Statistics in R
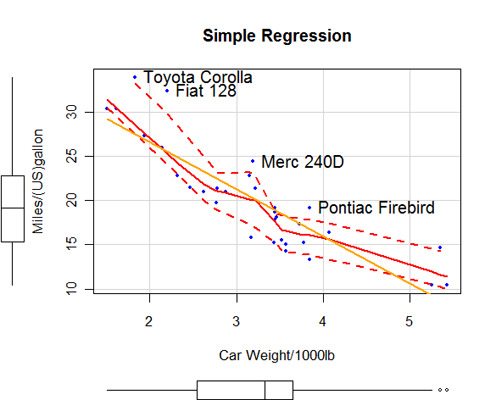
This section describes basic (and not so basic) statistics. It includes code for obtaining descriptive statistics, frequency counts and crosstabulations (including tests of independence), correlations(pearson, spearman, kendall, polychoric), t-tests (with equal and unequal variances), nonparametric tests of group differences (Mann Whitney U, Wilcoxon Signed Rank, Kruskall Wallis Test, Friedman Test), multiple linear regression (including diagnostics, cross-validation and variable selection), analysis of variance (including ANCOVA and MANOVA), and statistics based on resampling.
Since modern data analyses almost always involve graphical assessments of relationships and assumptions, links to appropriate graphical methods are provided throughout.
It is always important to check model assumptions before making statistical inferences. Although it is somewhat artificial to separate regression modeling and an ANOVA framework in this regard, many people learn these topics separately, so I've followed the same convention here.
Regression diagnostics cover outliers, influential observations, non-normality, non-constant error variance, multicolinearity, nonlinearity, and non-independence of errors. Classical test assumptions for ANOVA/ANCOVA/MANCOVA include the assessment of normality and homogeneity of variances in the univariate case, and multivariate normality and homogeneity of covariance matrices in the multivariate case. The identification of multivariate outliers is also considered.
Power analysis provides methods of statistical power analysis and sample size estimation for a variety of designs.
Finally, two functions that aid in efficient processing (with and by) are described.
Advanced Statistics
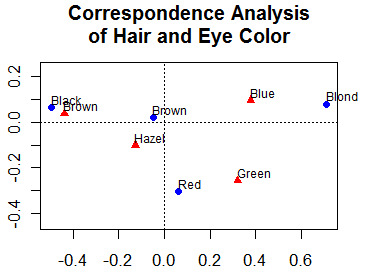
This section describes more advanced statistical methods. This includes the discovery and exploration of complex multivariate relationships among variables. Links to appropriate graphical methods are also provided throughout.
It is difficult to order these topics in a straight-forward way. I have chosen the following (admittedly arbitrary) headings.
Predictive models
Under predictive models, we have generalized linear models (include logistic regression, poisson regression, and survival analysis), discriminant function analysis (both linear and quadratic), and time series modeling.
Latent Variable Models
This includes factor analysis (principal components, exploratory and confirmatory factor analysis), correspondence analysis, and multidimensional scaling(metric and nonmetric).
Partitioning Methods
Cluster Analysis includes partitioning (k-means), hierarchical agglomerative, and model based approaches. Tree-Based methods (which could easily have gone under predictive models!) include classification and regression trees, random forests, and other partitioning methodologies.
Other Tools
This section includes tools that are broadly useful including bootstrapping in R and matrix algebra programming (think MATRIX in SPSS or PROC IML in SAS).
Going Further
To practice statistics in R interactively, try this course on the introduction to statistics.
Try the Supervised Learning in R course which includes an exercise with Random Forests.