Course
Streamlined Data Ingestion with pandas
4 hr
62.7K
Data analysis often heavily relies on the indispensable pandas library. It provides easy-to-use data structures and data manipulation functions that enable efficient handling of tabular datasets. With pandas, users can easily import, clean, transform, and aggregate data from various sources, including CSV files, Excel spreadsheets, SQL databases, and more.
If you would like to learn how to import and clean data, calculate statistics, and create visualizations with pandas, check out our Data Manipulation with pandas Course.
In this tutorial, we’ll explore the latest iteration of the pandas library, exploring the latest features with examples of how to use them.
Pandas 2.0 was released on April 3, 2023, marking three years of development. This latest version offers a range of new features, such as enhanced extension array support, DataFrames support for PyArrow, and non-nanosecond datetime resolution. However, it also includes enforced deprecations, resulting in API changes.
As a significant update to Pandas, version 2.0 implements all the deprecations in 1.X. The most recent release of 1.5.3 had approximately 150 warnings. If your code is warning-free in 1.X, it should be compatible with version 2.0.
Let’s take a look at what’s new with pandas 2.0, including how to use some of the improved features.
PyArrow can be considered the defining feature of this release.
Pandas was initially developed using NumPy data structures for memory management, but now users have the choice to utilize PyArrow as their backing memory format.
PyArrow is a Python library (built on top of Arrow) that provides an interface for handling large datasets using Arrow memory structures, as well as tools for serialization, compression, and integration with other data processing systems such as Apache Spark and Apache Parquet.
Arrow is an open-source and language-agnostic columnar data format to represent data in memory. It is written in C++, but it is language agonistic.
Inefficient memory usage caused by the original NumPy back-end is a common issue that drives users to explore alternative data processing tools, such as Spark, Dask, Ray, etc. By reducing memory consumption via PyArrow's back-end, Pandas can now offer users a more streamlined experience and enable them to work more efficiently.
Benchmarks comparing mean and replace operations using NumPy and PyArrow back-end, alongside Polars
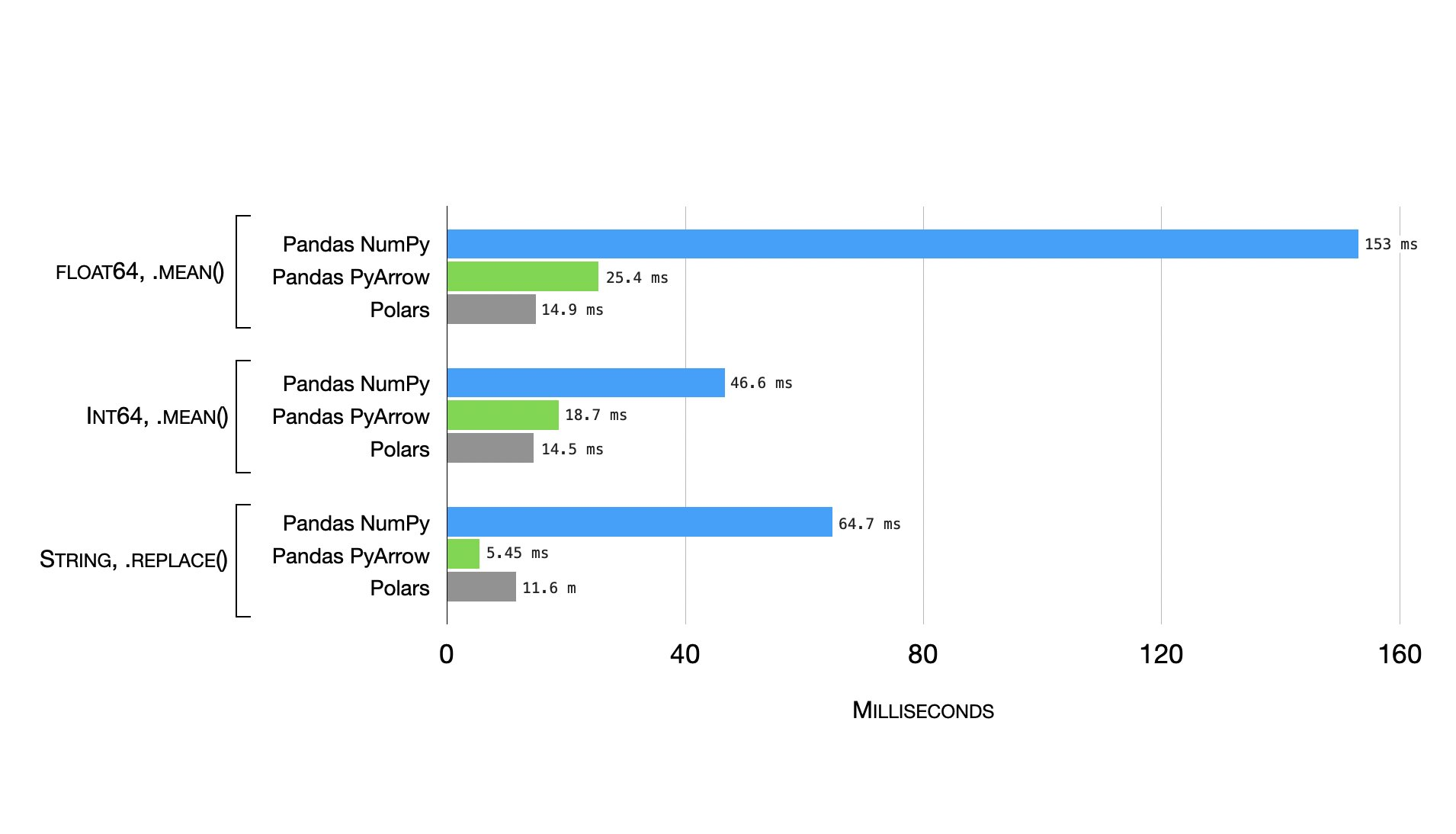
Polars is a Rust-based data manipulation library for Python that provides a DataFrame API similar to pandas, but with enhanced performance and scalability for large datasets. To learn more about Polars library, check out the official website.
Here's the code snippet to read a CSV file using PyArrow as the back-end:
pd.read_csv(my_file, dytpe_backend='pyarrow')
If you want to learn efficient techniques in pandas to optimize your Python code, check out the Writing Efficient Code with pandas course on DataCamp.
Dealing with missing values in pandas has been challenging in the past due to NumPy's lack of support for null values in certain data types. For instance, NumPy integer dtypes do not allow null values. When a null value was introduced in an integer column, the column would automatically be converted to a float dtype, which is not great.
Pandas 1.0 introduced nullable dtypes, but they required some effort to utilize. Fortunately, with the latest version, when reading data into a DataFrame, you can specify the use of nullable dtypes, making the process much more straightforward.
pd.read_csv(my_file, use_nullable_dtypes=True)
Copy-on-Write is a memory optimization technique utilized by Pandas to enhance performance and minimize memory usage while handling large datasets. It makes Pandas more similar to Spark and how lazy operations are performed in Spark. Lazy operations refer to operations that do not execute immediately but rather wait until an action is called to trigger the computation. These operations are called "lazy" because they delay execution until it is necessary to compute and return the final results.
The fundamental concept involves generating a reference to the original data when creating a copy of a pandas object, such as a DataFrame or Series, and only creating a new copy when any modifications are made.
This approach permits multiple copies of the same data to access the same memory until any changes are introduced, eliminating the need for redundant data copying and significantly reducing memory usage, thus enhancing performance.
In pandas 2.0, the Index feature has been expanded to include NumPy numeric dtypes, such as int8, int16, int32, uint8, uint16, uint32, uint64, float32, and float64, whereas previously only int64, uint64, and float64 types were supported.
This update enables the creation of indexes with lower-bit sizes, for instance, 32-bit indexes, in operations that previously produced 64-bit indexes.
All numeric indexes are now represented as Index with an associated dtype.
By specifying extras during the installation of pandas using pip, you can install additional sets of optional dependencies. For example:
pip install "pandas[performance, aws]>=2.0.0"
This will install performance and aws optional dependencies. The installation guide for pandas provides a list of available extras. This includes: [all, performance, computation, fss, aws, gcp, excel, parquet, feather, hdf5, spss, postgresql, mysql, sql-other, html, xml, plot, output_formatting, clipboard, compression, and test] Don’t forget to add quotes (“).
For a long time, pandas had a limitation where timestamps were only represented in nanosecond resolution. This limitation meant that it was not possible to represent dates before September 21, 1677, or after April 11, 2264. This limitation caused difficulties for researchers analyzing time series data that spanned over extended periods.
However, with the release of pandas 2.0, support for other resolutions such as second, millisecond, and microsecond has been added. This enhancement enables time ranges up to +/- 2.9e11 years, covering most use cases.
Previously, the to_datetime() function in pandas would infer the format of each element independently, which could be problematic when users expected a consistent format, but the function switched formats between elements.
Although this approach was suitable for instances with mixed date formats, it caused issues for many users.
In pandas 2.0, the parsing process has been modified to use a consistent format determined by the first non-NA value. Users can still specify a format, in which case that format will be used instead.
Old Behavior:
ser = pd.Series(['13-01-2000', '12-01-2000'])
pd.to_datetime(ser)
Out[2]:
0 2000-01-13
1 2000-12-01
dtype: datetime64[ns]
New Behavior:
ser = pd.Series(['13-01-2000', '12-01-2000'])
pd.to_datetime(ser)
Out[43]:
0 2000-01-13
1 2000-01-12
dtype: datetime64[ns]
Examples reproduced from the official documentation.
Backward incompatible API changes refer to modifications in a library’s API that could break existing code or integrations. These changes could include the removal or renaming of functions, classes, or parameters, or the alteration of their expected behavior. Check out the list of all breaking changes in pandas 2.0 in the documentation on backward incompatible API changes.
To update the pandas library, simply run this command in your terminal or notebook:
pip install -U pandas
Check out the full release notes for pandas 2.0
You can also use our pandas data science cheat sheet as a quick guide to the basics of the Python data analysis library, including code samples.

Cheatsheet from DataCamp. Source
A vast group of contributors and a smaller team of maintainers have collectively developed pandas, an open-source project driven by the community. The leadership of pandas is committed to establishing a positive, inclusive, and open community. If you want to participate in this community, check out the Contributor community guide by pandas.
Pandas 2.0 marks a significant update to the popular data analysis library, bringing new features such as improved performance through PyArrow, nullable data types, copy-on-write optimization, expanded support for NumPy numeric types in indexes, and non-nanosecond datetime resolution.
With this update, pandas is now capable of handling larger datasets with more efficient memory usage, providing a more streamlined experience for users.
To take advantage of these new features, users can simply update their pandas library with the pip install -U pandas command. The pandas community continues to provide support and resources, including courses on DataCamp, to help users improve their data analysis skills.
Here are a few excellent tutorials that you might find useful in your quest to learn data analysis.
Top pandas Courses
Course
Course
Course
blog
Abid Ali Awan
6 min
cheat-sheet
Karlijn Willems
cheat-sheet
Karlijn Willems
Tutorial
Javier Canales Luna
Tutorial
Karlijn Willems




