
Track
Developing Large Language Models
16 hr
Imagine telling a friend a long story, only to realize they have forgotten the beginning by the time you reach the punchline. This frustration is exactly what happens when an AI runs out of "short-term memory," forcing it to drop crucial details to make room for new ones.
In the world of Large Language Models (LLMs), this attention span is defined by the context window.
As models become stronger and context sizes increase, understanding how these windows work becomes key to building reliable and scalable AI systems. In this guide, we’ll walk through the basics of context windows, the trade-offs of expanding them, and the strategies to effectively use them.
To move beyond theory and learn how to manage context limits in real Python applications, check out our Developing LLM Applications with LangChain course.
The context window of an AI model determines the amount of text it can hold in its working memory while generating a response. It limits how long a conversation can be carried out without forgetting details from earlier interactions.
You can think of it as a human’s short-term memory. It stores information from previous conversations temporarily to use for the task at hand.

Context windows affect various aspects, including the quality of reasoning, the depth of conversation, and the model's ability to personalize responses effectively. It also determines the maximum size of input it can process at once. When a prompt or conversation context exceeds that limit, the model truncates (cuts off) the earliest parts of the text to make room.
To get a clearer picture of what this exactly means, let's look at a few basic concepts underlying AI models and context windows.
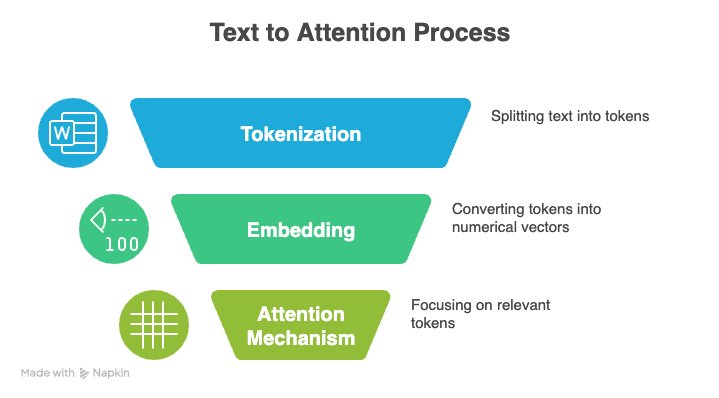
Three core concepts underlie LLMs: tokenization, the attention mechanism, and positional encoding.
Tokenization is the process of converting raw text into a sequence of smaller units, or tokens, that an LLM can process. These tokens can represent entire words, individual characters, or even partial syllables. Collectively, the entire set of unique tokens a model recognizes is referred to as its vocabulary.
For example, the sentence “Hello, world” might be tokenized into [“Hello”, “,”, “ world”].
During training or inference, each token is turned into a unique integer, and the model reads these numbers instead of the original text. It analyzes the numerical sequence, learns how tokens relate to one another, and generates new text by predicting the next probable token.
Efficient tokenization plays a big role in the amount of information that fits into a model’s context window. When a tokenizer can represent text with fewer tokens, more content fits into the same window.
Tokenizers that represent common words or phrases as single tokens are especially effective because they reduce the token count, allowing the model to handle longer documents within its context limits.
The so-called attention mechanism is another foundation of modern LLMs. It helps a model focus on the most relevant parts of its input when generating an output.
Instead of treating every token equally, the model compares the current representation against all other token representations and assigns a score to each comparison. This selective weighting lets the model process long sequences and understand context more effectively.
Attention is built around three components: Queries, Keys, and Values.
Queries: The signal sent by the current token to "search" for relevant information in the rest of the sequence.
Keys: The identifier for each token in the sequence that determines how well it matches the search signal.
Values: The actual informational content that is retrieved and used when a match between a Query and a Key is found.
The model computes similarity scores between queries and keys, converts those scores into weights using the softmax activation function, and then produces the final output as a weighted sum of the values.
Self-attention compares the current token to every other token in the sequence. This creates a quadratic computational cost: doubling the context window quadruples the processing power and memory required.
As context windows expand, this quickly becomes expensive, so models rely on optimizations like sparse attention, low-rank approximation, or chunking to keep computation manageable.
Transformers, which power modern language models, don’t naturally understand the order of tokens. Instead, they rely on positional encoding to incorporate this information.
Positional encoding adds a small signal to each token that helps the model understand distance and relative arrangement.
The specific method of positional information also defines how far the model can reliably track relationships within a sequence, which determines the size and effectiveness of its context window. Let’s compare some popular methods:
Absolute Positional Embeddings: The model learns a separate vector for each position in the sequence, like giving every token a fixed address. This works for shorter sequences, but the model can’t handle positions beyond what it was trained on, which makes the context window hard to extend.
Sinusoidal Encodings: Positions are encoded using repeating sine and cosine waves, which give each token a unique pattern based on its location. They generalize better to unseen lengths than absolute embeddings, though they become less stable with extremely long sequences.
Relative Positional Encodings: Instead of marking exact positions, the model learns the distance between tokens. This helps it generalize to longer sequences, but the overall context limit still depends on the model’s architecture and memory.
Rotary Positional Embeddings (RoPE): RoPE encodes position by rotating each token’s vector representation based on its absolute position, calculating the distance from other tokens. This method stays stable as sequences grow and supports much larger context windows.
ALiBi (Attention Linear Biases): ALiBi applies a simple distance-based bias inside the attention mechanism, so closer tokens naturally receive higher weight. It scales well to long sequences.
I recommend checking out this tutorial on how transformers work for a detailed overview.
If the context exceeds the context window, the model may truncate or ignore the earliest parts, potentially losing important context. This is why researchers continuously experiment with new techniques to push these limits and enable longer context windows.
Until 2022, OpenAI’s GPT models dominated the landscape. The first GPT model, released in 2018, supported a 512-token window. The next two versions in 2019 and 2020 each doubled that limit, reaching 2,048 tokens for GPT-3. Successive models kept extending these boundaries to up to one million tokens (GPT-4.1).
Recently, OpenAI was caught up or even outraced by the competition. Google’s Gemini 2.5 and 3 Pro versions match this window size of up to a million tokens, making it possible to process entire books, large codebases, and multi-document workloads in a single pass.
Anthropic’s Claude Sonnet 4.5 series is currently testing the same context window size in beta, expanding from its original size of 200,000 tokens.
Open-source model families like Llama and Mistral generally land in the 100k to 200k range, offering respectable long-context performance while remaining practical to deploy locally or fine-tune.
Notable exceptions include Llama Maverick, which supports a 1 million token window designed for general-purpose reasoning across long documents. Meanwhile, Llama Scout pushes the boundary even further with a massive 10 million token capacity, specifically engineered for processing entire codebases or legal archives in a single pass.
However, the release of GPT-5.2 just this week signaled a shift in strategy. Rather than chasing infinite context, OpenAI restricted its newest flagship to a 400,000-token window, trading raw size for 'perfect recall' and superior reasoning capabilities that avoid the distraction issues common in larger models.
The differences in context window size shape how each model performs in real workflows. Extended context windows power models with strong accuracy, coherence, and long-range reasoning, but they also require more computation and more careful context selection.
Mid-range models stay efficient and still manage long documents and extended chats, though they need the right structure for very large inputs.
The following use cases highlight how the strengths of models with large context windows show up in real-world applications.
With enough room to hold entire reports, transcripts, codebases, or research papers at once, a model can track patterns, connect distant details, and maintain a coherent understanding from start to finish. This offers many fields of application:
Law: Large windows allow models to analyze full contracts, compare clauses across multiple documents, and track references hidden in long documents.
Healthcare: Teams can review lengthy clinical guidelines, patient histories, or multi-study datasets while preserving important context that smaller windows would miss.
Research: A large-window model can read full papers and literature reviews in one pass and surface connections that only appear when the entire document is visible.
Larger context windows make conversational AI feel more natural because the model can remember more of the conversation without forgetting earlier messages.
In customer service, this leads to smoother and more personalized interactions. The model can use past preferences and earlier conversations to give more accurate and relevant responses.
Extended context windows support complex reasoning across text, audio, and visuals by giving the model enough space to hold all modalities together instead of processing them in isolation.
When the full transcript, visual frames, and related written material fit inside a single window, the model can compare details across formats, track relationships, and build a unified understanding of the context.
This eliminates the gaps that appear when information must be chunked or summarized and allows the model to reason over the entire set of inputs at once.
Large context windows unlock powerful model capabilities, but they also introduce new performance challenges as input sizes grow. Even advanced models struggle to maintain perfect attention across extremely long sequences, so they don’t always use information from every part of the context as reliably as you’d expect.
One common issue in long-context models is the “lost in the middle” effect. Models remember the beginning and end of a long sequence pretty well, but they often miss or ignore important details buried in the middle. This can lead to weaker answers, even when the full context is available.
Structuring the input in a smart way helps to avoid this issue for important tasks. This means breaking it into clear sections or repeating key points so the model doesn’t overlook them.
Costs can increase rapidly with an increased context window size. Every additional token increases the size of the attention computation, which raises inference time, GPU memory requirements, and overall system load.
To manage this, more effective ways to feed the model information are needed. Techniques such as selective retrieval, hierarchical chunking, or quick summaries help keep the input smaller, so the model isn’t overloaded.
Large windows also introduce concerns regarding safety, security, and privacy. When you give the model more input, there’s a higher chance of exposing sensitive data.
That’s why teams need solid data-handling rules, redaction steps, and access controls to make sure large context windows don’t create new risks.
In many cases, unnecessary or loosely related information increases cognitive load for the model, raising the risk of hallucinations and incorrect patterns. Lengthy inputs also introduce noise that can distort the model’s understanding of the task.
In practice, high-quality performance often stems from carefully curated context, ensuring the model sees the right information instead of just being exposed to the biggest amount of information.
Several methods can be employed to make optimal use of context windows. Among these are Retrieval Augmented Generation (RAG), context engineering, chunking, and model selection.
Retrieval Augmented Generation (RAG) works by pulling additional information from an external database and feeding it to the model whenever context is needed.
Instead of stuffing entire documents into the context window, RAG stores everything separately and only retrieves the pieces that matter for the current question. This keeps the context small while still giving the model all the information it needs.
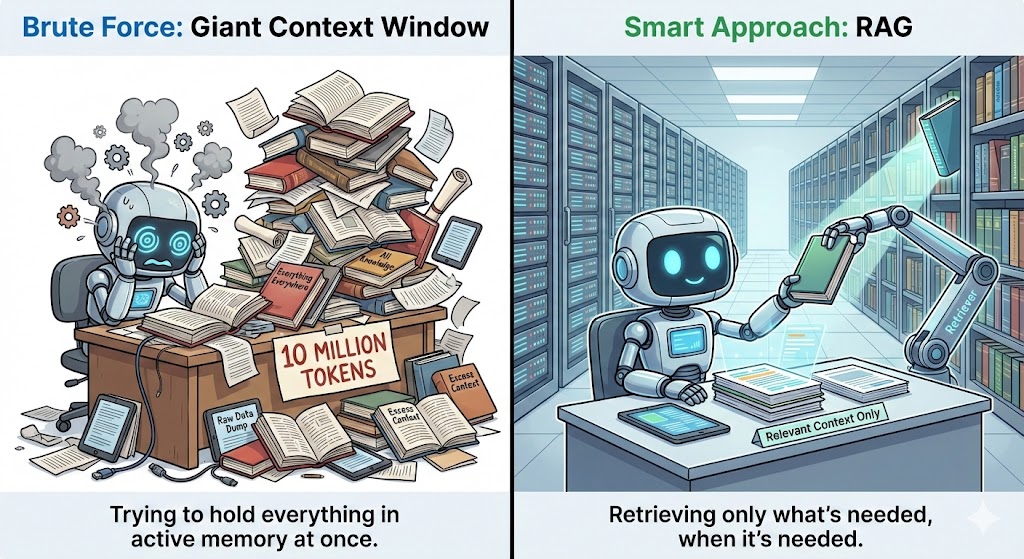
It does this by using embeddings or vector search to find the most relevant chunks and sending those chunks to the model in a clean, structured way. This increases accuracy by ensuring that the model can use relevant extra information beyond its training data.
Context engineering focuses on giving models relevant information instead of overwhelming them with unnecessary detail. Effective strategies include segmenting long documents, summarizing low-value sections, and using lightweight preprocessing steps to highlight main points.
Semantic search helps here by identifying the text that matters for the current query. You can also improve results by moving the most critical information to the beginning or end of the context, since models tend to remember those spots better.
Chunking breaks long documents into smaller, coherent sections. The idea is to group content based on its subject matter, structure, or the task it supports.
This keeps each chunk coherent and helps the model stay focused instead of getting lost in a huge block of text. If you want to know more, feel free to check out this article on advanced chunking strategies.
Semantic chunking groups sentences that share a similar meaning instead of cutting the text at random character limits. It splits the content at natural breakpoints like topic shifts, paragraph transitions, or section headers.
Task-based chunking goes even further by shaping each chunk around the specific question you’re trying to answer. Each section then contains only the information that is actually relevant to that task.
Tasks that involve full-document analysis, multi-file reasoning, or long-running conversations benefit from models with windows in the 200k–1M range. For more focused tasks like summarization, code review, or short-form question answering, models in the 100k–200k range often provide the best balance of speed, cost, and accuracy.
Smaller windows can still perform well when paired with strong retrieval systems. A good RAG system or Model Context Protocol (MCP) can pull the right information on demand, so the model doesn’t need to hold everything in its memory.
Before we wrap up, let’s take a look at where the technology is heading regarding context windows.
Future model architectures are moving toward dynamic context windows, rather than fixed-size windows.
Researchers are exploring approaches that blend transformer strengths with new long-range memory systems, resulting in models that can store and recall information without relying on attention mechanisms only.
These architectures overcome today’s limits by shifting from static context windows to dynamic memory layers that grow with the task.
Memory systems are another area of innovation. Future models are expected to rely more on context-aware memory systems that extend beyond a single session and provide continuity over time.
Instead of treating each conversation as a fresh start, these systems store key preferences, past decisions, and recurring themes in a structured memory layer that can be recalled when relevant.
This moves personalization from reactive to proactive, allowing the model to understand users more holistically and support long-running goals with far greater consistency.
External retrieval is evolving as well. Currently, RAG works like a search engine, pulling relevant text into the prompt. Advanced versions such as Corrective Retrieval-Augmented Generation (CRAG) have already surfaced, but that is just the beginning.
In the future, retrieval will feel more built-in, almost like the model has its own external memory. They will automatically gather, compress, and resurface information with minimal user intervention.
Persistent memory will also change how we interact with AI. Instead of forgetting everything when a session ends, the model will remember important details across days, weeks, or even months. As it learns your style, habits, and priorities, it can provide you with more tailored and helpful responses, all without requiring you to repeat yourself.
Tools like Mem0 are already pioneering this approach, acting as a dedicated memory layer between applications and LLMs. However, looking ahead, we expect to see more of these capabilities built directly into model architectures rather than relying on external layers.
Larger windows unlock powerful new workflows, yet they also introduce attention challenges, higher computational costs, and quality risks when context is overloaded. This makes strategic context management essential.
Techniques like retrieval augmentation, semantic chunking, and context engineering help models stay focused, efficient, and reliable even as their capacities expand.
Looking ahead, the best LLM-powered systems combine smart tools and a solid understanding of how context affects reasoning. By applying these principles, teams can capture the benefits of long-context models while preparing for the next generation of architectures that push context boundaries even further.
Take your Python basics to the next level with the Developing Large Language Models skill track. It is designed to guide you from foundational code to building and fine-tuning your own powerful AI applications.
LLM Courses
Track
Course
Course
blog
Benito Martin
15 min
blog
Amberle McKee
8 min
blog
Arun Nanda
14 min
Tutorial
Ryan Ong
Tutorial
Aashi Dutt
code-along
Richie Cotton
