
Track
Data Engineer in Python
40 hr
It seems as if every time you scroll through LinkedIn, another new tool emerges in an already crowded data landscape. As data teams continue to add to the components of their “data stack,” they need a way to manage and connect these disparate tools.
Data orchestration is the process of developing, executing, and monitoring processes that combine, transform, and organize data across an entire data ecosystem. To do this, data engineers use data orchestration tools. Here, we’ll explore two of the most popular orchestration tools; Apache Airflow and Dagster. Let’s get started!
Airflow is the industry standard for building, running, and monitoring data pipelines as code. It was originally developed in 2014 by the Data Engineering team at Airbnb. Since then, the project has been adopted by the Apache Software Foundation and has become the most popular offering under their license.
Each month, Airflow is downloaded more than thirty million times and has a vibrant community of contributors and users. In Airflow, data pipelines are referred to as DAGs, or directed acyclic graphs.
You can learn more about Airflow in our tutorial on getting started with Apache Airflow.
Like Airflow, Dagster is an orchestration tool that allows users to author data pipelines using as-code. It is open-source and was originally launched in 2019. Dagster uses Python to define “assets,” which are the building blocks for a data pipeline.
Dagster has emerged as a competitor to Airflow in a relatively uncrowded space. The project is maintained by its open-source community and commercially backed by Dagster Labs.
So, where do Airflow and Dagster fit into a modern data stack? We’ll start with the architecture diagram below.

An architecture diagram containing a sampling of common tools used in the modern data stack.
This architecture diagram shows what many consider a standard data stack. It’s made up of source systems, data warehousing and transformation tools, and downstream “destinations” such as Tableau and Looker.
Here, Airflow and Dagster are the arrows that connect this data ecosystem. Without an orchestration tool, it’s difficult to move data from one tool to another.
Orchestration tools, like Airflow and Dagster, also provide a layer of observability that makes it easy to understand where, how, and when data is pipelined from source to destination, and how it is manipulated along the way.
As you might have already guessed, Airflow and Dagster share a number of similarities in their intended use and the role they fill in the modern data stack. These include:
However, each has a unique set of features and functionality that allow for it to stand on its own.
Let’s start by looking at some of the main features of Airflow:
In Airflow, data pipelines are called DAGs—short for directed-acyclic graphs. Think of a DAG as a collection of tasks that are connected in a specific order. The most basic building block of a DAG is a task. For instance, in a pipeline that performs extraction, transformation, and loading (ETL), the "transform" step would be its own task.
These tasks are generally defined using Airflow operators. But, as you'll soon see, there’s also another way to define tasks using the TaskFlow API.
Scheduling a pipeline in Airflow is infinitely flexible. Need to run a pipeline daily? No problem. Want it to be executed on the first Friday of every month? That’s easy too. Now, what if your manager asks you to trigger a DAG when a dataset is updated? Airflow can handle that as well.
Airflow offers plenty of customization options when it comes to scheduling your DAGs. With features like CRON, Timetables, and data-aware scheduling, you can set DAGs to run whenever you need.
To make DAG-writing more accessible for data professionals, the Airflow community introduced the TaskFlow API. Instead of the traditional approach of using operators, the TaskFlow API lets you define tasks by simply decorating functions. This makes it much easier and more intuitive to share data between tasks and establish task dependencies.
Moreover, tools like the Astro SDK have been built on top of the TaskFlow API, further extending its capabilities.
Let’s explore how Dagster compares:
Dagster takes a unique asset-based approach to building data pipelines. In Dagster, any data object stored in persistent storage—like a file or a table—is called an asset.
These assets are defined in code using Python functions. When these functions are executed, Dagster automatically creates dependencies and materializes the asset. This asset-centric method makes it easy to track how data is produced and consumed within a pipeline.
Another key concept in Dagster is “ops,” which are somewhat similar to tasks in Airflow. Ops represent individual steps in a data pipeline, and each op has inputs and outputs that may consist of assets. What’s more, these inputs and outputs can be typed to clearly define the data being processed.
So, what’s the relationship between ops and assets? Ops are essentially the steps (like extract, transform, load) that operate on the assets, which are the data objects themselves.
To bring clarity to the data flowing through a pipeline, Dagster uses a robust typing system to validate the inputs and outputs of each op. While Airflow supports Python type definitions, Dagster has made typing a core part of its pipeline-authoring experience.
Not only can you type ops, but asset definitions can also be typed, ensuring that the data an asset produces is correct and validated.
When choosing an orchestration tool, things like feature density, total cost of ownership, and scalability may make up a list of acceptance criteria. That being said, it’s important to keep in mind the developer experience. An intuitive, efficient, and robust developer experience helps enable rapid iteration and proactively address challenges such as running unit tests and managing dependencies.
Have an Airflow question or bug you just can’t seem to figure out? Chances are, it’s already been solved. Airflow has one of the largest Slack communities of any Apache project and boasts a community of more than three thousand contributors. Thousands of blogs, tutorials, and courses have been developed around the Airflow project. In addition to supporting Airflow users, the community is responsible for building and maintaining the Airflow project.
Astronomer, the commercial developer behind the Apache Airflow project, has taken the Airflow developer experience to the next level. The astro CLI provides an additional layer of abstraction and functionality for Airflow utilities. Astronomer also provides their registry and “Ask Astro” chatbot to tackle any and every Airflow question a developer might have.
One feature that makes Airflow such an attractive option for orchestration is the ability to develop and test locally. Using the airflow CLI, a developer can spin up an instance of Airflow in just a matter of seconds. Then, changes can be made to the code locally, before testing via the UI or CLI. This allows for rapid iteration and a shorter release cycle, especially for Airflow-heavy teams.
For a while, the only way to define an Airflow DAG was via traditional operators. The TaskFlow API quickly changed that, and provided an alternative to DAG-creation. Now, tools like dag-factory and gusty make it easier than ever to get started writing and executing DAGs.
Much of Dagster’s local development experience matches that of Airflow, including the ability to develop, test, and execute pipelines locally. Both provide support for common enterprise-grade SDLC practices, like CI/CD.
However, it’s difficult to compare the sheer magnitude of Airflow’s community to that of Dagster’s. Where Airflow has thousands of community-developed resources, Dagster is still trying to catch up. When developing and troubleshooting data pipelines with Dagster, practitioners may find themselves struggling to easily find the resources they need to implement a solution.
Dagster’s asset-based approach to developing pipelines makes them quite easy to test. In fact, testing is one of the core tenets of Dagster’s value proposition. Along with the typing system mentioned above, Dagster has made it a priority to ensure that data pipelines are tested in a manner similar to how a software product would be tested.
Dagster’s documentation emphasizes the challenge of entangled business logic in any pipeline definition and common techniques to handle this when testing. This is an area where many feel the Airflow developer experience is lacking.
Starting to get a feel for what using Airflow and Dagster is like? Now, we’ll break down where each tool stands out over the other, as well as a handful of known shortcomings.
Cliche, but with Airflow, the sky is the limit. The extensibility of the project is second to none. Airflow developers can build their own operators, sensors, executors, and even timetables. For data teams with unique use cases, this is quite attractive. Don’t want to build your own custom integrations?
Don’t worry, chances are you won’t have to. There are more than 1,600 existing integrations ready to be used after a simple pip install. Being the industry standard for data orchestration means Airflow benefits from continual innovation, creating a sort of “positive feedback loop”.
A truly open-source product, there are tons of ways to run Airflow in production. From on-prem Kubernetes clusters to a fully managed service, thousands of enterprises run Airflow in a production environment.
Government and reporting regulations, commitments to data privacy and security, and a jungle of networking force data teams to configure tooling in ways that are sometimes unimaginable. For teams like this, they require all the flexibility and customizability they can get when running a tool like Airflow in production. Other teams may want a managed service provider to do all the heavy lifting for them. With Airflow, both of these extremes (as well as every option between them) are feasible.
Airflow is extensible and boasts thousands of plugins. DAGs can be defined using a number of techniques, pipelines triggered using data-aware scheduling, and a custom secrets backend can be configured.
All of this means that leveraging Airflow to its fullest extent yields a little bit of a learning curve.
For Data Engineers looking to quickly author and execute data pipelines, Airflow comes with a barrier to entry. Often, this will scare Data Engineers and the like towards a more straightforward offering, such as Dagster.
Building data pipelines with Dagster is intuitive. The asset-based approach is attractive for data practitioners interested in putting a pipeline into production with as little overhead as possible.
Dagster poses much less of a learning curve than working with traditional Airflow operators, especially for users who are accustomed to writing Python functions to build their data pipelines. This is one of Dagster’s greatest strengths and, often, a large part of why a data team may choose to trust Dagster to power their data pipelines.
Competing with the Airflow community is hard, even for Dagster. From contributing to the open source project to building connectors for the latest and greatest addition to the data stack, to answering questions and curating documentation, there’s not much that the Airflow community doesn’t offer. That being said, the Dagster community is growing, and quickly. At the enterprise level, this budding community is both a risk, as well as an opportunity to inject influence into the Dagster project.
So, now that we’ve compared each of these tools, which one is right for you? In the table below, we’ve compiled a comparison of each:
|
Feature/Aspect |
Airflow |
Dagster |
|
Pipeline Concept |
Uses Directed Acyclic Graphs (DAGs) to represent pipelines, with tasks being the basic units. |
Uses an asset-based approach where any data object stored is called an asset, with operations called “ops”. |
|
Task Representation |
Tasks are defined using operators, or with the TaskFlow API for function-based task definition. |
Ops are used to represent steps in the pipeline, with typed inputs and outputs for better clarity. |
|
Scheduling |
Highly flexible scheduling with CRON, timetables, and data-aware triggers. |
Scheduling is less emphasized but tied to assets and their dependencies. |
|
Local Development |
Supports local development via the Airflow CLI for rapid iteration and testing. |
Also supports local development and testing, but with fewer community resources available. |
|
Typing System |
Supports Python-type hints, but not a core feature. |
Strong typing system to validate inputs and outputs at every step, central to the pipeline's design. |
|
Extensibility |
Highly extensible with 1,600+ integrations, custom operators, sensors, and more. |
More limited extensibility but intuitive for Python function users. |
|
Community Support |
Large, mature community with thousands of contributors and extensive resources (e.g., blogs, tutorials). |
Smaller but rapidly growing community, providing an opportunity for influence and contribution. |
|
Ease of Learning |
Steeper learning curve due to extensibility and custom features. |
Lower learning curve due to intuitive pipeline authoring and an asset-based approach. |
|
Testing |
Testing is possible but not a core focus. |
Strong emphasis on testing, with an asset-based approach making pipelines easier to test. |
|
Production Deployment |
Can be run in various environments, from on-prem Kubernetes to fully managed services. |
Less mature in production deployment options but still flexible for enterprise use cases. |
|
Custom Integrations |
Infinite extensibility with thousands of integrations and the ability to create custom components. |
Limited compared to Airflow, but growing with its expanding community. |
|
Developer Experience |
TaskFlow API and tools like dag-factory enhance the developer experience. |
More intuitive with an emphasis on simplicity and rapid deployment, but fewer tools available. |
In the graphic below summarizes the key similarities and differences in the features and functionality of both Airflow and Dagster.
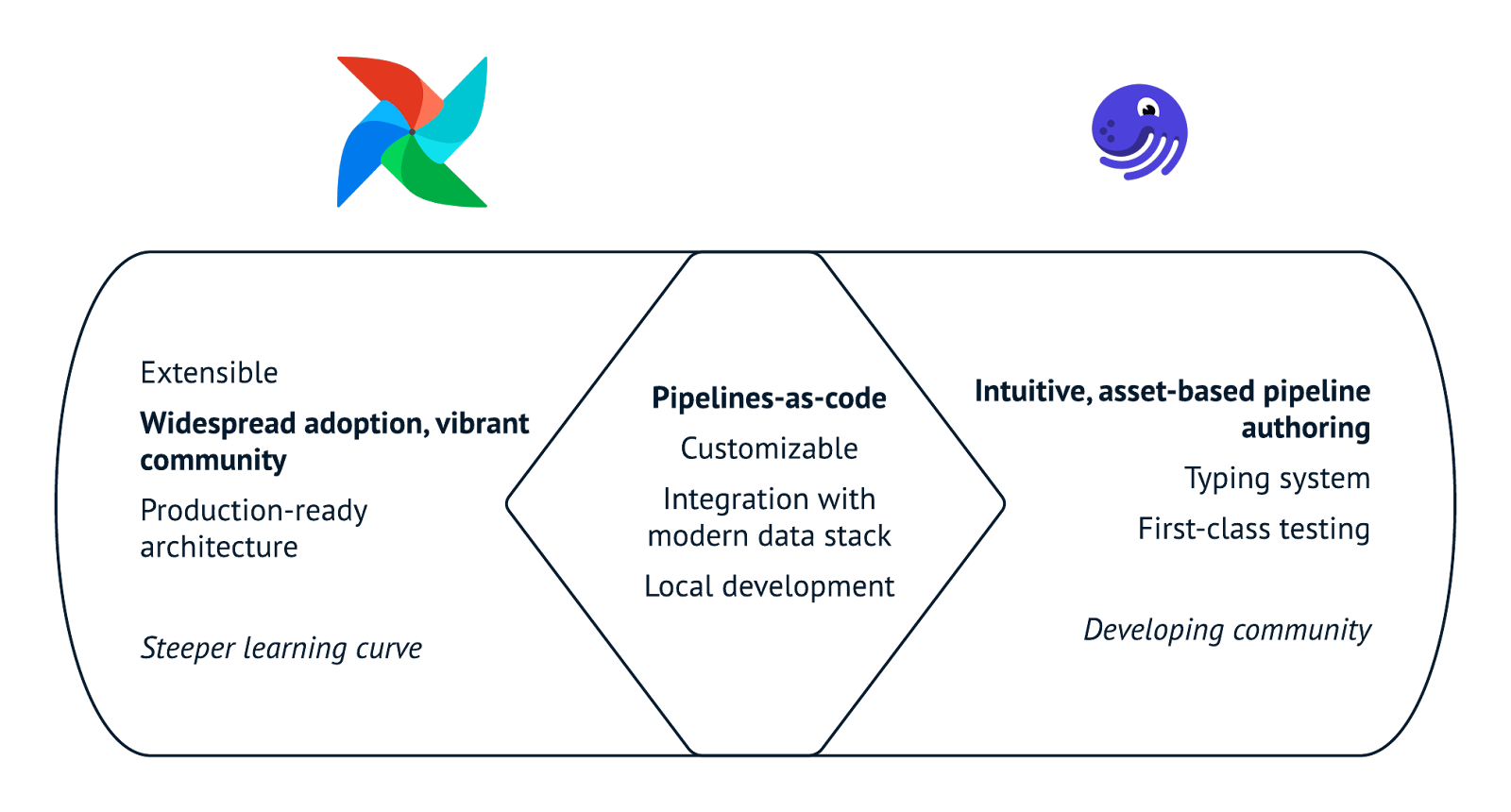
Similarities between Airflow and Dagster.
Now, the million-dollar question; which orchestration tool should you pick for the job?
Plain and simple, Airflow is the de facto standard for writing and running data pipelines in production. Yes, there are components of Dagster’s design patterns that may be technically superior to Airflow. But the extensibility of Airflow and the community that has grown to support the project make it an easy choice for well-established data teams. Airflow offers the best of both worlds; a massive library of existing tooling plus the ability to create any operator, sensor, or hook you can imagine. Airflow has found its niche, and it’s not going anywhere anytime soon.
For small data teams accustomed to writing home-grown data pipelines, Dagster just might be the right tool for the job. While Dagster may not boast the “bells and whistles” that Airflow supports, it offers a quick path from idea to production. Dagster provides top-notch support for the things that matter (think local development, robust unit-testing, and a modular framework), along with a plethora of integrations. As the project matures and community grows, Dagster continues to close the feature gap between itself and Airflow while maintaining a low barrier to entry.
Comparing tools is always challenging. It’s hard to say one is “better” than another, or force a certain tool into a particular use base. Truth be told, the underlying framework behind Airflow and Dagster is startlingly similar. The best data practitioners don’t reach for features when choosing a tool. Rather, they focus on how the tool they integrate into their ecosystem impacts the process.
Does Airflow allow for my teams to iterate more rapidly? Will a tool like Dagster help engineers better test code before shipping to production? Does this orchestration tool fit into the larger vision for a data platform? Questions like these help drive value for data teams and the stakeholders they serve.
If you’re ready to get started with Apache Airflow, check out DataCamp’s Introduction to Airflow in Python course. Here, you’ll learn the basics of using tasks, sensors, and everything else you need to build your first Airflow DAGs.
Top DataCamp Courses
Track
Track
Course
blog
Abid Ali Awan
13 min
blog
Gus Frazer
12 min
blog
Maria Eugenia Inzaugarat
8 min
Tutorial
Tim Lu
Tutorial
Jake Roach
Tutorial
Gus Frazer


