
Curso
Introdução à Engenharia de Dados
2 h
355.8K
Como alguém que já deu suporte a equipes de dados complataformas MLOpse ajudou a projetar infraestruturas dimensionáveis, vi em primeira mão como os data lakes são cruciais na pilha de dados atual.
Diferentemente dos data warehouses tradicionais, que exigem que os dados sejam limpos e estruturados antes do armazenamento, os data lakes permitem que você armazene tudo em formatos brutos, bagunçados e não estruturados. Essa flexibilidade abre um mundo de possibilidades para aplicativos orientados por dados e casos de uso. Um data lake permite que você reúna e armazene dados de várias fontes em um único local, onde eles podem ser analisados e usados para IA.
Neste artigo, explicarei o que é um data lake, como ele funciona, quando usá-lo e como ele se compara às soluções mais tradicionais.
Antes de discutir a arquitetura técnica ou os casos de uso, é essencial que você entenda o que é um data lake e o que o distingue dos sistemas de armazenamento mais tradicionais.
Esta seção define o conceito, detalha suas principais características e o compara com o mundo mais estruturado dos data warehouses.
Recomendo o curso Estratégia de dados se você quiser saber mais sobre como uma estratégia de dados bem elaborada pode ajudar as empresas.
Um data lake é um repositório centralizado que armazena todos os seus dados estruturados, semiestruturados e não estruturados em qualquer escala.
Você pode ingerir dados brutos de várias fontes e mantê-los em seu formato original até precisar processá-los ou analisá-los.
Diferentemente dos bancos de dados ou dos data warehouses, que normalmente exigem um esquema predefinido (schema-on-write), os data lakes usam uma abordagem de schema-on-read. Isso significa que a estrutura é aplicada somente quando os dados são acessados para análise, dando às equipes flexibilidade para interpretar e transformar os dados posteriormente.
Um data lake tem as seguintes características principais:
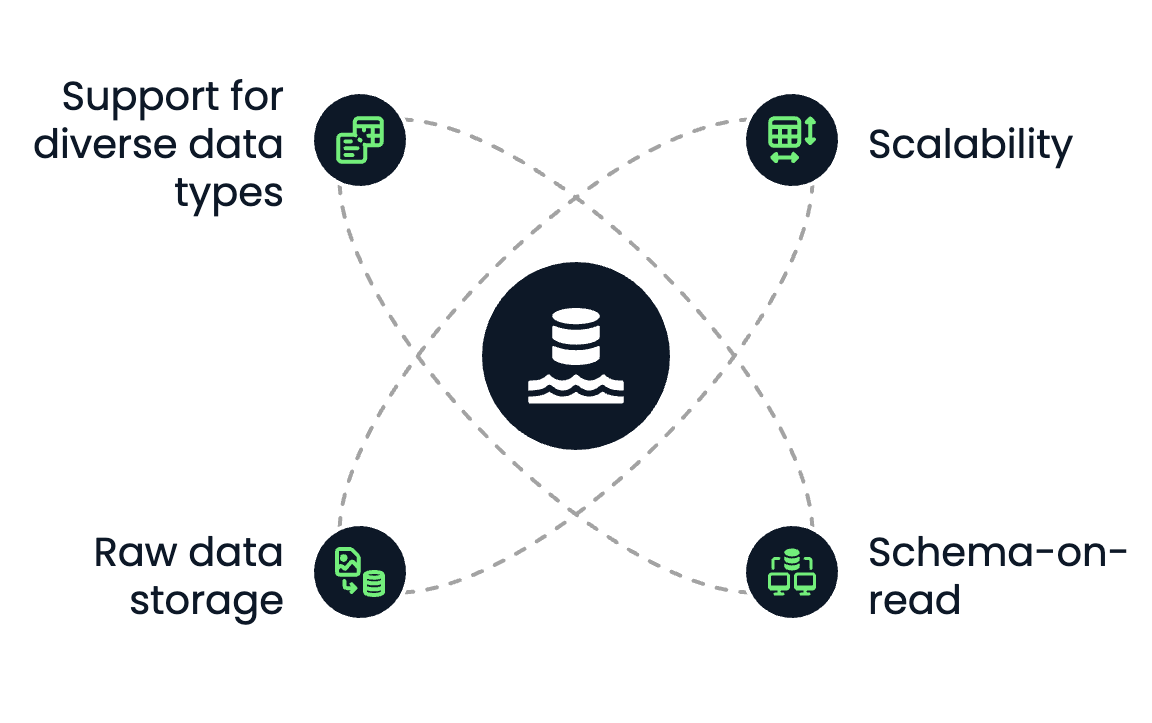
Principais características dos data lakes. Imagem do autor.
Os data lakes e data warehouses são usados para armazenar e analisar dados. No entanto, eles diferem significativamente em termos de estrutura, desempenho e casos de uso.
Se você não tem experiência com data warehouses e deseja saber mais, recomendo o curso Conceitos de data warehouse e os artigos O que é um data warehouse e Arquitetura de data warehouse: Tendências, ferramentas e técnicas.
Vamos ver como elesdiferem:
|
Recurso |
Lago de dados |
Data Warehouse |
|
Tipo de dados |
Estruturado, semiestruturado, não estruturado |
Somente estruturado |
|
Formato de armazenamento |
Raw (objetos de arquivo) |
Processado (tabelas, linhas, colunas) |
|
Esquema |
Esquema em leitura |
Esquema na gravação |
|
Custo |
Armazenamento de baixo custo |
Mais caro por GB |
|
Caso de uso |
Machine learning, big data e armazenamento de dados brutos |
Inteligência de negócios, análise estruturada |
|
Desempenho |
Flexível, depende do mecanismo de computação |
Otimizado para consultas SQL rápidas |
Na prática, muitas estratégias modernas de dados combinam ambos: usando data lakes como base para o armazenamento de dados brutos e data warehouses para relatórios estruturados e business intelligence.
Há também uma solução híbrida chamada de data lakehouse. O artigo O que é um Data Lakehouse? Architecture, Technology & Use Cases explica isso de forma mais completa.
Uma arquitetura de data lake bem projetada é essencial para tornar os dados brutos utilizáveis e acessíveis para análises downstream, machine learning e relatórios.
Esta seção detalha as cinco camadas principais de um data lake moderno, desde a ingestão até a governança.
A camada de ingestão traz dados de várias fontes para o lago de dados. Essas fontes incluem sistemas internos (como bancos de dados ou CRMs), APIs externas ou dispositivos e registros de IoT.
Há três modos principais de ingestão:
As ferramentas de ingestão padrão incluem:
Uma camada de ingestão flexível garante que os dados cheguem rapidamente e possa lidar com uma variedade de formatos e velocidades.
Quando os dados são ingeridos, eles são armazenados na zona bruta do lago de dados. A camada de armazenamento geralmente é criada com base no armazenamento de objetos em nuvem, que oferece dimensionamento elástico, redundância e eficiência de custo.
As opções mais populares incluem:
No entanto, também há opções para empresas que desejam armazenar seus dados em suas nuvens locais hospedadas em seus data centers.
Você pode, por exemplo, instalar o MinIO em sua infraestrutura. O próprio MinIO é de código aberto e oferece uma API compatível com o Amazon S3.
Os principais recursos de uma camada de armazenamento incluem:
O armazenamento de dados em seu formato original permite que você mantenha todo o seu potencial para processamento e análise futuros.
Sem metadados, um lago de dados se torna um pântano de dados, pois é impossível encontrar seus dados novamente e trabalhar com eles de forma eficiente.
O catálogo e a camada demetadados trazem estrutura ao caos, mantendo o controle:
Essa camada garante a capacidade de descoberta e de uso, indexando todos os conjuntos de dados disponíveis e permitindo a pesquisa e o controle de acesso. As ferramentas padrão para essa camada incluem:
Um sistema de metadados sólido é essencial para a colaboração, a governança e a eficiência operacional.
Essa é a camada em que os dados brutos são processados e transformados em insights. A camada de processamento oferece suporte a várias operações, desde transformações fundamentais até análises avançadas e machine learning.
Os fluxos de trabalho típicosincluem:
Essa camada geralmente inclui computação em lote e em tempo real, permitindo a análise exploratória de dados e cargas de trabalho de produção.
Uma arquitetura robusta de data lake deve ter mecanismos integrados para proteger dados confidenciais e garantir a conformidade. Essa parte é crucial, pois os data lakes contêm, em sua maioria, muitos dados confidenciais que, quando comprometidos, podem prejudicar a empresa à qual pertencem.
Os recursos essenciais dessa camada incluem:
Ferramentas e serviços populares:
A segurança geralmente determina se um data lake pode ser usado em setores regulamentados, como o financeiro, o de saúde ou o militar.
Os data lakes são adequados para casos de uso em que escala, flexibilidade e diversos tipos de dados são essenciais. Eles servem como base para operações e aplicativos modernos orientados por dados em todos os setores.
Nesta seção, exploraremos alguns dos casos de uso mais comuns e impactantes em que os lagos de dados desempenham um papel central.
Um dos usos mais conhecidos dos data lakes é permitir a análise de dados em grande escala.
Como os data lakes podem armazenar dados em sua forma bruta, as organizações não precisam mais se preocupar com a limpeza ou a estruturação de cada conjunto de dados antes da análise. Isso é ideal para a coleta de logs, dados de sensores ou fluxos de cliques, que são muito grandes ou mudam rapidamente para os sistemas tradicionais.
Os data lakes possibilitam que você:
Ferramentascomo o Amazon Athena ou o Google BigQuery podem consultar dados diretamente no lago sem exigir transformações complexas ou mover os dados para outro lugar.
Os data lakes são perfeitos para os fluxos de trabalho de machine learning e IA.
Eles proporcionam o ambiente ideal para você:
Em vez de limitar os modelos a dados pré-limpos de um warehouse, os cientistas de dados podem acessar dados ricos e brutos para fazer experiências com mais liberdade e iterar mais rapidamente. Isso é especialmente útil em domínios como processamento de linguagem natural (NLP), visão computacional e previsão de séries temporais.
Se você quiser um exemplo de como a solução Databricks Lakehouse pode ser usada para IA, recomendoa leitura de A Comprehensive Guide to Databricks Lakehouse AI For Data Scientists.
Muitas organizações usam data lakes para armazenamento e arquivamento de longo prazo.
Graças ao baixo custo do armazenamento de objetos em nuvem, é economicamente viável armazenar anos de dados operacionais que podem não ser usados diariamente, mas que ainda precisam estar acessíveis para fins de conformidade e auditoria, análise de tendências, previsão ou treinamento de futuros modelos de ML.
A maioria das soluções de armazenamento de objetos em nuvem permite que você classifique seu armazenamento em níveis para arquivar dados raramente acessados e, ao mesmo tempo, manter o lago enxuto e eficiente.
Os data lakes permitem que os cientistas de dados explorem dados brutos sem restrições.
Quer você esteja criando um protótipo rápido, testando uma nova hipótese ou executando uma análise exploratória de dados (EDA), o lago oferece acesso flexível a:
Essa camada de experimentação é essencial para a inovação. Os data lakes permitem que você explore conjuntos de dados de novas maneiras sem enviar tíquetes para a equipe de engenharia de dados ou esperar por uma versão limpa no warehouse.
Embora os data lakes ofereçam recursos potentes para fluxos de trabalho de dados modernos, eles também apresentam desafios exclusivos. Compreender os dois lados é essencial antes de adotar uma arquitetura de data lake. Nesta seção, discutirei os principais benefícios, as armadilhas comuns e como superá-las.
A vantagem mais significativa de um data lake é sua flexibilidade. Você não está vinculado a um esquema ou modelo de dados específico desde o início, o que é excelente quando se trabalha com conjuntos de dados que mudam ou evoluem rapidamente.
Aqui estão alguns dos principais benefícios:
Nos projetos em que trabalhei, essa centralização reduziu os silos de dados e melhorou significativamente a colaboração entre as equipes.
Os lagos de dados são poderosos, mas alguns desafios importantes devem ser gerenciados. Se não forem gerenciados, eles podem rapidamente se tornar desorganizados e inutilizáveis, um estado geralmente chamado de pântano de dados.
Alguns desafios comuns incluem:
Esses problemas podem diminuir a confiança no data lake e reduzir a adoção em toda a empresa.
Os data lakes mais bem-sucedidos têm práticas sólidas de gerenciamento de metadados e de ciclo de vida.
Veja como você pode reduzir os riscos e manter seu lago de dados saudável:
Um data lake pode continuar sendo um ativo, e não um passivo, se você projetar uma arquitetura limpa desde o início e estabelecer estruturas de governança sólidas.
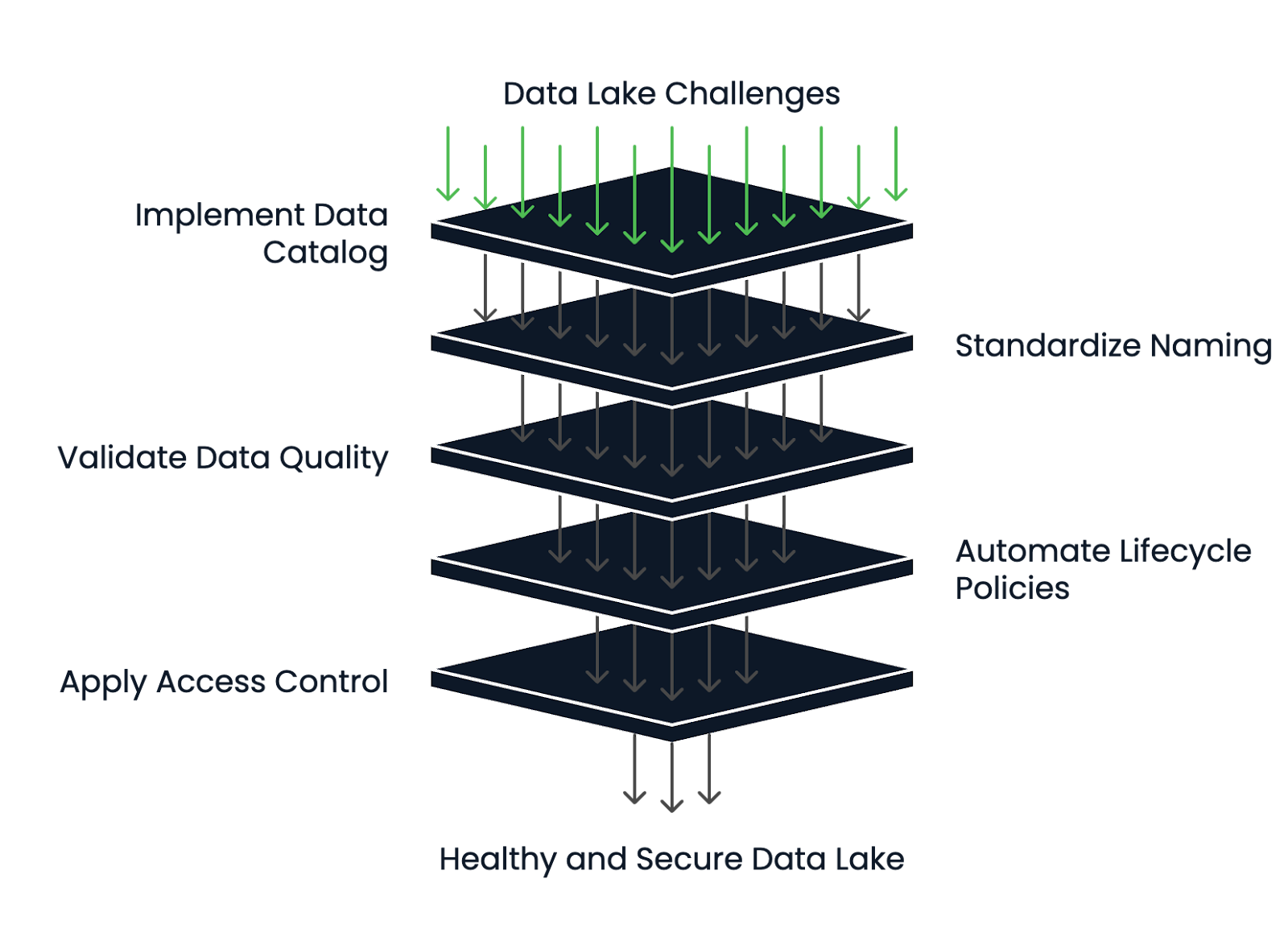
Estrutura de gerenciamento da integridade do lago de dados. Imagem do autor.
Com a crescente importância dos data lakes na arquitetura de dados moderna, surgiu uma ampla gama de tecnologias para dar suporte a eles. Essas ferramentas abrangem plataformas nativas de nuvem, ecossistemas de código aberto e integrações com soluções de análise. Nesta seção, mostrarei a você as ferramentas mais populares.
Os provedores de nuvem oferecem serviços totalmente gerenciados para a criação e manutenção de data lakes. Essas plataformas costumam ser o ponto de partida para equipes que buscam escala, durabilidade e forte integração com outros serviços em nuvem.
As soluções populares nativas da nuvem incluem:
Esses serviços são otimizados para elasticidade, economia e segurança, o que os torna ideais para lagos de dados em escala empresarial.
As tecnologias de código aberto adicionam flexibilidade e extensibilidade, especialmente para equipes que desejam evitar a dependência de fornecedores ou operar em ambientes híbridos/multi-nuvem.
As soluções mais populares incluem:
Essas ferramentas geralmente se integram a plataformas de dados mais amplas e são preferidas pelas equipes de engenharia que criam soluções personalizadas ou modulares.
Se você quiser explorar as diferenças entre o Apache Iceberg e o Delta Lake com mais detalhes, recomendoa leitura de Apache Iceberg vs. Delta Lake. Delta Lake: Recursos, diferenças e casos de uso.
Um lago de dados se torna valioso quando integrado a ferramentas de análise e visualização que ajudam a extrair insights e a orientar as decisões de negócios. Portanto, antes de selecionar a solução final, você deve sempre verificar antecipadamente com quais plataformas de análise a solução de data lake deve ser integrada.
As plataformas de análise mais populares incluem:
Se você quiser saber mais sobre o Databricks, recomendoo curso Introduction to Databricks.
Ao escolher as tecnologias, é essencial alinhá-las à experiência da sua equipe, à sua estratégia de dados e ao nível de flexibilidade ou abstração de que você precisa.
Os data lakes capacitam as organizações a criar aplicativos robustos de machine learning e painéis em tempo real, oferecendo uma base de dados flexível, escalável, bruta e semiestruturada.
Neste artigo, exploramos o que é um data lake, seus principais componentes e quando você deve usá-lo. Discutimos os benefícios, como flexibilidade e escalabilidade, os desafios, como a governança de dados e o risco de um "pântano de dados", e como evitá-los. Por fim, abordamos tecnologias populares para a criação de data lakes, incluindo plataformas de nuvem e ferramentas de código aberto.
Com base na minha experiência de trabalho em MLOps, infraestrutura de IA e sistemas de dados nativos da nuvem, vi como um data lake bem arquitetado pode transformar a forma como as equipes colaboram e inovam. Mas também vi como um lago de dados mal governado pode se tornar um problema rapidamente, e navegar por ele pode se tornar difícil.
Se a sua organização lida com dados complexos, diversificados ou em grande escala e deseja permitirexperimentação mais rápida, análises mais ricas ou desenvolvimento de IA, um data lake pode ser exatamente o que você precisa.
O curso Understanding Modern Data Architecture é uma ótima primeira parada se você quiser saber mais.
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Moez Ali
11 min
blog
Joleen Bothma
9 min
blog
Elena Kosourova
15 min
blog
Matt Crabtree
10 min
blog
Matt Crabtree
15 min
Tutorial
Kurtis Pykes




