DataCamp’s mission is to help individuals and companies at every step of their journey to become data fluent by building the smartest data science education platform out there.
This post aims to provide more context on why we started DataCamp at a macro level. In the first section of the post, we’ll discuss the data science (talent) market. The second part covers the core pillars that support our vision for the future of data science education. Finally, we tackle the importance of certification.
The market
The opportunity
Understanding how to analyze data enables people and companies to make better decisions, create better & new services and products, etc. We believe the impact data analysis and data science will have over the next 20 years, will be as large as the impact software engineering and computer science have had in the last 20 years. Software is eating the world, but data science and AI are going to have software engineering for supper!
The talent gap
While that’s very exciting, there’s a problem: Harvard Business Review and a McKinsey report first shined the spotlight on the data scientist shortage. Today, companies in every single industry are indeed struggling to find data scientists or people with a decent level of data literacy/fluency. Numbers on the (expected) shortage of data scientists range from hundreds of thousands to millions in the more recent research reports on this topic.
While you can debate the accuracy of these predictions, one thing is clear: traditional educational institutions can’t train enough people in the next decades to resolve this gap. Furthermore, a large part of the world does not have access to high-quality data science education at traditional education institutions because it’s often (very) expensive.
Consequently, the power of data science can only be harnessed if we find ways to retrain the existing workforce affordably. On the one hand, you should expect a large group of individuals to up-skill themselves for career advancement (and career shifts to a lesser extent), on the other hand, expect companies to retrain significant portions of their workforce. Note as well that the group of people learning for career advancement is larger than people learning because they want to change careers. This observation is not new. lynda.com and Pluralsight have proven that a focus on continuing education is a winning strategy in the creative and developer space respectively.
Finally, it’s important to realize that the skill gap exists at multiple levels: It ranges from people working with data on a weekly basis who run into the limits of the tools they currently use (often Microsoft Excel), to data analysts and data scientists, to managers and consultants. All of these groups have different needs, but for all these groups, there’s a shortage of people with the right level of data literacy/fluency.
Because of the above, we believe the education market for data literacy is huge and probably larger than the market for teaching basic coding skills. Two data points seem to confirm the validity of this belief:
- More than sixty percent of our 1.7 million students are working professionals active in a wide range of areas (consulting, finance, health care, research, marketing, …) taking on a wide range of roles. You can read some of their stories on DataCamp.

- Many people seem to associate data science with the technology industry and therefore think San Francisco is the Mecca of data science. However, data science is not unique to San Francisco at all. If you rank DataCamp’s learning traffic by city, San Francisco is ranked only in 24th position, surpassed by 7 cities in India and 4 cities in the US (New York City is number 1 in the US). The need for data science is everywhere. ### A shift to open-source Open-source software development has completely transformed the web development community and is now transforming the applied statistics and data science community. Whereas SAS and SPSS dominated the applied statistics world not that long ago, open-source technologies like R and Python seem to have pretty much taken over. By the way, DataCamp has also open-sourced some courses and technology. It’s difficult to argue with the growth of open-source software as the foundational layer of the future of data science. This is the main reason all of our data science training is focused on open-source at the moment. Furthermore, its very nature makes it easier to build interactive educational tools on top of it. A focus on open-source also allows us to give back to the open-source data science communities. We provide scalable revenue streams to open-source contributors who build DataCamp courses through our royalty model. While open-source will remain a large part of our curriculum in the years to come, we ultimately want to offer training on every relevant tool and methodology to our students. Expect us to start building training for proprietary tools as well in the future. ## The future of data science education A vertical focus and technology enables the best learning experience The University of Bologna in Italy was founded in 1088 and is the oldest one in Europe.

Historically, educational institutions covered a wide range of topics (let’s call this a horizontal focus). For example, the oldest university in Europe teaches topics ranging from history, economics, psychology, statistics, etc. The horizontal focus made sense at the time because of the combination of (i) economies of scale (around buildings, student administration, attracting the smartest professors, brand value for certification, etc.) and (ii) a constrained geographical reach given high communication and transportation costs. Horizontal focus was the dominant education model for centuries, which is why we’re still used to thinking about educational institutions as being horizontally focused.
Costs of transportation & communication and the fixed costs of the educational models have dropped significantly in recent decades, thanks to technological advancement. So… how does that impact educational landscape now and in the future?

If you take a helicopter view of the online education market in recent times, the first wave of companies has mostly copied the brick-and-mortar horizontal approach, while the second wave has been more technology and vertically focused (i.e. focused on one area of skills). The positive impact of the first wave in online education has been — without a doubt — enormous, as they managed to make high-quality education available at scale. That said, they did not go very far to leverage technology to actually improve the learning experience and they are even somewhat unexciting from a technology point of view. Their horizontal focus makes it really hard to overcome the traditional trade-off between personalization and scalability in education. What do I mean by that?
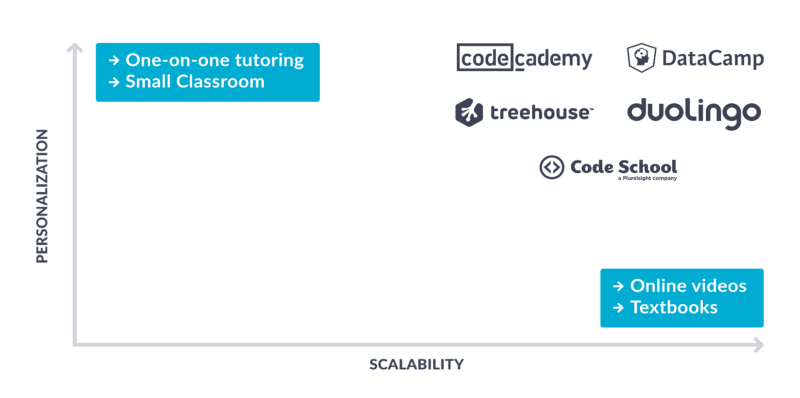
The most personalized educational experiences used to be very hard to scale. One-on-one tutoring, small classroom training, etc. can offer a great, highly personalized educational experience. However, the lack of scalability typically makes these options very expensive (and thus only available to the lucky few). On the other hand, highly scalable educational experiences such as online video training and textbooks are often affordable but they lack personalization. No personalization often makes training less effective and less engaging. The fairly low course completion rates of traditional MOOCs are a good example of lower engagement impacting learning outcomes.
Technology and a vertical focus now enable us to overcome the typical trade-off between scalability (and affordability) and personalization by building personalized learning experiences at scale. It enables students to learn by doing and to bring the learning experience as close as possible to — in our case — working on actual data science projects. Many of our courses have course completion rates of over 50%, which indicates that engagement benefits from this approach.
A network of expert instructors yields the best educational experience
The first wave in online education suffers from a lack of personalization, but it did get a key ingredient right: they leveraged the experience and knowledge of some of the smartest people in every domain.
The second wave in online education seems to have forgotten about the power of leveraging external partners to build educational content. In contrast, we strongly believe in the importance of building a network of external instructors from both industry as well as academia. For teaching the usage of open-source software tools, that may well be the package author; for more theoretical topics, it could be a well-respected professor; for more applied topics, it should be an industry expert. The benefits of this approach are:
- Working with external instructors allows us to build out the course library faster, which is essential as data science is a fast-moving field and our students want to learn the latest skills yesterday.
- Having a portion of the course library built by industry experts ensures that we teach skills relevant to the job market.
- Having a portion of the course library built by academics allows DataCamp to build upon (recent) research, their reputation and their educational experience.
- A segment of our students is more motivated if the course is taught by a real expert or by one of their open-source heroes.
We deeply value our course creation partnerships with companies like Anaconda. We also believe that we’ll get to build the best collection of data science courses by leveraging a network of individual instructors in addition to these partnerships. You may ask: “why not partner with universities to create the course library? or partner with book publishers?”. There are many reasons we feel that would be suboptimal. First of all, dealing with the legal departments of these organizations would be slow(er), and we don’t like slow. Second, we ultimately believe that technological progress in educational platforms can and should empower the individual content creator. This has happened in the music industry, to some extent in the entertainment industry and is now happening in the education industry. For those interested: a full list of DataCamp’s instructors can be found here.
Certification of skill level as matching mechanism
To solve the shortage of people with data skills, it’s not enough to train people in an affordable and scalable way. You need an efficient matching mechanism to help individuals communicate their skill level and to help organizations find people with the skills they need (both inside and outside their organization).
For centuries, university degrees were the most common way to signal ability and skills to potential employers. There are two key reasons why it’s hard to believe that traditional degrees will be the main signaling mechanism for data fluency:
- The number of people acquiring data skills through traditional education system will be a relatively small portion of the total number of people acquiring these skills in the next decade. Our data confirms this assumption; by far the largest group of learners is between 25 and 35.
- Data science is early in its development as a field and relevant skills still change every year. Therefore, you need a signaling mechanism that evolves with the field and allows to be updated in an efficient way. That also requires lifelong learning, which is something most traditional educational institutions aren’t able to provide. There are so many possible things to learn that data science is impossible to master at University, even after an undergraduate degree, a masters or even a PhD. Masters degrees will not let you master data science ;-).
Two signaling mechanisms emerge as alternatives:
- Course completion certificates are offered by most online education platforms. They certainly have value as a mechanism to signal motivation. However, course completion certifications are fairly ineffective to communicate skill level because: (i) they are often not set up to measure skill level in a rigorous way, and (ii) very few courses have the volume to even have a chance at getting recognition in the market.
- Certification mechanisms that measure skill level have emerged in fields like cloud computing as an efficient and effective way to communicate skill level. Certification is now a common way for IT professionals to distinguish themselves, but it doesn’t stop there. Duolingo recently launched their version of the TOEFL test in the context of assessing language skills, and the GMAT has been widely accepted by business schools for a long time. In data science, however, no one has created a way to assess and certify someone’s skill level yet. We’d like to create that assessment system as we believe this presents an enormous opportunity to enable people to communicate their skill level better and for companies to understand the skill level of their existing workforce as well as applicants.
Conclusion
The ubiquity of data creates enormous opportunities for people and companies to make better decisions and get ahead. However, the widening talent gap limits the positive impact the analysis of data has on the world. On the one hand, companies can’t find the talent they need, on the other hand, there’s a large group of people with limited access to high-quality educational resources (due to price and availability).
We believe online education as a way to fix this problem. More specifically, we believe in the value of personalization to create an engaging and effective learning experience. Furthermore, we believe in the strength of building a network of expert instructors to create that training. Finally, we believe that the market is missing an effective matching mechanism.
In a follow-up post, we’ll take a deeper dive into DataCamp’s plan.


