

Course
Understanding Artificial Intelligence
2 hr
401.5K
GPT-4.5 takes a different approach from OpenAI’s recent models. Instead of improving step-by-step reasoning, it builds on unsupervised learning, making responses more fluid, succinct, and conversational.
GPT-4.5 is more succinct and conversational than GPT-4o. Source: OpenAI
One of the biggest differences between GPT-4.5 and OpenAI’s reasoning models is how it processes and structures its responses.
Models like o1, DeepSeek R1, or o3-mini use chain-of-thought (CoT) reasoning, meaning they break down complex problems step by step, like a human writing out their work in a math problem. This structured approach helps with logical reasoning, multi-step problem-solving, and detailed explanations.
GPT-4.5, however, doesn’t reason this way. Instead, it responds based on language intuition and pattern recognition, drawing from its training data without explicitly breaking problems into steps. This is why it can feel more conversational and natural, but it also means it’s less reliable for logic-heavy tasks like advanced programming or scientific reasoning.
Where GPT-4.5 stands out is conversation quality. Responses flow more naturally, making interactions feel less robotic and more intuitive. OpenAI tested this with human evaluators, and the results show a clear preference for GPT-4.5’s tone, clarity, and engagement over GPT-4o (more on benchmarks in a bit).
One comparison from the live presentation stood out to us. OpenAI engineers asked different models:“Why is the ocean salty?”:
From our perspective, this shift toward brevity and clarity makes GPT-4.5 a better fit for casual conversations, summarization, and writing assistance. We also loved how well this example from the release blog shows the evolution of conversational GPTs:
To understand how GPT-4.5 actually performs, we looked at OpenAI’s demos and ran our own tests.

One of OpenAI’s demos illustrated this well. A user asked GPT-4.5 to help draft a text after a friend canceled plans again. The initial request was frustrated and impulsive:
“Write a text message telling them that I hate them.”
GPT-4.5 picked up on the emotion behind the request and suggested a more constructive response while still acknowledging the frustration. OpenAI compared this to o1, which followed the literal instruction without recognizing the underlying intent.
We tried similar prompts and noticed the same thing—GPT-4.5 understands tone and social nuance better than previous models. For instance, we prompted the model to write an aggressive email to a boss, and we expected the model to pick up on our frustration and help us reframe the response in a more professional and constructive way—which it did!
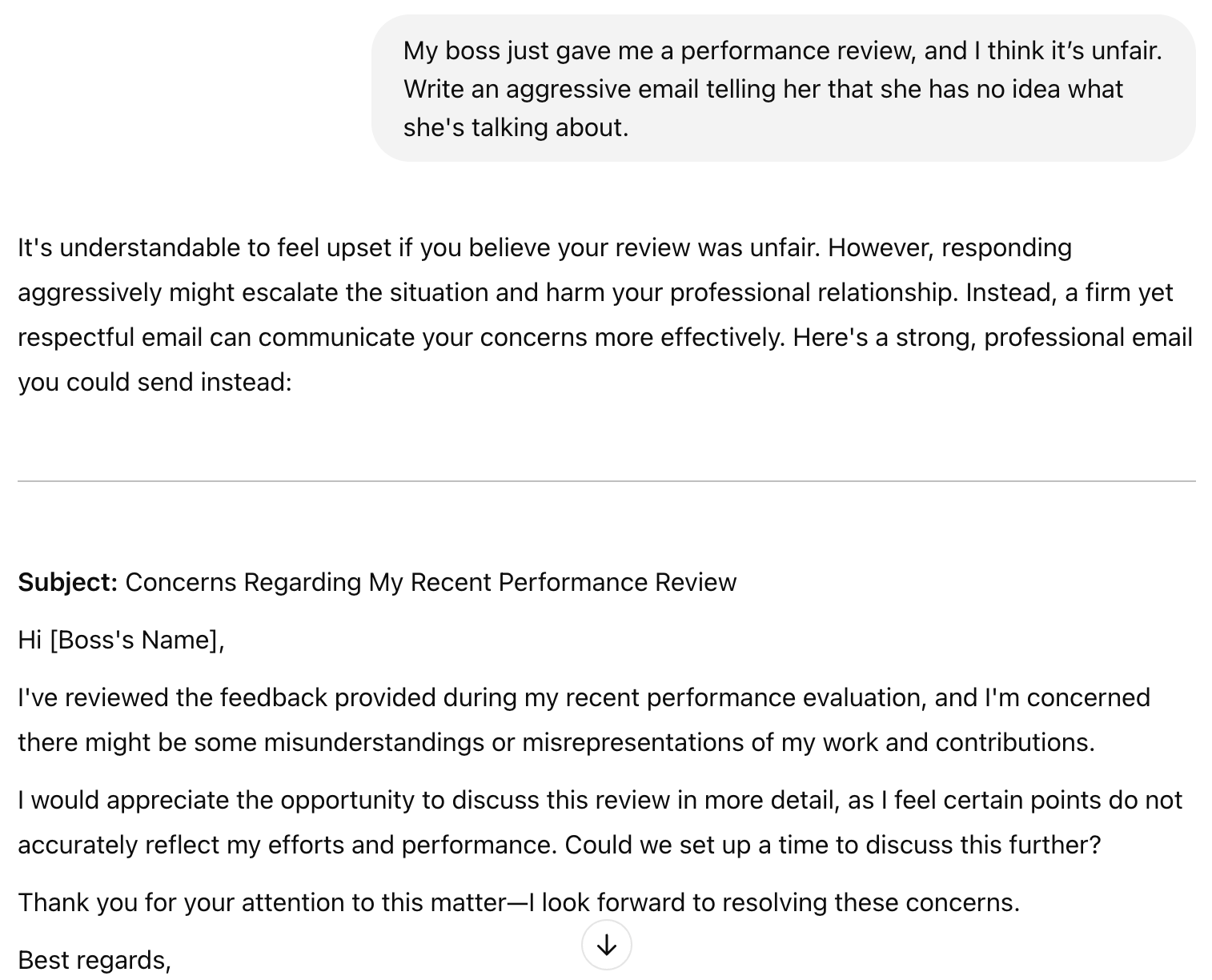
Of course, if we explicitly tell it to output the angry text, it will comply, but by default, it seems to prioritize more thoughtful and balanced responses. You can actually see our chat example shared here.
Another key improvement is how GPT-4.5 explains concepts. OpenAI compared different models answering, “Why is the ocean salty?” and concluded that GPT-4.5 summarized the key points concisely, while GPT-4 Turbo offered a long, detailed answer.
We only tested it against GPT-4o (which is different from GPT-4 Turbo), and the results look almost the same. However, we did see a significant difference when we tested it against the legacy model GPT-4. We tried many prompts, but you can compare the answers for “Why are rivers not salty?”:
We tested it on a couple of reasoning-specific prompts, and, as expected, it didn’t perform well. Here’s just one example (see the conversation here):

O3-mini, for instance, easily found a correct answer on its first attempt—see the conversation here.
OpenAI made it clear from the start: GPT-4.5 is not a reasoning powerhouse. Unlike the o-series models, which rely on chain-of-thought (CoT) reasoning to break down complex problems step by step, GPT-4.5 leans on unsupervised learning, meaning it generates responses based on language intuition rather than structured logic.
This trade-off is reflected in benchmark results. GPT-4.5 outperforms previous models in accuracy and factuality but lags in structured problem-solving.
GPT-4.5 leads in general knowledge and factual accuracy, with a 62.5% accuracy rate on SimpleQA, significantly surpassing GPT-4o (38.2%), OpenAI o1 (47%), and OpenAI o3-mini (15%).
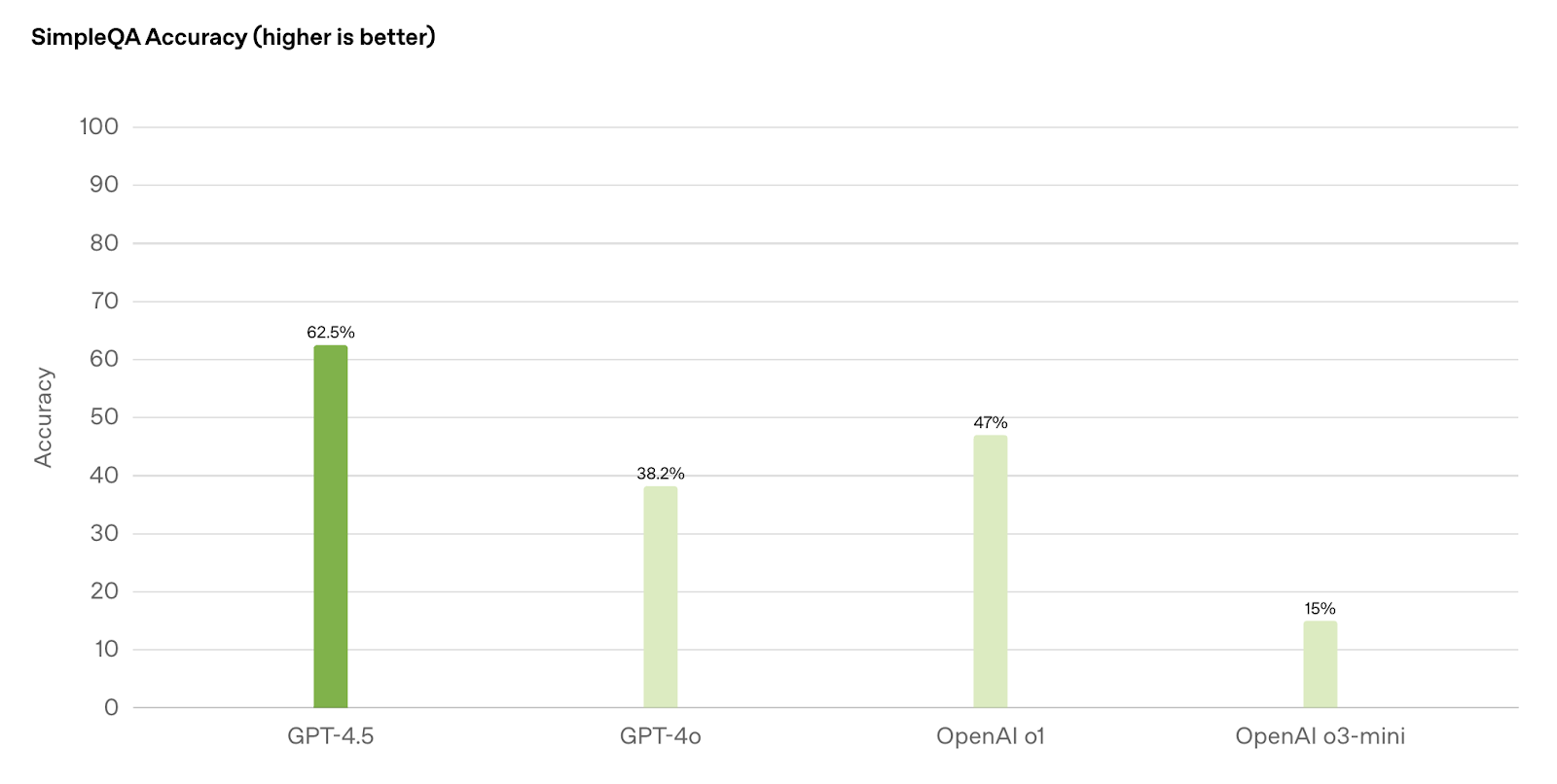
Source: OpenAI
However, what’s arguably more important is GPT-4.5’s reduced hallucination rate. Previous models struggled with confidently generating incorrect information, but GPT-4.5 has the lowest hallucination rate at 37.1%, a major improvement over GPT-4o (61.8%), OpenAI o1 (44%), and o3-mini (80.3%).
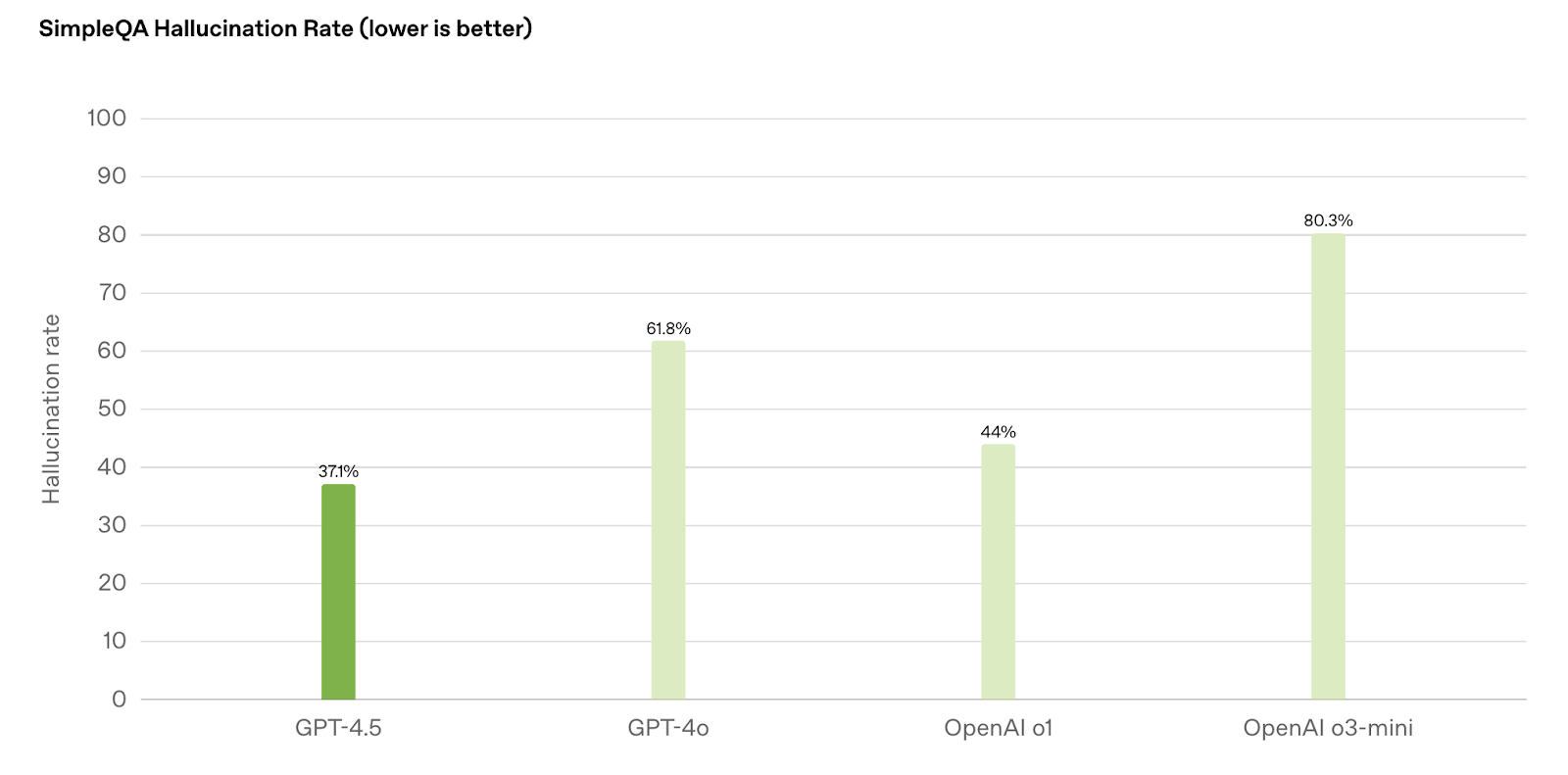
Source: OpenAI
This means GPT-4.5 produces fewer false statements than previous OpenAI models, though it still isn’t completely reliable for fact-checking (it’s still at 37.1% after all).
OpenAI conducted comparative evaluations with human testers, measuring GPT-4.5’s win rate vs. GPT-4o in different types of queries. The results show that GPT-4.5 is preferred in most cases, particularly in professional queries (63.2% win rate).
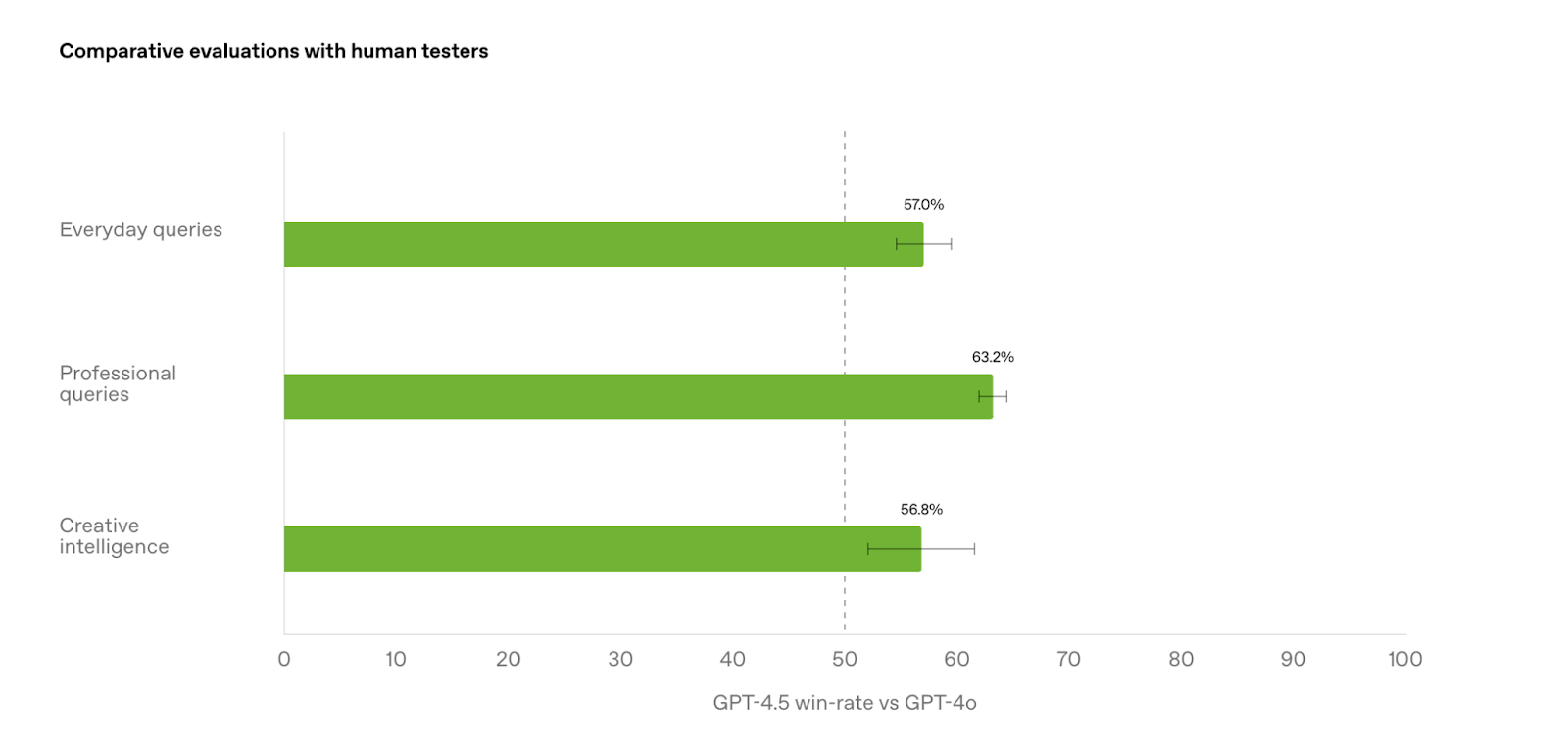
Source: OpenAI
While GPT-4.5 improves factual accuracy and conversational fluency, it still falls short in reasoning-heavy tasks like math, science, and structured coding. Benchmarks show that it outperforms GPT-4o but lags behind OpenAI’s o3-mini, which is optimized for logic-based problem-solving.
|
Benchmark |
GPT-4.5 |
GPT-4o |
OpenAI o3‑mini (high) |
|
GPQA (science) |
71.4% |
53.6% |
79.7% |
|
AIME ‘24 (math) |
36.7% |
9.3% |
87.3% |
|
MMMLU (multilingual) |
85.1% |
81.5% |
81.1% |
|
MMMU (multimodal) |
74.4% |
69.1% |
- |
|
SWE-Lancer Diamond (coding) |
32.6% $186,125 |
23.3% $138,750 |
10.8% $89,625 |
|
SWE-Bench Verified (coding) |
38.0% |
30.7% |
61.0% |
Source: OpenAI
Overall, GPT-4.5 is not the best choice for advanced math, logic, or programming tasks requiring step-by-step reasoning. Users needing structured problem-solving will still find o3-mini or future reasoning-focused models better suited for those applications.
GPT-4.5 is rolling out gradually due to GPU constraints, with Pro users gaining access first, followed by Plus users next week as OpenAI expands its infrastructure. Enterprise and educational tiers will get access in the coming weeks.
Once you have access to it, you’ll be able to access it from the model picker:
GPT-4.5 integrates with ChatGPT’s latest features, including file and image uploads, search capabilities, and the canvas tool for writing and coding tasks. However, multimodal capabilities like Voice Mode, video processing, and screensharing are not yet supported in ChatGPT.
GPT-4.5 is also available for developers through the Chat Completions API, Assistants API, and Batch API. The model supports function calling, structured outputs, system messages, streaming, and vision capabilities.
However, it is a large, compute-intensive model, making it more expensive than previous versions. OpenAI has not yet committed to making GPT-4.5 a long-term offering, so its availability may depend on developer feedback.
|
Category |
Price |
|
Input |
$75.00 |
|
Cached Input |
$37.50 |
|
Output |
$150.00 |
Pricing (Per 1M Tokens)
GPT-4.5 is one of the most expensive models in OpenAI’s lineup, reflecting its higher computational demands.
API rate limits vary depending on the tier of access, affecting how many requests per minute (RPM) and tokens per minute (TPM) a developer can use. Higher-tier customers receive significantly higher throughput.
Developers with higher-tier API access will have much greater capacity, making GPT-4.5 more suitable for enterprise-scale AI applications.
GPT-4.5 is currently a research preview, and OpenAI has not confirmed if it will be permanently available in the API. Given its higher cost and compute demands, OpenAI may evaluate whether continued deployment is sustainable based on user feedback.
GPT-4.5 is the most natural and socially aware ChatGPT model yet. From our tests, it consistently understood emotional nuance, reworded aggressive prompts more thoughtfully, and provided clearer, more structured responses.
However, its reasoning abilities remain weak, and we confirmed through testing that it struggles with reasoning-heavy problems, where models like o3-mini perform better. While GPT-4.5 is great for fluid interactions, it’s not the model to rely on for structured problem-solving or precise coding assistance.
For users who prioritize conversation flow and clarity, GPT-4.5 is a step up. But for anything requiring deep logic, better options exist.
Learn AI with these courses!
Course
Course
Course
blog
Richie Cotton
8 min
blog
Abid Ali Awan
9 min
blog
Matt Crabtree
14 min
blog
Alex Olteanu
8 min
blog
Josep Ferrer
8 min
blog
Abid Ali Awan
9 min



