
Curso
Comprender la ingeniería de datos
2 h
355.8K
Como alguien que ha apoyado a equipos de datos conplataformas MLOpsy ha ayudado a diseñar infraestructuras escalables, he visto de primera mano lo cruciales que son los lagos de datos en la pila de datos actual.
A diferencia de los almacenes de datos tradicionales, que exigen que los datos estén limpios y estructurados antes de almacenarlos, los lagos de datos te permiten almacenarlo todo en formatos brutos, desordenados y sin estructurar. Esta flexibilidad abre un mundo de posibilidades para aplicaciones y casos de uso basados en datos. Un lago de datos te permite reunir y almacenar datos de diversas fuentes en un solo lugar, donde pueden analizarse y utilizarse para la IA.
En este artículo, te explicaré qué es un lago de datos, cómo funciona, cuándo utilizarlo y cómo se compara con las soluciones más tradicionales.
Antes de hablar de la arquitectura técnica o los casos de uso, es esencial entender qué es un lago de datos y qué lo distingue de los sistemas de almacenamiento más tradicionales.
Esta sección define el concepto, desglosa sus características clave y lo compara con el mundo más estructurado de los almacenes de datos.
Te recomiendo el curso Estrategia de Datos si quieres saber más sobre cómo puede ayudar a las empresas una estrategia de datos bien diseñada.
Un lago de datos es un repositorio centralizado que almacena todos tus datos estructurados, semiestructurados y no estructurados a cualquier escala.
Puedes ingerir datos brutos de diversas fuentes y conservarlos en su formato original hasta que necesites procesarlos o analizarlos.
A diferencia de las bases de datos o los almacenes de datos, que suelen requerir un esquema predefinido (esquema en escritura), los lagos de datos utilizan un enfoque de esquema en lectura. Esto significa que la estructura se aplica sólo cuando se accede a los datos para su análisis, dando a los equipos flexibilidad para interpretar y transformar los datos posteriormente.
Un lago de datos tiene las siguientes características básicas:
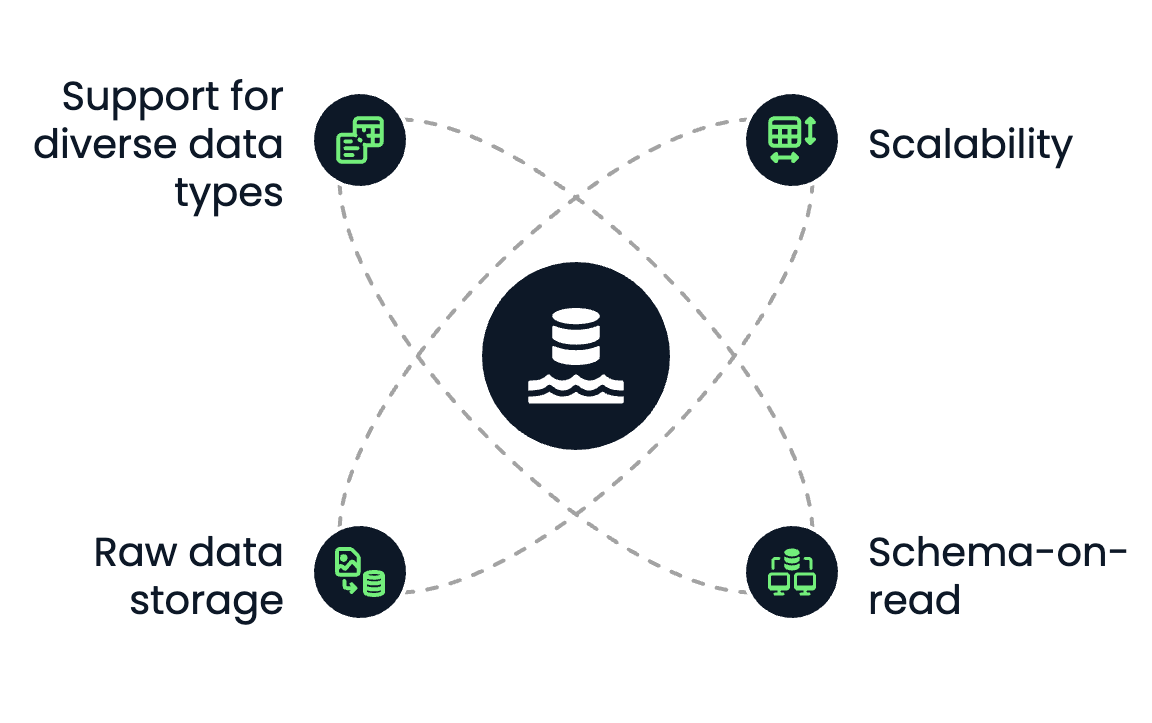
Características fundamentales de los lagos de datos. Imagen del autor.
Los lagos de datos y los almacenes de datos se utilizan para almacenar y analizar datos. Sin embargo, difieren significativamente en estructura, rendimiento y casos de uso.
Si eres nuevo en los almacenes de datos y quieres aprender más, te recomiendo el curso Conceptos de Almacén de Datos y los artículos Qué es un almacén de datos y Arquitectura de almacenes de datos: Tendencias, herramientas y técnicas.
Veamos en quése diferencian:
|
Función |
Lago de datos |
Almacén de datos |
|
Tipo de datos |
Estructurado, semiestructurado, no estructurado |
Sólo estructurado |
|
Formato de almacenamiento |
En bruto (objetos de archivo) |
Procesado (tablas, filas, columnas) |
|
Esquema |
Esquema en lectura |
Esquema en escritura |
|
Coste |
Almacenamiento de bajo coste |
Más caro por GB |
|
Caso práctico |
Aprendizaje automático, big data y almacenamiento de datos en bruto |
Inteligencia empresarial, análisis estructurado |
|
Rendimiento |
Flexible, depende del motor de cálculo |
Optimizado para consultas SQL rápidas |
En la práctica, muchas estrategias de datos modernas combinan ambas cosas: utilizan lagos de datos como base para el almacenamiento de datos brutos y almacenes de datos para la elaboración de informes estructurados y la inteligencia empresarial.
También existe una solución híbrida llamada "casa lago de datos". El artículo ¿Qué es un Data Lakehouse? Arquitectura, Tecnología y Casos de Uso lo explica con más detalle.
Una arquitectura de lago de datos bien diseñada es esencial para que los datos brutos sean utilizables y accesibles para el análisis posterior, el aprendizaje automático y la elaboración de informes.
Esta sección desglosa las cinco capas clave de un lago de datos moderno, desde la ingestión hasta la gobernanza.
La capa de ingestión introduce datos de diversas fuentes en el lago de datos. Estas fuentes incluyen sistemas internos (como bases de datos o CRM), API externas o dispositivos y registros IoT.
Hay tres modos principales de ingestión:
Las herramientas de ingesta estándar incluyen:
Una capa de ingesta flexible garantiza que los datos lleguen rápidamente y que puedan manejar diversos formatos y velocidades.
Cuando se ingieren los datos, se almacenan en la zona bruta del lago de datos. La capa de almacenamiento suele basarse en el almacenamiento de objetos en la nube, que ofrece escalado elástico, redundancia y rentabilidad.
Las opciones más populares son:
Sin embargo, también hay opciones para las empresas que quieren almacenar sus datos en sus nubes locales alojadas en sus centros de datos.
Uno podría, por ejemplo, instalar MinIO en su infraestructura. El propio MinIO es de código abierto y ofrece una API compatible con Amazon S3.
Las características clave de una capa de almacenamiento incluyen:
Almacenar los datos en su formato original te permite conservar todo su potencial para procesarlos y analizarlos en el futuro.
Sin metadatos, un lago de datos se convierte en un pantano de datos, ya que es imposible volver a encontrar tus datos y trabajar con ellos de forma eficiente.
El catálogo y la capa demetadatos aportan estructura al caos llevando un registro:
Esta capa garantiza la descubribilidad y usabilidad indexando todos los conjuntos de datos disponibles y permitiendo la búsqueda y el control de acceso. Las herramientas estándar para esta capa son
Un sistema de metadatos sólido es esencial para la colaboración, la gobernanza y la eficacia operativa.
Esta es la capa en la que se procesan los datos brutos y se convierten en información. La capa de procesamiento admite diversas operaciones, desde transformaciones fundamentales hasta análisis avanzados y aprendizaje automático.
Los flujos de trabajo típicosincluyen:
Esta capa suele incluir computación por lotes y en tiempo real, permitiendo el análisis exploratorio de datos y las cargas de trabajo de producción.
Una arquitectura robusta de lago de datos debe tener mecanismos incorporados para proteger los datos sensibles y garantizar el cumplimiento. Esta parte es crucial, ya que los lagos de datos contienen en su mayoría muchos datos sensibles que, si se ponen en peligro, podrían perjudicar a la empresa a la que pertenecen.
Las características esenciales de esa capa incluyen
Herramientas y servicios populares:
La seguridad determina a menudo si un lago de datos puede utilizarse en sectores regulados como el financiero, el sanitario o el militar.
Los lagos de datos son adecuados para casos de uso en los que la escala, la flexibilidad y la diversidad de tipos de datos son esenciales. Sirven de base para las operaciones y aplicaciones modernas basadas en datos en todos los sectores.
En esta sección, exploraremos algunos de los casos de uso más comunes e impactantes en los que los lagos de datos desempeñan un papel central.
Uno de los usos más conocidos de los lagos de datos es permitir el análisis de datos a gran escala.
Como los lagos de datos pueden almacenar datos en su forma bruta, las organizaciones ya no tienen que preocuparse de limpiar o estructurar cada conjunto de datos antes de analizarlos. Es ideal para recopilar registros, datos de sensores o secuencias de clics, que son demasiado grandes o cambian demasiado rápido para los sistemas tradicionales.
Los lagos de datos permiten
Herramientascomo Amazon Athena o Google BigQuery pueden consultar los datos directamente en el lago, sin necesidad de transformaciones complejas ni de trasladar los datos a otro lugar.
Los lagos de datos se adaptan perfectamente a los flujos de trabajo del aprendizaje automático y la IA.
Proporcionan el entorno ideal para:
En lugar de limitar los modelos a los datos prelimpiados de un almacén, los científicos de datos pueden acceder a datos ricos y sin procesar para experimentar con mayor libertad e iterar más rápidamente. Esto es especialmente útil en ámbitos como el procesamiento del lenguaje natural (PLN), la visión por ordenador y la previsión de series temporales.
Si quieres un ejemplo de cómo puede utilizarse la solución DatabricksLakehouse para la IA, te recomiendo queleas Una guía completa de la IA de Databricks Lakehouse para científicos de datos.
Muchas organizaciones utilizan los lagos de datos para el almacenamiento y archivo a largo plazo.
Gracias al bajo coste del almacenamiento de objetos en la nube, es económicamente factible almacenar años de datos operativos que quizá no se utilicen a diario, pero a los que aún es necesario acceder con fines de cumplimiento y auditoría, análisis de tendencias, previsiones o entrenamiento de futuros modelos de ML.
La mayoría de las soluciones de almacenamiento de objetos en la nube te permiten escalonar el almacenamiento para archivar los datos a los que se accede raramente, manteniendo el lago reducido y eficiente.
Los lagos de datos permiten a los científicos de datos explorar datos brutos sin restricciones.
Tanto si estás construyendo un prototipo rápido, probando una nueva hipótesis o ejecutando un análisis exploratorio de datos (AED), el lago te ofrece un acceso flexible a:
Esta capa de experimentación es esencial para la innovación. Los lagos de datos te permiten explorar conjuntos de datos de nuevas formas sin tener que enviar tickets al equipo de ingeniería de datos ni esperar a tener una versión depurada en el almacén.
Aunque los lagos de datos proporcionan potentes capacidades para los flujos de trabajo de datos modernos, también presentan retos únicos. Comprender ambas partes es esencial antes de adoptar una arquitectura de lago de datos. En esta sección, hablaré de las principales ventajas, los escollos más comunes y cómo superarlos.
La ventaja más significativa de un lago de datos es su flexibilidad. No estás atado a un esquema o modelo de datos específico desde el principio, lo que es excelente cuando trabajas con conjuntos de datos que cambian o evolucionan rápidamente.
He aquí algunas ventajas clave:
En los proyectos en los que he trabajado, esta centralización ha reducido los silos de datos y ha mejorado significativamente la colaboración entre equipos.
Los lagos de datos son potentes, pero hay que gestionar algunos retos clave. Si no se gestionan, pueden quedar rápidamente desorganizados e inutilizables, un estado que suele denominarse "pantano de datos".
Algunos retos comunes son:
Estos problemas pueden reducir la confianza en el lago de datos y la adopción en toda la empresa.
Los lagos de datos de más éxito tienen sólidas prácticas de gestión de metadatos y del ciclo de vida.
He aquí cómo reducir el riesgo y mantener sano tu lago de datos:
Un lago de datos puede seguir siendo un activo y no un pasivo si se diseña una arquitectura limpia desde el principio y se establecen estructuras de gobierno sólidas.
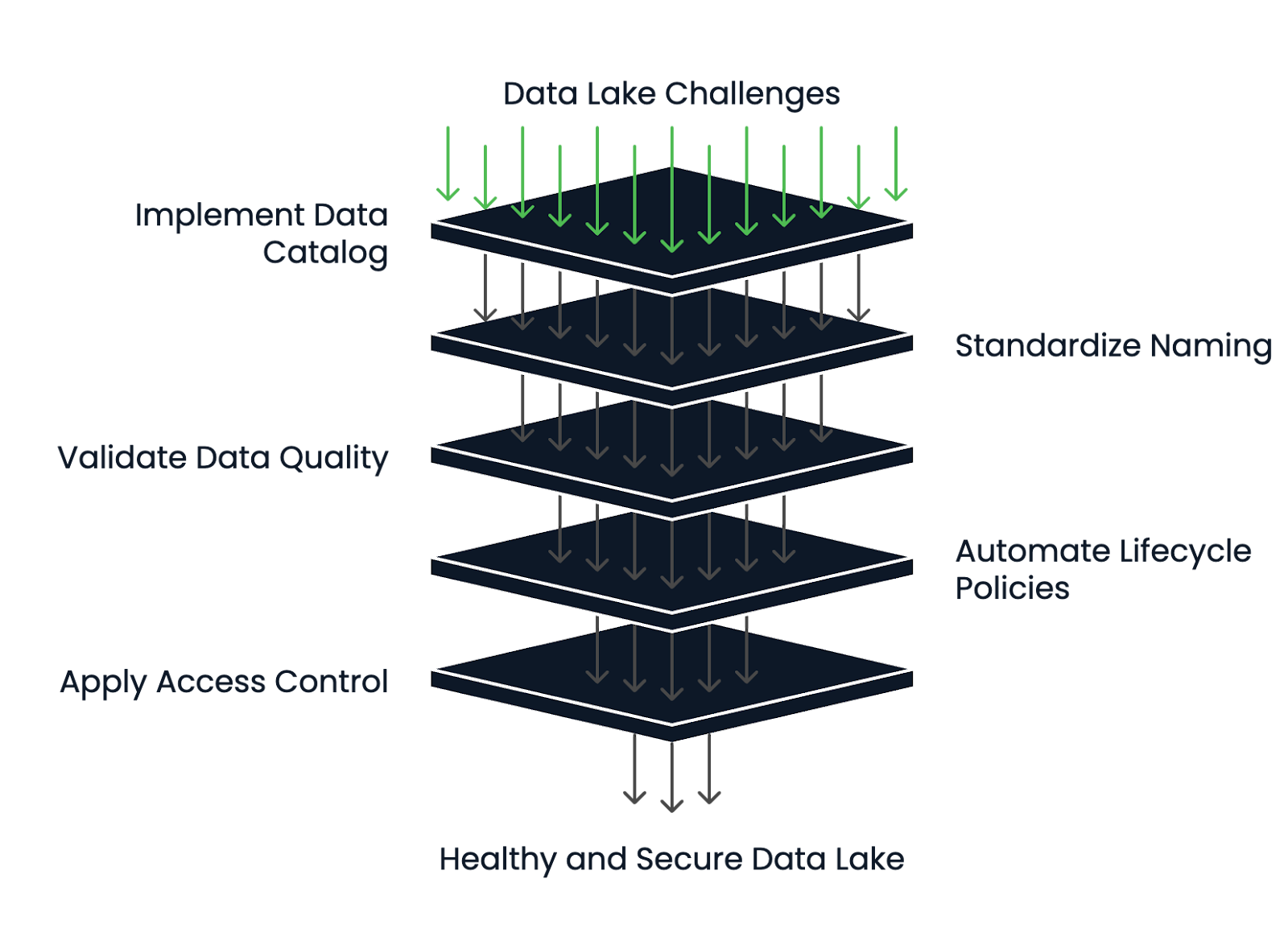
Marco de gestión de la salud del lago de datos. Imagen del autor.
Con la creciente importancia de los lagos de datos en la arquitectura de datos moderna, ha surgido una amplia gama de tecnologías para darles soporte. Estas herramientas abarcan plataformas nativas en la nube, ecosistemas de código abierto e integraciones con soluciones analíticas. En esta sección, te guiaré a través de las herramientas más populares.
Los proveedores de la nube ofrecen servicios totalmente gestionados para crear y mantener lagos de datos. Estas plataformas suelen ser el punto de partida para los equipos que buscan escala, durabilidad y una estrecha integración con otros servicios en la nube.
Las soluciones nativas en la nube más populares son:
Estos servicios están optimizados para ofrecer elasticidad, rentabilidad y seguridad, lo que los hace ideales para los lagos de datos a escala empresarial.
Las tecnologías de código abierto añaden flexibilidad y extensibilidad, especialmente para los equipos que quieren evitar la dependencia de un proveedor u operar en entornos híbridos/multi-nube.
Las soluciones más populares son:
Estas herramientas suelen integrarse en plataformas de datos más amplias y son las preferidas por los equipos de ingeniería que construyen soluciones personalizadas o modulares.
Si quieres explorar las diferencias entreApache Iceberg y Delta Lake con más detalle, te recomiendo queleas Apache Iceberg vs. Delta Lake. Delta Lake: Características, diferencias y casos de uso.
Un lago de datos adquiere valor cuando se integra con herramientas de análisis y visualización que ayudan a extraer ideas e impulsar las decisiones empresariales. Por tanto, antes de seleccionar la solución definitiva, siempre hay que comprobar por adelantado con qué plataformas analíticas debe integrarse la solución de lago de datos.
Las plataformas analíticas más populares son:
Si quieres saber más sobre Databricks , te recomiendoel curso Introducción a Databricks.
Al elegir las tecnologías, es esencial alinearlas con la experiencia de tu equipo, tu estrategia de datos y el nivel de flexibilidad o abstracción que necesitas.
Los lagos de datos permiten a las organizaciones crear sólidas aplicaciones de aprendizaje automático y cuadros de mando en tiempo real, al ofrecer una base de datos flexible, escalable, sin procesar y semiestructurada.
En este artículo, exploramos qué es un lago de datos, sus componentes clave y cuándo utilizarlo. Discutimos las ventajas, como la flexibilidad y la escalabilidad, los retos, como la gobernanza de los datos y el riesgo de un "pantano de datos", y cómo evitarlos. Por último, cubrimos las tecnologías más populares para construir lagos de datos, incluidas las plataformas en la nube y las herramientas de código abierto.
Desde mi experiencia trabajando en MLOps, infraestructuras de IA y sistemas de datos nativos en la nube, he visto cómo un lago de datos bien diseñado puede transformar la forma en que los equipos colaboran e innovan. Pero también he visto lo rápido que un lago de datos mal gobernado puede convertirse en un lastre, y navegar por él puede resultar difícil.
Si tu organización maneja datos complejos, diversos o a gran escala y quiere permitiruna experimentación más rápida, análisis más ricos o desarrollo de IA, un lago de datos puede ser precisamente lo que necesitas.
El curso Comprender la Arquitectura Moderna de Datos es una gran primera parada si quieres saber más.
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Matt Crabtree
10 min
blog
Matt Crabtree
15 min
blog
Mike Shakhomirov
11 min
Tutorial
Joleen Bothma

