Course
Intermediate Python
4 hr
1.4M
Pandas is the defacto toolbox for Python data scientists to ease data analysis: you can use it, for example, before you start analyzing, to collect, explore, and format the data. Pandas makes these steps a breeze via its numerous I/O and handy data manipulation functions. What’s more, as you will learn later in this tutorial, it also has some visualizations capabilities (through the use of matplotlib).
Even though the Pandas data structures are very powerful and flexible, they also come with some complexities which can make your analysis rather harder than easier, especially for beginners. In this tutorial, you’ll focus on learning more about how you can save yourself a headache and write more idiomatic Pandas code. Besides learning how you can load, explore and clean the data, you’ll learn more about the following five topics:
Of course, this tutorial is by no means exhaustive; The Pandas package is very rich and there are, without a doubt, other ways in which you might improve your Pandas code so that it becomes more idiomatic.
Let’s not wait any longer and get started!
As always, your data analysis starts with loading and exploring your data. This section is just a warm-up in which you’ll use the read_csv() function to load in world university rankings, after which you can already quickly explore your data with the functions head() and describe(). If you’re interested in a full introduction to Pandas, consider taking DataCamp’s three-part Pandas course, starting with the Pandas Foundations.
If you already know all of this, you can just skip this section and see how you can perform indexing with Pandas in a more idiomatic way.
To start, let’s import the usual Python packages for data science. As you might have guessed, Pandas is among these.
# If you're working with a notebook, don't forget to use Matplotlib magic!
%matplotlib inline
# Import pandas under the alias pd import pandas as pd # Import seaborn under the alias sns import seaborn as sns # Set the Seaborn theme if desired sns.set_style('darkgrid')Moreover, you can also use the watermark package: it is a nice tool that makes your notebook more reproducible. Reproducible work is very important when collaborating with colleagues. Your future self will thank you for that as well! You can read more about reproducible data science here.
In order to start this tutorial, you will also need to fetch some “real” world data. For this tutorial, you will be working with a dataset from Kaggle. If you are unfamiliar with Kaggle, it is one of the biggest data science and machine learning communities. Moreover, it is a good place to learn more about data science once you know the basics.
The dataset that you’ll be using is the World University Rankings.
As mentioned above, Pandas has many convenient method to read data from different data sources (you can learn more about it here). Since the data is in a CSV format, we will be using the .read_csv method. But before starting, you need to download the data from Kaggle (or get it from the code repository under the data folder if you don’t want to create an account).
Once you have fetched the data, you should have a folder data that contains the different csv files.
Next, you will be working with the Times Higher Education World University Rankings ranking (Times for short) and Academic Ranking of World Universities (Shanghai for short) ranking data. There is also a third ranking system in the data folder CWUR but it is much less known so you can safely ignore it for now.
# Import Times Higher Education World University Rankings data
times_df = pd.read_csv('data/timesData.csv', thousands=",")
# Import Academic Ranking of World Universities data
shanghai_df = pd.read_csv('data/shanghaiData.csv')As you have learned in the DataCamp’s Exploratory Data Analysis tutorial, Pandas offers some methods to quickly inspect DataFrames, namely .head() to inspect the first n rows (n being 5 by default) and .describe() to get a quick statistical summary.
Refresh these functions by executing the following lines of code. The data has been loaded in already for you under the variables times_df and shanghai_df:
Now that you have loaded in your data, you can start thinking about how you can manipulate the data with Pandas in an idiomatic way!
First off, writing more idiomatic Pandas code means leveraging the power of indexing. Indexing means that you select subsets from your DataFrame.
When you’re just starting out with Pandas, you might need some time to get used to how indexes work. In fact, if you have worked before with (Python) lists, you might be already familiar with the use of square brackets [] in combination with the colon : to select elements. This method works on DataFrames.
In addition, there are two other, more idiomatic ways to select a subset DataFrame. These two methods are namely iloc and loc:
loc is label-based. This means that if you write loc[2], you are looking for the values of your DataFrame that have an index labeled 2.iloc is position-based. This means that if you write iloc[2], you are looking for the values of your DataFrame that are at index 2.Try this out in the DataCamp Light chunk below by typing times_df.loc[2] and times_df.iloc[2] in the IPython console to see the difference. Next, try solving the exercise below with the help of loc, iloc and the traditional square brackets!
Of course, your exploration can go a lot further than just simply subsetting or selecting from rows and columns of your data. Things can get very interesting when you combine the loc and iloc with, for example, boolean arrays.
You see that this goes somewhat beyond selecting data on the basis of columns or indexing; It’s somewhat like querying your data!
loc and iloc are great to index your data, but be careful when you start using two sets of square brackets after each other! Pandas could return a copy of a view and in such cases, you wouldn't know with what you're still working! So think twice if you're using two sets of square brackets in combination with loc or iloc.
Note also that, to query your data, Pandas also provides you with a query() function which you can use to quickly inspect your data (available since version 0.13). For example, you can compose a query to see which universities have a total_score that is slightly below 50:
Of course, there are many more possibilities when it comes to querying your data! Why not try out to come up with some queries and test them in the IPython console of the above DataCamp Light chunk?
If you’re short on inspiration, try queries that return the universities with a first national rank and universities with a first world rank. Additionally, you can query the alumni numbers of the universities.
Are you lost on how to compose the queries? Check out some of the examples below:
shanghai_df.query("national_rank == 1 and world_rank == 1")
shanghai_df.query("alumni < 20")Method chaining is something typical of Pandas, but when you’re just starting out with the Python data manipulation package, it might not be straightforward how this exactly works. It’s basically calling methods on an object one after another.
In this section, you will go deeper into method chaining by creating data pipelines with pipe().
As you have already noticed, the datasets are quite different. Here are some of the differences:
Thus, in order for us to use both DataFrames, we will need to only select the common columns. Hopefully, these common columns have similar content.
The common columns are thus:
total_score: Score used to determine rank. As mentioned in the Kaggle description page, these contain range ranks (i.e. between two values) and equal ranks (there is an = sign in front)university_name: University nameworld_rank: Rank of the universityyear: Year for which the ranking is doneIn order to concatenate both data, we need to do some cleaning first. Then apply the complete pipeline now to clean the data:
As you have probably noticed, I use the .pipe method a lot in this tutorial. If you come from the R world, you should probably be (somehow) familiar with it.
It is a handy new Pandas (since 0.16.2 version) method that allows you to chain operations and thus eliminate the need for intermediate DataFrames. Your code becomes more readable.
In fact, without this operator, instead of writing df.pipe(f).pipe(g).pipe(h) you would write: h(g(f(df))). This becomes harder to follow once the number of nested functions grows large.
To learn more about the subject, I highly recommend reading the following blog post.
Now that both DataFrames are cleaned, we can concatenate them into a single DataFrame. Also, don’t forget to clean the missing data:
Since you have around 38% of data missing from the total_score column, it’s better to drop this column with the .drop method.
A third way of making your Pandas code more “idiomatic” -which is in this case more equal to “performant”- is by optimizing the memory usage. Especially when you start making data pipelines by using method chaining, you’ll see that memory can start to play a big part in how fast your pipelines can run. You’ll see more on all of this here.
This is probably overkill for this small dataset but it is often a good practice to cast some columns to specific types to optimize the memory usage. To start, let’s find how much memory is allocated for ranking_df using the .info method.
The result of the first line of code tells us that the data takes 144 KB. However, upon inspecting the arguments of the .info method, one finds out that there is an optional one namely memory_usage that is set to None by default. What happens when you set the argument memory_usage to deep?
The new memory footprint is 6 -5.6 to be more precise- times larger than your initial answer.
What happened here?
The difference in the memory estimation stems from the fact that without the “deep” flag turned on, Pandas won’t estimate memory consumption for the object dtype. This (Python) type of data takes more space than other numpy optimized dtypes. This is why it is recommended to cast object types to more appropriate ones (let’s say category when dealing with categorical data).
Let’s do it!
def memory_change(input_df, column, dtype):
df = input_df.copy()
old = round(df[column].memory_usage(deep=True) / 1024, 2) # In KB
new = round(df[column].astype(dtype).memory_usage(deep=True) / 1024, 2)# In KB
change = round(100 * (old - new) / (old), 2)
report = ("The inital memory footprint for {column} is: {old}KB.\n"
"The casted {column} now takes: {new}KB.\n"
"A change of {change} %.").format(**locals())
return report
print(memory_change(ranking_df,'world_rank', 'int16'))
print(memory_change(ranking_df,'university_name', 'category'))
print(memory_change(ranking_df,'name', 'category'))Now that you know that, by changing the world_rank to int16, for example, your memory will be used more efficiently, it’s time to actually apply these changes. You can use the astype() function to do this. End by double-checking what your memory usage looks like now:
That’s much better. You can optimize even further by casting the year column down to int32.
Now that we have a well-formed data set (i.e. it is in a tidy state) with an optimized memory footprint, data analysis can start.
Now there are some questions that you might be interested in answering:
Let’s find out by tackling the first question by making use of the more idiomatic Pandas pointers that you have already seen in the previous sections!
Before you start, notice that ‘Massachusetts Institute of Technology (MIT)’ and ‘Massachusetts Institute of Technology’ are two different records of the same university. Thus, you change the first name to the latter.
Note that in cases like these, the loc function, which you saw earlier in this tutorial, comes in particularly handy!
To find the 5 (more generally n) top universities over the years, for each ranking system, here is how to do it in pseudo-code:
year column) and for each ranking system (in the name column):Let’s apply this.
Now that we have this ranking dictionary, let’s find out how much (in percentage) both ranking methods differ over the years: the two are 100% set-similar if the selected 5-top universities are the same even though they aren’t ranked the same.
As you have noticed, this was tedious. Is there a better, more idiomatic Pandas way?
Of course, there is! Firstly, filter the ranking DataFrame to only keep the 5 top universities for each year and ranking method. Also check out the result with the help of the head() function:
Now that you have the correct DataFrame to work with, let’s use the .groupby method to compare both ranking methods using the set similarity defined above.
You get the same results as above with less hassle.
Now that you have gone through some initial analysis of your data sets, it’s also time to explore your data visually. More idiomatic Pandas code also means that you make use of Pandas’ plotting integration with the Matplotlib package. Because of this, you’ll make great plots in no time!
For this section, you’ll go back to the times_df and shanghai_df datasets to make some basic visualizations with Matplotlib and Seaborn.
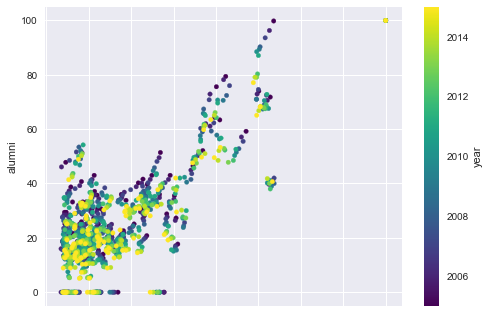
The above plot immediately makes clear that there are some 0 values for the alumni column. This is something to definitley take into account when you’re exploring your data: with the help of data profiling, you’ll be able to see these 0 values and be able to handle them. If you’d like to know more about this, check out DataCamp’s Data Profiling Tutorial.
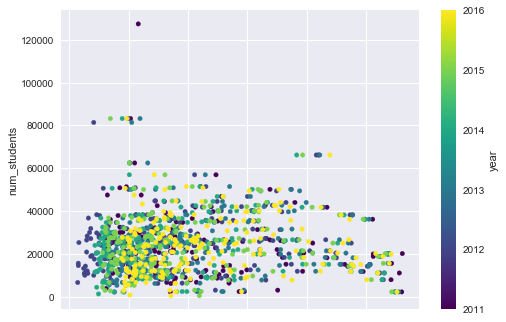
Or, in case you have values that don’t have a place in your data set, you can simply replace them by NaN and then remove all the NaN values of the columns which would make plotting the data more difficult. Note that this is just a quick way of adjusting your data and that you probably need a more elaborate data profiling step to make sure that your data quality improves because you still see 0 values for the num_students column in the plot below:
Of course, you don’t need to limit yourself to Matplotlib to visualize your data. There are also other libraries out there that allow you to quickly visualize your data, such as Seaborn.
The Seaborn plotting tool is mainly used to create statistical plots that are visually appealing (as stated in the official website). In fact, prior to version 2.0 of Matplotlib, it was a hassle (though possible) to create beautiful plots.
The combination of Pandas with Seaborn also allows you to quickly iterate over your data by means of visualizations.
Let’s explore some examples!
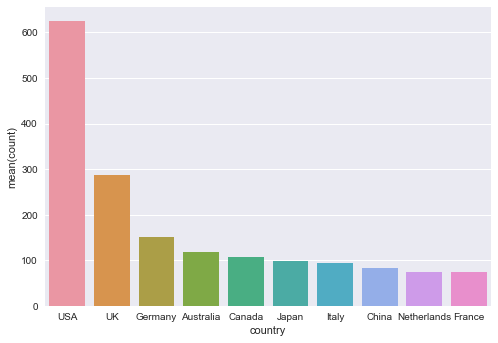
Take a look at the following plot, where you count the number of times a specific country appears in your data, you take the first ten observations and you make sure that you sort the counts from highest to lowest value when you plot the barplot:
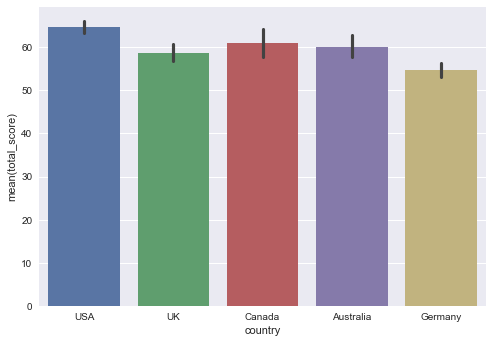
Then, you can go on and plot these countries and their mean scores:
Your plots can also get pretty complex. Look at the following pairplot, which is designed to show you the pairwise relationships in a dataset more clearly:
import numpy as np
np.seterr(invalid='ignore')
sns.pairplot(times_df, hue='country')
plt.show()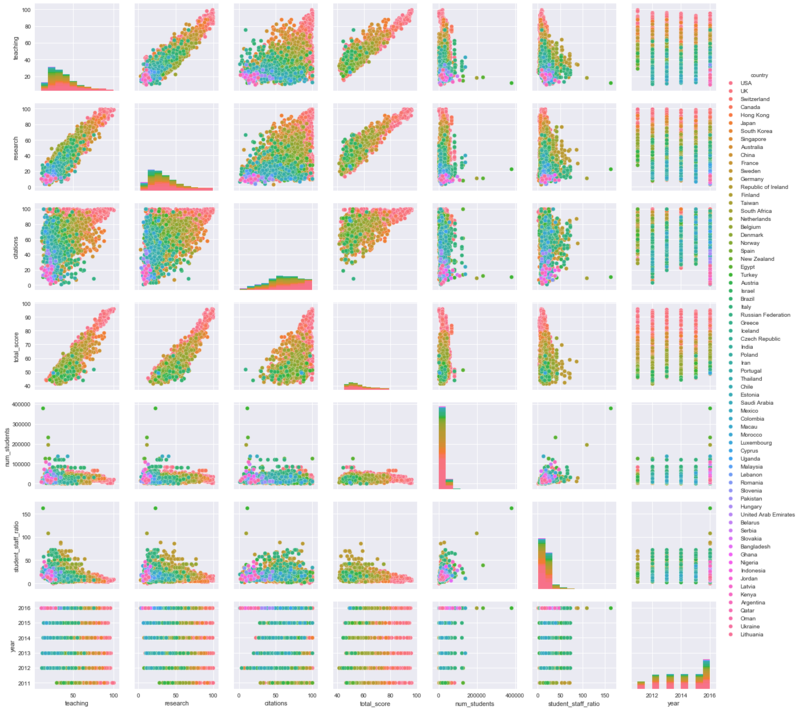
Likewise, you can check out this combination of FacetGrid and regplot, which gives you some insights on the evolution of the total_score over the years for the top 5 countries:

Lastly, also a correlation plot might come in handy when you’re exploring your data. You can use the heatmap() function from Seaborn to get this done:
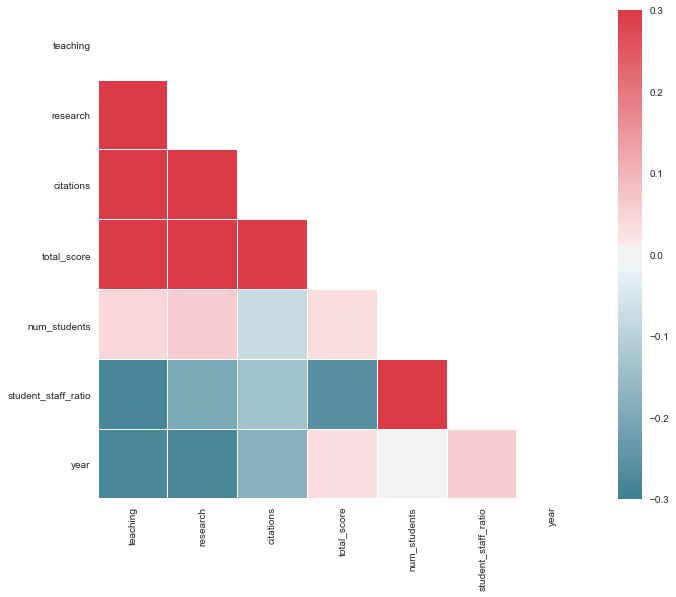
You can keep going on and on with these visualizations, so maybe it’s best to stop for now :)
That’s it for this time, I hope you have enjoyed learning some intermediate techniques working with Pandas and more specifically how to write more idiomatic Pandas code.
If you have enjoyed this blog post and want to dig deeper about performance in Pandas, I highly recommend the following additional material:
Pandas Courses
Course
Course
Course
blog
Javier Canales Luna
13 min
cheat-sheet
Karlijn Willems
cheat-sheet
Karlijn Willems
Tutorial
Vidhi Chugh
Tutorial
DataCamp Team



