
Kurs
Grundlagen von Data Engineering
2 Std.
356K
Als jemand, der Datenteams mitMLOps-Plattformenunterstütztund an der Entwicklung skalierbarer Infrastrukturen mitgewirkt hat, weiß ich aus erster Hand, wie wichtig Data Lakes in der heutigen Datenlandschaft sind.
Im Gegensatz zu traditionellen Data Warehouses, bei denen die Daten vor der Speicherung sauber und strukturiert sein müssen, kannst du in Data Lakes alles in roher, ungeordneter und unstrukturierter Form speichern. Diese Flexibilität eröffnet dir eine Welt voller Möglichkeiten für datengesteuerte Anwendungen und Anwendungsfälle. Ein Data Lake ermöglicht es dir, Daten aus verschiedenen Quellen an einem Ort zu sammeln und zu speichern, wo sie weiter analysiert und für KI genutzt werden können.
In diesem Artikel erkläre ich, was ein Data Lake ist, wie er funktioniert, wann er eingesetzt werden sollte und wie er sich von herkömmlichen Lösungen unterscheidet.
Bevor wir über die technische Architektur oder Anwendungsfälle sprechen, ist es wichtig zu verstehen, was ein Data Lake ist und was ihn von herkömmlichen Speichersystemen unterscheidet.
In diesem Abschnitt wird das Konzept definiert, seine wichtigsten Merkmale aufgeschlüsselt und mit der stärker strukturierten Welt der Data Warehouses verglichen.
Ich empfehle den Kurs Datenstrategie, wenn du mehr darüber erfahren möchtest, wie eine gut durchdachte Datenstrategie Unternehmen helfen kann.
Ein Data Lake ist ein zentraler Speicher, der alle strukturierten, halbstrukturierten und unstrukturierten Daten in beliebigem Umfang speichert.
Du kannst Rohdaten aus verschiedenen Quellen einlesen und sie in ihrem ursprünglichen Format aufbewahren, bis du sie verarbeiten oder analysieren musst.
Im Gegensatz zu Datenbanken oder Data Warehouses, die in der Regel ein vordefiniertes Schema benötigen (Schema-on-write), verwenden Data Lakes einen Schema-on-read-Ansatz. Das bedeutet, dass die Struktur nur dann angewendet wird, wenn auf die Daten für die Analyse zugegriffen wird, sodass die Teams die Daten später flexibel interpretieren und umwandeln können.
Ein Data Lake weist die folgenden Hauptmerkmale auf:
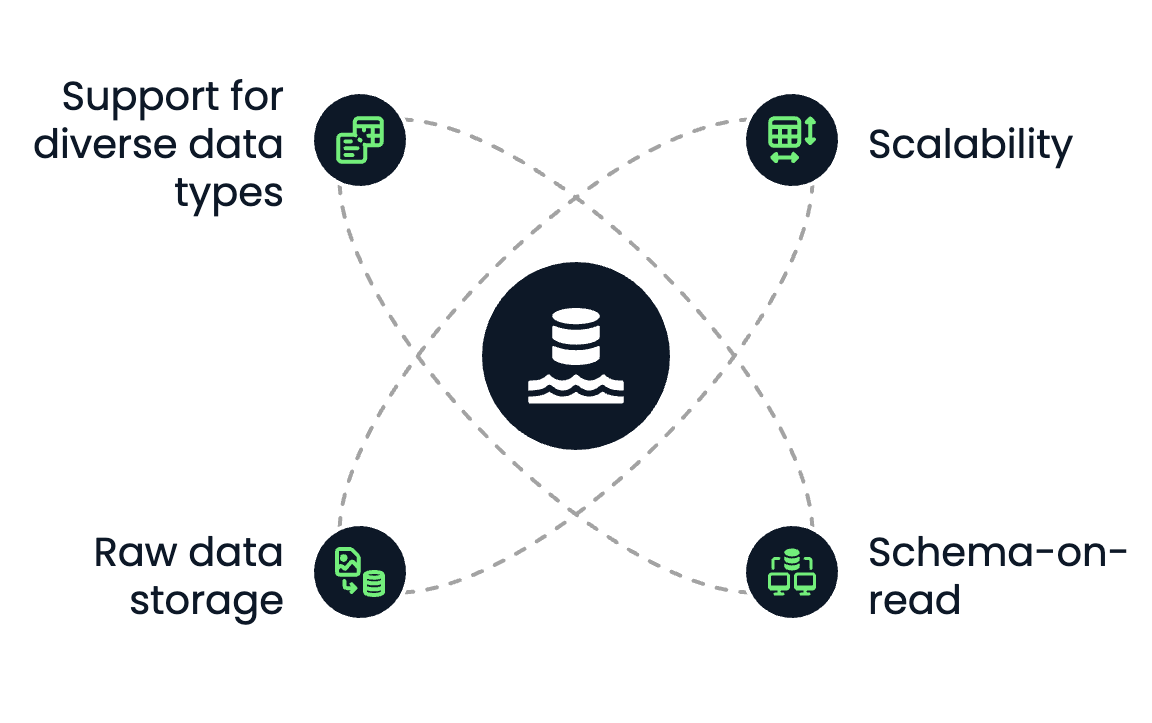
Kernmerkmale von Data Lakes. Bild vom Autor.
Data Lakes und Data Warehouses werden zum Speichern und Analysieren von Daten verwendet. Sie unterscheiden sich jedoch erheblich in Struktur, Leistung und Anwendungsfällen.
Wenn du neu im Bereich Data Warehouse bist und mehr darüber erfahren möchtest, empfehle ich dir den Kurs Data Warehousing Concepts und die Artikel What Is a Data Warehouse und Data Warehouse Architecture: Trends, Tools und Techniken.
Schauen wiruns an, wie siesich unterscheiden:
|
Feature |
Datensee |
Data Warehouse |
|
Datentyp |
Strukturiert, halbstrukturiert, unstrukturiert |
Nur strukturiert |
|
Speicherformat |
Raw (Dateiobjekte) |
Verarbeitet (Tabellen, Zeilen, Spalten) |
|
Schema |
Schema-on-read |
Schema-on-write |
|
Kosten |
Kostengünstige Lagerung |
Teurer pro GB |
|
Anwendungsfall |
Maschinelles Lernen, Big Data und Speicherung von Rohdaten |
Business Intelligence, strukturierte Analytik |
|
Leistung |
Flexibel, abhängig von der Compute Engine |
Optimiert für schnelle SQL-Abfragen |
In der Praxis kombinieren viele moderne Datenstrategien beides: Sie nutzen Data Lakes als Grundlage für die Speicherung von Rohdaten und Data Warehouses für strukturierte Berichte und Business Intelligence.
Es gibt auch eine hybride Lösung, das sogenannte Data Lakehouse. Der Artikel Was ist ein Data Lakehouse? Architektur, Technologie und Anwendungsfälle erklärt es genauer.
Eine gut durchdachte Data-Lake-Architektur ist wichtig, um Rohdaten für nachgelagerte Analysen, maschinelles Lernen und Berichte nutzbar und zugänglich zu machen.
In diesem Abschnitt werden die fünf Schlüsselebenen eines modernen Data Lakes beschrieben, von der Datenaufnahme bis zur Governance.
Der Ingestion Layer bringt Daten aus verschiedenen Quellen in den Data Lake. Zu diesen Quellen gehören interne Systeme (wie Datenbanken oder CRMs), externe APIs oder IoT-Geräte und Logs.
Es gibt drei Hauptarten der Einnahme:
Zu den Standard-Ingestion-Tools gehören:
Ein flexibler Ingestion Layer sorgt dafür, dass die Daten schnell ankommen und eine Vielzahl von Formaten und Geschwindigkeiten verarbeiten können.
Wenn die Daten aufgenommen werden, werden sie in der Rohzone des Data Lake gespeichert. Die Speicherebene basiert in der Regel auf Cloud Object Storage, der elastische Skalierung, Redundanz und Kosteneffizienz bietet.
Beliebte Optionen sind:
Es gibt aber auch Optionen für Unternehmen, die ihre Daten in ihren eigenen Clouds speichern wollen, die in ihren Rechenzentren gehostet werden.
Man könnte z.B. MinIO in seiner Infrastruktur installieren. MinIO selbst ist Open-Source und bietet eine Amazon S3-kompatible API.
Zu den wichtigsten Merkmalen einer Speicherschicht gehören:
Wenn du die Daten in ihrem ursprünglichen Format speicherst, behältst du ihr gesamtes Potenzial für die spätere Verarbeitung und Analyse.
Ohne Metadaten wird ein Data Lake zu einem Datensumpf, denn es ist unmöglich, deine Daten wiederzufinden und effizient mit ihnen zu arbeiten.
Der Katalog und die Metadatenebene bringen Struktur in das Chaos, indem sie den Überblick behalten:
Diese Ebene stellt die Auffindbarkeit und Nutzbarkeit sicher, indem sie alle verfügbaren Datensätze indexiert und die Suche und Zugriffskontrolle ermöglicht. Zu den Standardwerkzeugen für diese Ebene gehören:
Ein solides Metadatensystem ist für die Zusammenarbeit, die Verwaltung und die betriebliche Effizienz unerlässlich.
Dies ist die Ebene, auf der Rohdaten verarbeitet und in Erkenntnisse umgewandelt werden. Die Verarbeitungsebene unterstützt verschiedene Operationen, von grundlegenden Transformationen bis hin zu fortgeschrittenen Analysen und maschinellem Lernen.
TypischeArbeitsabläufe sind:
Diese Schicht umfasst oft Batch- und Echtzeitberechnungen, die explorative Datenanalysen und Produktionsworkloads ermöglichen.
Eine robuste Data-Lake-Architektur muss über integrierte Mechanismen verfügen, um sensible Daten zu schützen und die Einhaltung von Vorschriften zu gewährleisten. Dieser Teil ist entscheidend, da Data Lakes meist viele sensible Daten enthalten, die, wenn sie kompromittiert werden, dem Unternehmen, zu dem sie gehören, schaden könnten.
Zu den wesentlichen Merkmalen dieser Ebene gehören:
Beliebte Tools und Dienste:
Die Sicherheit entscheidet oft darüber, ob ein Data Lake in regulierten Branchen wie dem Finanzwesen, dem Gesundheitswesen oder dem Militär eingesetzt werden kann.
Data Lakes eignen sich gut für Anwendungsfälle, bei denen Skalierbarkeit, Flexibilität und unterschiedliche Datentypen wichtig sind. Sie dienen als Grundlage für moderne datengesteuerte Abläufe und Anwendungen in allen Branchen.
In diesem Abschnitt werden wir einige der häufigsten und wirkungsvollsten Anwendungsfälle untersuchen, in denen Data Lakes eine zentrale Rolle spielen.
Eine der bekanntesten Anwendungen von Data Lakes ist die Ermöglichung groß angelegter Datenanalysen.
Da Data Lakes Daten in ihrer Rohform speichern können, müssen sich Unternehmen nicht mehr darum kümmern, jeden Datensatz vor der Analyse zu bereinigen oder zu strukturieren. Dies ist ideal für die Erfassung von Logs, Sensordaten oder Clickstreams, die für herkömmliche Systeme zu groß sind oder sich schnell ändern.
Data Lakes machen es möglich,:
Toolswie Amazon Athena oder Google BigQuery können Daten direkt im Lake abfragen, ohne dass komplexe Transformationen oder das Verschieben der Daten an einen anderen Ort erforderlich sind.
Data Lakes sind perfekt für maschinelles Lernen und KI-Workflows geeignet.
Sie bieten die ideale Umgebung für:
Anstatt Modelle auf vorbereinigte Daten aus einem Lagerhaus zu beschränken, können Datenwissenschaftler/innen auf umfangreiche Rohdaten zugreifen, um freier zu experimentieren und schneller zu iterieren. Dies ist vor allem in Bereichen wie der Verarbeitung natürlicher Sprache (NLP), dem Computersehen und der Zeitreihenprognose nützlich.
Wenn du ein Beispiel dafür suchst, wie die Databricks Lakehouse-Lösung für KI genutzt werden kann, empfehle ich dirdie Lektüre von A Comprehensive Guide to Databricks Lakehouse AI For Data Scientists.
Viele Unternehmen nutzen Data Lakes für die langfristige Speicherung und Archivierung.
Dank der niedrigen Kosten der Cloud-Objektspeicherung ist es wirtschaftlich machbar, jahrelange Betriebsdaten zu speichern, die zwar nicht täglich genutzt werden, aber dennoch für Compliance- und Audit-Zwecke, Trendanalysen, Prognosen oder das Training zukünftiger ML-Modelle zugänglich sein müssen.
Die meisten Cloud-Objektspeicherlösungen ermöglichen es dir, deinen Speicher zu staffeln, um selten genutzte Daten zu archivieren und gleichzeitig den See schlank und effizient zu halten.
Data Lakes ermöglichen es Datenwissenschaftlern, Rohdaten ohne Einschränkungen zu untersuchen.
Ganz gleich, ob du einen schnellen Prototyp baust, eine neue Hypothese testest oder eine explorative Datenanalyse (EDA) durchführst, der Lake bietet dir flexiblen Zugriff darauf:
Diese Experimentierebene ist für die Innovation unerlässlich. Mit Data Lakes kannst du Datensätze auf neue Art und Weise erforschen, ohne Tickets an das Data Engineering Team zu schicken oder auf eine bereinigte Version im Warehouse zu warten.
Data Lakes bieten zwar leistungsstarke Funktionen für moderne Daten-Workflows, haben aber auch einzigartige Herausforderungen. Es ist wichtig, beide Seiten zu verstehen, bevor du eine Data-Lake-Architektur einführst. In diesem Abschnitt erläutere ich die wichtigsten Vorteile, die häufigsten Fallstricke und wie du sie umgehen kannst.
Der größte Vorteil eines Data Lake ist seine Flexibilität. Du bist nicht von Anfang an an ein bestimmtes Schema oder Datenmodell gebunden, was bei der Arbeit mit sich schnell ändernden oder sich weiterentwickelnden Datensätzen hervorragend ist.
Hier sind einige wichtige Vorteile:
In Projekten, an denen ich gearbeitet habe, hat diese Zentralisierung Datensilos reduziert und die teamübergreifende Zusammenarbeit deutlich verbessert.
Data Lakes sind leistungsfähig, aber es gibt einige wichtige Herausforderungen, die es zu bewältigen gilt. Wenn sie nicht verwaltet werden, können sie schnell unübersichtlich und unbrauchbar werden - ein Zustand, der oft als Datensumpf bezeichnet wird.
Zu den häufigsten Herausforderungen gehören:
Diese Probleme können das Vertrauen in den Data Lake mindern und die Akzeptanz im Unternehmen verringern.
Die erfolgreichsten Data Lakes verfügen über ein solides Metadaten- und Lebenszyklusmanagement.
Hier erfährst du, wie du das Risiko reduzierst und deinen Data Lake gesund hältst:
Ein Data Lake kann ein Aktivposten und keine Belastung sein, wenn von Anfang an eine saubere Architektur entworfen undsolide Governance-Struktureneingerichtet werden.
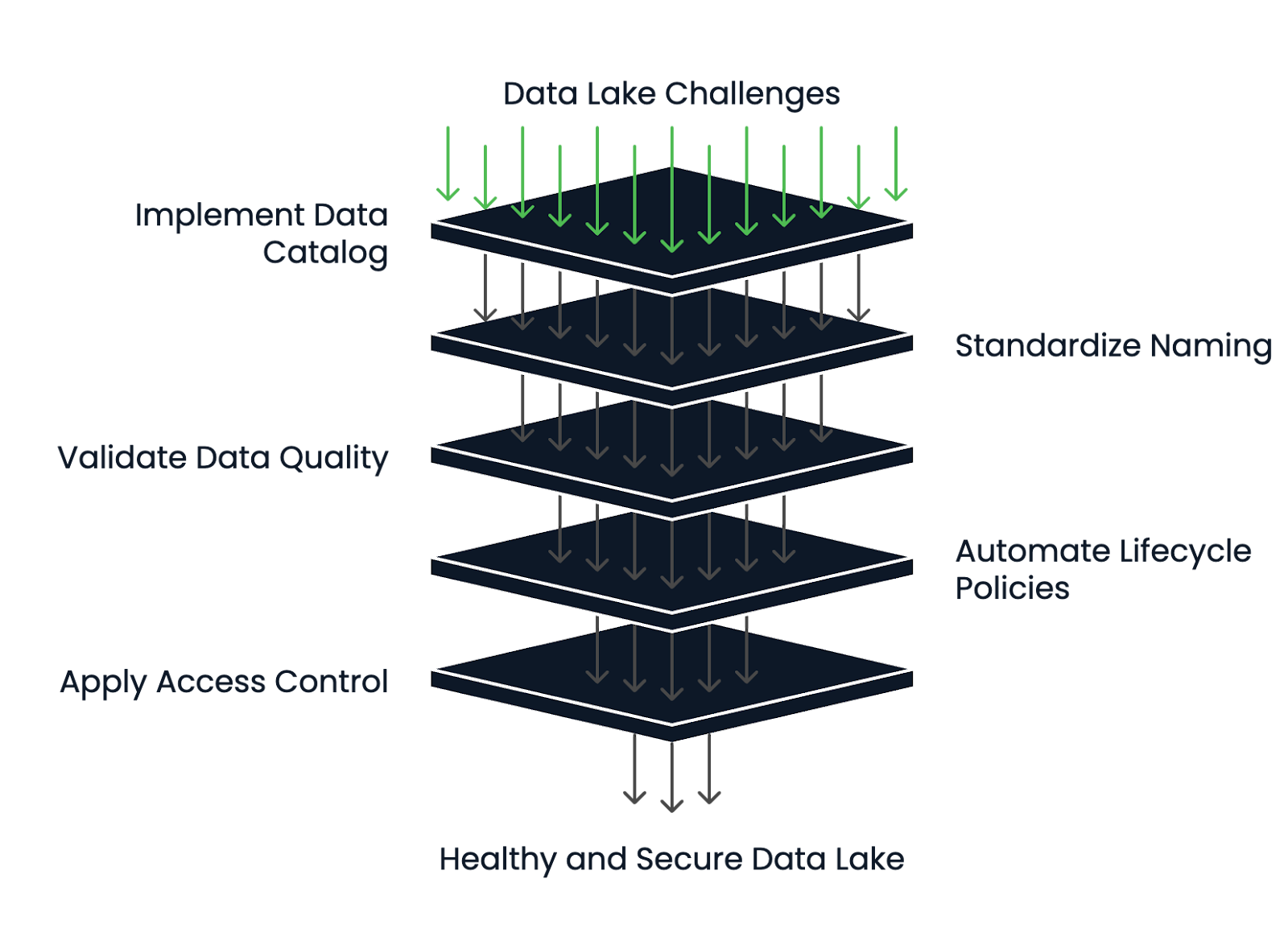
Data Lake Health Management Framework. Bild vom Autor.
Mit der wachsenden Bedeutung von Data Lakes in der modernen Datenarchitektur ist eine breite Palette von Technologien entstanden, die sie unterstützen. Diese Tools umfassen Cloud-native Plattformen, Open-Source-Ökosysteme und Integrationen mit Analyselösungen. In diesem Abschnitt stelle ich dir die beliebtesten Tools vor.
Cloud-Anbieter bieten vollständig verwaltete Dienste für den Aufbau und die Pflege von Data Lakes an. Diese Plattformen sind oft der Ausgangspunkt für Teams, die nach Skalierbarkeit, Langlebigkeit und enger Integration mit anderen Cloud-Diensten suchen.
Zu den beliebten Cloud-nativen Lösungen gehören:
Diese Dienste sind für Elastizität, Kosteneffizienz und Sicherheit optimiert und damit ideal für Data Lakes im Unternehmensmaßstab.
Open-Source-Technologien sorgen für mehr Flexibilität und Erweiterbarkeit, vor allem für Teams, die eine Herstellerbindung vermeiden oder in hybriden bzw. Multi-Cloud-Umgebungen arbeiten wollen.
Beliebte Lösungen sind:
Diese Tools lassen sich oft in breitere Datenplattformen integrieren und werden von Entwicklungsteams bevorzugt, die maßgeschneiderte oder modulare Lösungen entwickeln.
Wenn du die Unterschiede zwischen Apache Iceberg und Delta Lake genauer kennenlernen möchtest, empfehle ich dir, Apache Iceberg vs. Delta Lakezu lesen. Delta Lake: Merkmale, Unterschiede und Anwendungsfälle.
Ein Data Lake wird wertvoll, wenn er mit Analyse- und Visualisierungstools integriert wird, die helfen, Erkenntnisse zu gewinnen und Geschäftsentscheidungen zu treffen. Deshalb sollte man vor der Auswahl der endgültigen Lösung immer im Voraus prüfen, mit welchen Analyseplattformen die Data-Lake-Lösung integriert werden soll.
Beliebte Analyseplattformen sind u. a:
Wenn du mehr über Databricks erfahren möchtest, empfehle ich dirden Kurs Einführung in Databricks.
Bei der Auswahl von Technologien ist es wichtig, dass du sie mit dem Fachwissen deines Teams, deiner Datenstrategie und dem Grad an Flexibilität oder Abstraktion, den du brauchst, in Einklang bringst.
Data Lakes ermöglichen es Unternehmen, robuste Machine-Learning-Anwendungen und Echtzeit-Dashboards zu entwickeln, indem sie eine flexible, skalierbare, rohe und halbstrukturierte Datengrundlage bieten.
In diesem Artikel haben wir uns angesehen, was ein Data Lake ist, welche Komponenten er hat und wann man ihn einsetzen sollte. Wir erörterten die Vorteile wie Flexibilität und Skalierbarkeit, Herausforderungen wie Data Governance und das Risiko eines "Datensumpfes" und wie man sie vermeiden kann. Schließlich haben wir beliebte Technologien für den Aufbau von Data Lakes behandelt, darunter Cloud-Plattformen und Open-Source-Tools.
Durch meine Erfahrung in den Bereichen MLOps, KI-Infrastruktur und Cloud-native Datensysteme habe ich gesehen, wie ein gut strukturierter Data Lake die Zusammenarbeit und Innovation von Teams verändern kann. Aber ich habe auch gesehen, wie schnell ein schlecht verwalteter Datensee zu einer Belastung werden kann und wie schwierig es sein kann, sich darin zurechtzufinden.
Wenn dein Unternehmen komplexe, vielfältige oder umfangreiche Daten verarbeitet undschnellere Experimente, umfassendere Analysen oder KI-Entwicklung ermöglichen möchte, könnte ein Data Lake genau das Richtige für dich sein.
Der Kurs Understanding Modern Data Architecture ist eine gute erste Anlaufstelle, wenn du mehr erfahren möchtest.
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
