improve the quality of transcription by using a prompt argument. By providing partial transcription in the prompt argument, we are helping the model to understand writing style, punctuation, capitalization, and spelling.
A major drawback of the current prompting system is that it offers little control over the generated text. Moreover, the prompting process cannot be automated, since it involves a human partially transcribing the audio manually.
What’s Next?
You can use the code example from this tutorial to create a voice assistant or use it to create J.A.R.V.I.S. from Iron Man. To achieve that, you just have to figure out the user interface and how to combine Whisper, text-to-speech, and ChatGPT API, which we have covered in this live training.
If you are new to ChatGPT, you can take the Introduction to ChatGPT course to learn best practices for writing prompts and translate ChatGPT Into business value. And If you are interested in learning about GPT-4 and how the generative models work, read What is GPT-4 and Why Does it Matter? You can also find some more resources below:
- [Webinar] A beginner’s guide to prompt engineering with ChatGPT
- [Cheat Sheet] ChatGPT Cheat Sheet for Data Scientists
- [Cheat Sheet] The OpenAI API in Python
- [Podcast] ChatGPT and How Generative AI is Augmenting Workflows
- Start learning AI with DataCamp



