
Course
Introduction to R
4 hr
3M
Histograms are commonly used in data analysis to represent the distribution of a data set graphically. It allows us to visualize how data is spread across different values, helping uncover patterns, trends, and anomalies.
This article introduces frequency histograms and helps you create one step-by-step. We will also learn about different types of histograms, some popular technologies for creating them, common mistakes to avoid, and best practices to follow.
A frequency histogram is a graphical representation of the distribution of a data set. A histogram is constructed from a series of bins, essentially intervals that cover the range of the data. Each bin has a frequency, the count of data points within that interval. The bins are plotted on the horizontal axis, while the frequencies are plotted on the vertical axis, resulting in a bar chart-like representation. The height of each bar corresponds to the frequency of data points in that bin.
Histograms are common because they serve several critical purposes in data analysis:
Since we’ve understood frequency histograms and their purpose in data analytics, let’s learn how to create one using an example.
Consider a scenario where you, as a data analyst, are tasked with analyzing the daily sales data for a retail store over the past month.
Your goal is to understand the distribution of daily sales to identify patterns, assess performance, and provide insights to help with inventory management and sales strategies. As part of the analysis, you’ve decided a histogram can help derive insights.
Here are the steps you could follow to create your frequency histogram:
Let’s say you connected with your organization’s data team and retrieved the data from your organization’s sales databases. You have organized the data in a tabular format as below:
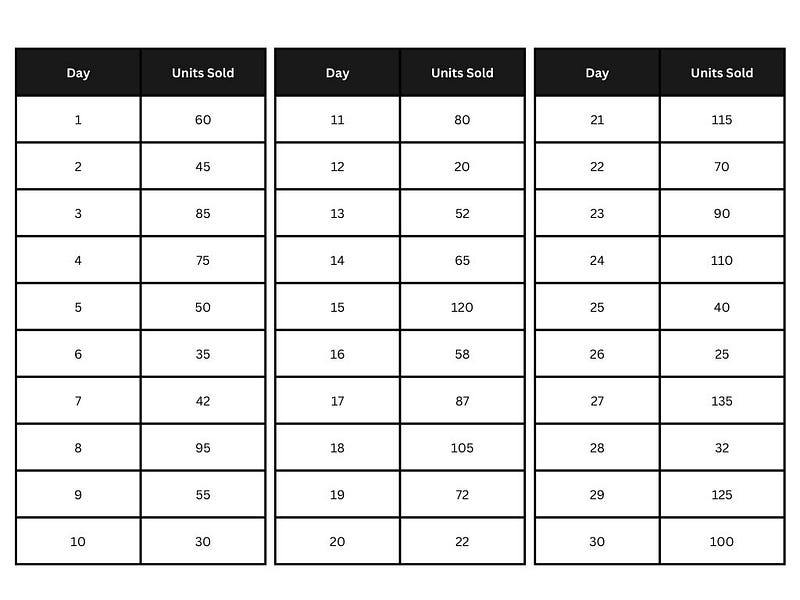 Sales dataset. Image by Author.
Sales dataset. Image by Author.
Next, choose appropriate bins based on the range and distribution of the data.
After analyzing the data, you realize the smallest value is 20, the largest is 135, and you have 30 observations. Using the square root rule (we will learn more on this topic later), √30 ≈ 5.5, you could use six bins. We must divide the range of 115 into six bins, leading to a bin width of approximately 19 units.
For simplicity, let’s use bins of width 20 units:
Let’s count the number of observations within each interval and tabulate them as shown below:
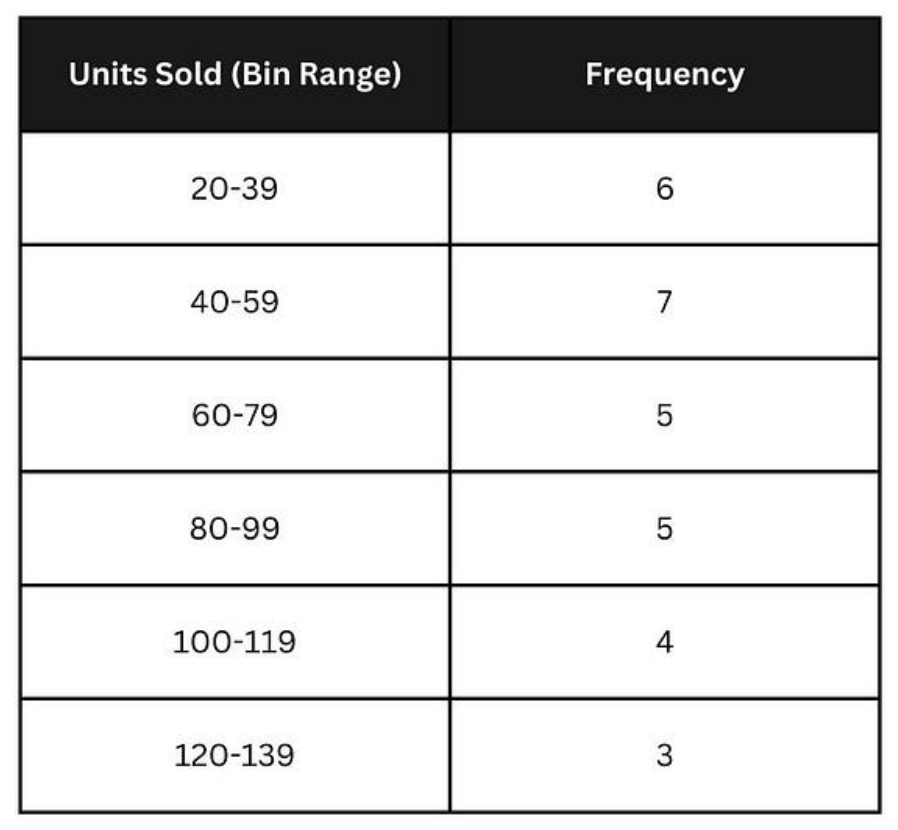
Calculating frequencies in each bin. Image by Author.
Draw a horizontal line (x-axis) for the bins and a vertical line (y-axis) for the frequencies. For each bin, draw a bar whose height corresponds to the frequency.
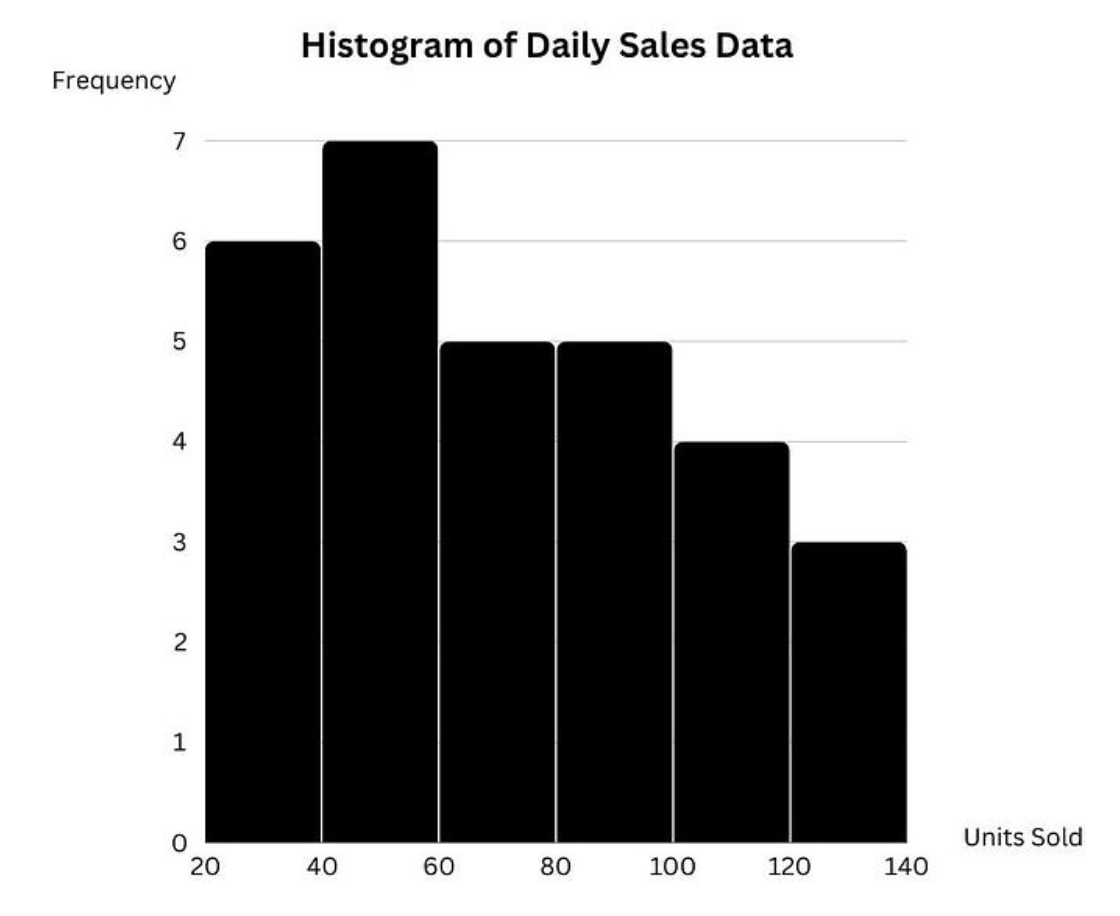
Your histogram should look something like this:
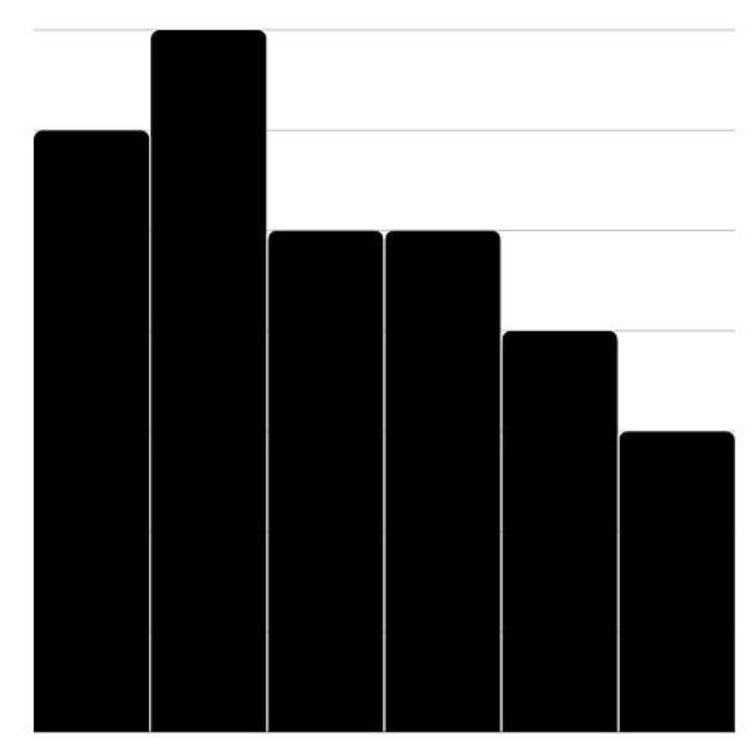 Plotting the histogram. Image by Author.
Plotting the histogram. Image by Author.
Label the x-axis “Units Sold” and the y-axis “Frequency.” Add a title such as “Histogram of Daily Sales Data.” Ensure the bars are evenly spaced and distinct for clear visualization.
The completed diagram should look like this:
Labeling and formatting the histogram. Image by Author.
That’s it! You’ve created the frequency histogram for your analysis.
There are different kinds of frequency histograms, each offering slight variations in how the data is represented.
These histogram variations allow you to uncover different insights depending on the scenarios you encounter in your analytical projects; hence, knowing these types exist can be helpful.
Though we learned to create histograms manually above, you can do so with various tools and technologies, each with different features and capabilities.
Here are some popular technologies for creating histograms:
Of course, this list is not exhaustive, and plenty of other online tools are available to create histograms. Feel free to use them and adopt the tool that best suits the needs of your analytical project.
Since histograms are perceived as one of the basic analytical diagrams, we never formally learn them, often leading to mistakes in creating them. Here are some common mistakes and the best practices to avoid them:
Choosing inappropriate bin widths can significantly impact the histogram’s appearance and accuracy.
Too-wide bins can oversimplify the data by grouping too many data points together, masking important patterns and variations within the data. This makes it difficult to see finer details and nuances in the distribution.
On the other hand, narrow bins mean that each bin covers a very small range of data values, which can result in many bins with very few data points in each. This level of detail might be unnecessary and overwhelm the viewer with too much information, making it challenging to discover any meaningful patterns or trends in the data.
Inconsistent bin sizes will lead to misleading visualization and make it harder to interpret the histograms.
First, ensure all bins in your histogram have the same width. This consistency allows for a straightforward comparison of frequencies across different intervals.
Several guidelines can help determine the appropriate bin width (and the number of bins):
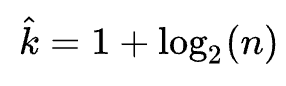 Sturges’s rule. Source: Wikipedia
Sturges’s rule. Source: Wikipedia
In practice, the best bin width is found through iterative adjustment. Start with a guideline-based bin width and then adjust up or down while evaluating the resulting histogram for clarity and informativeness.
A common mistake is to focus only on the diagram and not so much on the labels and the scales.
Viewers may not understand what the histogram represents if the axes are labeled incorrectly or inadequately.
When comparing multiple histograms, inconsistent scaling on the y-axis can distort the comparison. Suppose one histogram uses a y-axis scale from 0 to 100 and another uses 0 to 50; the heights of the bars will not be directly comparable. This inconsistency can mislead viewers into thinking some significant differences or similarities are not actually present.
Inconsistent scaling within a single histogram can also misrepresent the data. If the y-axis starts at a number other than zero or uses irregular intervals, it can exaggerate or minimize the apparent differences between bin frequencies, leading to incorrect conclusions about the data distribution.
Always label the x-axis and y-axis clearly and accurately. Specify what each axis represents and include units of measurement if applicable. Include a descriptive title that provides context for the histogram.
Use a consistent scale for the y-axis, especially when comparing multiple histograms. This ensures that the height of the bars accurately reflects the frequency or relative frequency and allows for meaningful comparisons. Ensure the y-axis starts at zero to provide a true representation of the data distribution. If starting at zero is impractical, clearly indicate the starting point and use consistent intervals.
Outliers are data points that fall significantly outside the main cluster of data, affecting the shape of the data distribution. A common mistake is to simply exclude and ignore the outliers.
Excluding them can hide the true nature of the distribution, such as the presence of a long tail or asymmetry (skewness). A dataset with a few extremely high values might show a skewed distribution if outliers are included, but it will appear more symmetric if they are removed.
Outliers can sometimes represent significant phenomena or important insights. For instance, in sales data, an outlier could represent an unusually large purchase that might indicate a successful marketing campaign or a bulk order. Ignoring such points can overlook valuable information.
Include outliers in the histogram to present a complete view of the data distribution. Ensure the y-axis scale accommodates these outliers without overly compressing the main data.
If outliers are excluded for specific reasons (e.g., errors, irrelevant extreme values), explain clearly in the accompanying text or legend. This ensures transparency and helps viewers understand the rationale behind their exclusion.
Following these best practices ensures that your histogram communicates the intended insights to viewers and helps you with downstream data analytics in analytics projects.
This article introduced you to frequency histograms, different kinds, and their importance in data analytics. After manually creating histograms, we listed a few popular tools and technologies you can use to create histograms. We also learned some common mistakes to avoid and the best practices to follow.
We encourage you to put your skills to the test and create and interpret histograms from multiple datasets to gain proficiency. Practicing analytics tasks and analyzing the results can help you become proficient in data analytics.
Happy learning!
Learn with DataCamp
Course
Course
Course
Tutorial
Kevin Babitz
Tutorial
Arunn Thevapalan
Tutorial
Aditya Sharma
Tutorial
Kurtis Pykes
Tutorial
Kevin Babitz
Tutorial
Bex Tuychiev