Statistik in R
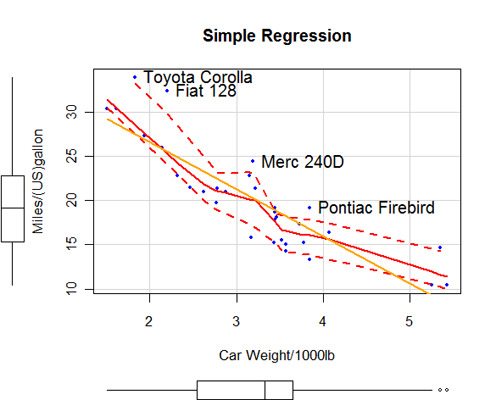
In diesem Abschnitt werden grundlegende (und nicht so grundlegende) Statistiken beschrieben. Sie enthält Code zur Erstellung von deskriptiven Statistiken, Häufigkeitsauszählungen und Kreuztabellen (einschließlich Unabhängigkeitstests), Korrelationen(Pearson, Spearman, Kendall, Polychoric), t-Tests (mit gleichen und ungleichen Varianzen), nichtparametrischen Tests für Gruppenunterschiede (Mann Whitney U, Mann Whitney U, Wilcoxon Signed Rank, Kruskall Wallis Test, Friedman Test), multiple lineare Regression (einschließlich Diagnose, Kreuzvalidierung und Variablenauswahl), Varianzanalyse (einschließlich ANCOVA und MANOVA) und Statistik auf der Grundlage von Stichproben.
Da moderne Datenanalysen fast immer grafische Auswertungen von Zusammenhängen und Annahmen beinhalten, finden sich überall Links zu geeigneten grafischen Methoden.
Es ist immer wichtig, die Modellannahmen zu überprüfen, bevor statistische Schlüsse gezogen werden. Obwohl es etwas künstlich ist, die Regressionsmodellierung und die ANOVA zu trennen, lernen viele Menschen diese Themen getrennt voneinander, deshalb habe ich mich hier an diese Konvention gehalten.
Die Regressionsdiagnose umfasst Ausreißer, einflussreiche Beobachtungen, Nicht-Normalität, nicht konstante Fehlervarianz, Multikolinearität, Nichtlinearität und Nicht-Unabhängigkeit der Fehler. Zu den klassischen Testannahmen für die ANOVA/ANCOVA/MANCOVA gehören die Bewertung der Normalität und Homogenität der Varianzen im univariaten Fall sowie die multivariate Normalität und Homogenität der Kovarianzmatrizen im multivariaten Fall. Auch die Identifizierung von multivariaten Ausreißern wird berücksichtigt.
Die Power-Analyse bietet Methoden zur statistischen Power-Analyse und zur Schätzung des Stichprobenumfangs für eine Vielzahl von Designs.
Zum Schluss werden zwei Funktionen beschrieben, die bei der effizienten Verarbeitung helfen(mit und durch).
Erweiterte Statistik
Dieser Abschnitt beschreibt fortgeschrittenere statistische Methoden. Dazu gehört die Entdeckung und Erforschung komplexer multivariater Beziehungen zwischen Variablen. Außerdem gibt es überall Links zu geeigneten grafischen Methoden.
Es ist schwierig, diese Themen in eine übersichtliche Reihenfolge zu bringen. Ich habe die folgenden (zugegebenermaßen willkürlichen) Überschriften gewählt.
Vorhersagemodelle
Bei den Vorhersagemodellen haben wir verallgemeinerte lineare Modelle (einschließlich logistischer Regression, Poisson-Regression und Überlebensanalyse), Diskriminanzfunktionsanalyse (sowohl linear als auch quadratisch) und Zeitreihenmodellierung.
Modelle für latente Variablen
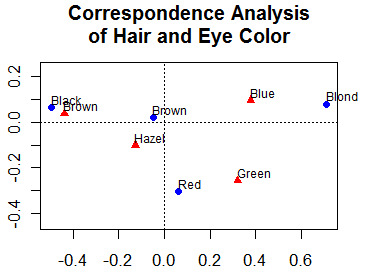
Dazu gehören die Faktorenanalyse (Hauptkomponenten, explorative und konfirmatorische Faktorenanalyse), die Korrespondenzanalyse und die multidimensionale Skalierung(metrisch und nicht metrisch).
Partitionierungsmethoden
Die Clusteranalyse umfasst partitionierende (k-means), hierarchisch agglomerative und modellbasierte Ansätze. Zu den baumbasierten Methoden (die auch unter Vorhersagemodelle fallen könnten!) gehören Klassifikations- und Regressionsbäume, Zufallswälder und andere Partitionierungsmethoden.
Andere Werkzeuge
In diesem Abschnitt findest du nützliche Tools wie Bootstrapping in R und Matrixalgebra-Programmierung (z. B. MATRIX in SPSS oder PROC IML in SAS).
Weiter gehen
Um Statistik in R interaktiv zu üben, probiere diesen Kurs zur Einführung in die Statistik aus.
Probiere den Kurs Supervised Learning in R aus, der eine Übung mit Random Forests enthält.