
Track
AI Agent Fundamentals
6 hr
For many people, large language models (LLMs) are primarily used as conversational interfaces. You ask a question, the model answers, and that’s where the interaction ends.
However, LLMs are capable of doing more: they are being embedded into systems that can plan, remember, and take actions autonomously, unlocking what’s known as LLM agents. Agentic systems are becoming more popular in modern analytics and business workflows.
By the end of this article, you will understand what LLM agents are, how they are built, the different types of agents, and where they can create value.
To make the most of the information in this article, pair it with the AI Fundamentals skill track to refresh your knowledge on AI and LLMs.
Let's talk about how LLM agents differ from standard language models.
Your usual LLM interface, like a chatbot, can only take in prompts and return generated responses based on its training, without external actions or state. An LLM agent, by contrast, uses an LLM as its core reasoning engine (like a brain) and surrounds it with supporting components that allow it to reason, plan, and execute.
LLM agents shift the focus from automation to autonomy.
Automation enables LLMs to take inputs and follow a series of steps to generate an output. With autonomy, we are handing the LLM a set of tools and the ability to decide how best to come to a solution based on what it knows about the situation. This gives more flexibility and complexity for the LLM to act “independently”.
Think of a plain LLM as an expert consultant who answers questions based on their knowledge. An LLM agent is like that expert leading a team: it decides what questions to ask, which team members (tools) to consult, and how to combine their answers into a solution.
An LLM agent consists of several core components:
The following graph visualizes the relation between each of them.
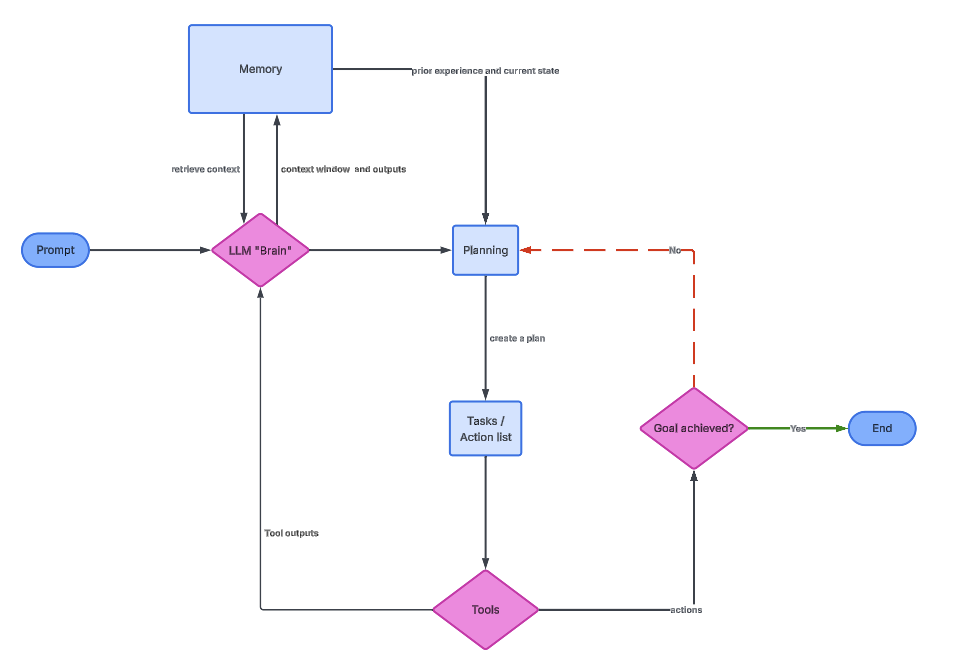
The LLM serves as the cognitive core of the agent. It interprets the user’s goal, reasons about intermediate steps, and decides which actions to take. In practice, the LLM is invoked repeatedly, not just once.
Each time the LLM is called, it receives context that may include the original goal, prior actions, tool outputs, and relevant memory. Based on this information, it decides on the next action. This makes the LLM function more like a controller than a static text generator.
For data practitioners, it is important to understand that the LLM does not directly execute code or queries. It generates structured instructions that other components interpret. The quality of an agent often depends on how well these instructions are constrained and validated.
The planning logic is the mechanism that allows agents to solve complex problems by breaking them down into manageable steps. Without planning, an agent would attempt to solve everything in a single response, which often leads to errors or hallucinations.
In a planning phase, the agent decomposes a high-level objective into smaller tasks. For example, “Analyze customer churn” might become “load customer data,” “calculate churn rate,” “identify trends,” and “summarize findings.” Each sub-task is then executed sequentially or conditionally.
One popular technique is Chain-of-Thought (CoT), which encourages the model to reason explicitly by chaining together a series of actions as sequential prompts.
ReAct (reasoning and acting) takes it even a step further and interleaves reasoning traces with tool-invoked actions and external observations. This external feedback helps agents remain grounded and correct themselves when intermediate results do not match expectations.
Memory allows an agent to maintain continuity across interactions and actions by reusing prior information. Without memory, every step would be isolated, forcing the agent to rediscover the same knowledge over and over again.
Short-term memory typically exists within the LLM’s context window. It includes recent messages, intermediate reasoning, and tool outputs. Much like RAM in computer architecture, this memory is fast but limited and disappears once the context is exceeded.
Long-term memory is implemented externally, often using vector databases. Techniques like RAG (Retrieval-Augmented Generation) allow the agent to retrieve relevant documents or past interactions and inject them into the current context.
Tools extend an agent’s capabilities beyond language. They allow the agent to interact with the real world, including databases, APIs, and computation engines.
From the agent’s perspective, tools are callable functions with defined inputs and outputs. The LLM decides when to use a tool, what arguments to provide, and how to interpret the result. This decision-making is what differentiates agents from scripted workflows.
Tools can include features such as Google searches, SQL execution, Python interpreters, and APIs. The agent effectively has access to the same technological tools we do and can bring them together to execute solutions.
The image above depicts the general LLM agent architecture. The Brain provides memory and planning information, which then initiates a series of tasks using tools.
This section summarizes the different categories of agents from the most basic reflex agents to complex learning agents.

Simple reflex agents operate on direct condition-action rules. They do not consider history, future consequences, or alternative actions. If a condition is met, the corresponding action is executed immediately.
This simplicity makes them easy to implement, but they are extremely fragile. Any unexpected input or missing signal can cause incorrect behavior. They also cannot adapt to changing environments.
The email unsubscribe bot example highlights this limitation. It performs its task quickly but lacks awareness, which can lead to undesirable outcomes.
Model-based reflex agents improve on simple reflex agents by maintaining an internal representation of the environment. This internal model allows them to reason about things that are not immediately visible.
By tracking a state over time, these agents can handle partial observability. They remember what has already happened and use that information to inform future actions.
IDE assistants like Copilot or Cursor AI are strong examples. They maintain awareness of files, variables, and functions across a session, enabling more intelligent suggestions than simple pattern matching. They also bridge the gap to the next category of agents.
Goal-based agents are designed around outcomes rather than triggers. They plan and evaluate actions based on whether they move the system closer to a desired objective instead of being purely reactive.
These agents generate plans that may involve multiple steps and conditional branching. If one approach fails, they can attempt an alternative path. This makes them significantly more flexible than reflex-based agents.
For example, creating a travel itinerary demonstrates how a single high-level goal can be decomposed into multiple coordinated actions across systems.
The agent is not just responding to a simple prompt of “give me an itinerary” and regurgitating information. Instead, it might break down the goal into small sub-problems, such as:
The goal of generating an itinerary is then achieved by combining the solutions of each of those problems.
Utility-based agents extend goal-based agents by introducing optimization. Rather than simply reaching a goal, they evaluate different outcomes by using a “utility function”.
A utility function assigns scores to outcomes based on criteria such as cost, time, risk, or user preference. The agent then selects the action sequence that maximizes overall utility.
This approach is common in recommendation systems and optimization problems. It could be things like finding the best route to a location, recommending the right products, or even coming up with the best analysis to show a particular user.
Learning agents are designed to improve their behavior over time without explicit reprogramming.
With each iteration, an agent gets feedback and uses that information to improve its performance. They operate in environments where optimal behavior is not known in advance and do not require explicit reprogramming for each new situation.
There are two main components: a “Critic” and a “Learning Element”. The "Critic" evaluates outcomes and provides feedback. The “Learning Element” uses this feedback to adjust future decisions. Over time, the agent becomes more aligned with user preferences or environmental constraints.
For example, imagine an LLM agent that summarizes the daily news for you. It might observe your behavior and adapt to your preferences. If the agent notices you rarely open “Sports” summaries, but have an interest in “Food and Drink”, it may stop providing sports summaries and instead focus on your interest in particular cuisines or restaurants.
The following table summarizes the differences between the types of LLM agents.
|
Agent |
Core Idea |
Memory |
Planning |
Learning |
Complexity |
Example |
|
Simple Reflex Agent |
Directly maps a condition to an action |
No |
None |
No |
Very Low |
Automatically archiving emails that contain the word “unsubscribe” |
|
Model-Based Reflex Agent |
Maintains an internal model of the environment |
Yes (state tracking) |
Minimal |
No |
Low |
IDE assistant remembering variables or files defined earlier in a session |
|
Goal-Based Agent |
Takes actions to reach a specific objective |
Yes |
Yes |
No |
Medium |
Booking flights, hotels, and transport for a business trip |
|
Utility-Based Agent |
Chooses the best outcome based on preferences |
Yes |
Yes |
No |
Medium to High |
Travel agent optimizing cost vs duration vs comfort |
|
Learning Agent |
Improves behavior based on feedback over time |
Yes |
Yes |
Yes |
High |
News agent that adapts content based on user engagement patterns |
This section introduces common frameworks used to build LLM agent systems.
LangChain provides a modular framework for building LLM-powered systems. Its core idea is that complex workflows can be constructed by composing simple components. It takes the challenge of communicating with different LLMs and abstracts that process for the user through Python objects.
The key concept in LangChain is its concept of “Chains,” which link prompts, models, and parsers into repeatable workflows. For instance, the idea is that you take a PromptTemplate, which is fed to the LLM and processed by an OutputParser.
LCEL (LangChain Expression Language) provides a declarative syntax that allows users to use pipes (|) to visually compose chains. So instead of classic Python workflows that require you to explicitly feed prompts into your model, you can simply write chain = prompt | model and let LangChain handle the templating.
For more complex functionality, LangChain allows users to add tools like Wikipedia, Python REPLs, and Google Search to their agents
LangGraph builds on LangChain’s functionality and combines these concepts with memory to support stateful, production-grade agent architectures with explicit control over execution flow.
Beyond LangGraph, LangChain’s ecosystem has further grown to include ways to observe agents more easily (LangSmith) and even drag-and-drop interfaces (LangFlow).
LlamaIndex excels in document-centric workflows by providing high-accuracy OCR and parsing for 90+ unstructured file types, optionally combined with agentic workflows for intelligent retrieval and extraction.
Its data connectors simplify ingestion from many sources, while its indexing structures optimize retrieval. The VectorStoreIndex is the most common choice for semantic search.
Query engines orchestrate retrieval and generation, while routers introduce agent-like decision-making by selecting the most appropriate data source for a given query.
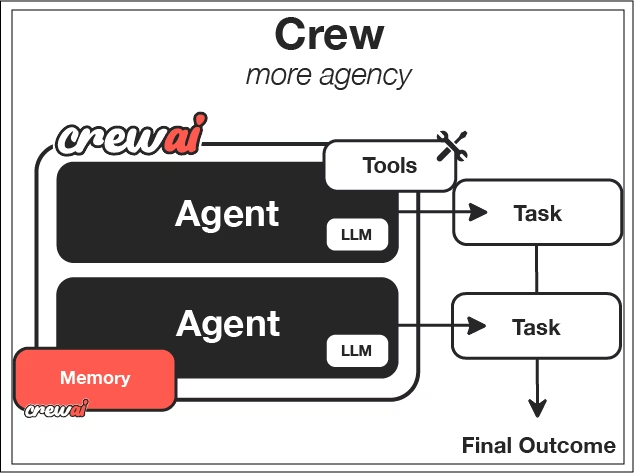
CrewAI is designed around collaboration. Instead of a single agent, it enables multiple agents with distinct roles to work together.
It focuses on the idea of “Crews,” which are a defined set of agents. Each agent is assigned a persona, goal, and backstory, which shapes its behavior.
Tasks define what needs to be done and what success looks like. You define what an individual task looks like, provide some parameters, the expected output, and which agents should work on that task.
Processes determine how tasks are executed: sequentially, hierarchically, or through orchestrator-worker patterns where a primary agent dynamically decomposes complex tasks, mimicking human teams.
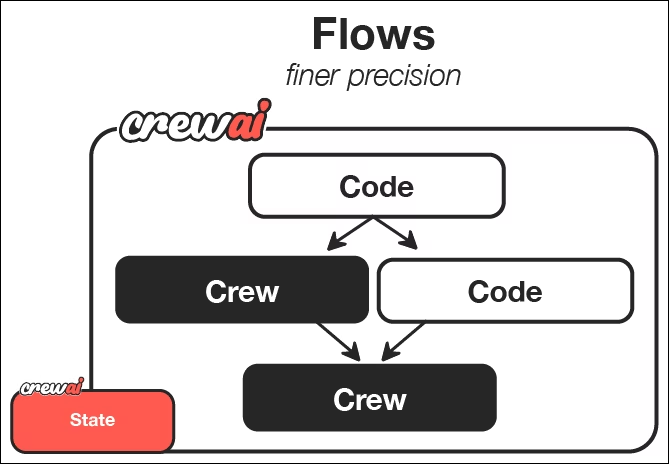
From the CrewAI documentation, we can see that flows provide a way to orchestrate and trigger crews. Each crew uses LLM agents with defined roles and tasks to perform specific work and create desired outcomes.
Choosing a framework depends on your problem domain and constraints. Each of the presented frameworks has their own strengths:
Consider your data complexity, required level of autonomy, and operational constraints. There is no universally correct choice.
To support your decision-making, you can also consult our articles comparing LangChain to Llamaindex, respectively, CrewAI to LangGraph.
The use cases for LLM agents are basically endless and only limited by your imagination.
Modern coding assistants use agentic workflows to plan, execute, and verify changes. They can explore a codebase, generate solutions, run tests, and fix errors iteratively.
For instance, Cursor integrates into your IDE natively and helps you complete lines or fix changes to pipelines with downstream implications. Claude Code can help you write tests, create entire scripts, or assess inconsistencies in your code across a repo. We can use GitHub Copilot to help with writing pull requests and testing code as part of a request workflow.
This shifts the developer role from writing every line to supervising and guiding intelligent systems. For data practitioners, this can dramatically speed up experimentation and prototyping.
I recommend you take the Software Development with GitHub Copilot course if you want to get started with LLM-powered coding assistants.
Agentic BI systems allow users to ask questions in natural language and receive actionable insights. The agent can translate questions into SQL, execute queries, and explain results.
You can talk to your data like you would talk to a senior member of the team and get new insights and visualizations in real time. This reduces dependency on dashboards and enables exploratory analysis for non-technical team members.
Research agents automate information gathering and synthesis. They search the web, retrieve sources, and summarize findings; some systems include basic source-quality filters. They can even look at internal documentation hosted on websites like Notion or messages within Slack.
With access to all these information sources, LLM agents can not only quickly synthesize information but also generate entire documents and summary documents for teams to quickly share information.
This is especially valuable in fast-moving domains where static datasets quickly become outdated. Agents provide continuously refreshed insights.
For more ideas on how folks are using AI Agents, look at our guide about the Top 10 AI Agent Projects.
While agentic workflows are amazing and extremely powerful, they do come with their own challenges. Agents can hallucinate steps, misinterpret tool outputs, or enter long or unintended loops. Guardrails, validation, and observability are critical for production systems.
Each agent action often requires an LLM call. Complex tasks may involve dozens of calls, increasing latency and API costs. Plus, you may be paying for additional infrastructure like cloud storage, cloud computing, and other costs to support the LLM agent.
Autonomous systems are harder to debug than deterministic code. Understanding why an agent made a decision requires tracing state, memory, and reasoning steps.
Depending on which agent framework you use, this can be exceptionally challenging. Some frameworks, like CrewAI, abstract far more deeply due to their additional complexity over a more straightforward framework like LangChain, whose focus is on simplifying accessing your LLMs.
We are transitioning from isolated chatbots to fully agentic workflows that can reason, plan, and act. While still early, this paradigm is already reshaping how data systems are built and used.
For aspiring data practitioners, learning about LLM agents today provides a strong advantage for tomorrow’s roles. These systems represent the future of intelligent automation.
Start practicing and building these LLM agents with our Designing Agentic Systems with LangChain course!
LLM Agent Courses
Track
Course
Course
blog
Javier Canales Luna
12 min
blog
Tim Lu
15 min
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev

