Course
Introduction to Python
4 hr
6.9M
Python won the TIOBE "Language of the Year" award three times in the last four years. The popular programming language is still on top of the TIOBE index halfway through 2022.
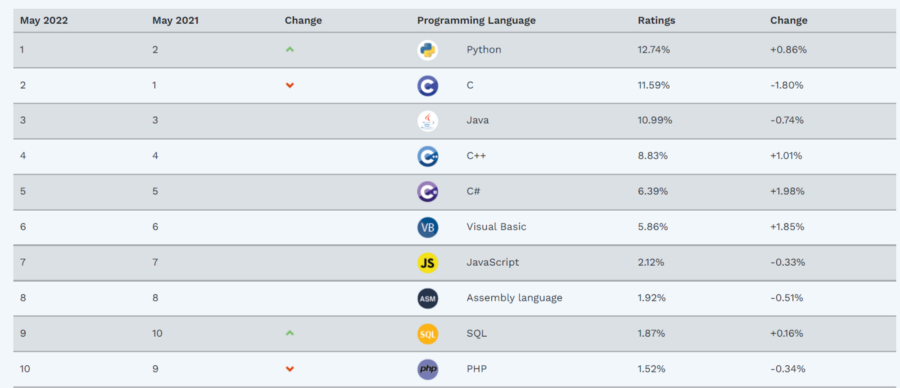
Python sits atop the TIOBE Index for June 2022.
Python having ratings of 12.74% means that the keyword “Python” popped up in about ~13% of all programming-related search engine queries. In other words, every 7th or 8th programming question on the Internet is about Python.
Today, Python is frequently associated with the biggest breakthroughs in data science and AI. Practitioners appreciate its simplicity, its large set of built-in and third-party libraries for a multitude of tasks, and its community.
With the final stable version of 3.11 coming on October 3, 2022, the Python community can look forward to various welcome updates, including a significant speed increase, better error handling and debugging, and numerous quality-of-life improvements to standard libraries.
The Python 3.11 changelog consists of a nearly endless list of bug fixes, improvements, and additions, most of which you may never even notice. However, a few critical new features might considerably improve your Python workflow when the stable release comes. These new features are outlined below.
The first significant change that will excite data scientists is speed improvement—the standard benchmark suite runs about 25% faster compared to 3.10. The Python docs claim 3.11 can be up to 60% faster in some instances. Here’s how to perform the benchmark test yourself in order to test speed improvements for yourself.
To compare the speeds of Python 3.10 and 3.11, you will need a Docker installation. After making sure Docker desktop is running, run these two commands in the terminal, which will download two images for the two versions of Python.
$ docker run -d python:3.10.4-bullseye
$ docker run -d python:3.11-rc-bullseyeThe downloaded images should be visible in your Docker dashboard, where you can also fire them up.
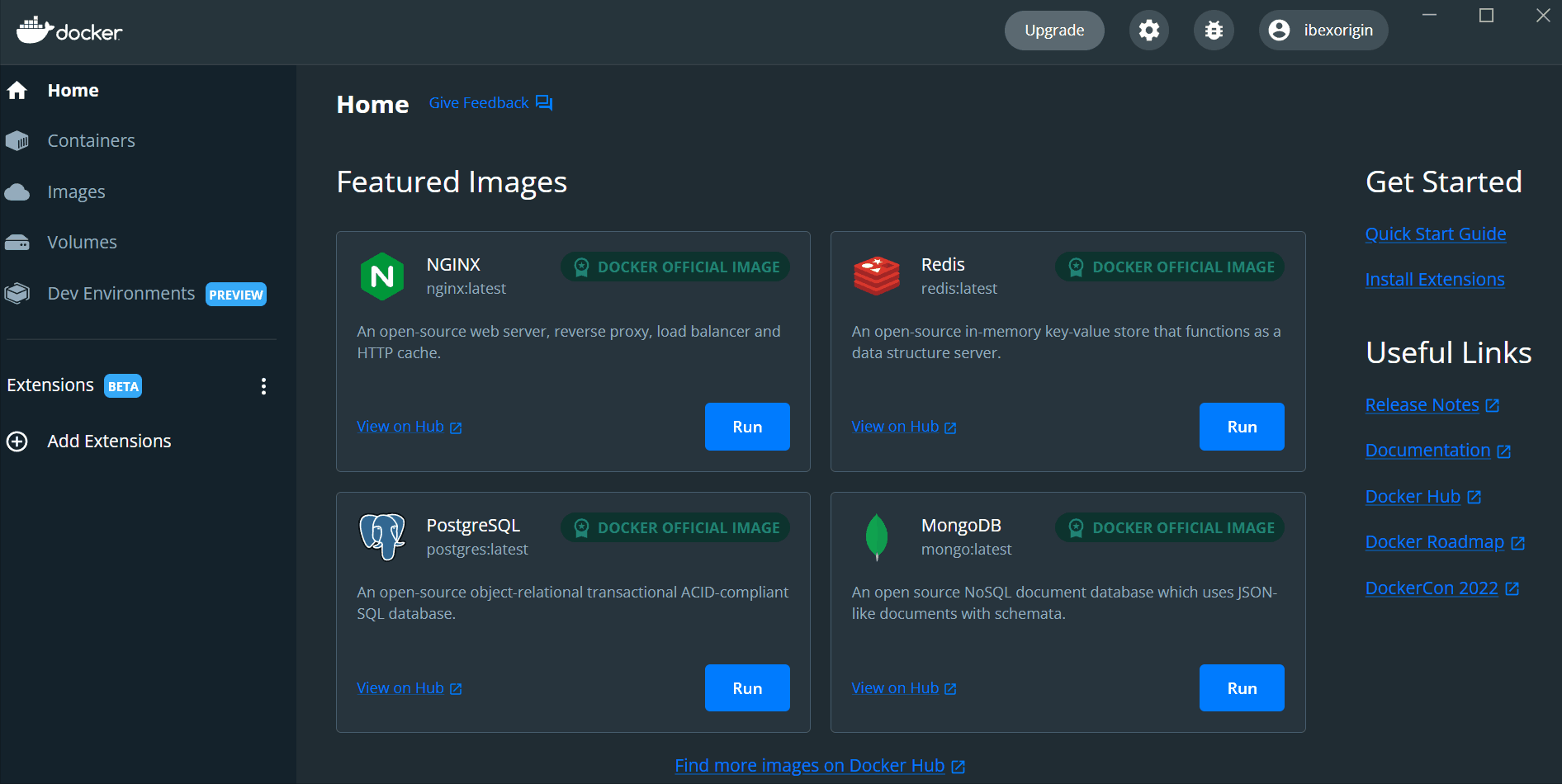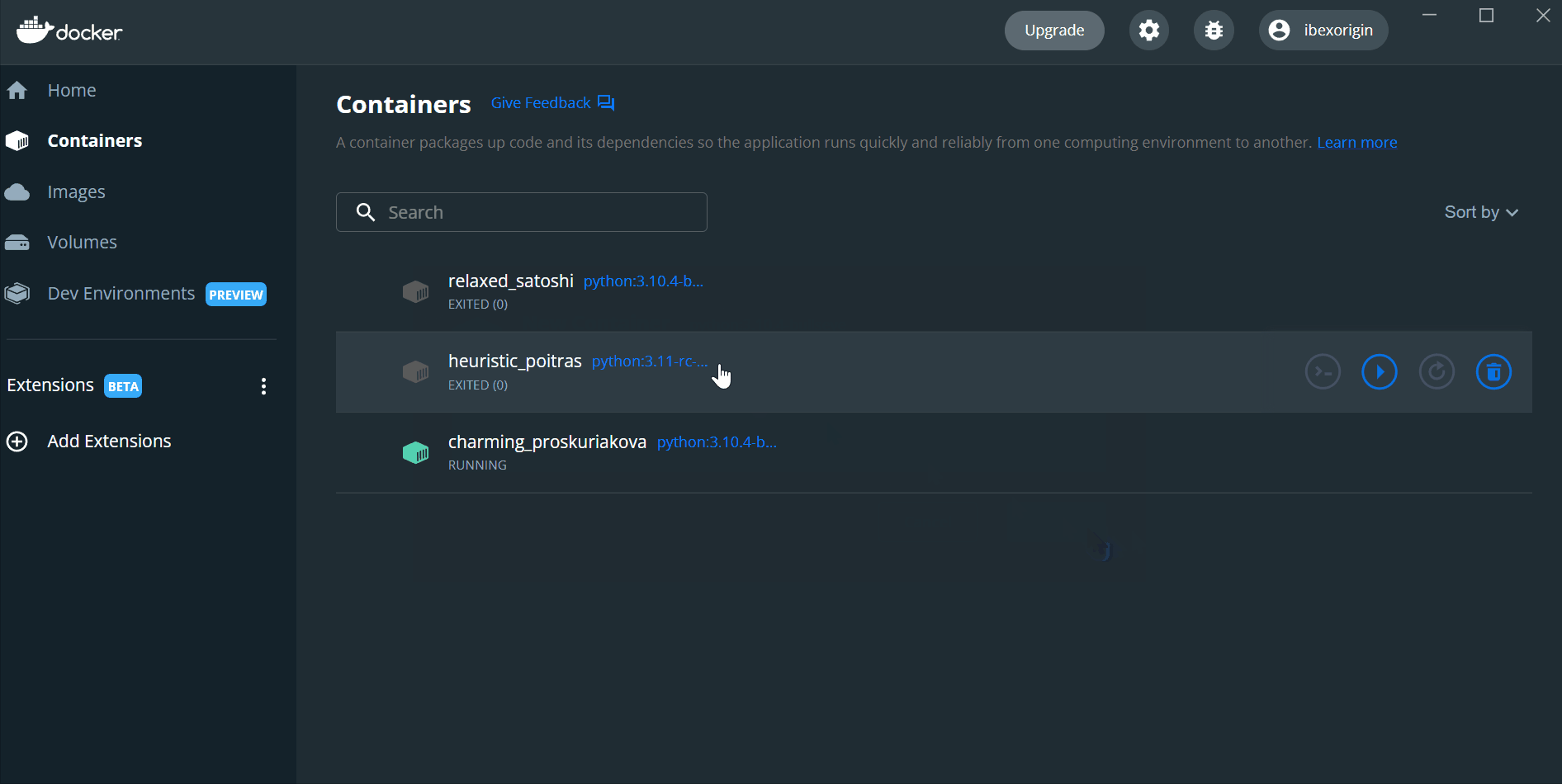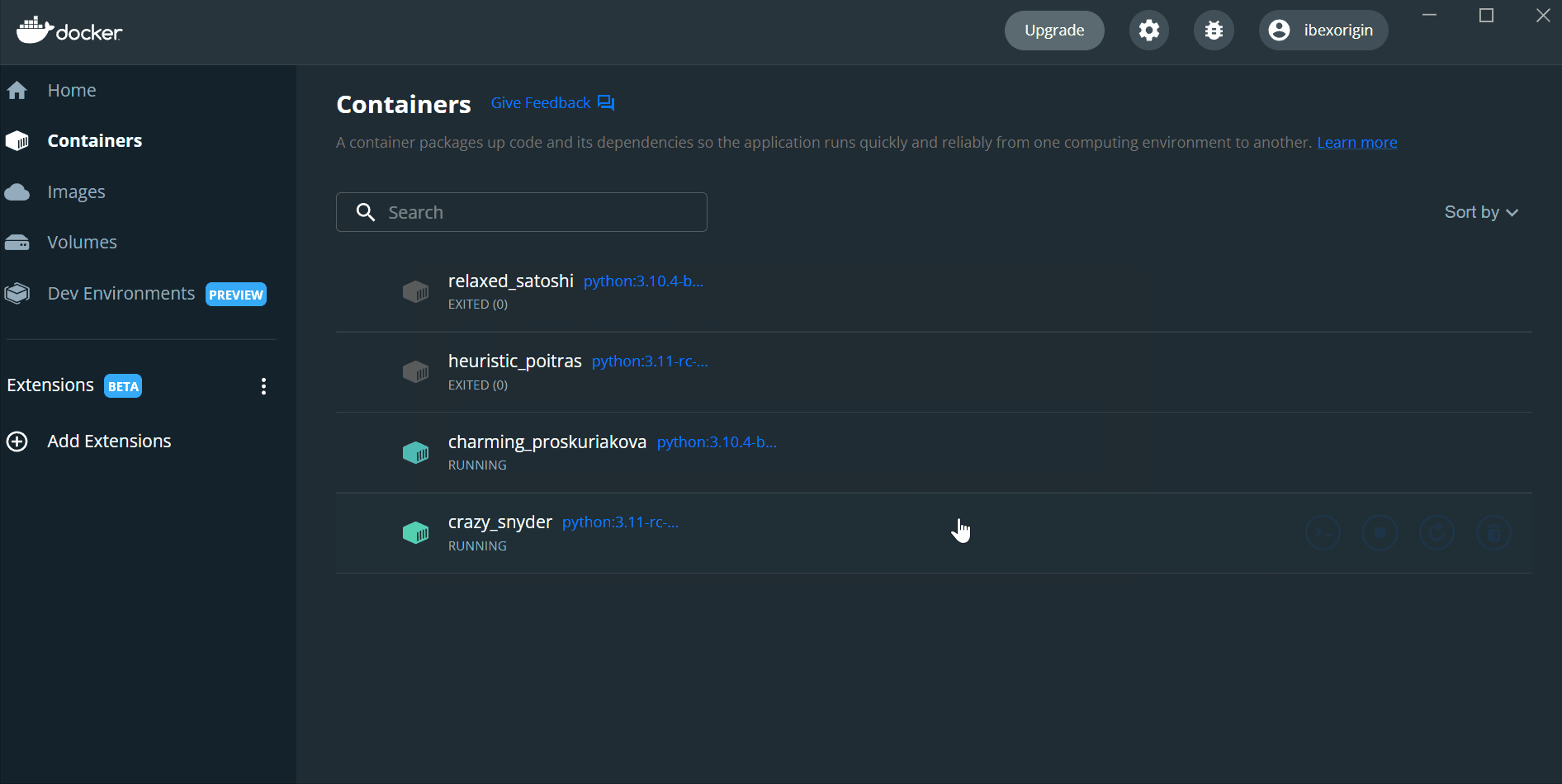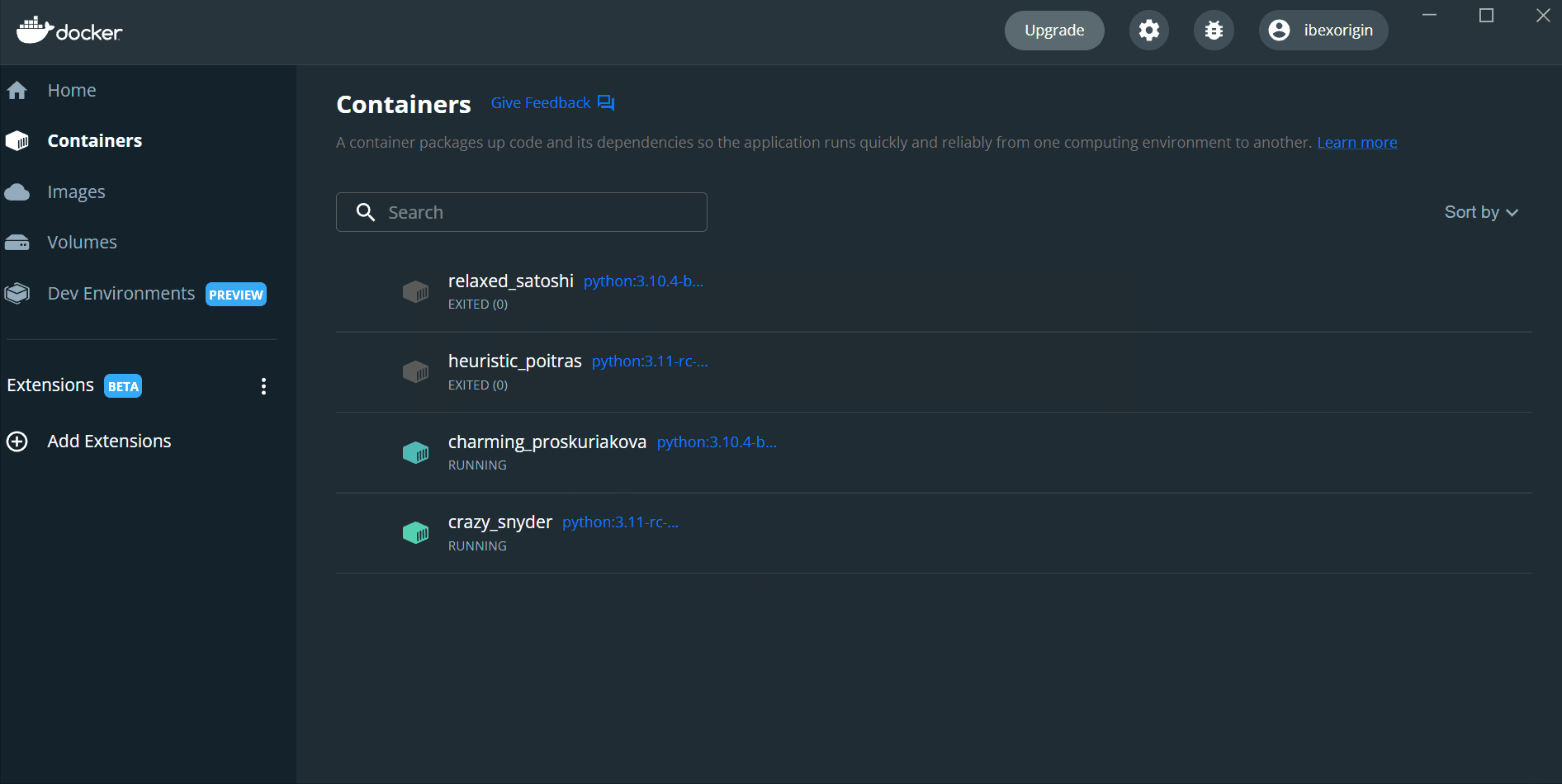
After you launch the containers, you can run docker ps to see details like container ID, the image, its status, and more.

The running containers are also visible under the Containers tab in your dashboard, where you will also find CLI buttons next to "Run/Stop" Click them for both containers to launch two terminal tabs attached to the containers.
In both tabs, install the pyperformance package via pip. Then, run the below commands in each container terminal.
$ pyperformance run -r -o py310.json$ pyperformance run -r -o py310.jsone run -r -o py311.jsonThese commands will run benchmark tests for about 60 Python functions from standard libraries and produce JSON metadata. I've optionally added the -r tag to tell pyperformance I want the tests to be rigorous, which takes more time. In my case, both containers are running on a Windows machine with an AMD Ryzen 12-core CPU.
Now, we have two JSON files in two containers, and we will need to put both in a single directory to continue the speed test. For that, we will use the docker cp command to copy the JSON file from Python 3.11 container to 3.10.
Run the below commands in a separate terminal tab, updating the path to reflect the proper path on your computer:
$ docker cp crazy_snyder:/py311.json C:/Users/bex/Desktop
$ docker cp C:/Users/bex/Desktop/py311.json charming_proskuriakova:/In my case, crazy_snyder and charming_proskuriakova are the IDs of the running containers. Now both JSON files are in the Python 3.10 container. To complete the benchmark and save the results as a CSV, run the below commands.
$ pyperformance compare py310.json py311.json --csv comparison.csv
$ docker cp charming_proskuriakova:/comparison.csv C:/Users/bex/Desktop/articlesFinally, let's load the CSV into Pandas and analyze it:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.read_csv("data/comparison.csv")
df.rename({"Base": "py310", "Changed": "py311", "Benchmark": "function"},
axis=1,
inplace=True)>>> df.shape
(59, 3)>>> df.sample(5)
| Function | py310 | py311 | |
| 40 | scimark_monte_carlo |
0.12392 | 0.08052 |
| 19 | mako |
0.01967 | 0.01289 |
| 1 | chameleon |
0.01131 | 0.00843 |
| 8 | float |
0.14265 | 0.09133 |
| 35 | regex_effbot |
0.00315 | 0.00261 |
Each row in the dataframe records how much time it took (in milliseconds) for both versions to run the given Python function. Let's plot a histogram of speedups.
df["speed_up"] = (df["py310"] / df["py311"]).round(3)
fig, ax = plt.subplots()
sns.histplot(df["speed_up"], bins=11)
ax.set(xlabel="Speedup (times)",
title="Python 3.10 vs. Python 3.11 - speedup comparison")
plt.show()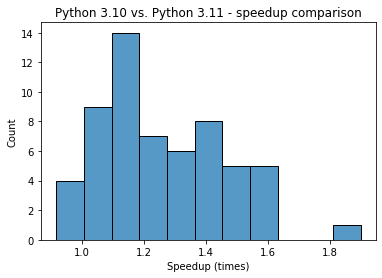
It is clear from the plot that the majority of functions in Python 3.11 were about 1.2 times (20%) faster. We can also confirm the estimate with the mean and median.
>>> df["speed_up"].mean()
1.2605593220338982>>> df["speed_up"].median()
1.207It seems there is one case where speed increase exceeded 60%.
>>> df["speed_up"].max()
1.899There are also four cases where Python 3.10 was faster than the new version.
>>> (df["speed_up"] <= 1).sum()
4While the performance increases are noticeable on paper, the specific impact of the improvements will vary from person to person and the stable, final version of Python 3.11 is yet to be released. The benchmark test uses pure Python functions, which you may not use much in your everyday work, but setting up a Docker installation for both Python 3.10 and 3.11 will allow you to get an idea of speed increases for your specific use-cases.
Another exciting feature of Python 3.11 is better error messaging that pinpoints the exact location of the error. Rather than returning a 100-line traceback ending in an error message that’s hard to interpret, Python 3.11 points to the exact expression which caused the error.

In the above example, the Python interpreter points to the x that crashed the script because of its None value. The error would have been ambiguous in current versions of Python as there are two objects with the ‘x’ attribute. However, 3.11’s error handling clearly points out the problematic expression.
This example shows how 3.11 pinpoints an error from a deeply nested dictionary and can clearly show which key the error belongs to.
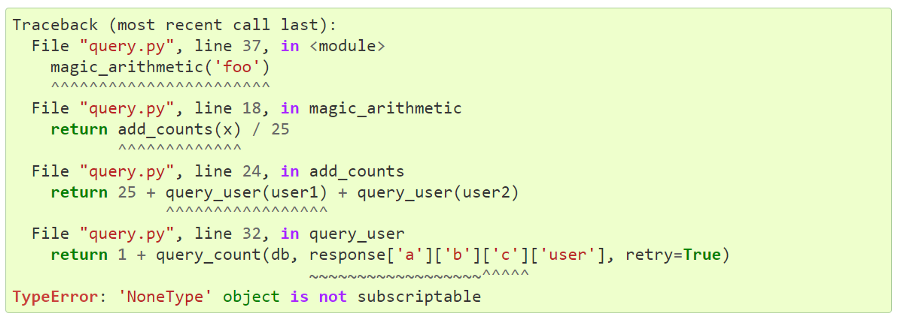
You can see the same precision in complex arithmetic expressions.

The updated error messages are definitely a welcome addition, especially for data scientists who struggle with debugging scripts.
“Explicit is better than implicit.”
The above sentence is the second line of the Zen of Python, a list of the 20 design principles of Python. This one represents the rule that Python code should be as expressive as possible.
To reinforce this design pattern, Python 3.11 introduces exception notes (PEP 678). Now, inside your except clauses, you can call the add_note() function and pass a custom message when you raise an error.
import math
try:
math.sqrt(-1)
except ValueError as e:
e.add_note("Negative value passed! Please try again.")
raise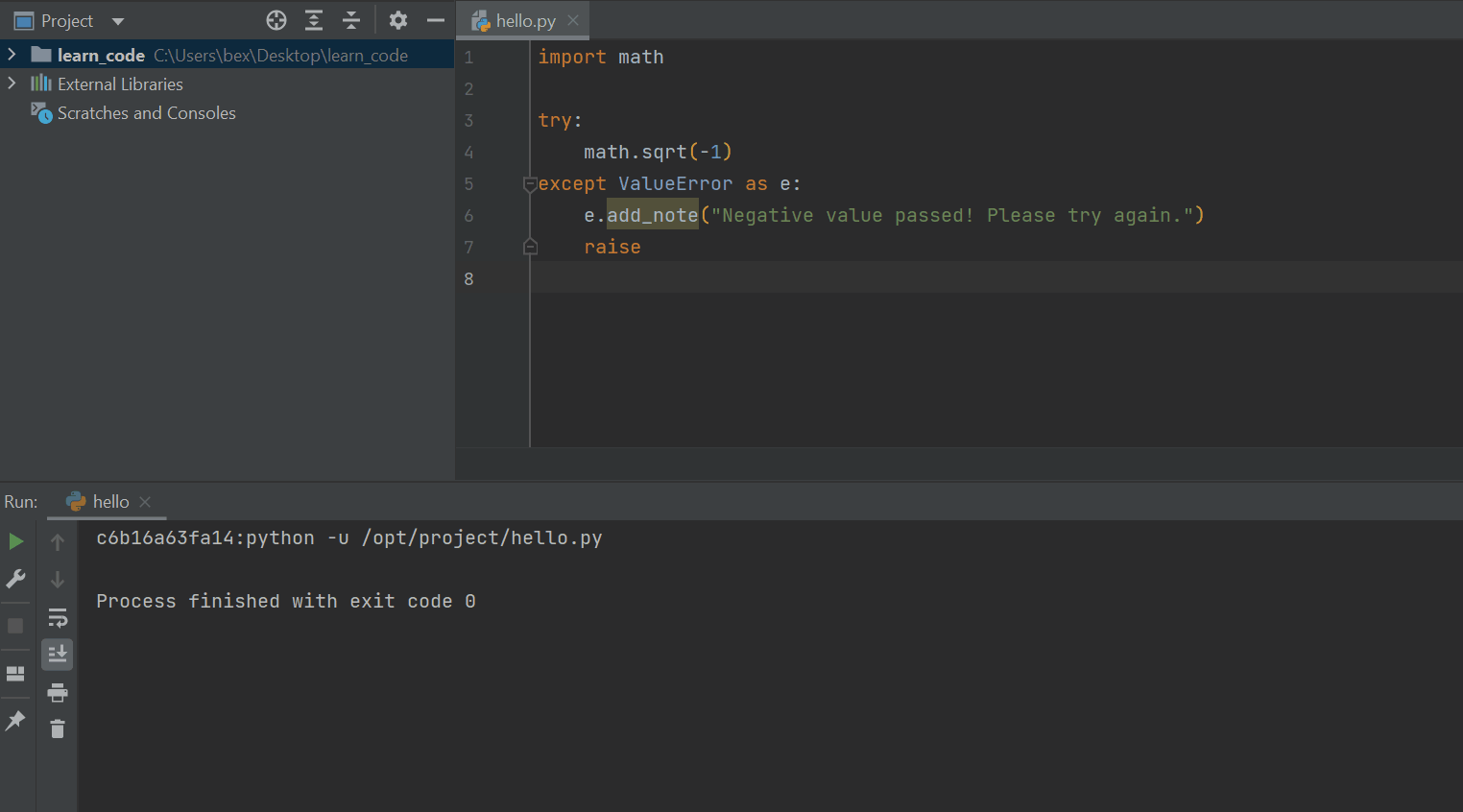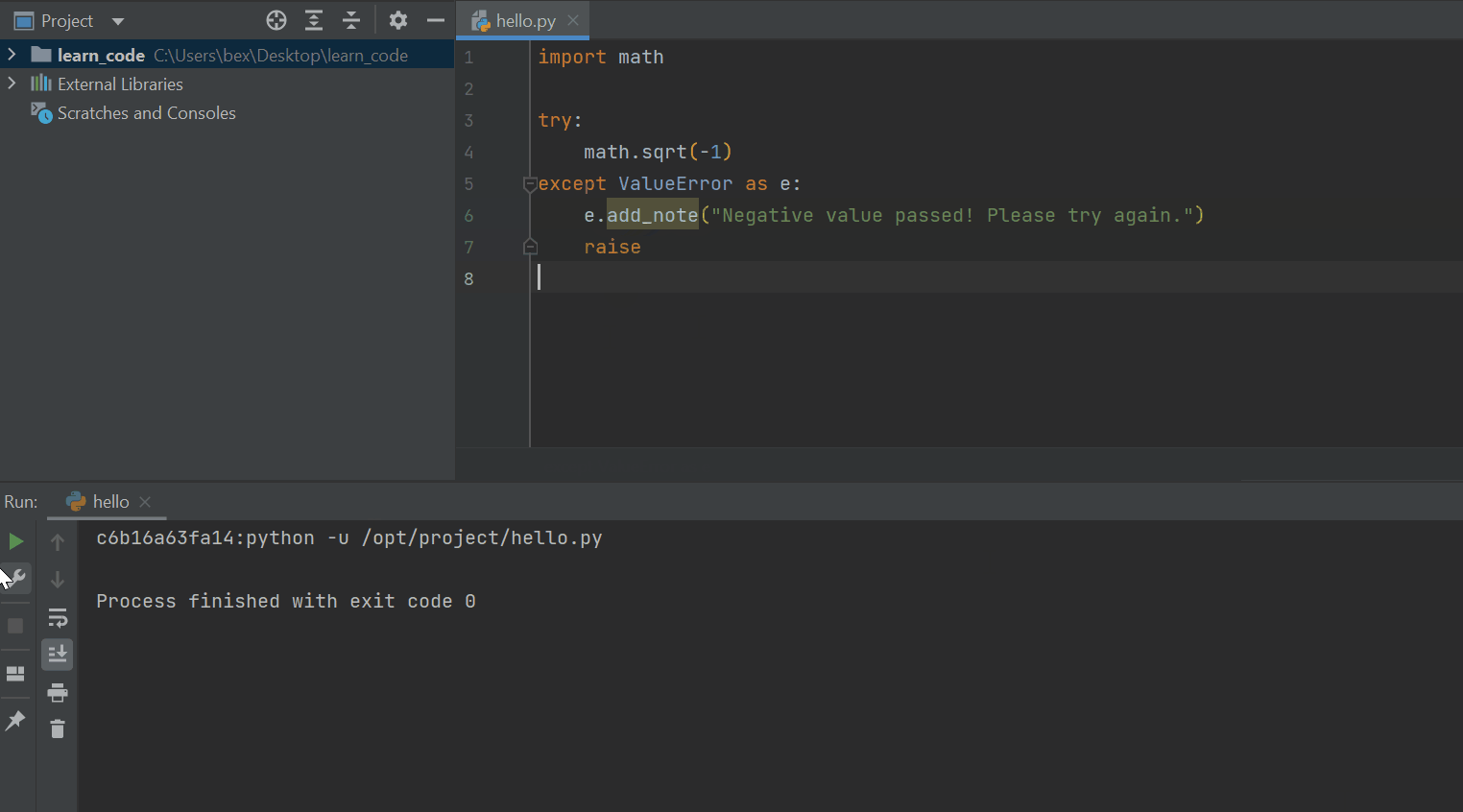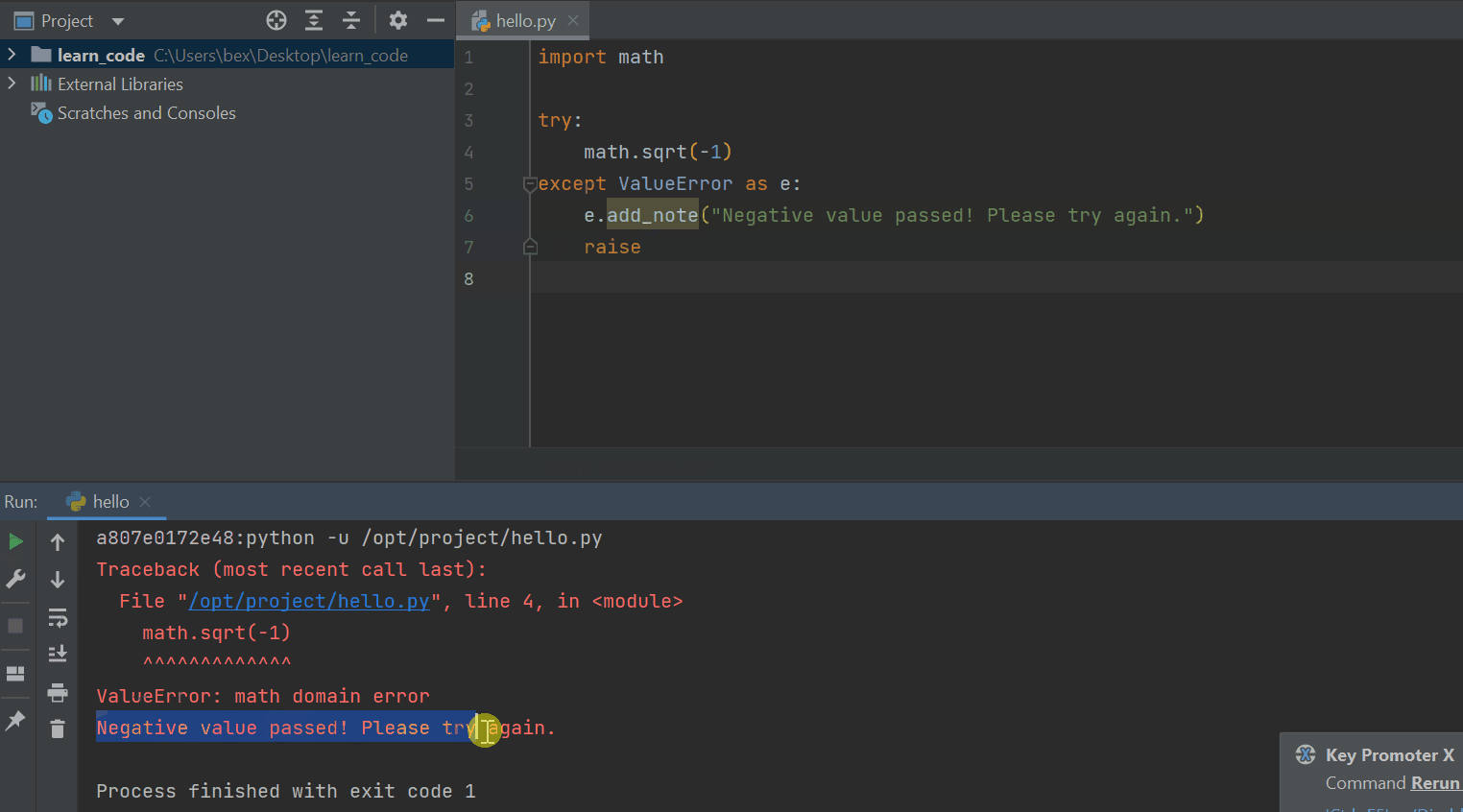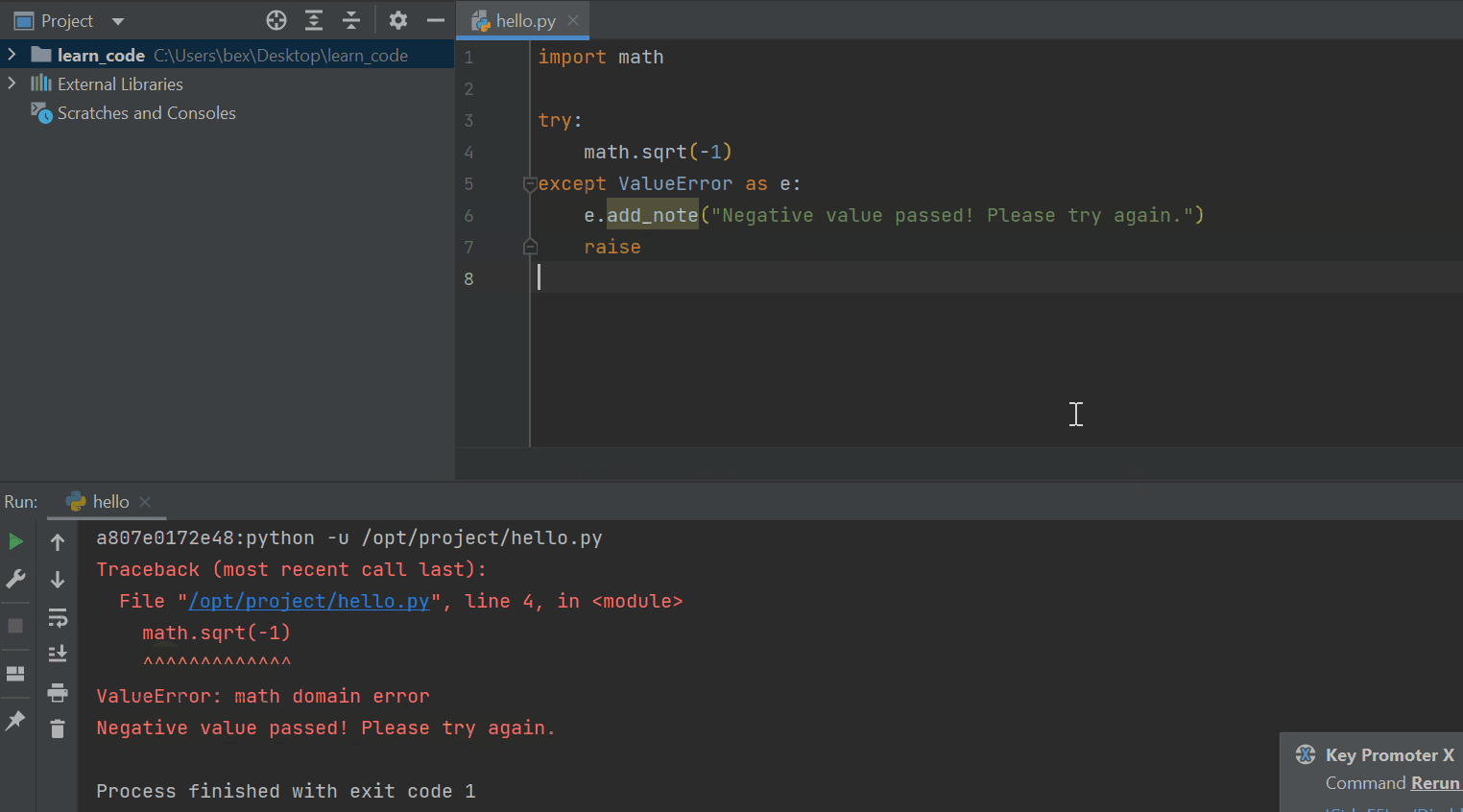
If you have written a custom exception class like below, you can add multiple notes to the class inside the protected class-level attribute __notes__:
import math
class MyOwnError(Exception):
# Should be a list of strings
__notes__ = ["This is a custom error!"]
try:
math.sqrt(-1)
except:
raise MyOwnError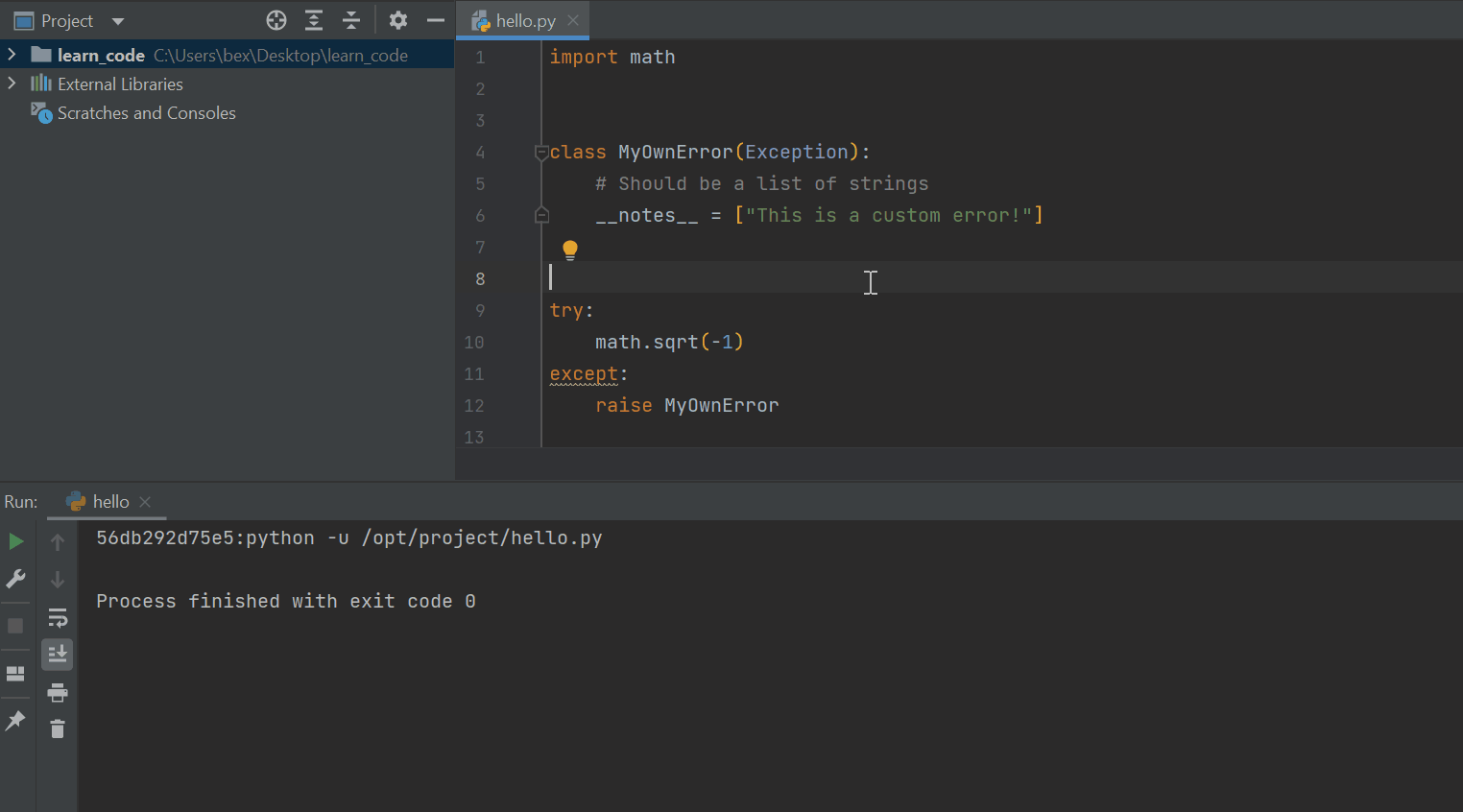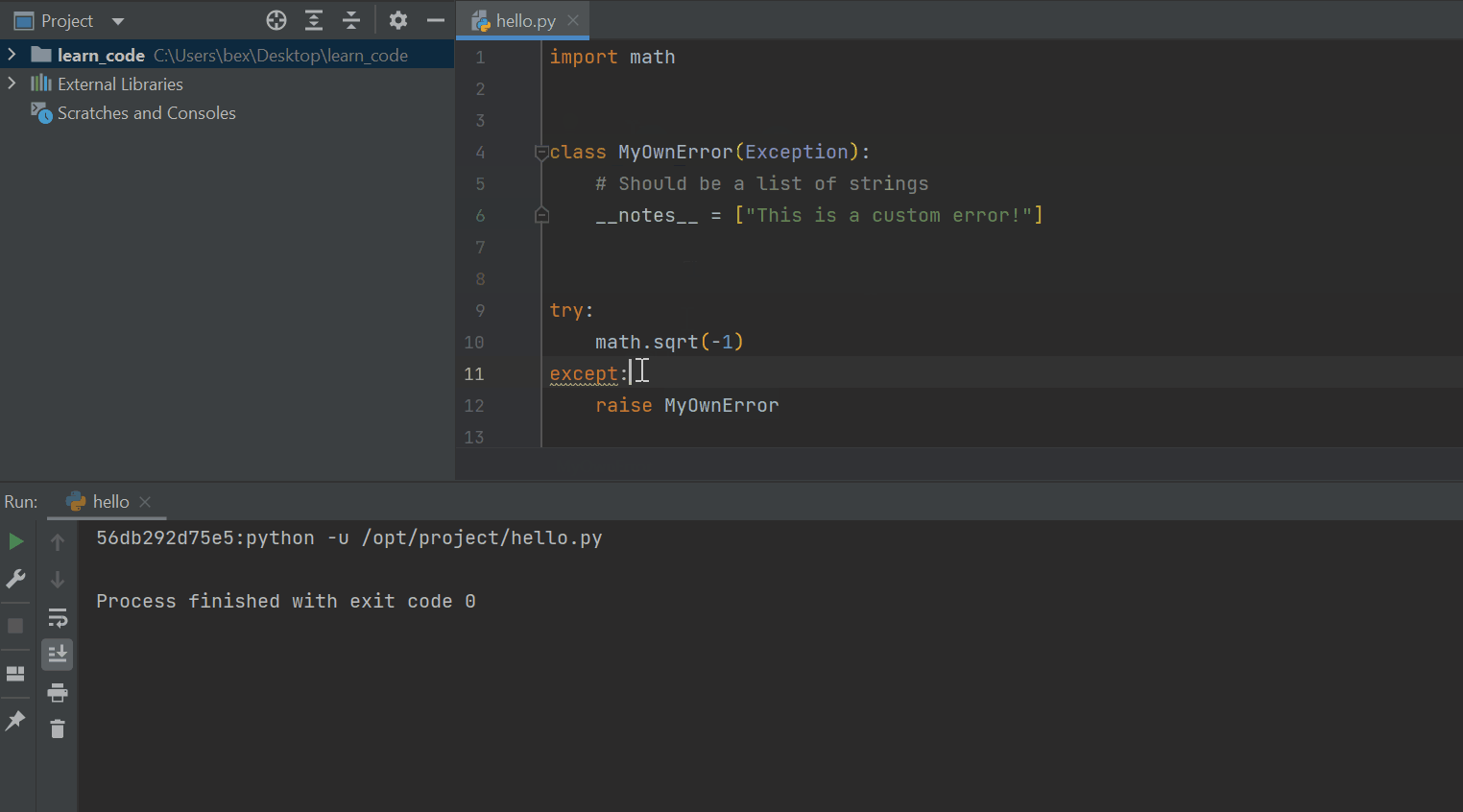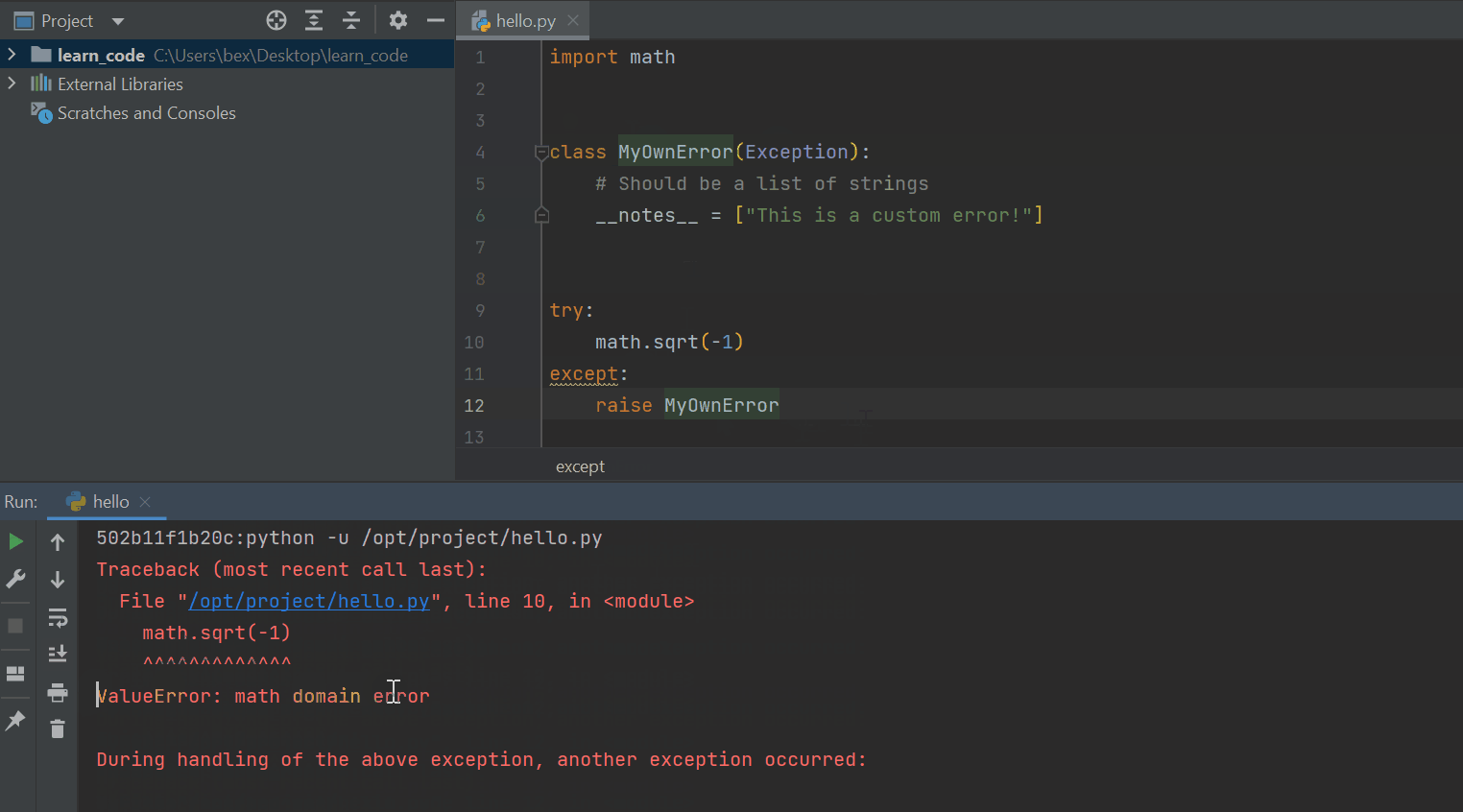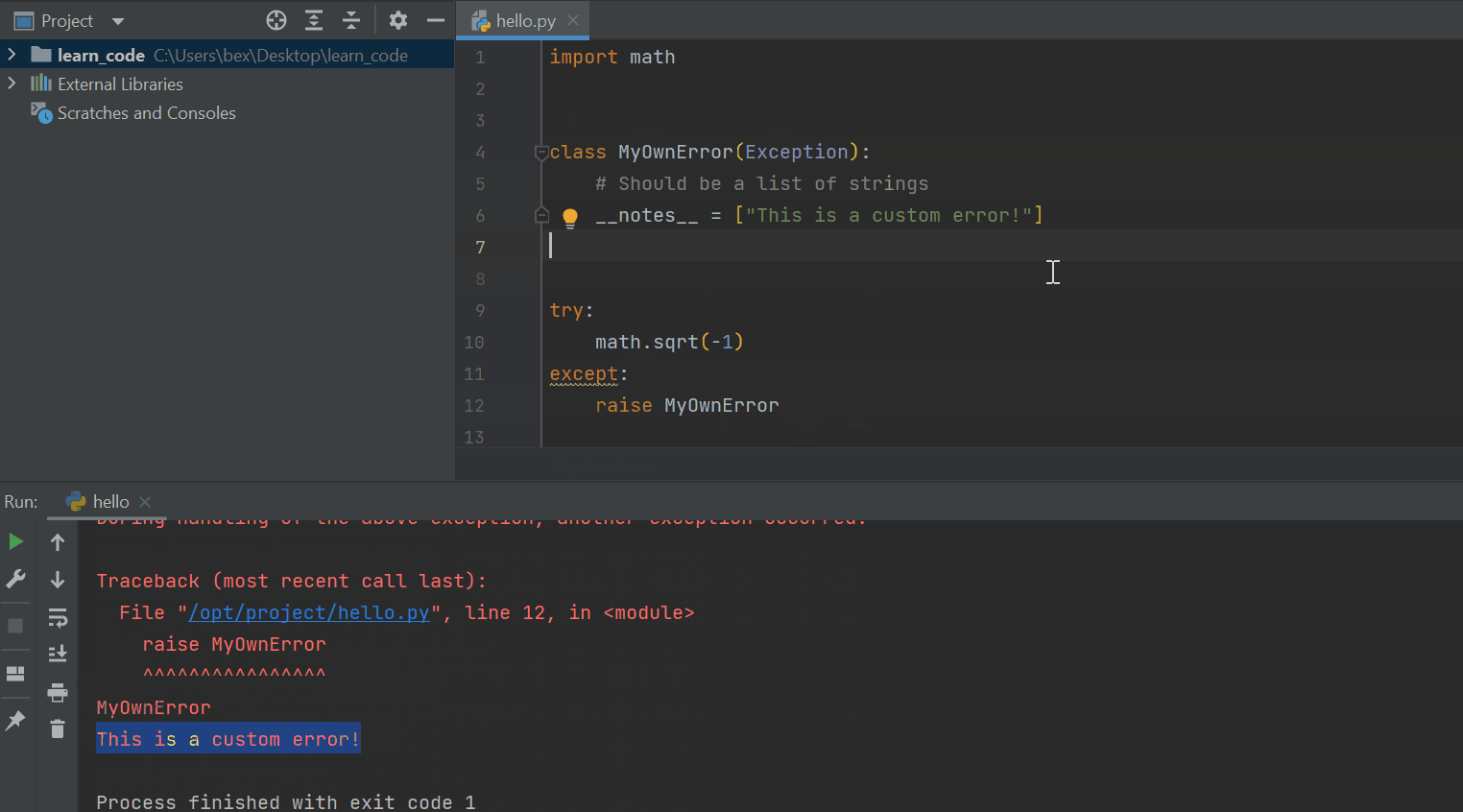
Now, when the interpreter hits the error, it will display the custom message after the regular message body.
There is also a new syntax to raise exceptions with the except* clause, which is used along with the new ExceptionGroup class. PEP 654 says that you can use it to raise multiple unrelated errors simultaneously in various scenarios. Most of these situations are too niche, like working with web sockets, programming concurrently with asyncio, etc., which rarely come up in everyday data science work, but if you’re interested, you can learn about the new syntax here.
Statically typed languages help make your code readable and easy to debug. Defining the exact type of variables, function inputs, and outputs may save you hours of debugging time and make reading your code easier for others. Adding typing annotations will also let modern IDEs display function definitions as you type their names, making your functions easier to interpret by others.
Until now, the powerful typing module in Python had classes for virtually any data type, except for classes that return instances of themselves. In current versions of Python, the below example isn’t possible:
from typing import Self
class Language:
def __init__(self, name, version, release_date):
self.name = name
self.version = version
self.release_date = release_date
def change_version(self, version) -> Self:
self.version = version
return Language(self.name, self.version, self.release_date)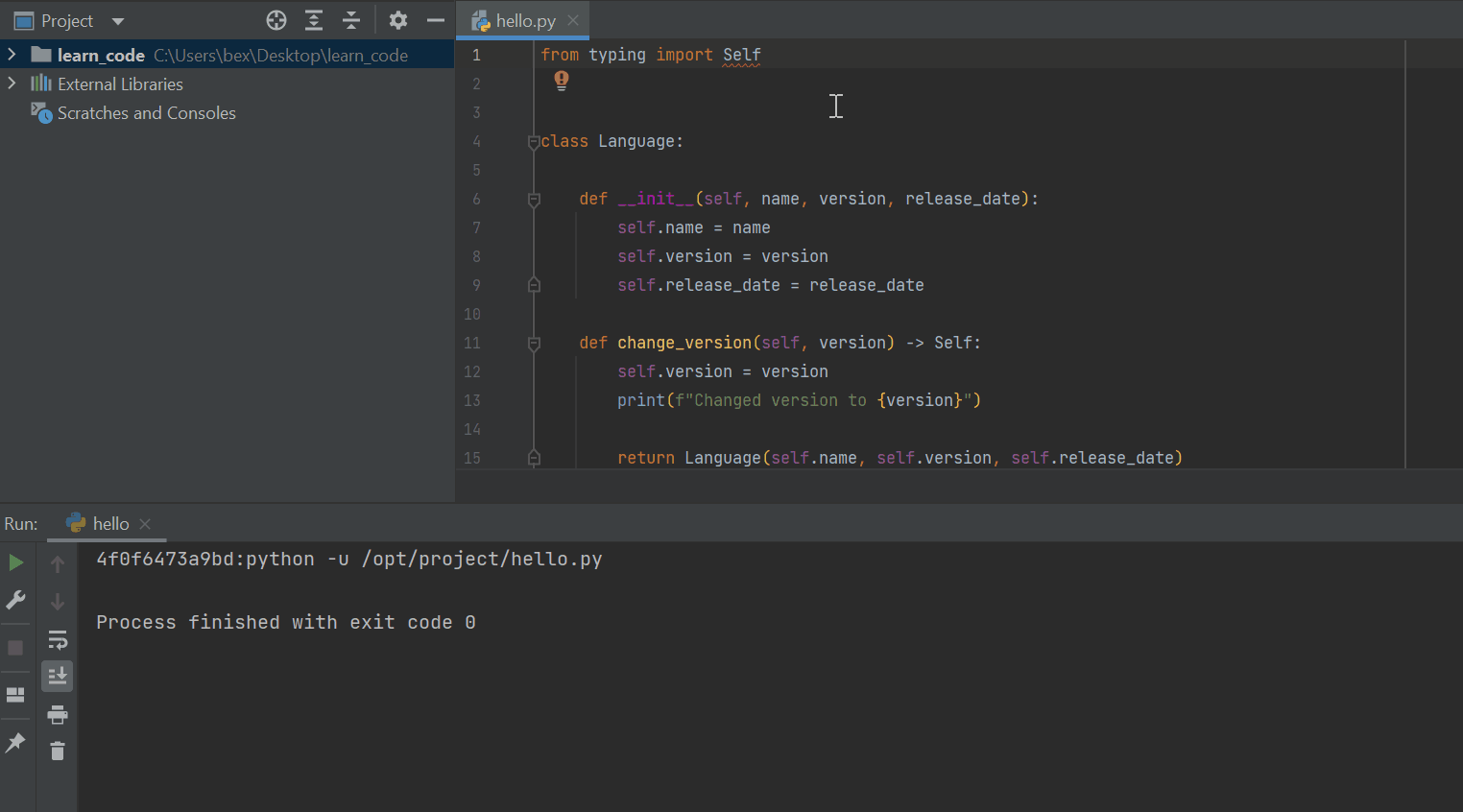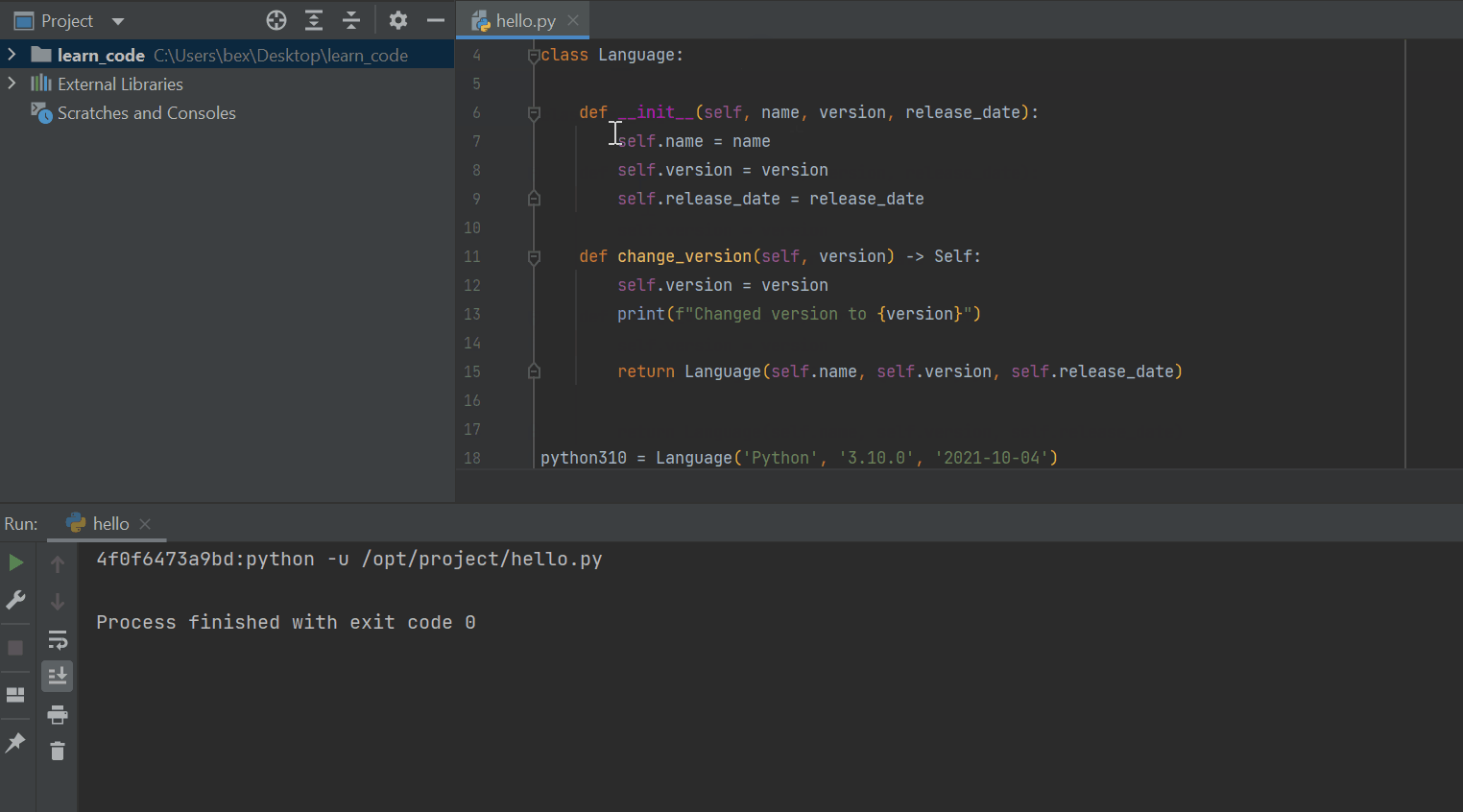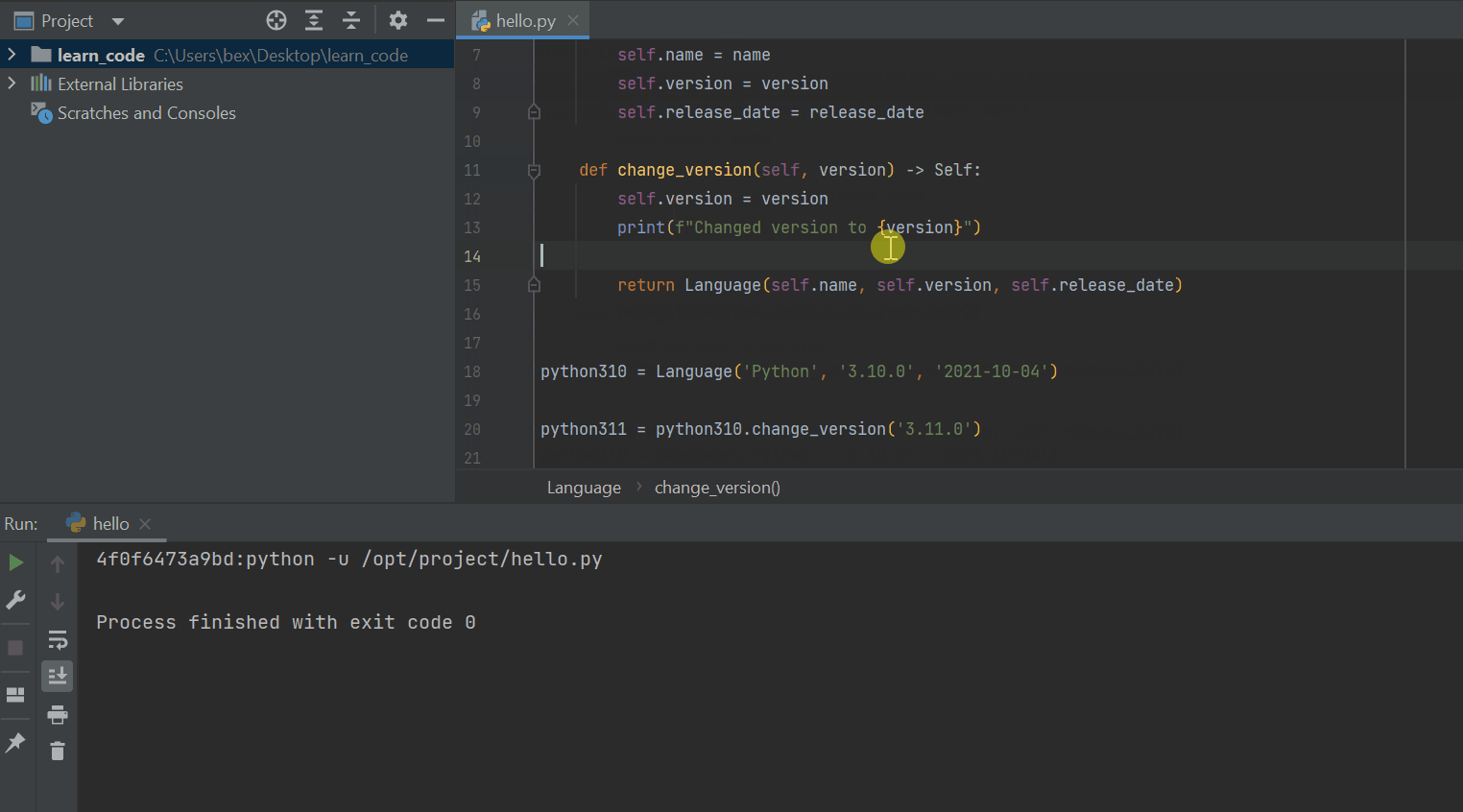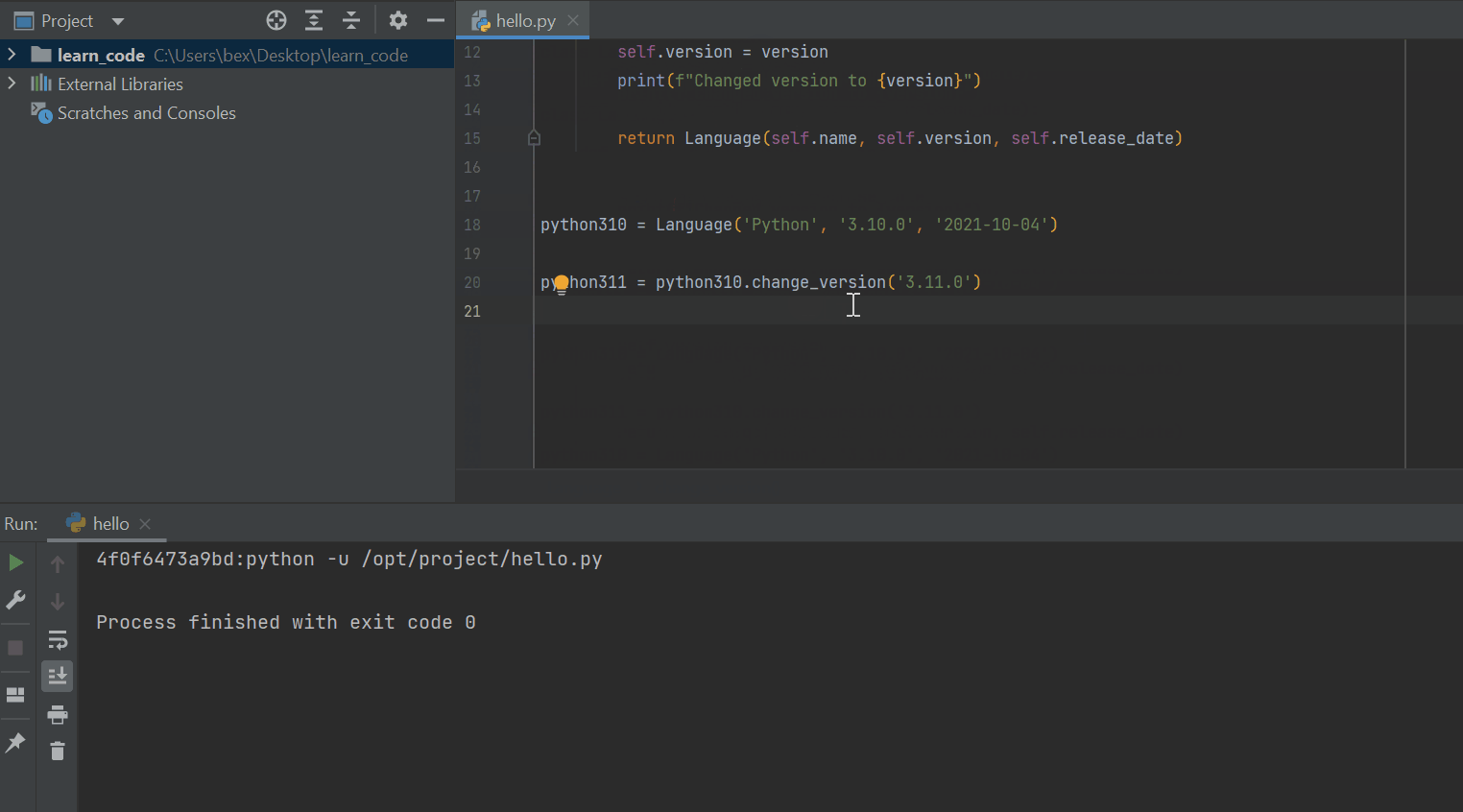
However, Python 3.11 introduces the Self class, which you can add to a function's definition if its return value is self or a new instance of the class itself.
There are a few other quality-of-life improvements to the standard libraries. First of all, two long-awaited functions are added to the math module.
>>> import math
>>> math.cbrt(9) # Find the cube-root of x
2.080083823051904
>>> math.cbrt(27)
3.0000000000000004
>>> math.exp2(5) # Raise 2 to the power of x
32.0The fact that it took Python 28 years to add the cube-root function is pretty surprising but, as the saying goes, better late than never.
The fractions module also added a new feature that lets you create fractions from strings:
>>> from fractions import Fraction
>>> Fraction("22/7") # New in Python 3.11
Fraction(22, 7)
>>> Fraction(numerator=22, denominator=7)
Fraction(22, 7)
>>> Fraction("3e-4")
Fraction(3, 10000)
>>> Fraction("-73/41")
Fraction(-73, 41)
>>> Fraction(3.1415) # Find the closest approximation to the given float
Fraction(7074029114692207, 2251799813685248)As you can see, the fractions module can be handy for certain arithmetic operations. Mainly, I like how you can find the closest fraction that approximates the given float. You can take this a step further by providing a denominator limit:
>>> from math import pi
>>> Fraction(pi).limit_denominator(100000)
Fraction(312689, 99532)There is also a new module named tomllib for parsing TOML documents. TOML (Tom's Obvious Minimal Language) is a popular file format for writing human-readable configuration files. Here is an image from the project's homepage:

import tomllib
toml_str = """
python-version = "3.11.0"
release_date = "2022-10-22"
"""
data = tomllib.loads(toml_str)
print(data) # {'python-version': '3.11.0', 'release_date': '2022-10-22'}
print(data['python-version']) # 3.11.0
print(data['release_date']) # 2022-10-22The development of Python 3.11 started on May 5, 2021. Since then, seven alpha versions have been released, coinciding with the first beta version on May 8, 2022. From this date until the official release there won't be new features introduced to Python.
The final, stable release will come out on October 3, 2022, after three more beta versions and two candidate versions in the meantime. You can learn more about Python by checking out the following resources.
Learn more about Python
Course
Course
Course
blog
Javier Canales Luna
6 min
blog
Javier Canales Luna
12 min
blog
Moez Ali
9 min
blog
DataCamp Team
8 min
blog
Thaylise Nakamoto
9 min
Tutorial
Matthew Przybyla



