
Track
Data Engineer in Python
40 hr
Apache Airflow 3.0 is finally here, and it is easily the most significant release in the project’s history.
This release will reshape how you think about managing workflows, regardless of whether you are new to data or have been working with Airflow for years.
After exploring the new version firsthand, I can confidently say this is far more than just an incremental update.
Some of the top highlights include:
This guide will walk you through Airflow 3.0 and everything it has to offer.
Apache Airflow is an open-source platform that helps users programmatically author, schedule, and monitor data workflows.
It has been the go-to orchestrator for complex ETL pipelines, data engineering workflows, and, more recently, machine learning pipelines.
The foundational concept in Airflow is the DAG (a Directed Acyclic Graph that defines a sequence of tasks and their dependencies).
Tasks can range from Python scripts to SQL transformations and even containerized operations when it comes to using Airflow.
The platform is flexible, extensible, and now, with 3.0, more future-proof than ever.
If you are just getting started with Airflow, the Introduction to Apache Airflow in Python course is a great resource that provides hands-on experience.
Airflow was initially developed by Airbnb in 2014 and open-sourced in 2015.
It later became an Apache project and has since become one of the most widely adopted orchestration tools in the data engineering ecosystem.
It is clear from the image below that GitHub contributions have significantly increased year-over-year, which shows that Apache Airflow is one of the most active open-source projects in the data orchestration space.
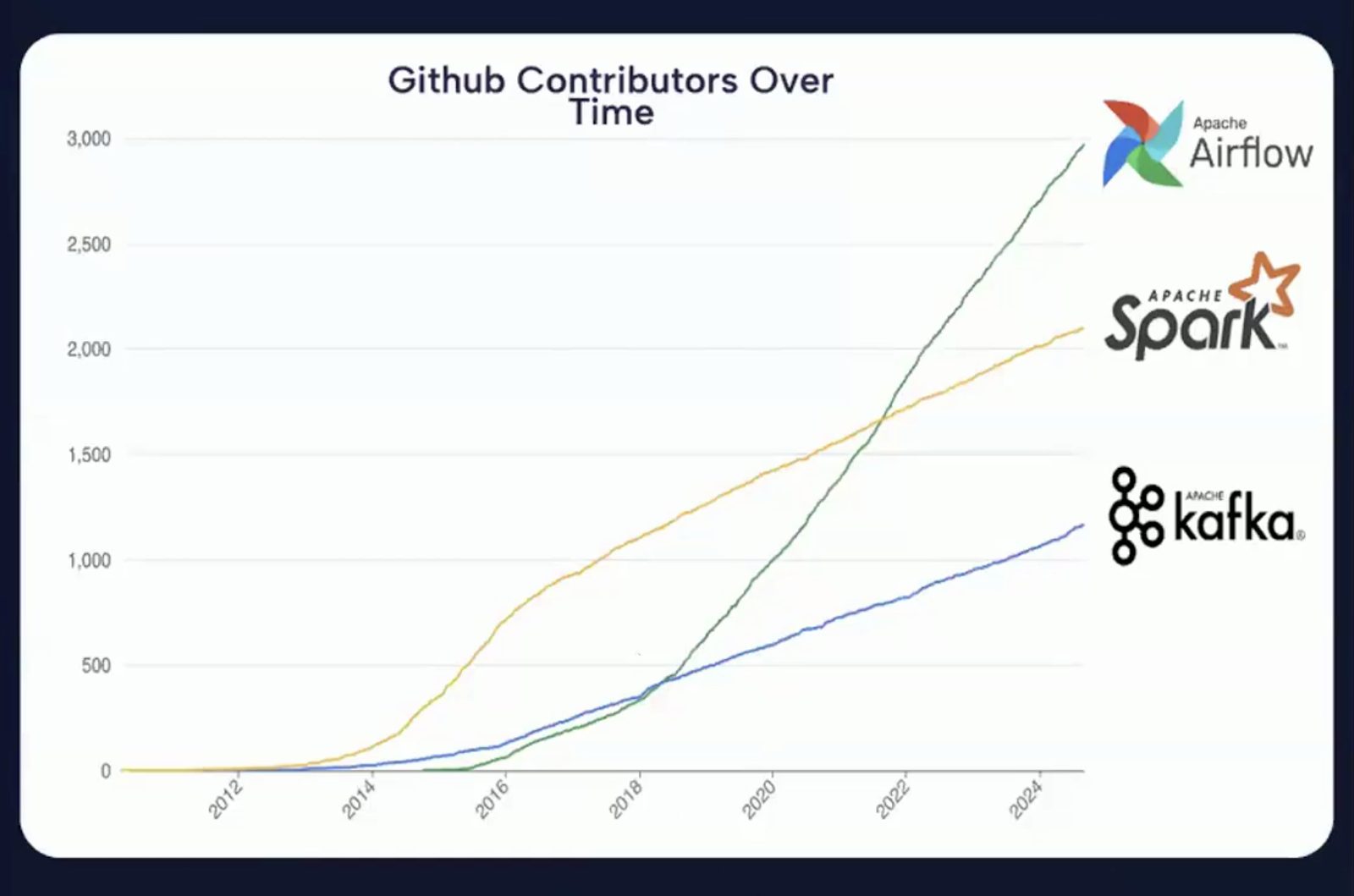
Chart showing the increasing number of GitHub contributions to Apache Airflow over the years. Source: Airflow 3.0 Introduction Video
Apache Airflow 3.0 is a release grounded in three foundational themes.
Screenshot of the Apache Airflow 3.0 release page. Source: Apache Airflow
These themes reflect the project’s vision to meet the demands of modern data platforms, enhance developer experience, and strengthen Airflow’s position as a central orchestrator in distributed, hybrid, and ML-powered environments.
The key themes can be broadly categorized as follows:
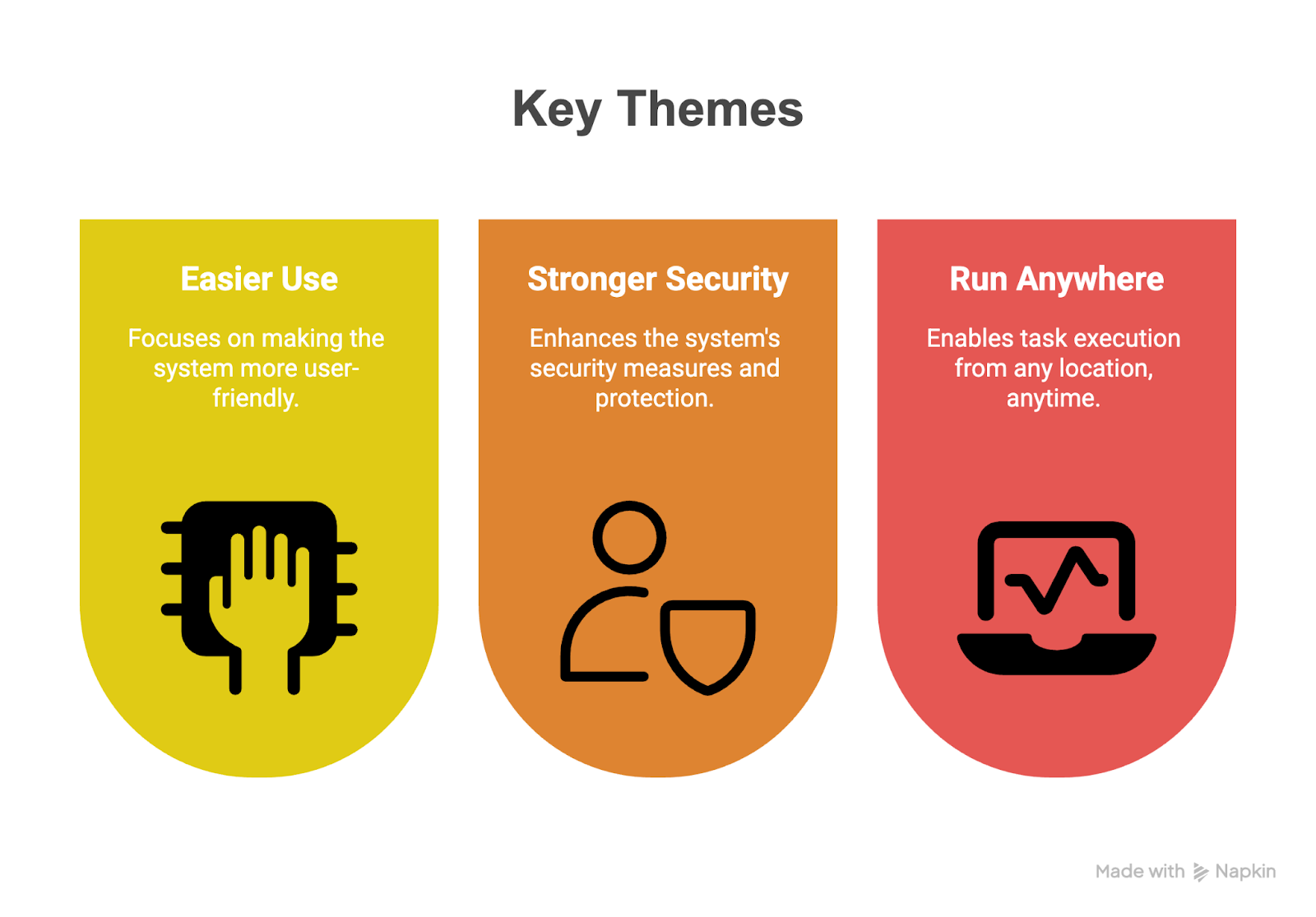
Image summarizing the three core themes of Apache Airflow 3.0. Image created using Napkin AI
One of the most significant objectives of the 3.0 release is to improve usability across the board, from the command line to the user interface and underlying API interactions.
Airflow is now easier to learn, more enjoyable to use daily, and better equipped to support complex operational requirements.
Security has become a central concern in data engineering, especially as a result of growing privacy regulations and the scale of data infrastructure.
Airflow 3.0 addresses these concerns with deeper architectural support for task isolation and execution control.
Security improvements in Airflow 3.0 are both proactive and strategic, which aligns with the needs of enterprise deployments, highly regulated industries, and modern DevSecOps practices.
The modern data stack is no longer confined to on-premises data centers or even centralized cloud environments.
Airflow 3.0 meets this challenge with support for diverse deployment topologies and execution patterns.
Enabling tasks to run anywhere (and supporting workflows that execute anytime) provides unmatched flexibility, resilience, and scalability for orchestrating the modern data lifecycle.
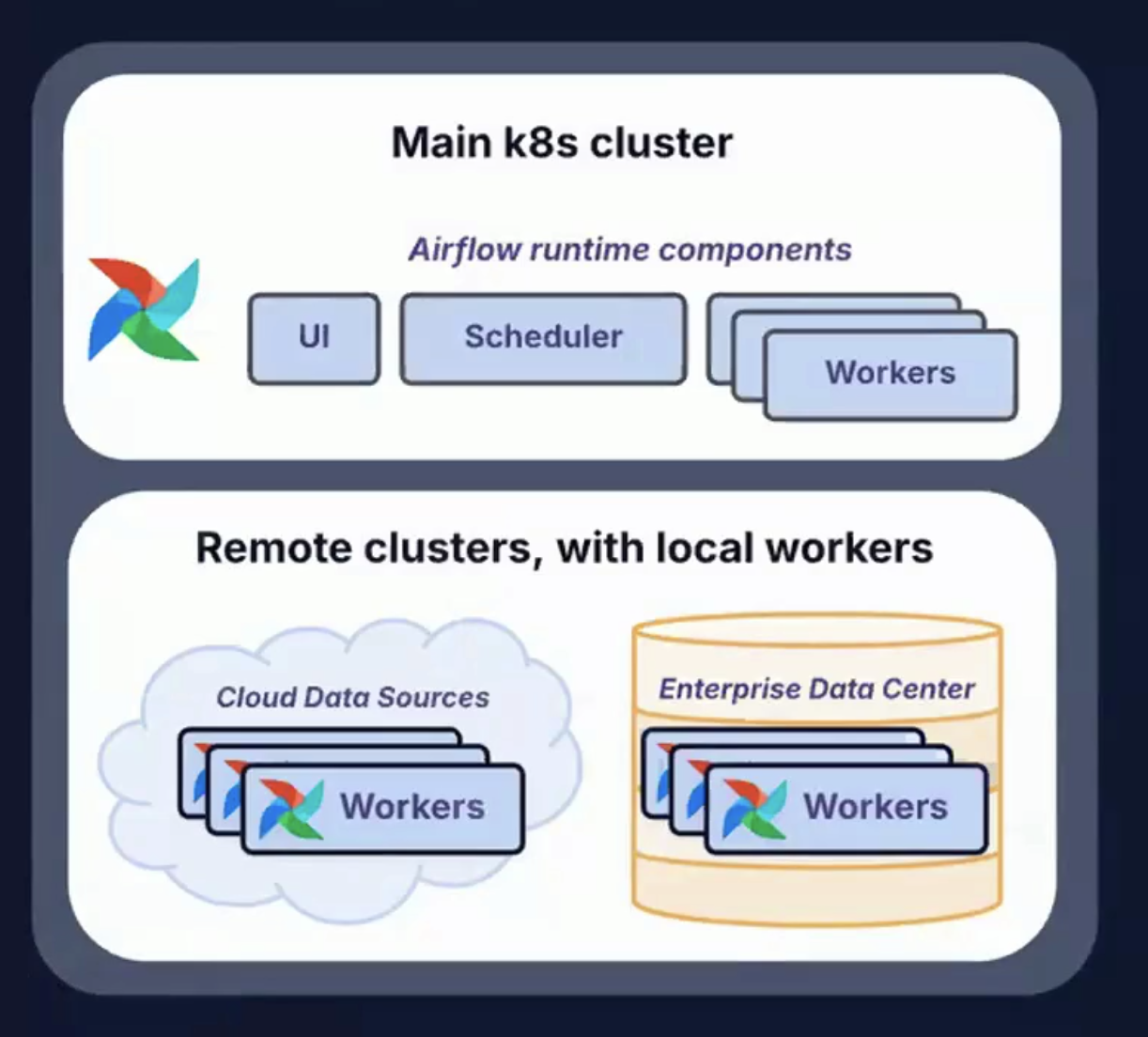
Image showing remote clusters with local workers, used to run anywhere, anytime. Source: Airflow 3.0 Astronomer Introduction Video
The rest of this guide will cover aspects of the key theme of Airflow 3.0 in more detail.
Apache Airflow 3.0 release reimagines how tasks are executed, where they can be run, and how developers and operators interact with the system.
The focus is on decoupling, modularization, scalability, and deployment flexibility, enabling Airflow to meet the demands of hybrid and multi-cloud data platforms.
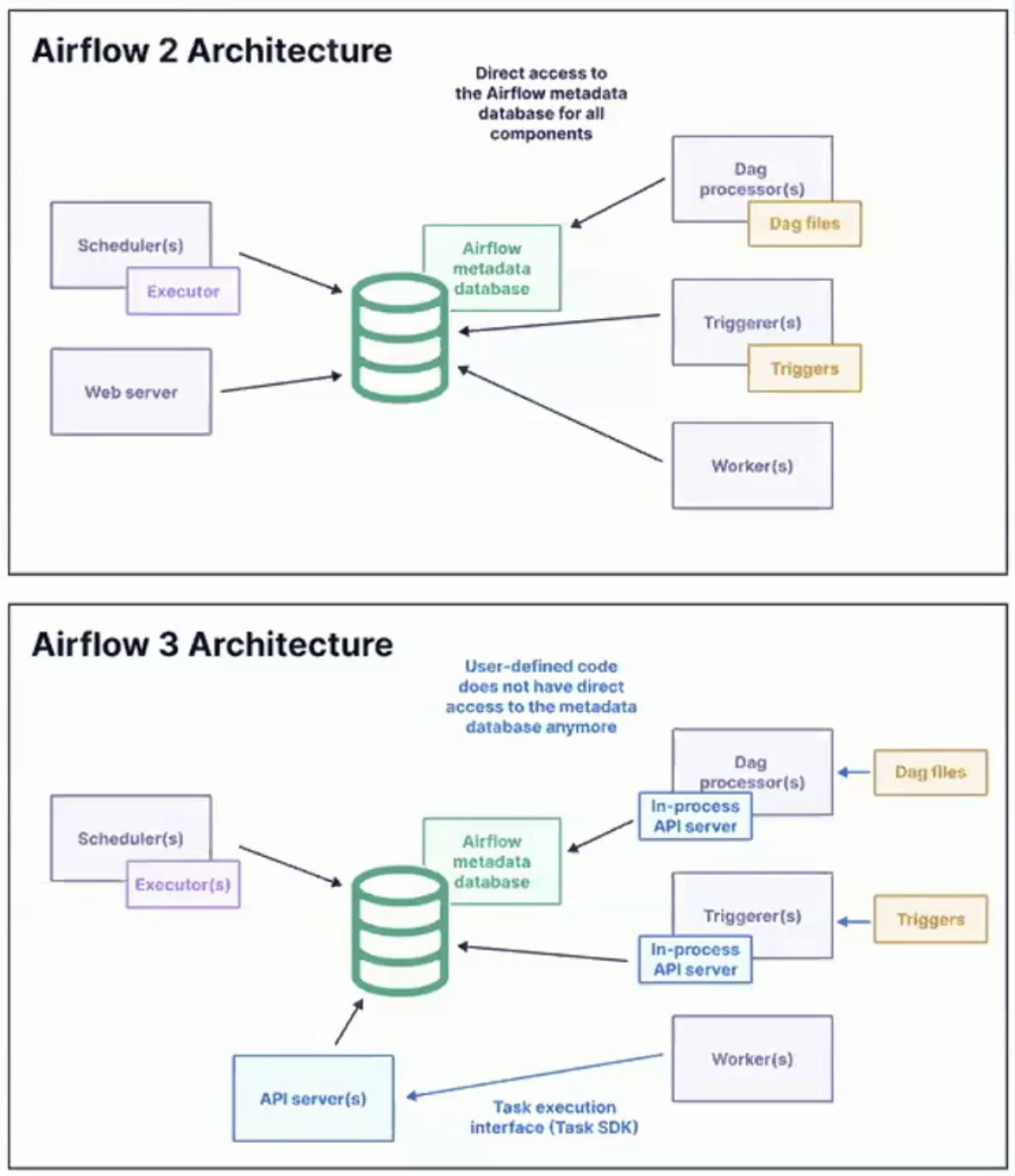
Image showing architecture for Airflow 2 and Airflow 3. Source: Airflow 3.0 Astronomer Introduction Video
One of the most important innovations in Airflow 3.0 is the introduction of a Task Execution API and an accompanying Task SDK.
These components enable tasks to be defined and executed independently of Airflow’s core runtime engine.
Here are some key implications of this:
This architecture is a major leap forward in making Airflow more flexible and cloud-native.
It aligns with the broader shift in data engineering towards language diversity, containerization, and task-level reproducibility.
The Edge Executor is another addition to Airflow 3.0 that is transformative.
It is designed to enable event-driven and geographically distributed execution of tasks.
Rather than requiring all executions to occur in a centralized cluster, the Edge Executor allows tasks to run at or near the data source.
Some of the key benefits of Edge Execution include:
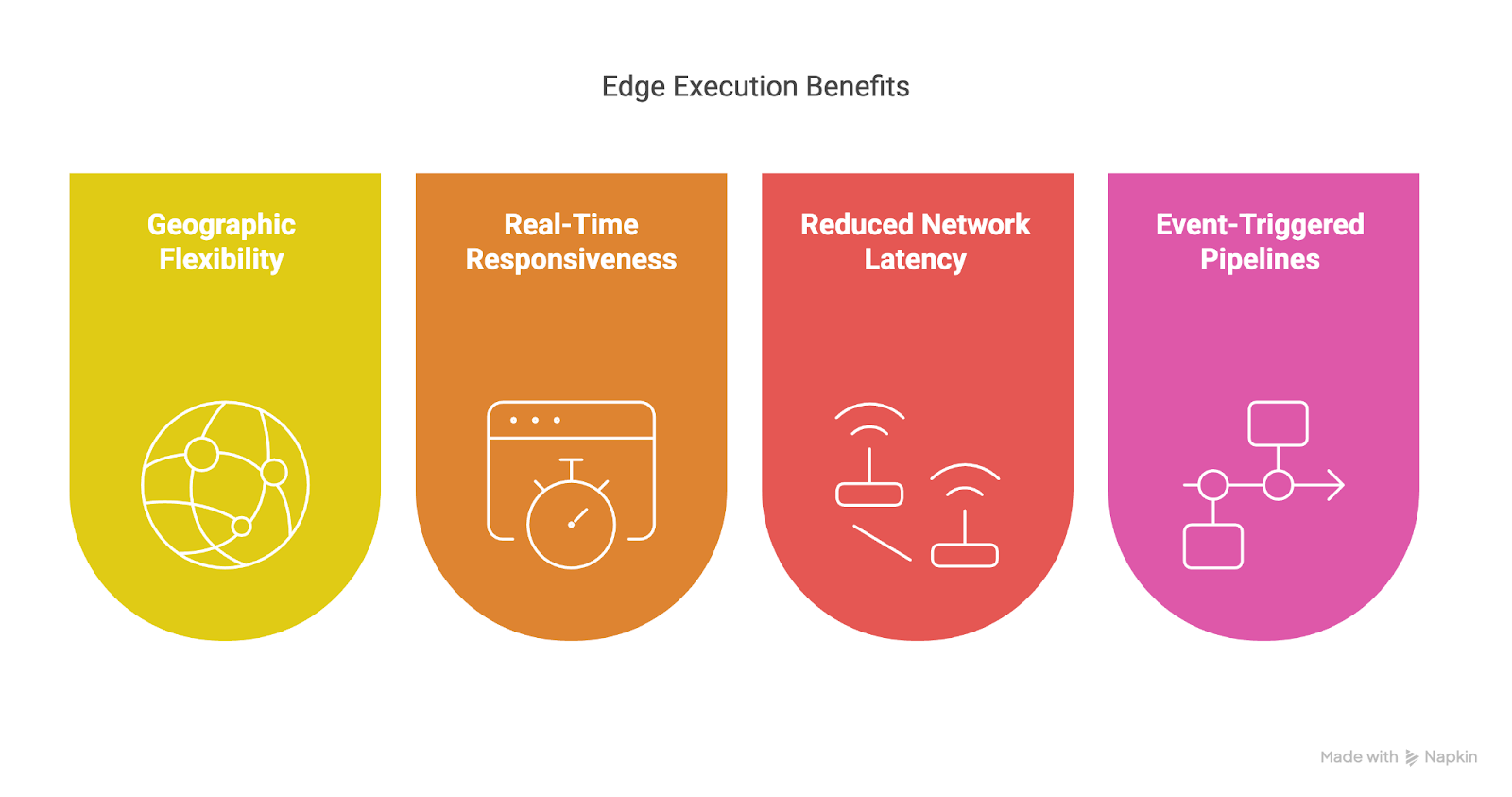
Image showing key benefits of Edge Execution. Image created using Napkin AI
Airflow 3.0 introduces a new level of task isolation that significantly enhances both security and performance.
Enabling tasks to run in sandboxed environments reduces the risk of data leaks and resource conflicts.
It also allows for more flexible dependency management, as different tasks or DAGs can operate with their own versions of libraries, Python environments, or runtime engines.
This isolation further supports smoother upgrades. Airflow’s core components can be updated without disrupting running tasks or breaking compatibility.
The improved architecture also enables a range of deployment scenarios tailored to diverse infrastructure needs.
In public cloud environments, Airflow workers can be easily distributed across providers like AWS, GCP, or Azure.
For private or hybrid cloud setups, control plane components can remain within a secure network while tasks execute in a DMZ or local data center.
In addition, Airflow 3.0 supports edge deployments, which enable use cases like ML inference or anomaly detection directly on industrial or mobile hardware.
These capabilities support compliance with data locality regulations, fault-tolerant scheduling, and GPU-accelerated execution.
Airflow 3.0 introduces a split command-line interface (CLI) designed to complement the modular backend, which distinguishes between local development and remote operational tasks.
This division simplifies workflows for both individual developers and platform teams.
For full technical details and a complete list of changes, check out the official Airflow 3.0 release notes.
Here is a table containing a summary of the architecture enhancements:
|
Feature |
Description |
|
Task SDK + API |
Write and run tasks in any language with remote execution support |
|
Edge Executor |
Distributed task execution near data sources or across geographies |
|
Task Isolation |
Secure and independent task environments; flexible dependency management |
|
CLI Split |
Clear distinction between local (airflow) and remote (airflowctl) commands |
|
Deployment Topologies |
Supports hybrid, multi-cloud, edge, and GPU-accelerated execution patterns |
Airflow 3.0 introduces a completely redesigned user interface, built from the ground up using React for the frontend and FastAPI as the new backend framework.
The new UI architecture offers a significantly smoother user experience, particularly in environments with hundreds or thousands of DAGs.
Page loads are faster, UI elements are more intuitive, and the navigation model feels consistent and responsive across different views.
Some of the key UI enhancements include:
Dark mode is now natively and thoughtfully integrated into Airflow, which offers a refined visual experience designed for clarity and long-term comfort.
While a version of dark mode was available in 2.x, this release introduces a fully developed and purpose-built design layer.
It has clearly been carefully optimized for contrast, readability, and reduced eye strain during extended work sessions.
As someone who's spent time in the development space, I really appreciate this.
It was one of the most requested community features and is especially valuable for developers who often work in low-light environments or simply prefer a darker interface.
The images below highlight the visual contrast between light and dark mode in the Airflow console dashboard.
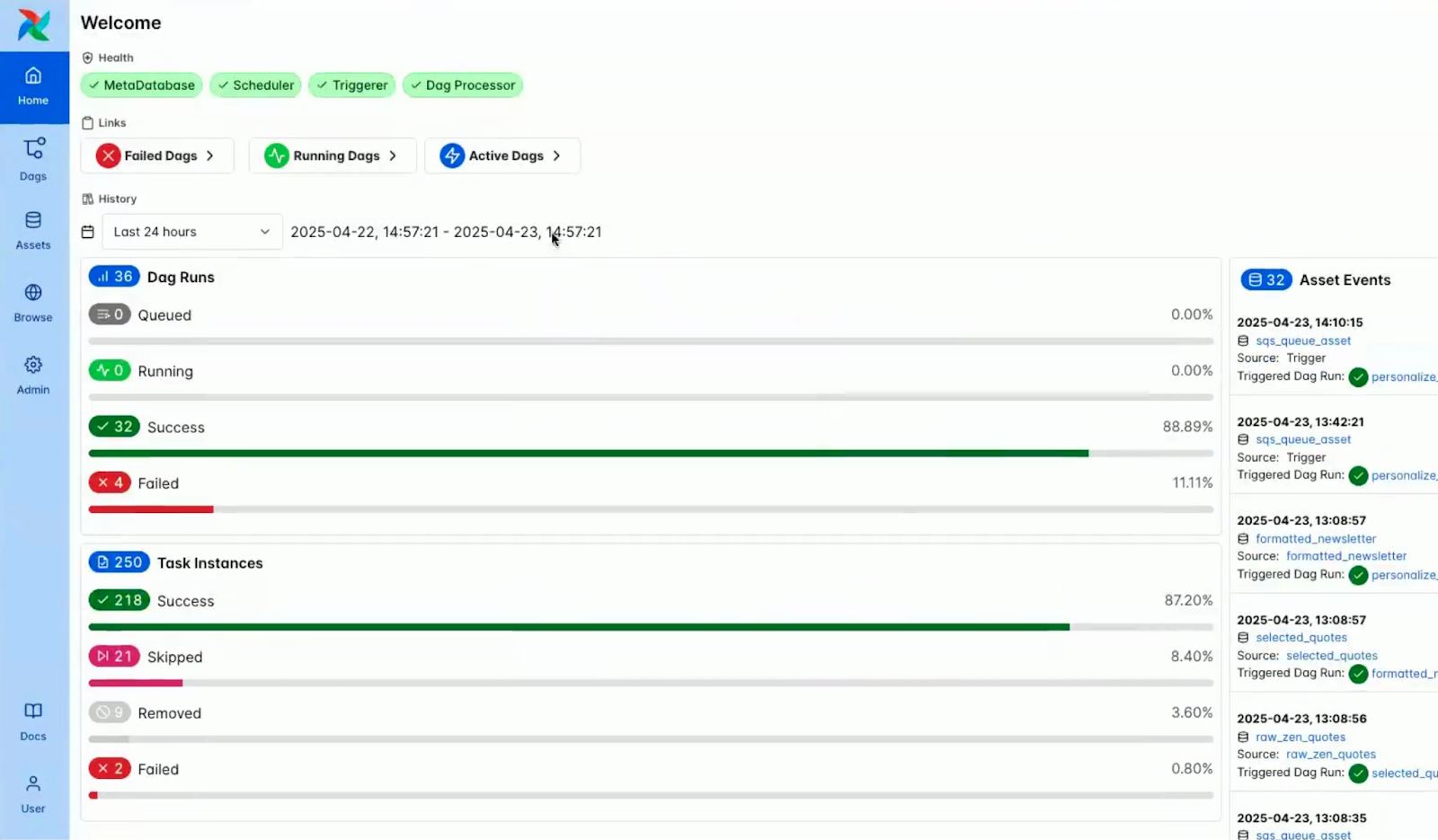
Screenshot of the Airflow console in light mode. Source: Airflow 3.0 Astronomer Introduction Video
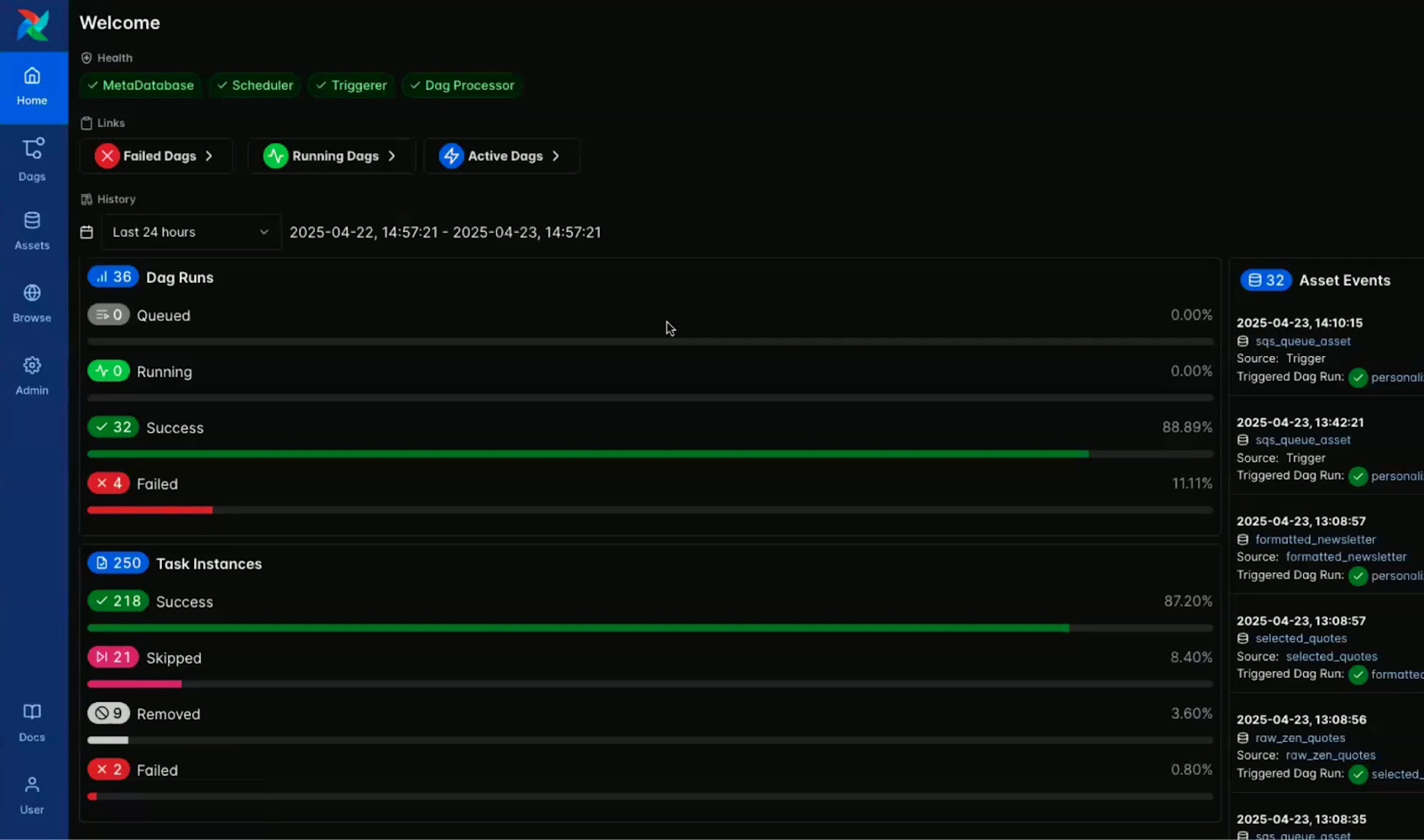
Screenshot of the Airflow console in dark mode. Source: Airflow 3.0 Astronomer Introduction Video
One of the most impactful new capabilities in Airflow 3.0 is first-class DAG versioning.
In prior versions of Airflow, DAGs were parsed from source code files, and the latest version of the DAG was applied universally, even retroactively, to past DAG runs.
This approach led to several well-known issues.
One major problem was execution drift. If you updated a DAG during a run, tasks could end up executing under different versions of the code.
There was also a loss of auditability as Airflow had no native mechanism to track which version of a DAG was used for a specific execution.
Additionally, historical accuracy suffered because the UI always displayed the latest DAG structure, regardless of when the DAG actually ran, which resulted in inconsistent and potentially misleading execution histories.
Airflow 3.0 introduces structured DAG version tracking directly into the platform:
I really appreciate this feature because, in practice, it is nearly impossible to create a DAG that won’t need changes.
DAGs will need to evolve due to new business logic, fixing bugs, or optimizing performance, and having built-in versioning makes that process far more transparent and manageable.
You can see this in action in the screenshots below, which show the DAG orchestration interface and the new version history dropdown.
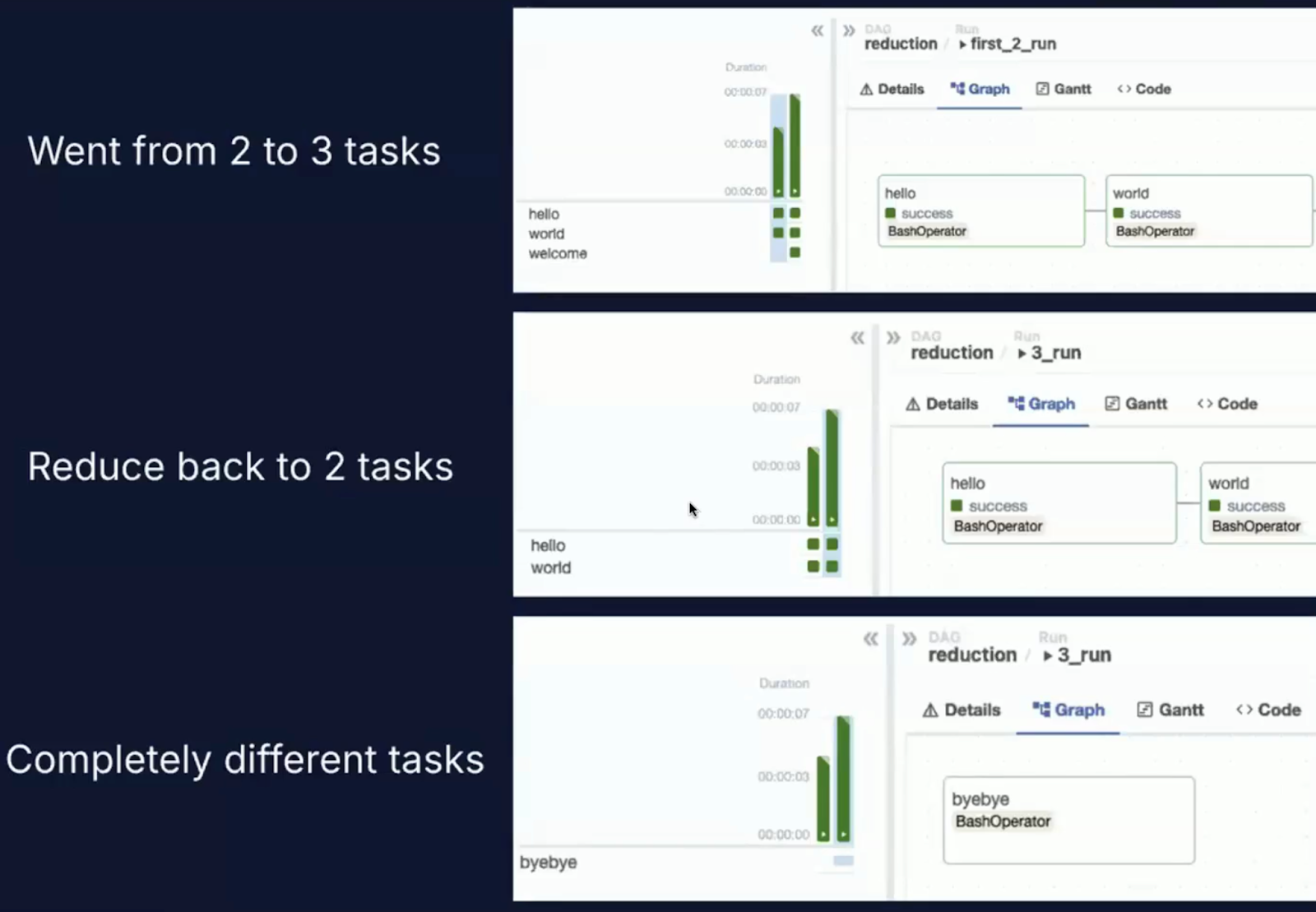
Image of DAG orchestration. Source: Airflow 3.0 Astronomer Introduction Video
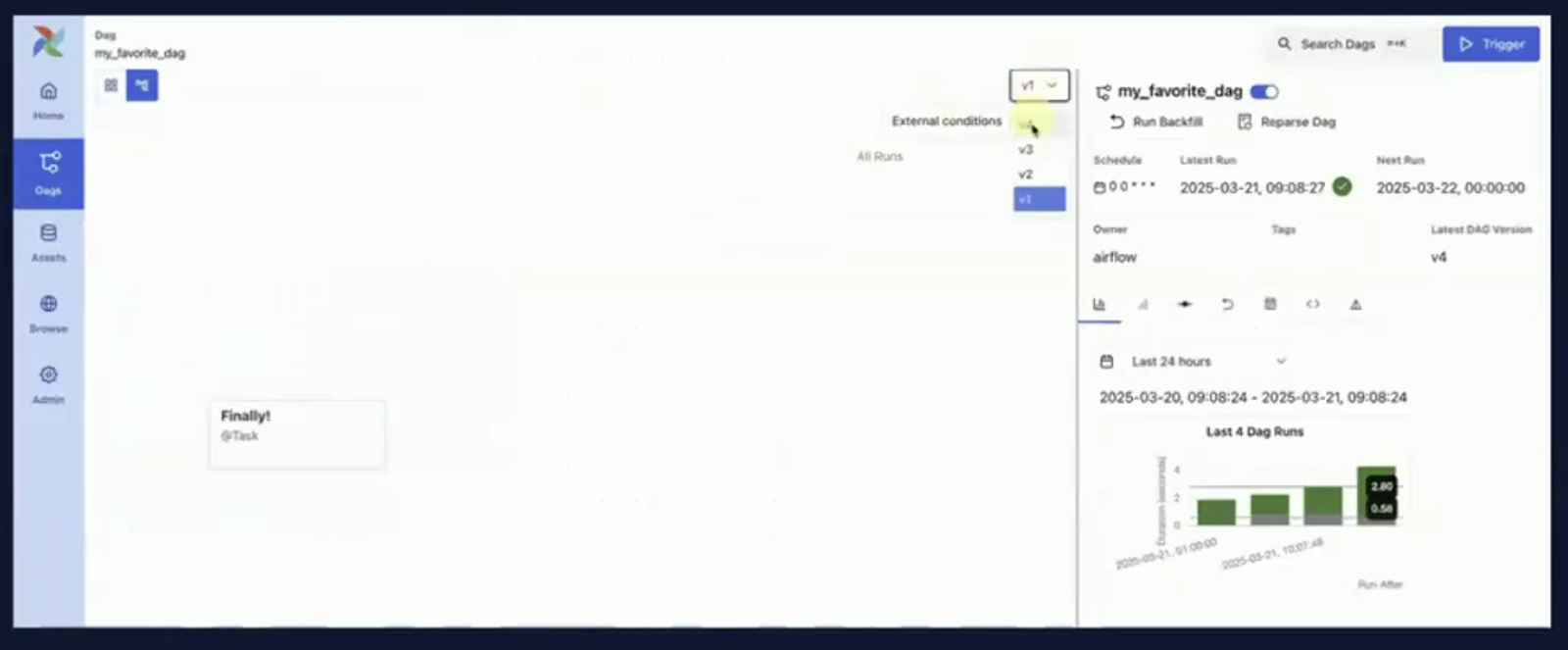
Screenshot of DAG orchestration with a version history dropdown. Source: Airflow 3.0 Astronomer Introduction Video
DAG versioning plays a crucial role in maintaining reliable, traceable, and compliant data workflows. Here is why it is important:
The screenshots below show how some of the changes are surfaced in the UI, with version-aware views in both the DAG overview and the code pane.
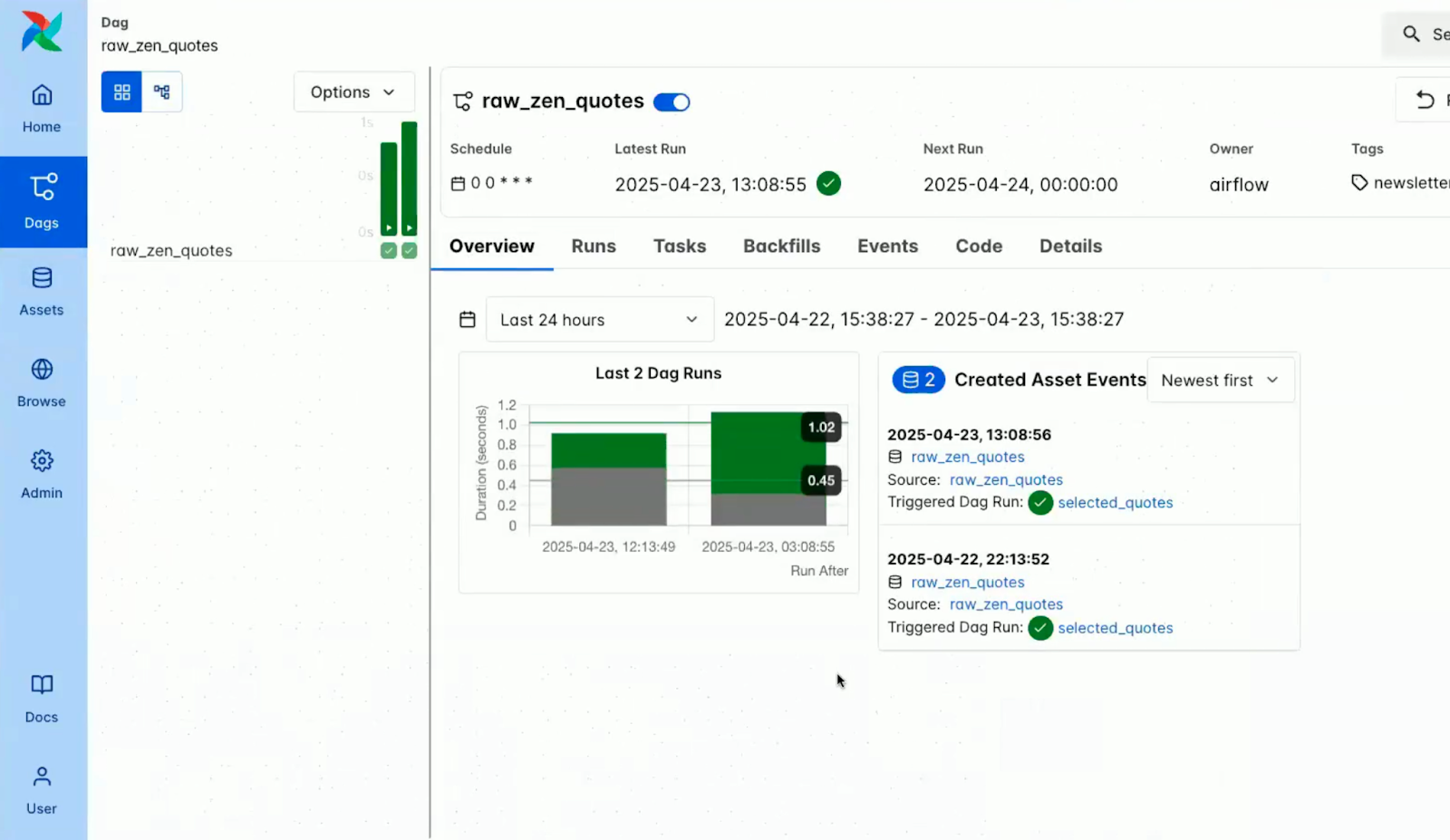
Screenshot of the overview pane within a DAG in the Airflow console. Source: Airflow 3.0 Astronomer Introduction Video)
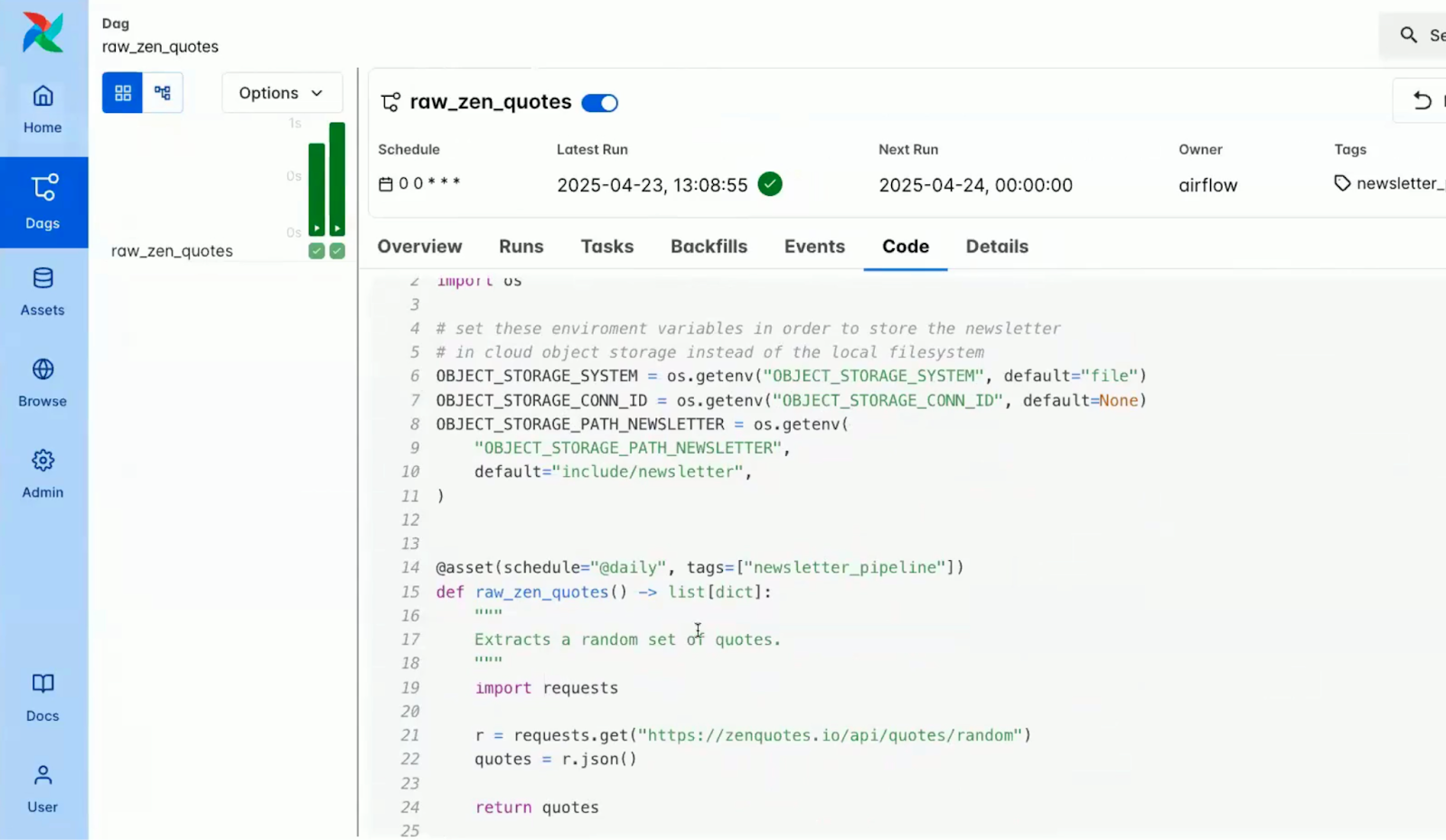
Screenshot of the code pane within a DAG in the Airflow console. Source: Airflow 3.0 Astronomer Introduction Video
DAG versioning also makes it easier for data teams to collaborate. For example:
Airflow 3.0 marks a significant evolution in how workflows are triggered, managed, and coordinated.
At the core of smarter scheduling in Airflow 3.0 is the concept of Assets.
Inspired by the evolution of datasets introduced in earlier versions, the new @asset decorator allows users to define pipelines that are driven by the availability and status of logical data entities.
An asset in Airflow represents a piece of data or an output that is produced, transformed, or consumed by a DAG.
This could be a database table, a file in cloud storage, a trained ML model, or even an API response.
With the @asset decorator:
The screenshot below shows how assets are visualized in the Airflow console.
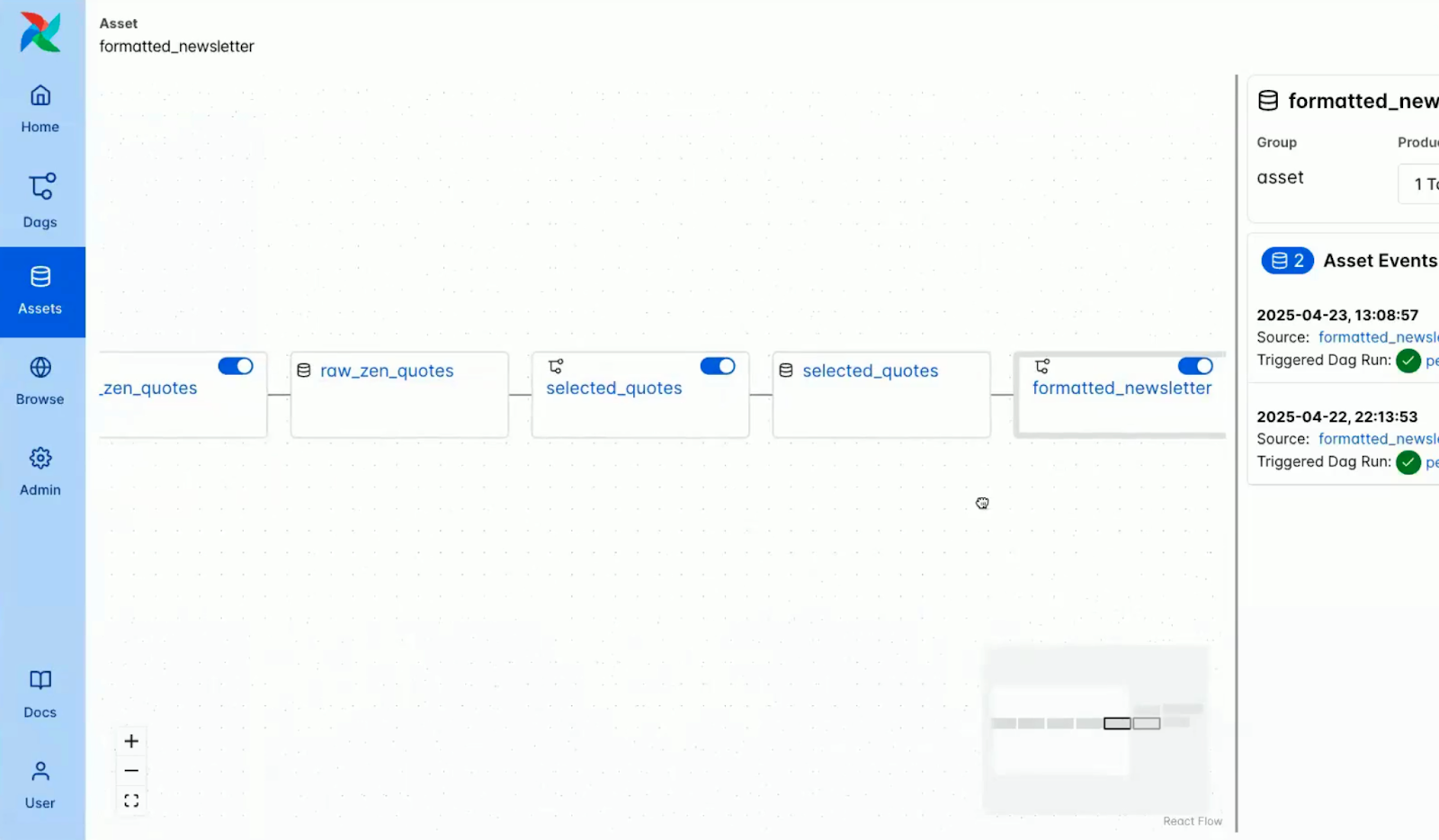
Screenshot of assets within the Airflow console. Source: Airflow 3.0 Astronomer Introduction Video
Some of the key features of assets in Airflow 3.0 include:
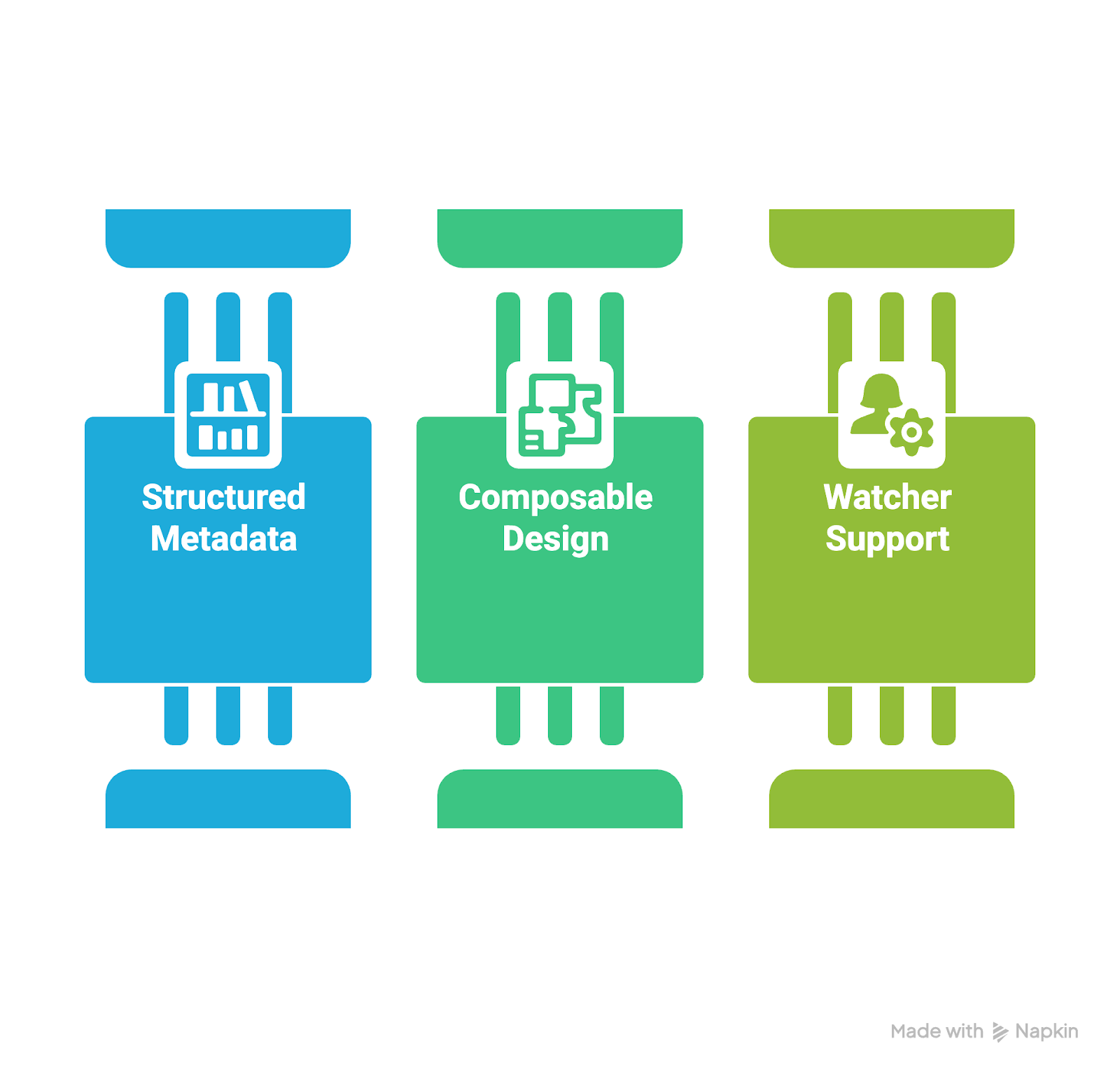
Image of key features of Assets in Airflow 3.0. Image created using Napkin AI
This model transforms DAG scheduling from “run every hour” to “run when relevant data is ready.”
This enables truly reactive workflows that are tightly coupled to the state of data, not the clock.
For more in-depth examples and production patterns using these new capabilities, the Astronomer guide on data-aware scheduling offers a detailed walkthrough. You can also learn how to implement a full data pipeline with these features in the guide to Building an ETL Pipeline with Airflow.
Airflow 3.0 introduces robust support for external event-driven scheduling, which allows workflows to be initiated based on real-world triggers from outside the Airflow ecosystem.
This feature is a significant shift from Airflow’s traditional polling-based approach.
Supported event sources include AWS SQS for integrating with message queues in cloud-native, decoupled workflows, planned support for Kafka to support streaming and microservices coordination, and HTTP/webhooks for receiving signals from monitoring systems, APIs, or other orchestration platforms.
Use cases range from starting a data pipeline when a new file lands in S3 to launching a DAG in response to an ML model registry update or coordinating real-time alerting and incident response workflows.
Event-driven DAGs allow Airflow to become more flexible and powerful, capable of reacting to external systems in real time.
One of the most anticipated improvements in Airflow 3.0 is the overhaul of backfill mechanics, the process of rerunning past data intervals or repairing failed DAGs.
Some of the challenges in Airflow 2.x included the lack of UI and API support for backfills, which had to be triggered manually via the CLI.
As a result of this, improvements were made in Airflow 3.0 which include:
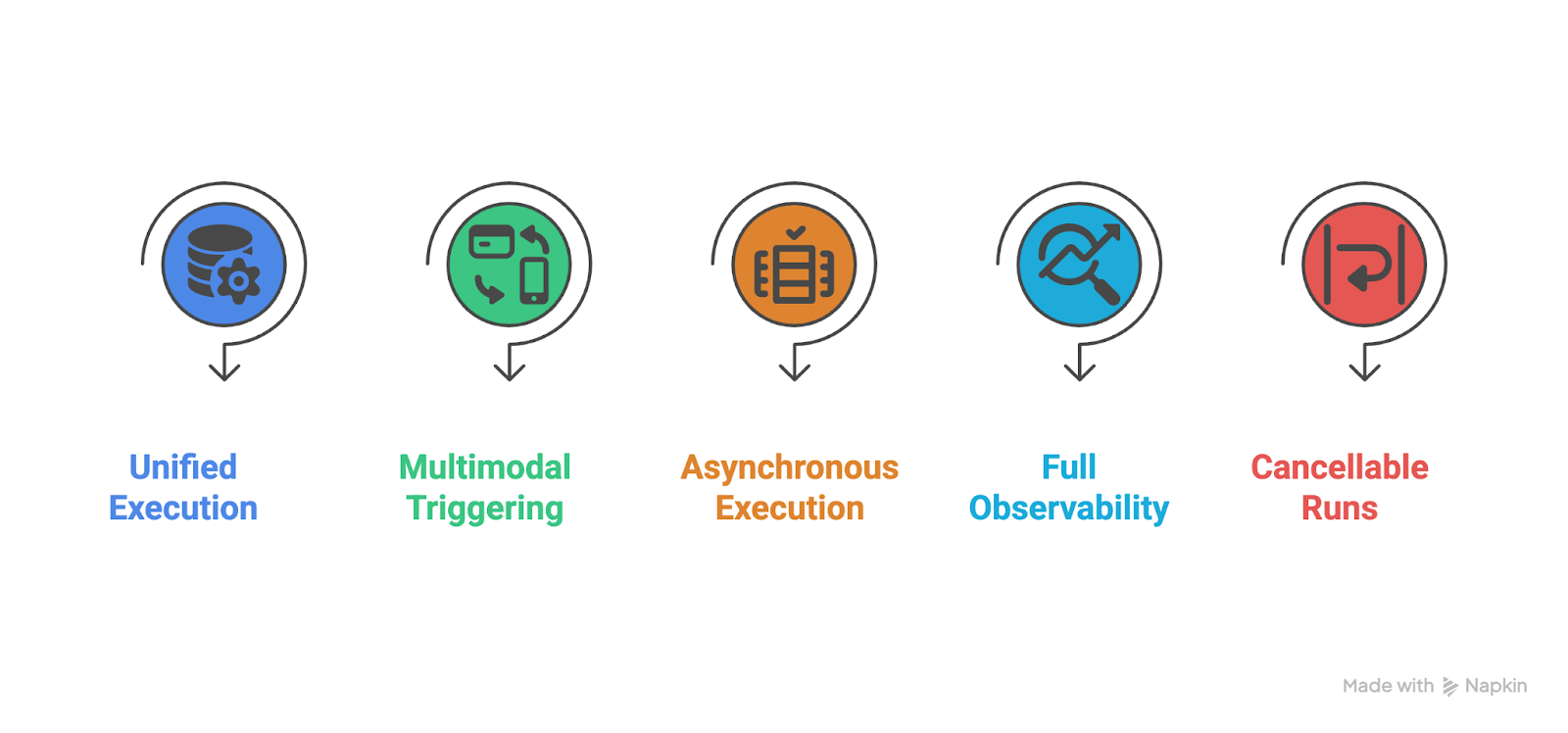
Image containing improvements in Airflow 3.0. Image created using Napkin AI
Airflow 3.0 takes a significant step toward becoming a first-class orchestration tool for modern machine learning (ML) and AI-driven workflows.
One of the most transformative changes in 3.0 is the removal of the long-standing execution date constraint.
In Airflow 2.x and earlier, every DAG run was required to have a unique execution_date, which was primarily tied to the scheduling interval.
While this model worked well for time-based ETL jobs, it created friction in experimental and inference scenarios.
With non-data-interval DAGs, Airflow 3.0 introduces true execution independence:
Some of the use cases empowered by this change include:
This decoupling dramatically simplifies orchestration logic for ML engineers and enables higher levels of automation, parallelism, and reproducibility.
Airflow 3.0 now officially supports multiple execution paradigms, recognizing that modern data workflows do not always conform to fixed schedules.
This update makes Airflow more adaptable to a variety of operational and data processing needs.
Supported execution modes include traditional Scheduled (Batch) execution, which uses cron-like scheduling and is well-suited for jobs like nightly reports, hourly syncs, or batch ETL pipelines.
Airflow 3.0 also supports Event-Driven execution, where DAGs can be triggered by external events—such as a new file appearing in a cloud storage bucket or a message arriving on Kafka—allowing for responsive, real-time orchestration. Additionally, Ad Hoc/Inference Execution is now possible, which enables DAGs to run without needing a specific timestamp.
This is particularly useful for use cases like machine learning inference, data quality checks, or user-triggered jobs where concurrency and immediacy matter.
Airflow 3.0 introduces significant improvements but also breaks from legacy patterns in meaningful ways.
To help you transition smoothly, the core contributors have provided an extensive and well-structured upgrade guide.
This is a major release, and careful planning is advised.
That said, the upgrade process has been made as straightforward as possible with clear documentation, upgrade checklists, and compatibility tooling.
Some of the aspects the guide covers include:
Screenshot of Apache Airflow webpage on upgrading to 3.0. Source: Apache Airflow
It is important that you evaluate the following areas before proceeding with the upgrade:
If you want a smooth upgrade experience, have a look at the full Upgrading to Airflow 3.0 documentation before you update Airflow.
To see the new features of Airflow 3.0 in action, the official demo DAGs provided by Astronomer offer a hands-on way to explore the platform’s latest capabilities.
These demos serve as a comprehensive showcase and are ideal for understanding how features like DAG versioning, asset-driven workflows, and event-driven execution function in real scenarios.
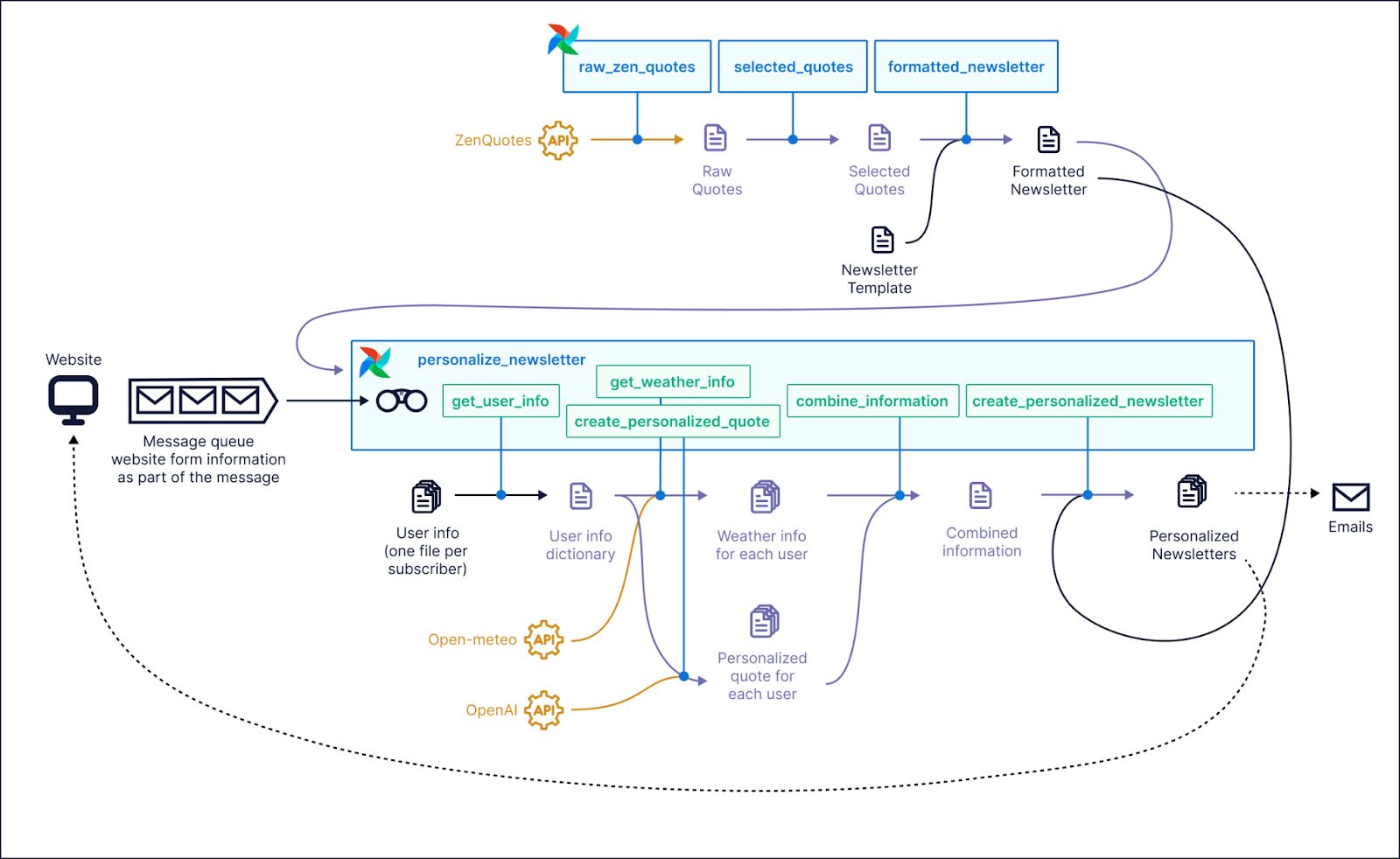
Screenshot of an example use case where Airflow 3.0 could be used. Source: Astronomer GitHub
The updated interface stood out immediately. The Asset view offered a clear visual map of data dependencies and lineage, which proved especially useful when working with asset-driven DAGs.
The DAG version history panel was another highlight. It allowed for quick inspection of past changes, made reproducibility straightforward, and made it easy to correlate specific runs with the code that produced them.
Additionally, the newly redesigned dark mode provided excellent contrast and readability, making it a welcome improvement for extended debugging sessions or late-night development work.
If you would like to try it out yourself, Astronomer provides step-by-step instructions and a ready-to-run demo environment on their GitHub repository. You can clone the repo, follow the setup guide, and explore Airflow 3.0’s new features.
Apache Airflow has always been driven by its community, and this applies to Airflow 3.0, too.
Many of the most impactful features in this release were direct responses to community surveys, GitHub discussions, and user feedback.
If you are using Airflow, you should consider getting involved. Here is how you can make an impact:
Apache Airflow 3.0 brings a service-oriented architecture, polyglot task execution, smarter scheduling, and a completely modernized UI, all in a single release.
The shift may feel dramatic, especially with the new CLI split and edge-focused executors, but the result is a more modular, scalable, and production-ready orchestration platform.
It is also more flexible for ML teams, cloud-native stacks, and event-driven systems where responsiveness and observability are key.
If you are still on an older version of Airflow, upgrading to 3.0 is definitely worth considering.
To get hands-on with Airflow, start with our course, Getting Started with Apache Airflow, or deepen your understanding of core concepts in Introduction to Apache Airflow in Python.
Top DataCamp Courses
Track
Track
Course
blog
Jake Roach
9 min
Tutorial
Jake Roach
Tutorial
Jake Roach
Tutorial
Patrick Brus
Tutorial
Tim Lu
Tutorial
Sayak Paul

