
Cours
Présentation de l’ingénierie des données
2 h
355.8K
En tant que personne ayant soutenu des équipes de données avec desplateformes MLOpset aidé à concevoir des infrastructures évolutives, j'ai vu de mes propres yeux à quel point les lacs de données sont cruciaux dans la pile de données d'aujourd'hui.
Contrairement aux entrepôts de données traditionnels, qui exigent que les données soient propres et structurées avant d'être stockées, les lacs de données vous permettent de tout stocker dans des formats bruts, désordonnés et non structurés. Cette flexibilité ouvre un monde de possibilités pour les applications et les cas d'utilisation axés sur les données. Un lac de données vous permet de rassembler et de stocker des données provenant de diverses sources en un seul endroit, où elles peuvent être analysées et utilisées pour l'IA.
Dans cet article, je vais vous expliquer ce qu'est un lac de données, comment il fonctionne, quand l'utiliser et comment il se compare aux solutions plus traditionnelles.
Avant d'aborder l'architecture technique ou les cas d'utilisation, il est essentiel de comprendre ce qu'est un lac de données et ce qui le distingue des systèmes de stockage plus traditionnels.
Cette section définit le concept, décompose ses principales caractéristiques et le compare au monde plus structuré des entrepôts de données.
Je vous recommande le cours sur la stratégie des données si vous souhaitez en savoir plus sur la manière dont une stratégie des données bien conçue peut aider les entreprises.
Un lac de données est un référentiel centralisé qui stocke toutes vos données structurées, semi-structurées et non structurées à n'importe quelle échelle.
Vous pouvez ingérer des données brutes provenant de diverses sources et les conserver dans leur format d'origine jusqu'à ce que vous ayez besoin de les traiter ou de les analyser.
Contrairement aux bases de données ou aux entrepôts de données, qui nécessitent généralement un schéma prédéfini (schéma à l'écriture), les lacs de données utilisent une approche de schéma à la lecture. Cela signifie que la structuren'est appliquée que lorsque l'on accède aux données pour les analyser, ce qui donne aux équipes une certaine souplesse pour interpréter et transformer les données par la suite.
Un lac de données présente les caractéristiques essentielles suivantes :
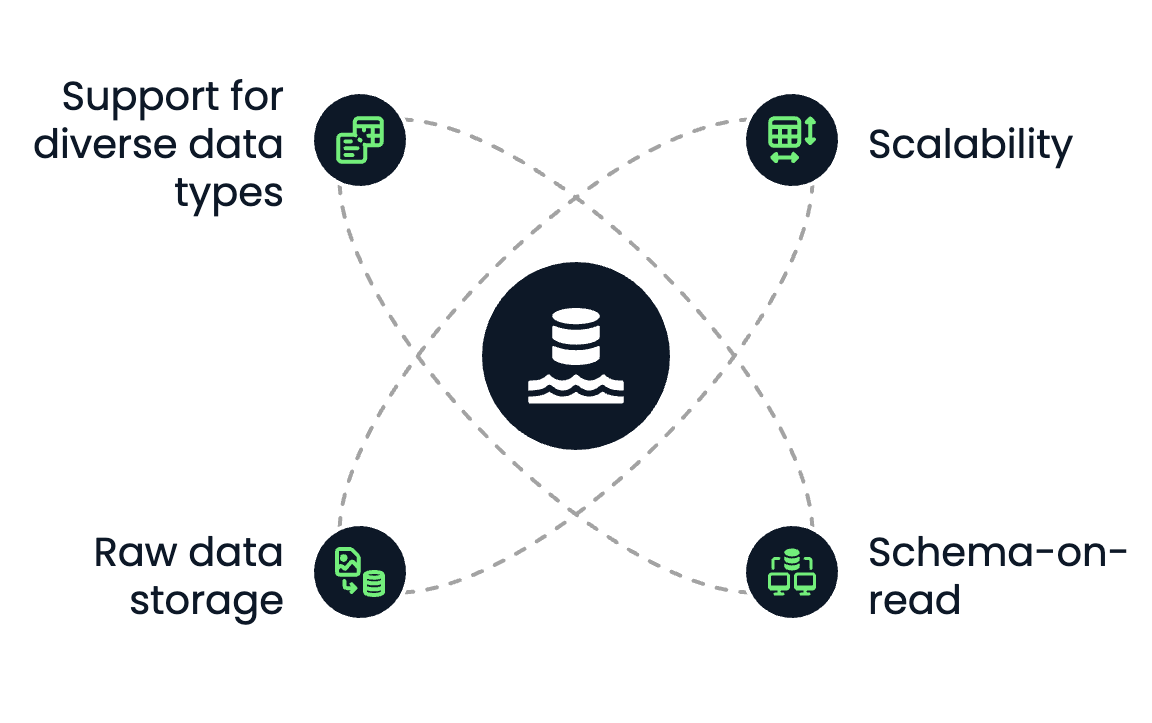
Caractéristiques principales des lacs de données. Image par l'auteur.
Les lacs de données et les entrepôts de données sont utilisés pour stocker et analyser les données. Cependant, ils diffèrent considérablement en termes de structure, de performances et de cas d'utilisation.
Si vous êtes novice en matière d'entrepôts de données et que vous souhaitez en savoir plus, je vous recommande le cours Concepts d'entreposage de données et les articles Qu'est-ce qu'un entrepôt de données et Architecture d'entrepôt de données : Tendances, outils et techniques.
Voyons ce quiles différencie :
|
Fonctionnalité |
Lac de données |
Entrepôt de données |
|
Type de données |
Structuré, semi-structuré, non structuré |
Structuré uniquement |
|
Format de stockage |
Brut (objets de fichiers) |
Traitée (tableaux, lignes, colonnes) |
|
Schéma |
Schéma en lecture |
Schéma en écriture |
|
Coût |
Stockage à faible coût |
Plus cher par Go |
|
Cas d'utilisation |
Apprentissage automatique, big data et stockage de données brutes |
Intelligence économique, analyse structurée |
|
Performance |
Flexible, dépend du moteur de calcul |
Optimisé pour des requêtes SQL rapides |
Dans la pratique, de nombreuses stratégies de données modernes combinent les deux : les lacs de données servent de base au stockage des données brutes et les entrepôts de données au reporting structuré et à la veille stratégique.
Il existe également une solution hybride appelée "data lakehouse". L'article Qu'est-ce qu'un Data Lakehouse ? Architecture, technologie et cas d'utilisation l'explique plus en détail.
Une architecture de lac de données bien conçue est essentielle pour rendre les données brutes utilisables et accessibles à l'analyse en aval, à l'apprentissage automatique et au reporting.
Cette section présente les cinq couches clés d'un lac de données moderne, de l'ingestion à la gouvernance.
La couche d'ingestion permet d'introduire dans le lac de données des données provenant de diverses sources. Ces sources comprennent les systèmes internes (comme les bases de données ou les CRM), les API externes, ou les appareils IoT et les journaux.
Il existe trois modes d'ingestion principaux :
Les outils d'ingestion standard sont les suivants
Une couche d'ingestion flexible garantit que les données arrivent rapidement et peut gérer une variété de formats et de vitesses.
Lorsque les données sont ingérées, elles sont stockées dans la zone brute du lac de données. La couche de stockage est généralement construite sur le stockage d'objets dans le cloud, qui offre une mise à l'échelle élastique, une redondance et un bon rapport coût-efficacité.
Les options les plus courantes sont les suivantes :
Toutefois, il existe également des options pour les entreprises qui souhaitent stocker leurs données dans leurs clouds sur site hébergés dans leurs centres de données.
On peut, par exemple, installer MinIO dans son infrastructure. MinIO est un logiciel libre qui propose une API compatible avec Amazon S3.
Les principales caractéristiques d'une couche de stockage sont les suivantes
Le stockage des données dans leur format d'origine vous permet de conserver tout leur potentiel en vue d'un traitement et d'une analyse ultérieurs.
Sans métadonnées, un lac de données devient un marécage de données, car il est impossible de retrouver vos données et de les utiliser efficacement.
Le catalogue et la couche demétadonnées apportent une structure au chaos en gardant une trace :
Cette couche garantit la facilité de découverte et d'utilisation en indexant tous les ensembles de données disponibles et en permettant la recherche et le contrôle d'accès. Les outils standard pour cette couche sont les suivants :
Un système de métadonnées solide est essentiel pour la collaboration, la gouvernance et l'efficacité opérationnelle.
C'est à ce niveau que les données brutes sont traitées et transformées en informations. La couche de traitement prend en charge diverses opérations, des transformations fondamentales aux analyses avancées et à l'apprentissage automatique.
Les flux de travail typiquessont les suivants :
Cette couche comprend souvent des calculs en lots et en temps réel, permettant l'analyse exploratoire des données et les charges de travail de production.
Une architecture robuste de lac de données doit comporter des mécanismes intégrés pour protéger les données sensibles et garantir la conformité. Cette partie est cruciale, car les lacs de données contiennent généralement de nombreuses données sensibles qui, si elles sont compromises, peuvent nuire à l'entreprise à laquelle elles appartiennent.
Les caractéristiques essentielles de cette couche sont les suivantes
Outils et services populaires :
La sécurité détermine souvent si un lac de données peut être utilisé dans des secteurs réglementés comme la finance, les soins de santé ou l'armée.
Les lacs de données sont bien adaptés aux cas d'utilisation où l'échelle, la flexibilité et la diversité des types de données sont essentielles. Ils servent de base aux opérations et applications modernes basées sur les données dans tous les secteurs d'activité.
Dans cette section, nous allons explorer quelques-uns des cas d'utilisation les plus courants et les plus importants dans lesquels les lacs de données jouent un rôle central.
L'une des utilisations les plus connues des lacs de données est l'analyse de données à grande échelle.
Les lacs de données pouvant stocker des données brutes, les entreprises n'ont plus à se préoccuper du nettoyage ou de la structuration de chaque ensemble de données avant de les analyser. Cette solution est idéale pour la collecte de journaux, de données de capteurs ou de flux de clics, qui sont trop volumineux ou évoluent trop rapidement pour les systèmes traditionnels.
Les lacs de données permettent de :
Des outilscomme Amazon Athena ou Google BigQuery permettent d'interroger les données directement dans le lac, sans nécessiter de transformations complexes ou de déplacement des données.
Les lacs de données sont parfaitement adaptés à l'apprentissage automatique et aux flux de travail de l'IA.
Ils constituent l'environnement idéal pour :
Au lieu de limiter les modèles à des données pré-nettoyées provenant d'un entrepôt, les scientifiques des données peuvent accéder à des données riches et brutes afin d'expérimenter plus librement et de procéder à des itérations plus rapides. Ceci est particulièrement utile dans des domaines tels que le traitement du langage naturel (NLP), la vision par ordinateur et les prévisions de séries temporelles.
Si vous voulez un exemple de la façon dont la solution Databricks Lakehouse peut être utilisée pour l'IA, je vous recommande delire A Comprehensive Guide to Databricks Lakehouse AI For Data Scientists (Guide complet de l'IA Databricks Lakehouse pour les scientifiques des données).
De nombreuses organisations utilisent des lacs de données pour le stockage et l'archivage à long terme.
Grâce au faible coût du stockage d'objets dans le cloud, il est économiquement possible de stocker des années de données opérationnelles qui ne sont peut-être pas utilisées quotidiennement, mais qui doivent tout de même être accessibles à des fins de conformité et d'audit, d'analyse des tendances, de prévision ou d'entraînement de futurs modèles ML.
La plupart des solutions de stockage objet dans le cloud vous permettent de hiérarchiser votre stockage afin d'archiver les données rarement consultées tout en conservant un lac léger et efficace.
Les lacs de données permettent aux data scientists d'explorer les données brutes sans contraintes.
Que vous construisiez un prototype rapide, que vous testiez une nouvelle hypothèse ou que vous réalisiez une analyse exploratoire des données (EDA), le lac vous offre un accès flexible :
Cette couche d'expérimentation est essentielle pour l'innovation. Les lacs de données vous permettent d'explorer des ensembles de données d'une nouvelle manière sans avoir à soumettre des tickets à l'équipe d'ingénierie des données ou à attendre une version nettoyée dans l'entrepôt.
Si les lacs de données offrent de puissantes capacités pour les flux de données modernes, ils présentent également des défis uniques. Il est essentiel de comprendre les deux aspects avant d'adopter une architecture de lac de données. Dans cette section, je discuterai des principaux avantages, des pièges les plus courants et de la manière de les surmonter.
L'avantage le plus important d'un lac de données est sa flexibilité. Vous n'êtes pas lié à un schéma ou à un modèle de données spécifique dès le départ, ce qui est excellent lorsque vous travaillez avec des ensembles de données qui changent ou évoluent rapidement.
En voici les principaux avantages :
Dans les projets sur lesquels j'ai travaillé, cette centralisation a permis de réduire les silos de données et d'améliorer considérablement la collaboration entre les équipes.
Les lacs de données sont puissants, mais certains défis majeurs doivent être relevés. Si elles ne sont pas gérées, elles peuvent rapidement devenir désorganisées et inutilisables, un état souvent appelé "marécage de données".
Les défis les plus courants sont les suivants :
Ces problèmes peuvent réduire la confiance dans le lac de données et son adoption par l'ensemble de l'entreprise.
Les lacs de données les plus performants ont de solides pratiques de gestion des métadonnées et du cycle de vie.
Voici comment réduire les risques et maintenir votre lac de données en bonne santé :
Un lac de données peut rester un actif et non un passif en concevant une architecture propre dès le départ et en établissant des structures de gouvernance solides.
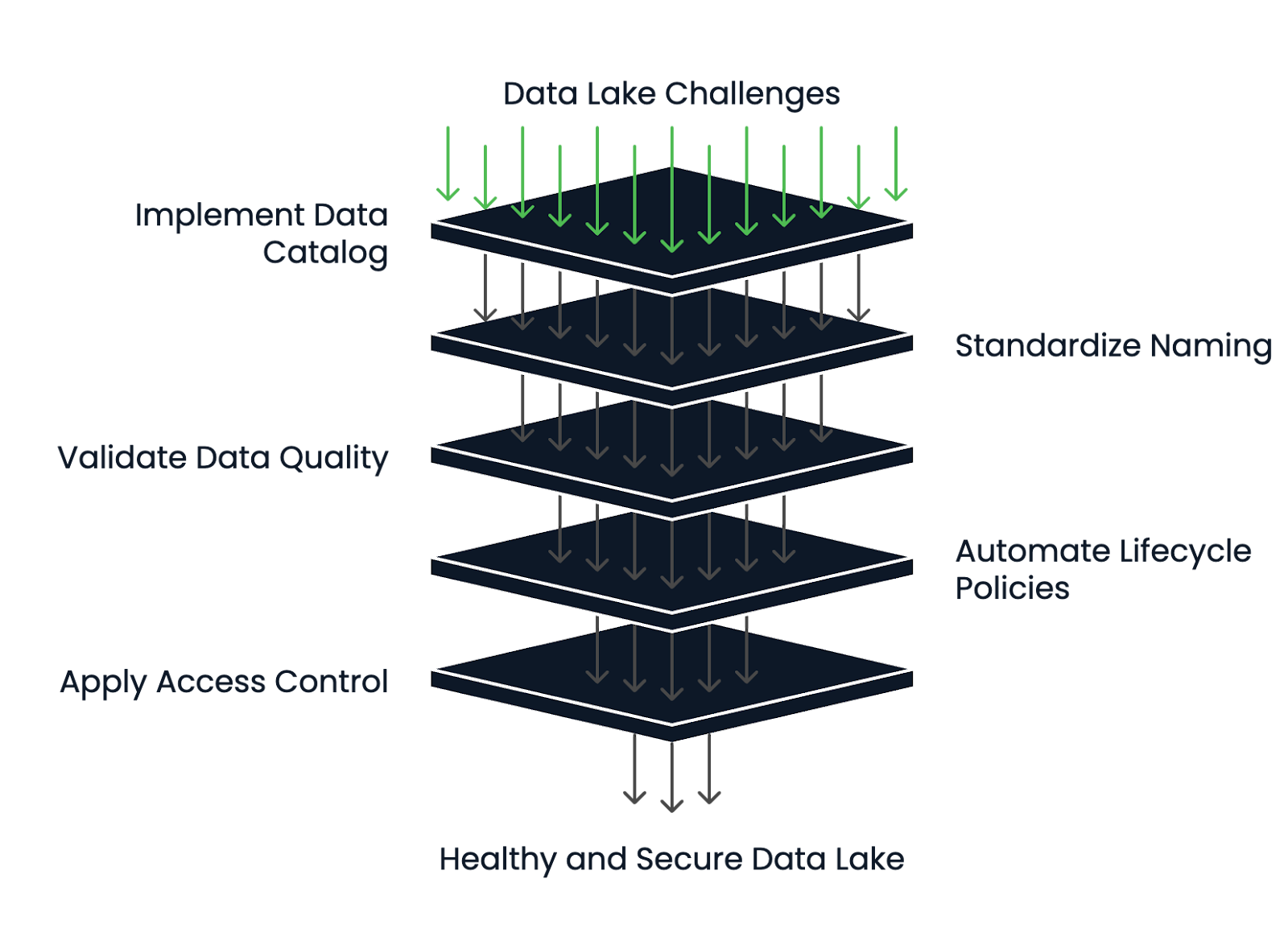
Cadre de gestion de la santé du lac de données. Image par l'auteur.
L'importance croissante des lacs de données dans l'architecture moderne des données a donné lieu à l'émergence d'un large éventail de technologies pour les prendre en charge. Ces outils couvrent les plateformes cloud-natives, les écosystèmes open-source et les intégrations avec des solutions d'analyse. Dans cette section, je vous présenterai les outils les plus populaires.
Les fournisseurs de cloud proposent des services entièrement gérés pour la construction et la maintenance des lacs de données. Ces plateformes sont souvent le point de départ pour les équipes qui recherchent l'évolutivité, la durabilité et une intégration étroite avec d'autres services cloud.
Parmi les solutions cloud-natives les plus populaires, citons :
Ces services sont optimisés pour l'élasticité, la rentabilité et la sécurité, ce qui les rend idéaux pour les lacs de données à l'échelle de l'entreprise.
Les technologies open-source ajoutent de la flexibilité et de l'extensibilité, en particulier pour les équipes qui veulent éviter le verrouillage des fournisseurs ou fonctionner dans des environnements hybrides/multi-cloud.
Les solutions les plus courantes sont les suivantes :
Ces outils s'intègrent souvent dans des plateformes de données plus larges et sont privilégiés par les équipes d'ingénieurs qui construisent des solutions personnalisées ou modulaires.
Si vous souhaitez étudier plus en détail les différences entre Apache Iceberg et Delta Lake, je vous recommande delire Apache Iceberg vs. Lac Delta : Caractéristiques, différences et cas d'utilisation.
Un lac de données devient précieux lorsqu'il est intégré à des outils d'analyse et de visualisation qui permettent d'extraire des informations et de prendre des décisions commerciales. Par conséquent, avant de choisir la solution finale, il faut toujours vérifier au préalable avec quelles plateformes analytiques la solution de lac de données doit être intégrée.
Les plates-formes d'analyse les plus répandues sont les suivantes :
Si vous souhaitez en savoir plus sur Databricks, je vous recommandele cours Introduction à Databricks.
Lors du choix des technologies, il est essentiel de les adapter à l'expertise de votre équipe, à votre stratégie en matière de données et au niveau de flexibilité ou d'abstraction dont vous avez besoin.
Les lacs de données permettent aux organisations de créer des applications d'apprentissage automatique robustes et des tableaux de bord en temps réel en offrant une base de données flexibles, évolutives, brutes et semi-structurées.
Dans cet article, nous avons exploré ce qu'est un lac de données, ses composants clés et quand l'utiliser. Nous avons discuté des avantages tels que la flexibilité et l'évolutivité, des défis tels que la gouvernance des données et le risque d'un "marécage de données", et de la manière de les éviter. Enfin, nous avons abordé les technologies populaires pour la construction de lacs de données, notamment les plateformes cloud et les outils open-source.
De par mon expérience au sein des MLOps, de l'infrastructure d'IA et des systèmes de données cloud-natives, j'ai pu constater qu'un lac de données bien architecturé peut transformer la façon dont les équipes collaborent et innovent. Mais j'ai également constaté qu'un lac de données mal géré peut rapidement devenir un handicap et qu'il peut être difficile de s'y retrouver.
Si votre organisation traite des données complexes, diverses ou à grande échelle et souhaiteaccélérer l'expérimentation, enrichir l'analyse ou développer l'IA, un lac de données pourrait être précisément ce dont vous avez besoin.
Le cours " Comprendre l'architecture moderne des données" est une excellente première étape si vous souhaitez en savoir plus.
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours