
Course
Introduction to Statistics in R
4 hr
130.4K
Outliers can often misdirect your insights, turning what should be a meaningful analysis into a misleading conclusion. Imperfect and noisy data are expected in real-world scenarios, and winsorization is one practical solution to reduce the impact of outliers without discarding any data.
This article will explore how the winsorized mean works, its practical applications, and the steps to calculate it using Python. We’ll also understand its pros and cons, compare it with other useful measures such as trimmed mean, and explore other winsorization statistical measures.
A winsorized mean is a statistical measure that reduces the impact of outliers by replacing extreme values with less extreme percentiles rather than completely removing them. Unlike the arithmetic mean, which considers all data points equally, the winsorized mean limits the influence of extreme values that can distort the overall result.
Winsorization works by capping or replacing values beyond a certain percentile threshold. For example, in a 5% winsorization, the lowest 5% of data points are replaced by the value at the 5th percentile, and the highest 5% are replaced by the value at the 95th percentile. This method helps retain the dataset’s overall structure while reducing the effect of outliers, making it a robust alternative to the standard mean in datasets that contain extreme values.
The relevance of the winsorized mean in statistical analysis is particularly evident in fields where data is prone to skewed distributions. Here are some key areas where the winsorized mean proves helpful:
In each of these applications, the winsorized mean is a robust alternative to the standard mean, allowing analysts to gain insights less affected by outliers while preserving important data patterns.
Calculating the winsorized mean in Python involves replacing the extreme values (outliers) with values at specific percentiles. Before starting, a quick summary of the steps we’ll follow:
Import the required libraries and dataset.
Winsorize the dataset using scipy.winsorize().
Calculate the mean using numpy.mean().
Let’s dive into the details with an example.
First, we shall import the libraries needed to calculate the mean.
import numpy as np
from scipy.stats.mstats import winsorizeNext, we load the dataset, which can be from a CSV file or any other data source. For the simplicity of the example, we shall create a sample dataset using numpy.
data = np.array([10, 12, 14, 15, 16, 18, 20, 22, 24, 25, 30, 35, 40, 45, 50, 60, 70, 80, 82, 85, 90, 200])The 200 might be considered an outlier in this dataset based on an initial analysis.
The winsorize() function from the scipy library allows you to specify the percentage of data to winsorize from both the lower and upper tails. The code to do so is as follows:
# Winsorize 5% from both the lower and upper tails
winsorized_data = winsorize(data, limits=[0.05, 0.05])In the code above, the limits=[0.05, 0.05] parameter fed to the winsorize() function replaces the smallest 5% and largest 5% of values with the values at the 5th and 95th percentiles, respectively. We can now inspect the winsorized data we have created.
print("Original data: ", data)
print("Winsorized data: ", winsorized_data)The output will show that the outliers have been replaced:
Original data: [ 10 12 14 15 16 18 20 22 24 25 30 35 40 45 50 60 70 80 82 90 200]
Winsorized data: [ 12 12 14 15 16 18 20 22 24 25 30 35 40 45 50 60 70 80 82 90 90]Here, the maximum value 200 has been replaced with 90; similarly, extreme values from the lower end, 10, have been replaced by 12.
Finally, let’s calculate the mean of the winsorized data:
winsorized_mean = np.mean(winsorized_data)
print("Winsorized mean: ", winsorized_mean)The output is as follows:
Winsorized mean: 42.5The winsorized mean has reduced the influence of the extremely high values compared to a regular mean. For comparison, we can calculate the original mean as follows:
original_mean = np.mean(data)
print("Original mean: ", original_mean)The output is as follows:
Original mean: 47.40909090909091The outliers heavily influence the original mean at 47.40, causing it to be significantly higher. After winsorizing the extreme values, the winsorized mean is much lower at 42.5 with lesser influence of the extreme values.
The winsorized mean and trimmed mean are both statistical methods used to reduce the effect of outliers on the mean, but they differ in how they handle extreme values:
The winsorized mean is preferred when you want to preserve the data structure (i.e., keep the sample size the same) but still reduce the effect of extreme values. The trimmed mean is preferred when the dataset contains clear outliers you want to remove entirely and when a smaller sample size after trimming is acceptable.
Let’s see how both methods affect the dataset and compare their results.
from scipy.stats import trim_mean
# Calculate the Trimmed mean by removing 5% from both tails
trimmed_mean = trim_mean(data, proportiontocut=0.05)
# Print the results
print("Original mean: ", np.mean(data))
print("Winsorized mean (5%): ", winsorized_mean)
print("Trimmed mean (5%): ", trimmed_mean)The output is as follows:
Original mean: 47.40909090909091
Winsorized mean (5%): 42.5
Trimmed mean (5%): 41.65The original mean was 47.4, heavily influenced by outliers. The winsorized mean, 42.5, was calculated with outliers replaced with less extreme values. The Trimmed mean, when the outliers were removed completely, is 41.65.
Use winsorized mean when you want to keep all the data points but reduce the impact of extreme values. This is a good heuristic because the winsorized mean is useful when you believe the outliers are genuine but want to minimize their influence.
Use the trimmed mean when you want to remove outliers from the dataset altogether. Trimmed mean is most useful when you suspect the outliers are erroneous or not representative of the data distribution.
The summarized differences can be tabulated as below:
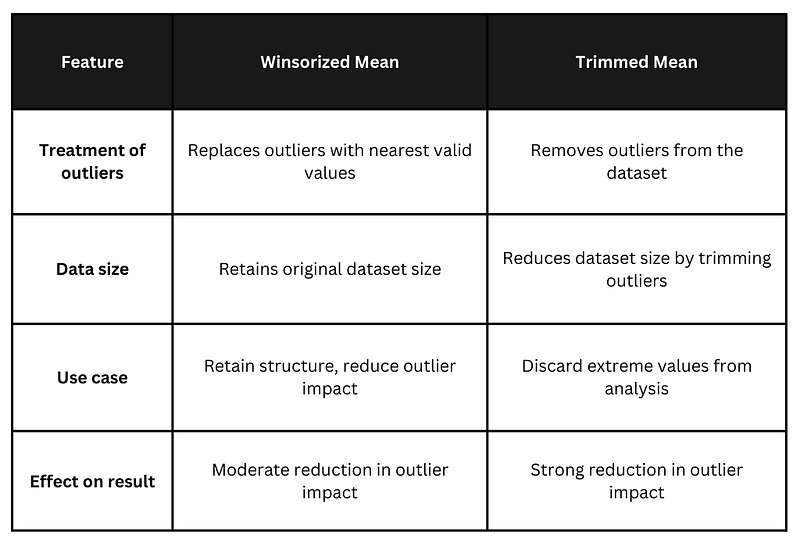 Key differences between winsorized mean vs. trimmed mean. Image by Author.
Key differences between winsorized mean vs. trimmed mean. Image by Author.
Winsorized and trimmed means help handle outliers, but the choice depends on whether you want to retain or discard extreme values from the dataset.
While the winsorization process is a robust approach to handling outliers, modifying extreme values might raise concerns about data manipulation. Here are some advantages and drawbacks of the technique:
Thus, it’s important to consider the pros and cons of using the technique before incorporating it into our data analysis projects.
Since winsorization is a statistical technique applied to a measure, it can be extended to other usual statistical measures. Let’s explore some other measures which winsorization can be applied to:
Each of these winsorized measures helps reduce the influence of outliers on the analysis when working with non-normal data or datasets with extreme values.
This tutorial introduced a statistical measure to handle outliers: the winsorized mean. We learned the concept of winsorization, its practical applications, and a hands-on implementation on a sample dataset. Further, the tutorial covered the trimmed mean, its implementation, and how it differs from the winsorized mean. It also explored the pros, cons, and other statistical concepts based on winsorization.
As we have seen, winsorized mean balances discarding outliers and keeping them, allowing for more reliable results in skewed datasets. We encourage you to use the technique in your data analysis projects, experimenting with different winsorization levels to find what works best for specific datasets.
Check out our Intermediate Predictive Analytics in Python course to learn more about handling outliers in datasets using Python, including winsorization. You can also explore our Machine Learning Scientist with Python career track, which is a great way to practice by building some actual models.
Learn with DataCamp
Course
Course
Course
podcast
Tutorial
Daniel Poston
Tutorial
Aditya Sharma
Tutorial
Conor O'Sullivan
Tutorial
DataCamp Team
Tutorial
Sayak Paul
