
Course
Generative AI Concepts
2 hr
105.1K
The SOLAR-10.7B project represents a significant leap forward in the development of large language models, introducing a new approach to scaling these models in an effective and efficient manner.
This article starts by explaining what the SOLAR-10.7 B model is before highlighting its performance against other large language models and diving into the process of using its specialized fine-tuned version. Lastly, the reader will understand the potential applications of the fine-tuned SOLAR-10.7 B-Instruct model and its limitations.
SOLAR-10.7B is a 10.7 billion parameters model developed by a team at Upstage AI in South Korea.
Based on the Llama-2 architecture, this model surpasses other large language models with up to 30 billion parameters, including the Mixtral 8X7B model.
To learn more about Llama-2, our article Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model provides a step-by-step guide to fine-tune Llama-2, using new approaches to overcome memory and computing limitations for better access to open-source large language models.
Furthermore, building upon the robust foundation of SOLAR-10.7B, the SOLAR 10.7B-Instruct model is fine-tuned with an emphasis on following complex instructions. This variant demonstrates enhanced performance, showcasing the model's adaptability and the effectiveness of fine-tuning in achieving specialized objectives.
Finally, SOLAR-10.7B introduces a method called Depth Up-Scaling, and let’s further explore that in the following section.
This innovative method allows for the expansion of the model's neural network depth without requiring a corresponding increase in computational resources. Such a strategy enhances both the efficiency and the overall performance of the model.
The Depth Up-Scaling is based on three main components: (1) Mistral 7B weight, (2) Llama 2 framework, and (3) Continuous pre-training.
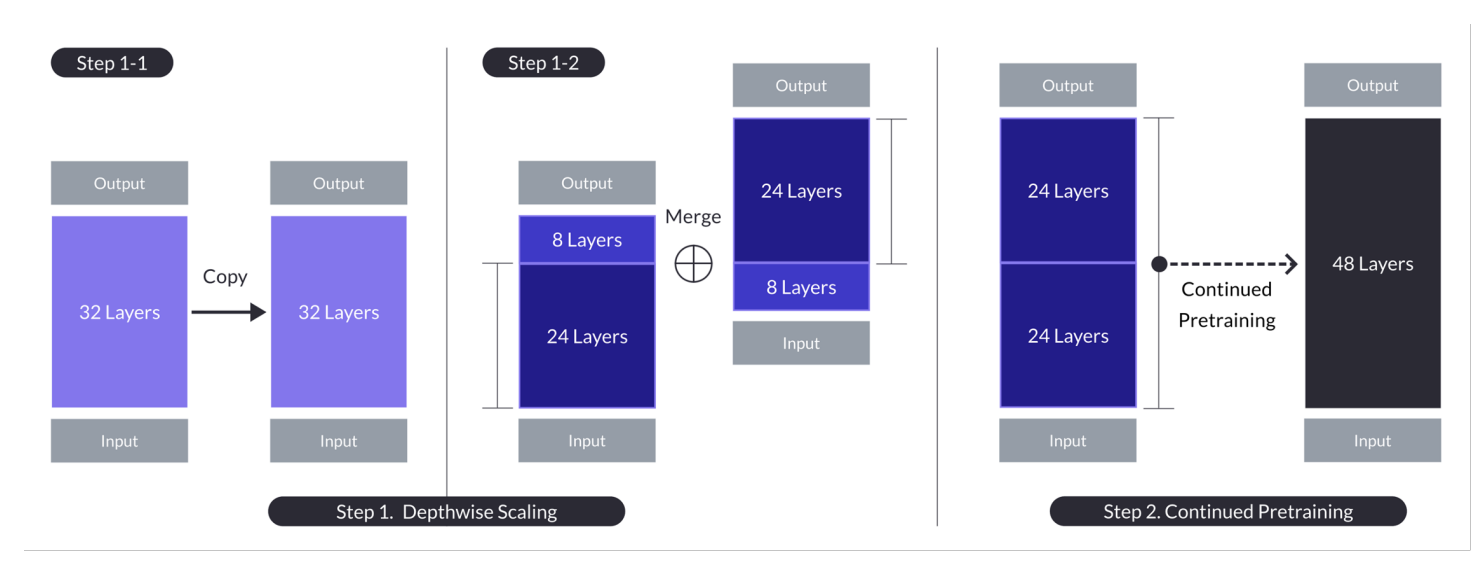
Depth up-scaling for the case with n = 32, s = 48, and m = 8. Depth up-scaling is achieved through a dual-stage process of depthwise scaling followed by continued pretraining. (Source)
Base Model:
Depthwise Scaling:
Continued Pretraining:
These summaries highlight the key strategies and outcomes of the Depth Up-Scaling approach, focusing on leveraging existing models, scaling through depth adjustment, and enhancing performance through continued pretraining.
This multifaceted approach SOLAR-10.7B achieves and, in many cases, exceeds the capabilities of much larger models. This efficiency makes it a prime choice for a range of specific applications, showcasing its strength and flexibility.
SOLAR-10.7B instruct excels at interpreting and executing complex instructions, making it incredibly valuable in scenarios where precise understanding and responsiveness to human commands are crucial. This capability is essential for developing more intuitive and interactive AI systems.
Overall, the fine-tuned SOLAR-10.7B model's importance lies in its enhanced performance, adaptability, and potential for widespread application, driving forward the fields of natural language processing and artificial intelligence.
Before diving into the technical implementation, let’s explore some of the potential applications of a fine-tuned SOLAR-10.7B model.
Below are some examples of personalized education and tutoring, enhanced customer support, and automated content creation.
These examples underscore the versatility and potential of SOLAR-10.7B-Instruct to impact and improve efficiency, accessibility, and user experience across a broad spectrum of industries.
We have enough background about the SOLAR-10.7B model, and it is time to get our hands dirty.
This section aims to provide all the instructions to run the SOLAR 10.7 Instruct v1.0 - GGUF model from upstage.
The codes are inspired by the official documentation on Hugging Face. The main steps are defined below:
The main libraries used are transformers and accelerate.
%%bash
pip -q install transformers==4.35.2
pip -q install accelerateNow that the installation is completed, we proceed by importing the following necessary libraries:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizerThe model being used is the version 1 of the SOLAR-10.7B model from Hugging Face.
A GPU resource is necessary for speeding up the model loading and inference process.
The access to GPU on Google Colab is illustrated in the graphic below:
This will switch the default runtime to T4:
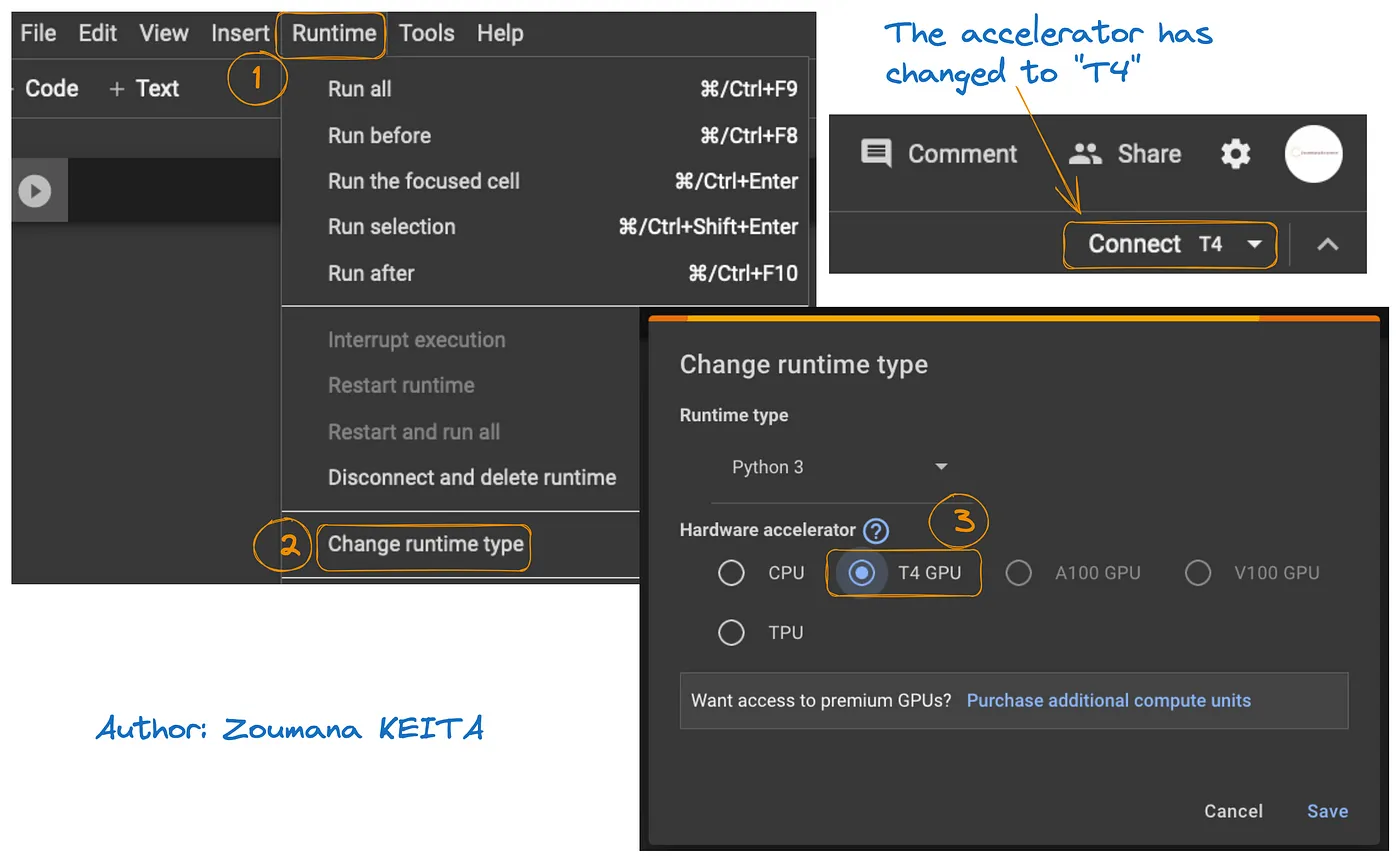
We can check the properties of the runtime by running the following command from the Colab notebook.
!nvidia-smi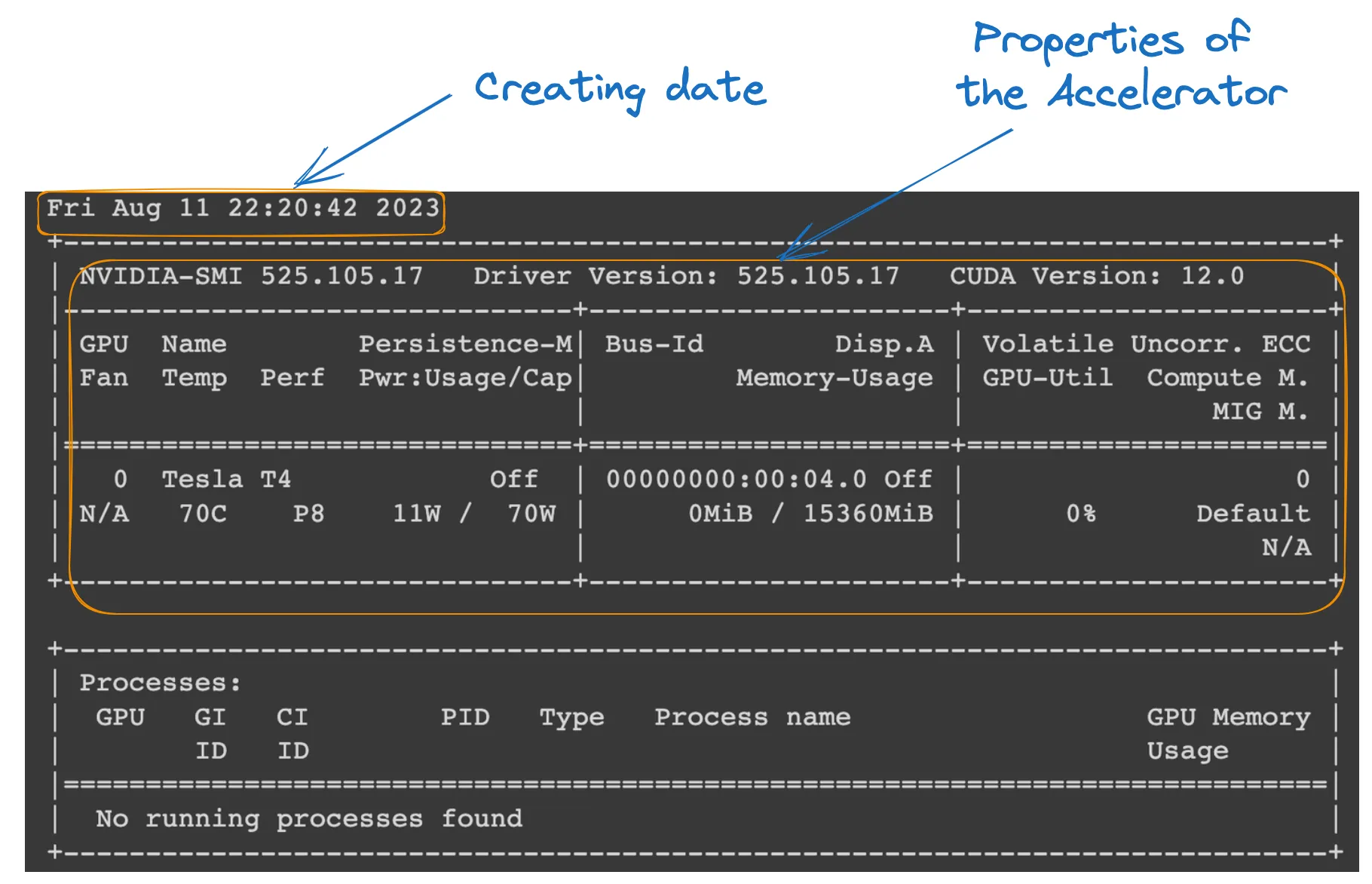
GPU properties
Everything is set up; we can further with the loading of the model as follows:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_ID)
model = AutoModelForCausalLM.from_pretrained(
model_ID,
device_map="auto",
torch_dtype=torch.float16,
)Before generating a response, the input text (user's request) is formatted and tokenized.
user_request = "What is the square root of 24?"
conversation = [ {'role': 'user', 'content': user_request} ]
prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)The final section uses the model to generate a response to the input question and then decodes and prints the generated text.
outputs = model.generate(**inputs, use_cache=True, max_length=4096)
output_text = tokenizer.decode(outputs[0])
print(output_text)The successful execution of the code above generates the following result:

By replacing the user request with the following text, we get the response generated
user_request = "Tell me a story about the universe"
Despite all the benefits of the SOLAR-10.7B, it has its own limitations like any other large language model, and the main ones are highlighted below:
This article has explored the SOLAR-10.7B model, highlighting its contribution to artificial intelligence through the depth up-scaling approach. It has outlined the model’s operation and potential applications, and provided a practical guide for its use, from installation to generating results.
Despite its capabilities, the article also addressed the SOLAR-10.7B model's limitations, ensuring a well-rounded perspective for users. As AI continues to evolve, SOLAR-10.7B exemplifies the strides made toward more accessible and versatile AI tools.
For those looking to delve deeper into AI's potential, our tutorial, FLAN-T5 Tutorial: Guide and Fine-Tuning, offers a complete guide to fine-tuning a FLAN-T5 model for a question-answering task using transformers library and running optimized inference on a real-world scenario. You can also find our Fine-Tuning GPT-3.5 tutorial and our code-along on fine-tuning your own LlaMA 2 model.
Start Your AI Journey Today!
Course
Course
Course
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan



