
Cursus
Principes fondamentaux des agents IA
6 h
Pour de nombreuses personnes, les grands modèles linguistiques (LLM) sont principalement utilisés comme interfaces conversationnelles. Vous posez une question, le modèle répond, et l'interaction s'arrête là.
Cependant, les LLM sont capables de faire davantage : ils sont intégrés dans des systèmes qui peuvent planifier, mémoriser et agir de manière autonome, donnant ainsi naissance à ce que l'on appelle les agents LLM. Les systèmes agentics sont de plus en plus utilisés dans les analyses modernes et les flux de travail commerciaux.
À la fin de cet article, vous comprendrez ce que sont les agents LLM, comment ils sont conçus, les différents types d'agents et où ils peuvent créer de la valeur.
Pour tirer le meilleur parti des informations contenues dans cet article, veuillez le consulter en parallèle avec l'article parcours de compétences « Principes fondamentaux de l'IA » cursus pour rafraîchir vos connaissances sur l'IA et les LLM.
Examinons en quoi les agents LLM diffèrent des modèles linguistiques standard.
Votre interface LLM habituelle, telle qu'un chatbot, ne peut que recevoir des invites et renvoyer des réponses générées en fonction de son apprentissage, sans actions ni état externes. Un agent LLM, en revanche, utilise un LLM comme moteur de raisonnement central (à l'instar d'un cerveau) et l'entoure de composants de soutien qui lui permettent de raisonner, de planifier et d'exécuter.
Les agents LLM déplacent l'accent mis sur l'automatisation vers l'autonomie.
L'automatisation permet aux LLM de recevoir des entrées et de suivre une série d'étapes pour générer une sortie. Grâce à l'autonomie, nous fournissons au LLM un ensemble d'outils et la capacité de déterminer la meilleure façon de parvenir à une solution en fonction de sa connaissance de la situation. Cela confère davantage de flexibilité et de complexité au LLM pour agir de manière « indépendante ».
Considérez un LLM simple comme un consultant expert qui répond aux questions en se basant sur ses connaissances. Un agent LLM est comparable à un expert dirigeant une équipe : il détermine les questions à poser, les membres de l'équipe (outils) à consulter et la manière de combiner leurs réponses pour aboutir à une solution.
Un agent LLM se compose de plusieurs éléments principaux :
Le graphique suivant illustre la relation entre chacun d'entre eux.
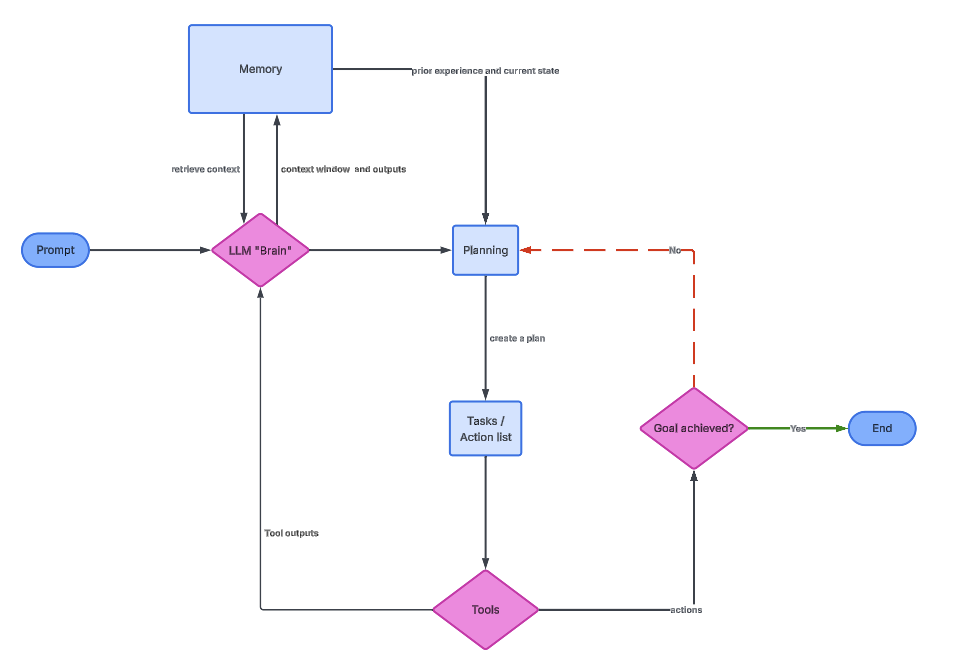
Le LLM constitue le noyau cognitif de l'agent. Il interprète l'objectif de l'utilisateur, réfléchit aux étapes intermédiaires et détermine les actions à entreprendre. En pratique, le LLM est invoqué à plusieurs reprises, et non pas une seule fois.
À chaque fois que le LLM est appelé, il reçoit un contexte pouvant inclure l'objectif initial, les actions précédentes, les résultats des outils et la mémoire pertinente. Sur la base de ces informations, il détermine la prochaine action à entreprendre. Cela rend la fonction LLM plus proche d'un contrôleur que d'un générateur de texte statique.
Pour les professionnels des données, il est essentiel de comprendre que le LLM n'exécute pas directement de code ou de requêtes. Il génère des instructions structurées que d'autres composants interprètent. La qualité d'un agent dépend souvent de la manière dont ces instructions sont définies et validées.
La logique de planification est le mécanisme qui permet aux agents de résoudre des problèmes complexes en les décomposant en étapes gérables. Sans planification, un agent tenterait de tout résoudre en une seule réponse, ce qui conduit souvent à des erreurs ou à des hallucinations.
Au cours d'une phase de planification, l'agent décompose un objectif de haut niveau en tâches plus petites. Par exemple, « analyser le taux de désabonnement des clients » pourrait se décomposer en « charger les données clients », « calculer le taux de désabonnement », « identifier les tendances » et « résumer les conclusions ». Chaque sous-tâche est ensuite exécutée de manière séquentielle ou conditionnelle.
Une technique courante est la chaîne de pensée (CoT), qui encourage le modèle à raisonner de manière explicite en enchaînant une série d'actions sous forme d'invites séquentielles.
ReAct (raisonnement et action) va encore plus loin et entremêle les traces de raisonnement avec les actions déclenchées par des outils et les observations externes. Ces commentaires externes aident les agents à rester concentrés et à se corriger lorsque les résultats intermédiaires ne correspondent pas aux attentes.
La mémoire permet à un agent de maintenir une continuité entre les interactions et les actions en réutilisant des informations antérieures. Sans mémoire, chaque étape serait isolée, obligeant l'agent à redécouvrir les mêmes connaissances à maintes reprises.
La mémoire à court terme est généralement présente dans la fenêtre contextuelle du LLM. Il comprend les messages récents, le raisonnement intermédiaire et les résultats des outils. Tout comme la mémoire vive (RAM) dans l'architecture informatique, cette mémoire est rapide mais limitée et disparaît une fois le contexte dépassé.
La mémoire à long terme est mise en œuvre en externe, souvent à l'aide de bases de données vectorielles. Des techniques telles que RAG (Retrieval-Augmented Generation) permettent à l'agent de récupérer des documents pertinents ou des interactions passées et de les intégrer dans le contexte actuel.
Les outils élargissent les capacités d'un agent au-delà de la langue. Ils permettent à l'agent d'interagir avec le monde réel, notamment les bases de données, les API et les moteurs de calcul.
Du point de vue de l'agent, les outils sont des fonctions appelables avec des entrées et des sorties définies. Le LLM détermine quand utiliser un outil, quels arguments fournir et comment interpréter le résultat. Ce processus décisionnel est ce qui distingue les agents des flux de travail scriptés.
Les outils peuvent inclure des fonctionnalités telles que les recherches Google, l'exécution SQL, les interpréteurs Python et les API. L'agent a effectivement accès aux mêmes outils technologiques que nous et peut les combiner pour mettre en œuvre des solutions.
L'image ci-dessus représente l'architecture générale d'un agent LLM. Le cerveau fournit des informations relatives à la mémoire et à la planification, qui déclenchent ensuite une série de tâches à l'aide d'outils.
Cette section résume les différentes catégories d'agents, des agents réflexifs les plus basiques aux agents d'apprentissage complexes.

Les agents réflexes simples fonctionnent selon des règles condition-action directes. Ils ne prennent pas en compte l'histoire, les conséquences futures ou les actions alternatives. Si une condition est remplie, l'action correspondante est exécutée immédiatement.
Cette simplicité les rend faciles à mettre en œuvre, mais ils sont extrêmement fragiles. Toute entrée inattendue ou tout signal manquant peut entraîner un comportement incorrect. Ils ne peuvent pas non plus s'adapter à des environnements changeants.
L'exemple du bot de désabonnement aux e-mails illustre cette limitation. Il accomplit sa tâche rapidement, mais manque de discernement, ce qui peut entraîner des résultats indésirables.
Les agents réflexifs basés sur des modèles améliorent les agents réflexifs simples en conservant une représentation interne de l'environnement. Ce modèle interne leur permet de raisonner sur des éléments qui ne sont pas immédiatement visibles.
En suivant un état au fil du temps, ces agents peuvent gérer l'observabilité partielle. Ils se souviennent de ce qui s'est déjà produit et utilisent ces informations pour orienter leurs actions futures.
Les assistants IDE tels que Copilot ou Cursor AI en sont de bons exemples. Ils conservent en mémoire les fichiers, les variables et les fonctions tout au long d'une session, ce qui leur permet de proposer des suggestions plus pertinentes qu'une simple correspondance de modèles. Ils comblent également le fossé avec la catégorie suivante d'agents.
Les agents basés sur les objectifs sont conçus en fonction des résultats plutôt que des déclencheurs. Ils planifient et évaluent les actions en fonction de leur capacité à rapprocher le système de l'objectif souhaité, plutôt que d'adopter une approche purement réactive.
Ces agents génèrent des plans pouvant impliquer plusieurs étapes et des branchements conditionnels. Si une approche échoue, ils peuvent envisager une autre solution. Cela les rend nettement plus flexibles que les agents basés sur les réflexes.
Par exemple, la création d'un itinéraire de voyage démontre comment un objectif général unique peut être décomposé en plusieurs actions coordonnées entre différents systèmes.
L'agent ne se contente pas de répondre à une simple demande « donnez-moi un itinéraire » et de restituer des informations. Au lieu de cela, il pourrait décomposer l'objectif en plusieurs sous-problèmes, tels que :
L'objectif de générer un itinéraire est alors atteint en combinant les solutions de chacun de ces problèmes.
Les agents basés sur l'utilité étendent les agents basés sur les objectifs en introduisant l'optimisation. Plutôt que de simplement atteindre un objectif, ils évaluent différents résultats à l'aide d'une « fonction d'utilité ».
Une fonction utilitaire attribue des notes aux résultats en fonction de critères tels que le coût, le temps, le risque ou les préférences de l'utilisateur. L'agent sélectionne ensuite la séquence d'actions qui maximise l'utilité globale.
Cette approche est couramment utilisée dans les systèmes de recommandation et les problèmes d'optimisation. Il peut s'agir, par exemple, de trouver le meilleur itinéraire pour se rendre à un endroit, de recommander les produits adaptés ou même de proposer la meilleure analyse à présenter à un utilisateur particulier.
Les agents d'apprentissage sont conçus pour améliorer leur comportement au fil du temps sans reprogrammation explicite.
À chaque itération, un agent reçoit un retour d'information et utilise ces informations pour améliorer ses performances. Ils fonctionnent dans des environnements où le comportement optimal n'est pas connu à l'avance et ne nécessitent pas de reprogrammation explicite pour chaque nouvelle situation.
Il existe deux composantes principales : un « critique » et un « élément d'apprentissage ». Le « critique » évalue les résultats et fournit des commentaires. L'« élément d'apprentissage » utilise ces commentaires pour ajuster les décisions futures. Au fil du temps, l'agent s'adapte davantage aux préférences de l'utilisateur ou aux contraintes environnementales.
Par exemple, envisagez un agent LLM qui résume les actualités quotidiennes pour vous. Il pourrait observer votre comportement et s'adapter à vos préférences. Si l'agent remarque que vous consultez rarement les résumés « Sports », mais que vous vous intéressez à « Gastronomie et boissons », il pourrait cesser de vous fournir des résumés sportifs et se concentrer plutôt sur votre intérêt pour des cuisines ou des restaurants particuliers.
Le tableau suivant résume les différencesentre les types d'agents LLM.
|
Agent |
Idée principale |
Mémoire |
Planification |
Apprentissage |
Complexité |
Exemple |
|
Agent réflexe simple |
Associe directement une condition à une action. |
Non |
Aucun |
Non |
Très faible |
Archiver automatiquement les e-mails contenant le terme « se désabonner » |
|
Agent réflexif basé sur un modèle |
Gère un modèle interne de l'environnement |
Oui (suivi de l'état) |
Minimal |
Non |
Faible |
Assistant IDE mémorisant les variables ou les fichiers définis précédemment au cours d'une session |
|
Agent basé sur les objectifs |
Prend des mesures pour atteindre un objectif précis |
Oui |
Oui |
Non |
Moyen |
Réserver des vols, des hôtels et des moyens de transport pour un voyage d'affaires |
|
Agent basé sur l'utilité |
Sélectionne le résultat le plus approprié en fonction des préférences. |
Oui |
Oui |
Non |
Moyen à élevé |
Agent de voyage optimisant le rapport coût/durée/confort |
|
Agent d'apprentissage |
Améliore le comportement en fonction des commentaires reçus au fil du temps |
Oui |
Oui |
Oui |
Élevé |
Agent d'actualités qui adapte le contenu en fonction des modèles d'engagement des utilisateurs. |
Cette section présente les cadres courants utilisés pour développer des systèmes d'agents LLM.
LangChain fournit un cadre modulaire pour la construction de systèmes alimentés par LLM. Son principe fondamental est que des flux de travail complexes peuvent être construits en assemblant des composants simples. Il relève le défi de communiquer avec différents modèles de langage (LLM) et résume ce processus pour l'utilisateur à l'aide d'objets Python.
Le concept clé de LangChain est celui de « chaînes », qui relient les invites, les modèles et les analyseurs syntaxiques dans des flux de travail reproductibles. Par exemple, l'idée est que vous prenez un PromptTemplate, qui est transmis au LLM et traité par un OutputParser.
LCEL (LangChain Expression Language) fournit une syntaxe déclarative qui permet aux utilisateurs d'utiliser des pipes (|) pour composer visuellement des chaînes. Ainsi, au lieu des workflows Python classiques qui exigent que vous alimentiez explicitement votre modèle en invites, vous pouvez simplement écrire chain = prompt | model et laisser LangChain gérer la création des modèles.
Pour des fonctionnalités plus complexes, LangChain permet aux utilisateurs d'ajouter des outils tels que Wikipédia, Python REPLet Google Search à leurs agents.
LangGraph s'appuie sur les fonctionnalités de LangChain et combine ces concepts avec la mémoire pour prendre en charge des architectures d'agents avec état, de qualité production, avec un contrôle explicite sur le flux d'exécution.
Au-delà de LangGraph, l'écosystème de LangChain s'est encore développé pour inclure des moyens d'observer plus facilement les agents (LangSmith) et même des interfaces glisser-déposer (LangFlow).
LlamaIndex excelle dans les flux de travail centrés sur les documents en fournissant une reconnaissance optique de caractères (OCR) et une analyse syntaxique de haute précision pour plus de 90 types de fichiers non structurés, combinées en option à des flux de travail agentés pour une récupération et une extraction intelligentes.
Ses connecteurs de données facilitent l'ingestion à partir de nombreuses sources, tandis que ses structures d'indexation optimisent la récupération. Le VectorStoreIndex est le choix le plus courant pour la recherche sémantique.
Les moteurs de requête coordonnent la récupération et la génération, tandis que les routeurs introduisent une prise de décision de type agent en sélectionnant la source de données la plus appropriée pour une requête donnée.
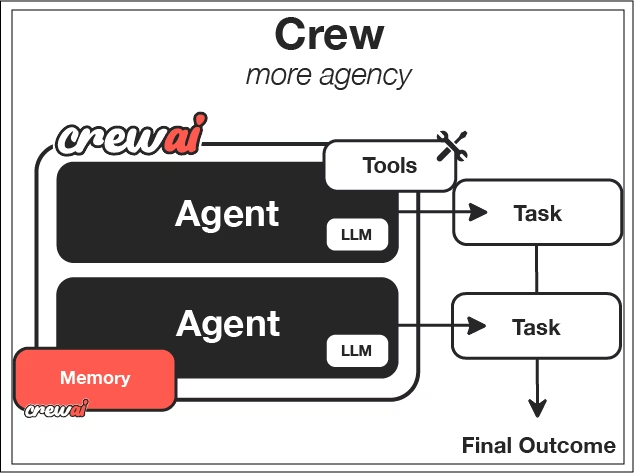
CrewAI est conçu pour favoriser la collaboration. Au lieu d'un seul agent, cela permet à plusieurs agents ayant des rôles distincts de collaborer.
Il se concentre sur le concept de « Crews », qui sont un ensemble défini d'agents. Chaque agent se voit attribuer une personnalité, un objectif et une histoire, qui déterminent son comportement.
Les tâches définissent ce qui doit être accompli et ce à quoi ressemble le succès. Vous définissez la nature d'une tâche individuelle, fournissez certains paramètres, le résultat attendu et les agents qui devraient travailler sur cette tâche.
Les processus déterminent la manière dont les tâches sont exécutées : de manière séquentielle, hiérarchique ou selon des modèles orchestrateur-travailleur, dans lesquels un agent principal décompose dynamiquement des tâches complexes, imitant ainsi le fonctionnement des équipes humaines.
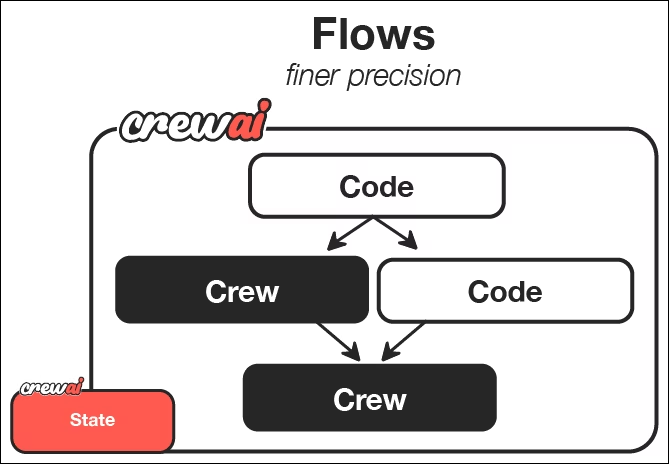
Extrait de la documentation CrewAI, nous pouvons constater que les flux offrent un moyen d'orchestrer et de déclencher les équipes. Chaque équipe utilise des agents LLM avec des rôles et des tâches définis pour effectuer un travail spécifique et obtenir les résultats souhaités.
Le choix d'un cadre dépend de votre domaine d'activité et de vos contraintes. Chacun des cadres présentés possède ses propres atouts :
Veuillez prendre en considération la complexité de vos données, le niveau d'autonomie requis et les contraintes opérationnelles. Il n'existe pas de choix universellement correct.
Pour vous aider dans votre prise de décision, vous pouvez également consulter nos articles comparant LangChain à Llamaindex, respectivement, CrewAI et LangGraph.
Les cas d'utilisation des agents LLM sont pratiquement illimités et ne sont restreints que par votre imagination.
Les assistants de codage modernes utilisent des flux de travail agencés pour planifier, exécuter et vérifier les modifications. Ils peuvent examiner le code source, générer des solutions, exécuter des tests et corriger les erreurs de manière itérative.
Par exemple, Cursor s'intègre de manière native à votre IDE et vous aide à compléter des lignes ou à corriger des modifications apportées aux pipelines ayant des implications en aval. Claude Code peut vous aider à rédiger des tests, à créer des scripts complets ou à évaluer les incohérences dans votre code à travers un dépôt. Nous pouvons utiliser GitHub Copilot pour faciliter la rédaction des pull requests et le test du code dans le cadre d'un workflow de requête.
Cela modifie le rôle du développeur, qui passe de la rédaction de chaque ligne de code à la supervision et à l'orientation de systèmes intelligents. Pour les professionnels des données, cela peut considérablement accélérer l'expérimentation et le prototypage.
Je vous recommande de suivre le cours cours « Développement logiciel avec GitHub Copilot » si vous souhaitez vous initier aux assistants de codage basés sur le LLM.
Les systèmes BI agentiels permettent aux utilisateurs de poser des questions en langage naturel et d'obtenir des informations exploitables. L'agent est capable de traduire les questions en SQL, d'exécuter des requêtes et d'expliquer les résultats.
Vous pouvez interagir avec vos données comme vous le feriez avec un membre senior de l'équipe et obtenir de nouvelles informations et visualisations en temps réel. Cela réduit la dépendance vis-à-vis des tableaux de bord et permet aux membres non techniques de l'équipe de réaliser des analyses exploratoires.
Les agents de recherche automatisent la collecte et la synthèse d'informations. Ils effectuent des recherches sur le Web, récupèrent des sources et résument leurs conclusions ; certains systèmes intègrent des filtres de base pour évaluer la qualité des sources. Ils peuvent également consulter la documentation interne hébergée sur des sites web tels que Notion ou les messages dans Slack.
Grâce à l'accès à toutes ces sources d'information, les agents LLM peuvent non seulement synthétiser rapidement les informations, mais également générer des documents complets et des résumés afin que les équipes puissent partager rapidement les informations.
Cela est particulièrement utile dans les domaines en constante évolution où les ensembles de données statiques deviennent rapidement obsolètes. Les agents fournissent des informations actualisées en permanence.
Pour découvrir d'autres idées sur la manière dont les gens utilisent les agents IA, veuillez consulter notre guide sur les 10 meilleurs projets d'agents IA.
Bien que les flux de travail agentic soient remarquables et extrêmement puissants, ils présentent également leurs propres défis. Les agents peuvent percevoir des étapes de manière erronée, interpréter incorrectement les résultats des outils ou entrer dans des boucles longues ou non souhaitées. Les garde-fous, la validation et l'observabilité sont essentiels pour les systèmes de production.
Chaque action de l'agent nécessite souvent un appel LLM. Les tâches complexes peuvent nécessiter des dizaines d'appels, ce qui augmente la latence et les coûts liés aux API. De plus, il est possible que vous deviez payer pour des infrastructures supplémentaires telles que le stockage dans le cloud, le cloud computing et d'autres coûts liés à l'agent LLM.
Les systèmes autonomes sont plus difficiles à déboguer que le code déterministe. Pour comprendre pourquoi un agent a pris une décision, il est nécessaire de retracer les étapes de l'état, de la mémoire et du raisonnement.
Selon le cadre d'agent que vous utilisez, cela peut s'avérer particulièrement difficile. Certains frameworks, tels que CrewAI, offrent une abstraction beaucoup plus poussée en raison de leur complexité supplémentaire par rapport à un framework plus simple comme LangChain, qui vise principalement à simplifier l'accès à vos LLM.
Nous sommes en train de passer de chatbots isolés à des flux de travail entièrement autonomes, capables de raisonner, de planifier et d'agir. Bien qu'il soit encore récent, ce paradigme est déjà en train de transformer la manière dont les systèmes de données sont conçus et utilisés.
Pour les futurs professionnels des données, acquérir dès aujourd'hui des connaissances sur les agents LLM constitue un avantage certain pour les postes de demain. Ces systèmes représentent l'avenir de l'automatisation intelligente.
Commencez à vous exercer et à créer ces agents LLM avec notre cours « Concevoir des systèmes agents avec LangChain » !
Cours pour agents LLM
Cursus
Cours
Cours