
Course
Understanding Data Engineering
2 hr
355.8K
As someone who’s supported data teams with MLOps platforms and helped design scalable infrastructures, I’ve seen firsthand how crucial data lakes are in today’s data stack.
Unlike traditional data warehouses, which require data to be clean and structured before storage, data lakes let you store everything in raw, messy, and unstructured formats. This flexibility unlocks a world of possibilities for data-driven applications and use cases. A data lake allows you to gather and store data from various sources in one place, where it can be further analyzed and used for AI.
In this article, I’ll explain what a data lake is, how it works, when to use it, and how it compares to more traditional solutions.
Before discussing the technical architecture or use cases, it’s essential to understand what a data lake is and what distinguishes it from more traditional storage systems.
This section defines the concept, breaks down its key characteristics, and compares it to the more structured world of data warehouses.
I recommend the Data Strategy course if you want to learn more about how a well-designed data strategy can help businesses.
A data lake is a centralized repository that stores all your structured, semi-structured, and unstructured data at any scale.
You can ingest raw data from various sources and keep it in its original format until you need to process or analyze it.
Unlike databases or data warehouses, which typically require a predefined schema (schema-on-write), data lakes use a schema-on-read approach. This means the structure is applied only when data is accessed for analysis, giving teams flexibility in interpreting and transforming the data later.
A data lake comes with the following core characteristics:
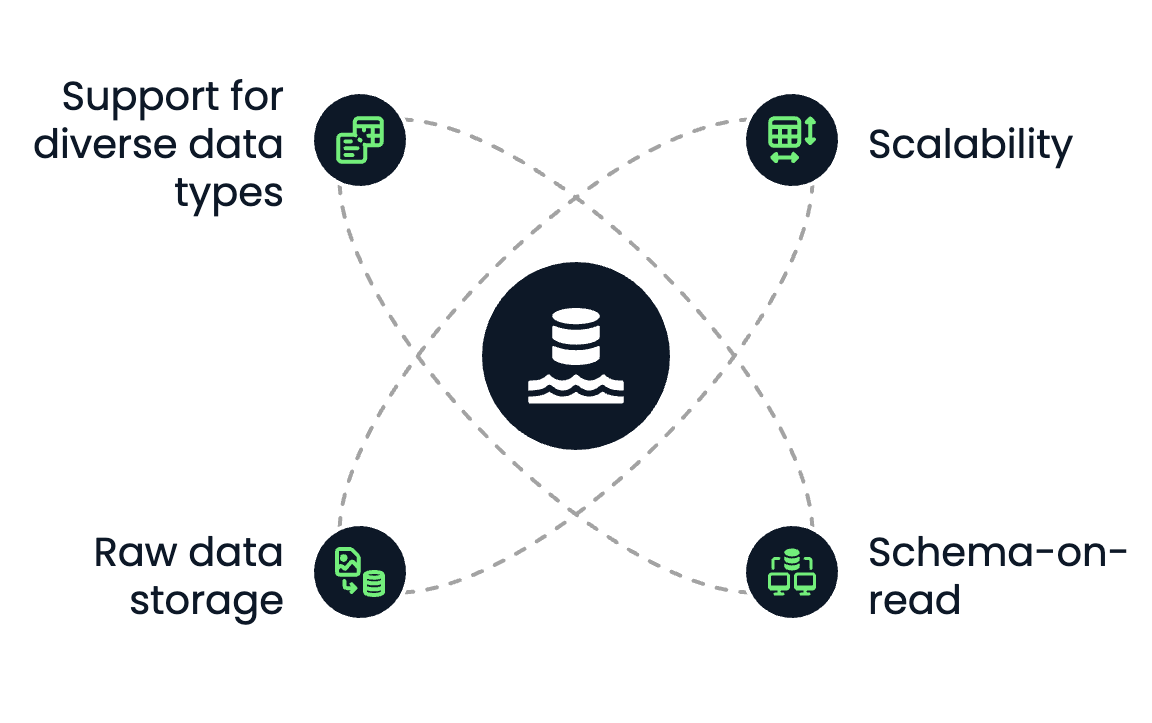
Core characteristics of data lakes. Image by Author.
Data lakes and data warehouses are used to store and analyze data. Yet, they differ significantly in structure, performance, and use cases.
If you are new to data warehouses and want to learn more, I recommend the course Data Warehousing Concepts and the articles What Is a Data Warehouse and Data Warehouse Architecture: Trends, Tools, and Techniques.
Let’s see how they differ:
|
Feature |
Data Lake |
Data Warehouse |
|
Data type |
Structured, semi-structured, unstructured |
Structured only |
|
Storage format |
Raw (file objects) |
Processed (tables, rows, columns) |
|
Schema |
Schema-on-read |
Schema-on-write |
|
Cost |
Low-cost storage |
More expensive per GB |
|
Use case |
Machine learning, big data, and raw data storage |
Business intelligence, structured analytics |
|
Performance |
Flexible, depends on the compute engine |
Optimized for fast SQL queries |
In practice, many modern data strategies combine both: using data lakes as the foundation for raw data storage and data warehouses for structured reporting and business intelligence.
There is also a hybrid solution called a data lakehouse. The article What is a Data Lakehouse? Architecture, Technology & Use Cases explains it more fully.
A well-designed data lake architecture is essential to make raw data usable and accessible to downstream analytics, machine learning, and reporting.
This section breaks down the five key layers of a modern data lake, from ingestion to governance.
The ingestion layer brings data from various sources into the data lake. These sources include internal systems (like databases or CRMs), external APIs, or IoT devices and logs.
There are three main ingestion modes:
Standard ingestion tools include:
A flexible ingestion layer ensures that data arrives quickly and can handle a variety of formats and velocities.
When data is ingested, it is stored in the raw zone of the data lake. The storage layer is usually built on cloud object storage, which offers elastic scaling, redundancy, and cost efficiency.
Popular options include:
However, there are also options for companies that want to store their data in their on-premise clouds hosted in their data centers.
One could, for example, install MinIO in their infrastructure. MinIO itself is open-source and offers an Amazon S3-compatible API.
Key features of a storage layer include:
Storing data in its original format allows you to keep all its potential for future processing and analysis.
Without metadata, a data lake becomes a data swamp, as it's impossible to find your data again and work with it efficiently.
The catalog and metadata layer bring structure to the chaos by keeping track of:
This layer ensures discoverability and usability by indexing all available datasets and enabling search and access control. Standard tools for this layer include:
A sound metadata system is essential for collaboration, governance, and operational efficiency.
This is the layer where raw data gets processed and turned into insights. The processing layer supports various operations, from fundamental transformations to advanced analytics and machine learning.
Typical workflows include:
This layer often includes batch and real-time computing, enabling exploratory data analysis and production workloads.
A robust data lake architecture must have built-in mechanisms to protect sensitive data and ensure compliance. This part is crucial, as data lakes mostly contain a lot of sensitive data, which, when compromised, could harm the business to which they belong.
Essential features of that layer include:
Popular tools and services:
Security often determines whether a data lake can be used in regulated industries like finance, healthcare, or the military.
Data lakes are well-suited for use cases where scale, flexibility, and diverse data types are essential. They serve as the foundation for modern data-driven operations and applications across industries.
In this section, we’ll explore some of the most common and impactful use cases where data lakes play a central role.
One of the most well-known uses of data lakes is enabling large-scale data analytics.
Because data lakes can store data in its raw form, organizations no longer need to worry about cleaning or structuring every dataset before analysis. This is ideal when collecting logs, sensor data, or clickstreams, which are too large or fast-changing for traditional systems.
Data lakes make it possible to:
Tools like Amazon Athena or Google BigQuery can query data directly in the lake without requiring complex transformations or moving the data elsewhere.
Data lakes are a perfect fit for machine learning and AI workflows.
They provide the ideal environment for:
Instead of limiting models to pre-cleaned data from a warehouse, data scientists can access rich, raw data to experiment more freely and iterate faster. This is especially useful in domains like natural language processing (NLP), computer vision, and time-series forecasting.
If you want an example of how the Databricks Lakehouse solution can be used for AI, I recommend reading A Comprehensive Guide to Databricks Lakehouse AI For Data Scientists.
Many organizations use data lakes for long-term storage and archiving.
Thanks to the low cost of cloud object storage, it’s economically feasible to store years of operational data that may not be used daily but still needs to be accessible for compliance and audit purposes, trend analysis, forecasting, or training future ML models.
Most cloud object storage solutions allow you to tier your storage to archive rarely accessed data while keeping the lake lean and efficient.
Data lakes empower data scientists to explore raw data without constraints.
Whether you're building a quick prototype, testing a new hypothesis, or running exploratory data analysis (EDA), the lake gives you flexible access to:
This experimentation layer is essential for innovation. Data lakes let you explore datasets in new ways without submitting tickets to the data engineering team or waiting for a cleaned version in the warehouse.
While data lakes provide potent capabilities for modern data workflows, they also have unique challenges. Understanding both sides is essential before adopting a data lake architecture. In this section, I’ll discuss the main benefits, common pitfalls, and how to overcome them.
The most significant advantage of a data lake is its flexibility. You’re not bound to a specific schema or data model from the beginning, which is excellent when working with fast-changing or evolving datasets.
Here are some key benefits:
In projects I’ve worked on, this centralization has reduced data silos and improved cross-team collaboration significantly.
Data lakes are powerful, yet some key challenges must be managed. Left unmanaged, they can quickly become disorganized and unusable, a state often called a data swamp.
Some common challenges include:
These issues can reduce trust in the data lake and reduce adoption across the business.
The most successful data lakes have strong metadata and lifecycle management practices.
Here’s how to reduce risk and keep your data lake healthy:
A data lake can remain an asset and not a liability by designing a clean architecture from the beginning and establishing solid governance structures.
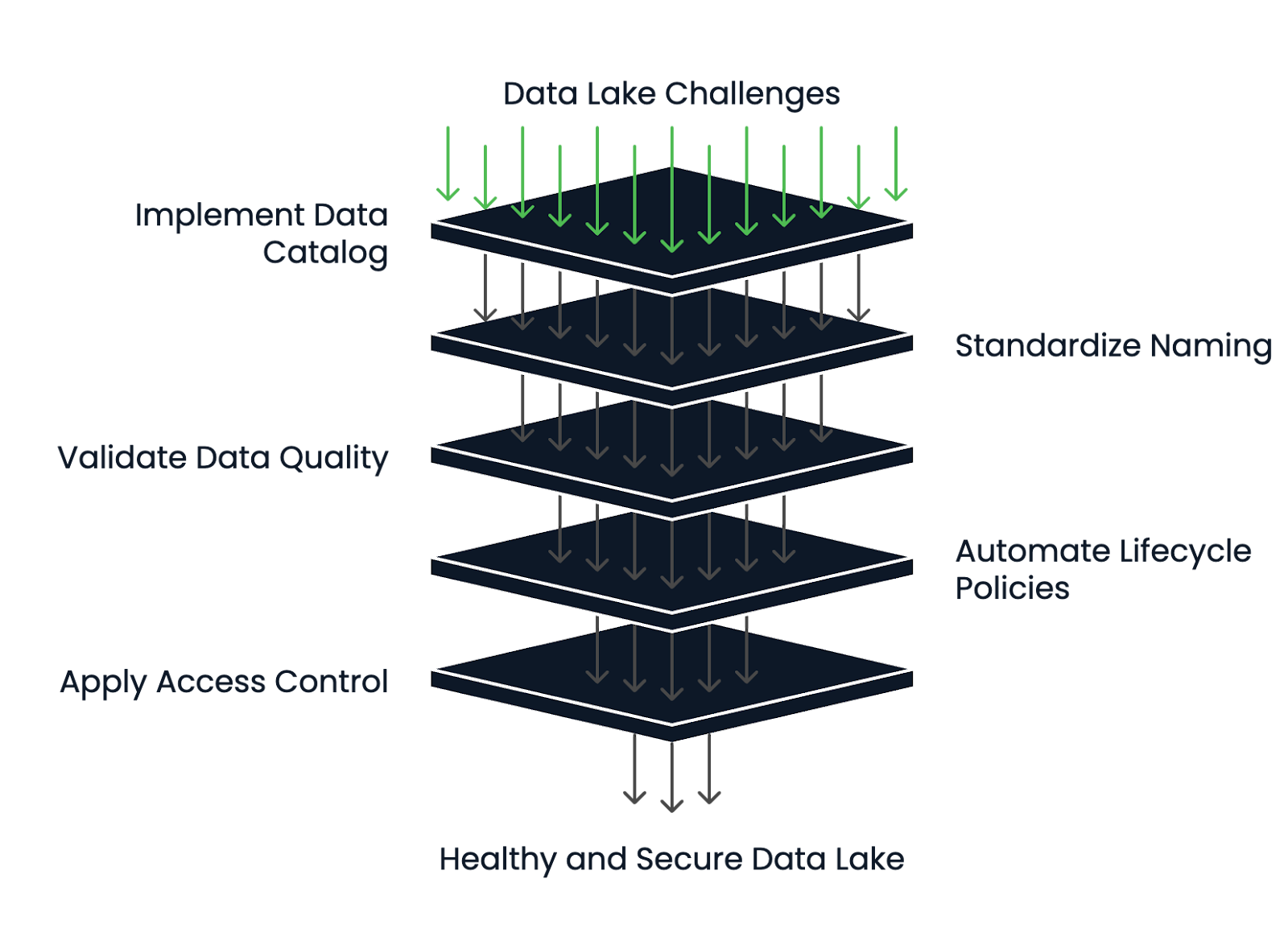
Data lake health management framework. Image by Author.
With the growing importance of data lakes in modern data architecture, a wide range of technologies has emerged to support them. These tools span cloud-native platforms, open-source ecosystems, and integrations with analytics solutions. In this section, I’ll walk you through the most popular tools.
Cloud providers offer fully managed services for building and maintaining data lakes. These platforms are often the starting point for teams looking for scale, durability, and tight integration with other cloud services.
Popular cloud-native solutions include:
These services are optimized for elasticity, cost-efficiency, and security, making them ideal for enterprise-scale data lakes.
Open-source technologies add flexibility and extensibility, especially for teams that want to avoid vendor lock-in or operate in hybrid/multi-cloud environments.
Popular solutions include:
These tools often integrate into broader data platforms and are favored by engineering teams building custom or modular solutions.
If you want to explore the differences between Apache Iceberg and Delta Lake in more detail, I recommend reading Apache Iceberg vs. Delta Lake: Features, Differences & Use Cases.
A data lake becomes valuable when integrated with analytics and visualization tools that help extract insights and drive business decisions. Therefore, before selecting the final solution, one should always check upfront with which analytics platforms the data lake solution should be integrated.
Popular analytics platforms include:
If you want to learn more about Databricks, I recommend the Introduction to Databricks course.
When choosing technologies, aligning them with your team’s expertise, your data strategy and the level of flexibility or abstraction you need is essential.
Data lakes empower organizations to build robust machine learning applications and real-time dashboards by offering a flexible, scalable, raw, and semi-structured data foundation.
In this article, we explored what a data lake is, its key components, and when to use one. We discussed the benefits like flexibility and scalability, challenges such as data governance and the risk of a "data swamp," and how to avoid them. Finally, we covered popular technologies for building data lakes, including cloud platforms and open-source tools.
From my experience working across MLOps, AI infrastructure, and cloud-native data systems, I’ve seen how a well-architected data lake can transform how teams collaborate and innovate. But I’ve also seen how quickly a poorly governed data lake can become a liability, and navigating it can become hard.
If your organization handles complex, diverse, or large-scale data and wants to enable faster experimentation, richer analytics, or AI development, a data lake might be precisely what you need.
The Understanding Modern Data Architecture course is a great first stop if you want to learn more.
Learn more about data engineering with these courses!
Course
Course
Course
blog
Moez Ali
15 min
blog
Sai Krupa Reddy
12 min
blog
Kurtis Pykes
15 min
blog
DataCamp Team
4 min
blog
Amberle McKee
8 min
blog
Bex Tuychiev
12 min