
Lernpfad
KI-Agent-Grundlagen
6 Std.
Für viele Leute sind große Sprachmodelle (LLMs) vor allem als Gesprächsschnittstellen genutzt. Du stellst eine Frage, das Modell antwortet, und damit ist die Interaktion schon vorbei.
LLMs können aber noch mehr: Sie werden in Systeme eingebaut, die selbstständig planen, sich Dinge merken und handeln können, wodurch sogenannte LLM-Agenten entstehen. Agentische Systeme werden in der modernen Analytik und in Geschäftsabläufen immer beliebter.
Am Ende dieses Artikels wirst du wissen, was LLM-Agenten sind, wie sie funktionieren, welche verschiedenen Arten es gibt und wo sie nützlich sein können.
Um das Beste aus den Infos in diesem Artikel rauszuholen, schau dir auch die AI Fundamentals Lernpfad für KI und LLMs, um dein Wissen aufzufrischen.
Reden wir mal darüber, wie sich LLM-Agenten von normalen Sprachmodellen unterscheiden.
Deine normale LLM-Schnittstelle, wie ein Chatbot, kann nur Eingaben nehmen und generierte Antworten basierend auf ihrem Training zurückgeben, ohne externe Aktionen oder Zustände. Ein LLM-Agent hingegen nutzt ein LLM als seine zentrale Entscheidungsmaschine (wie ein Gehirn) und hat drumherum Komponenten, die ihm helfen, zu denken, zu planen und zu handeln.
LLM-Agenten verlagern den Fokus von der Automatisierung auf die Autonomie.
Durch Automatisierung können LLMs Eingaben nehmen und dann eine Reihe von Schritten machen, um eine Ausgabe zu erzeugen. Mit Autonomie geben wir dem LLM eine Reihe von Tools und die Möglichkeit, selbst zu entscheiden, wie man am besten zu einer Lösung kommt, basierend auf dem, was er über die Situation weiß. Das gibt dem LLM mehr Flexibilität und Komplexität, um „unabhängig“ zu agieren.
Stell dir einen einfachen LLM wie einen Expertenberater vor, der Fragen mit seinem Wissen beantwortet. Ein LLM-Agent ist wie dieser Experte, der ein Team leitet: Er entscheidet, welche Fragen gestellt werden, welche Teammitglieder (Tools) konsultiert werden und wie ihre Antworten zu einer Lösung zusammengefügt werden.
Ein LLM-Agent hat ein paar Hauptteile:
Die folgende Grafik zeigt, wie die einzelnen Faktoren zusammenhängen.
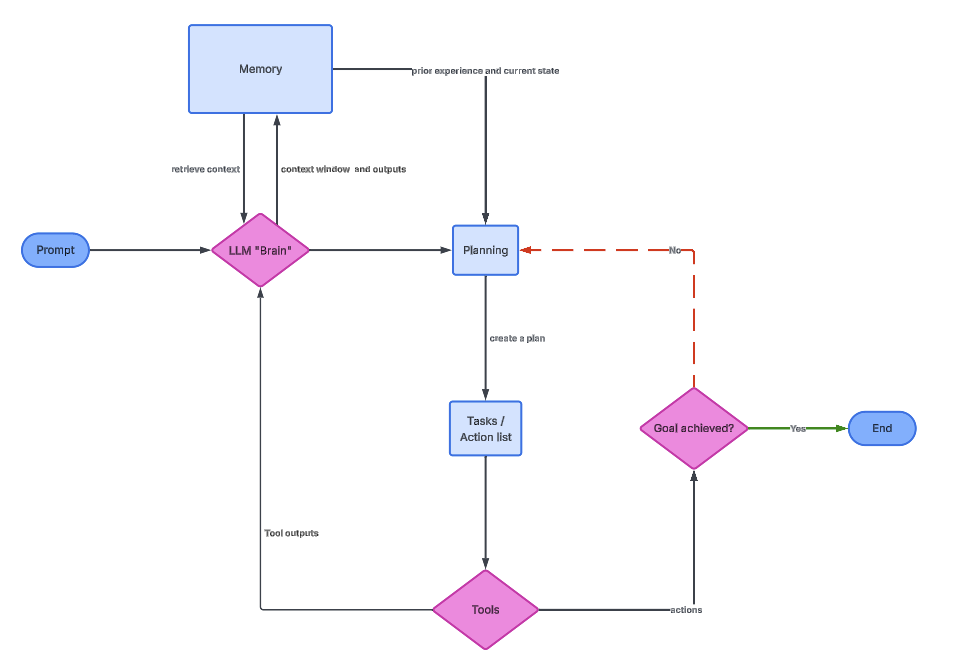
Der LLM ist der kognitive Kern des Agenten. Es versteht, was der Nutzer will, überlegt sich Zwischenschritte und entscheidet, was zu tun ist. In der Praxis wird das LLM öfter aufgerufen, nicht nur einmal.
Jedes Mal, wenn das LLM aufgerufen wird, kriegt es Infos, die das ursprüngliche Ziel, vorherige Aktionen, Tool-Ausgaben und relevante Erinnerungen beinhalten können. Aufgrund dieser Infos entscheidet es, was als Nächstes passiert. Dadurch funktioniert LLM eher wie ein Controller als wie ein statischer Textgenerator.
Für Leute, die mit Daten arbeiten, ist es wichtig zu wissen, dass das LLM keinen Code oder Abfragen direkt ausführt. Es macht strukturierte Anweisungen, die andere Teile verstehen. Die Qualität eines Agenten hängt oft davon ab, wie gut diese Anweisungen festgelegt und überprüft werden.
Die Planungslogik ist der Mechanismus, der es Agenten ermöglicht, komplexe Probleme zu lösen, indem sie diese in überschaubare Schritte zerlegen. Ohne Planung würde ein Agent versuchen, alles in einer einzigen Antwort zu klären, was oft zu Fehlern oder Wahnvorstellungen.
In der Planungsphase teilt der Agent ein großes Ziel in kleinere Aufgaben auf. Zum Beispiel könnte „Kundenabwanderung analysieren“ in „Kundendaten laden“, „Abwanderungsrate berechnen“, „Trends erkennen“ und „Ergebnisse zusammenfassen“ aufgeteilt werden. Jede Teilaufgabe wird dann entweder nacheinander oder abhängig von Bedingungen erledigt.
Eine beliebte Technik ist Chain-of-Thought (CoT), die das Modell dazu bringt, explizit zu denken, indem sie eine Reihe von Aktionen als aufeinanderfolgende Eingabeaufforderungen miteinander verknüpft.
ReAct (Reasoning and Acting) geht noch einen Schritt weiter und verknüpft Argumentationsspuren mit durch Tools ausgelösten Aktionen und externen Beobachtungen. Dieses Feedback von außen hilft den Mitarbeitern, auf dem Boden zu bleiben und sich zu korrigieren, wenn die Zwischenergebnisse nicht den Erwartungen entsprechen.
Das Gedächtnis hilft einem Agenten, durch die Wiederverwendung früherer Infos die Kontinuität zwischen Interaktionen und Handlungen zu wahren. Ohne Gedächtnis wäre jeder Schritt für sich allein, sodass der Agent immer wieder dasselbe Wissen neu entdecken müsste.
Das Kurzzeitgedächtnis ist normalerweise im Kontextfenster des LLM. Es enthält die neuesten Nachrichten, Zwischenüberlegungen und Tool-Ausgaben. Ähnlich wie RAM in der Computerarchitektur ist dieser Speicher schnell, aber begrenzt und verschwindet, sobald der Kontext überschritten wird.
Das Langzeitgedächtnis wird oft extern gemacht, meistens mit Vektordatenbanken. Techniken wie RAG (Retrieval-Augmented Generation) ermöglichen es dem Agenten, relevante Dokumente oder frühere Interaktionen abzurufen und sie in den aktuellen Kontext einzubinden.
Tools machen Agenten nicht nur sprachlich besser. Sie machen es dem Agenten möglich, mit der echten Welt zu interagieren, zum Beispiel mit Datenbanken, APIs und Rechenmaschinen.
Aus der Sicht des Agenten sind Tools Funktionen, die man aufrufen kann und die bestimmte Eingaben und Ausgaben haben. Der LLM entscheidet, wann ein Tool benutzt wird, welche Argumente man angibt und wie man das Ergebnis interpretiert. Diese Entscheidungsfindung ist das, was Agenten von vorprogrammierten Abläufen unterscheidet.
Tools können Sachen wie Google-Suchen, SQL-Ausführung, Python-Interpreter und APIs haben. Der Agent hat im Grunde Zugriff auf die gleichen technischen Tools wie wir und kann sie kombinieren, um Lösungen umzusetzen.
Das Bild oben zeigt die allgemeine Architektur eines LLM-Agenten. Das Gehirn liefert Erinnerungs- und Planungsinfos, die dann eine Reihe von Aufgaben mit Hilfsmitteln starten.
Dieser Abschnitt fasst die verschiedenen Kategorien von Agenten zusammen, von den einfachsten Reflexagenten bis hin zu komplexen Lernagenten.

Einfache Reflexmittel funktionieren nach direkten Regeln für Bedingungen und Aktionen. Sie denken nicht über die Geschichte, zukünftige Konsequenzen oder andere Möglichkeiten nach. Wenn eine Bedingung erfüllt ist, wird die dazugehörige Aktion sofort gemacht.
Diese Einfachheit macht sie leicht umsetzbar, aber sie sind echt anfällig. Jeder unerwartete Eingang oder ein fehlendes Signal kann zu einem falschen Verhalten führen. Sie können sich auch nicht an veränderte Umgebungen anpassen.
Das Beispiel vom E-Mail-Abmelde-Bot zeigt diese Einschränkung. Es erledigt seine Aufgabe schnell, aber es fehlt ihm das Bewusstsein, was zu unerwünschten Ergebnissen führen kann.
Modellbasierte Reflexagenten sind besser als einfache Reflexagenten, weil sie eine interne Darstellung der Umgebung haben. Dieses interne Modell hilft ihnen, über Sachen nachzudenken, die nicht sofort sichtbar sind.
Indem sie einen Zustand über die Zeit verfolgen, können diese Agenten mit teilweiser Beobachtbarkeit umgehen. Sie erinnern sich an das, was schon passiert ist, und nutzen diese Infos, um zukünftige Handlungen zu planen.
IDE-Assistenten wie Copilot oder Cursor AI sind echt gute Beispiele dafür. Sie behalten den Überblick über Dateien, Variablen und Funktionen während einer ganzen Sitzung und können so intelligentere Vorschläge machen als nur einfache Mustererkennung. Sie schließen auch die Lücke zur nächsten Kategorie von Agenten.
Zielorientierte Agenten sind eher auf Ergebnisse als auf Auslöser ausgerichtet. Sie planen und bewerten Maßnahmen danach, ob sie das System näher an ein gewünschtes Ziel bringen, anstatt nur zu reagieren.
Diese Agenten erstellen Pläne, die mehrere Schritte und bedingte Verzweigungen beinhalten können. Wenn ein Ansatz nicht klappt, kann man es mit einem anderen versuchen. Das macht sie viel flexibler als die reflexbasierten Mittel.
Zum Beispiel zeigt das Erstellen einer Reiseroute, wie ein einzelnes übergeordnetes Ziel in mehrere koordinierte Aktionen über verschiedene Systeme hinweg aufgeteilt werden kann.
Der Agent reagiert nicht einfach nur auf die einfache Aufforderung „Gib mir einen Reiseplan“ und gibt Informationen wieder. Stattdessen könnte es das Ziel in kleinere Teilprobleme aufteilen, wie zum Beispiel:
Das Ziel, eine Reiseroute zu erstellen, wird dann erreicht, indem man die Lösungen für jedes dieser Probleme zusammenbringt.
Nutzenbasierte Agenten erweitern zielbasierte Agenten, indem sie Optimierung einführen. Anstatt einfach nur ein Ziel zu erreichen, checken sie verschiedene Ergebnisse mit einer „Nutzenfunktion”.
Eine Nutzfunktion bewertet Ergebnisse anhand von Kriterien wie Kosten, Zeit, Risiko oder Nutzerpräferenz. Der Agent wählt dann die Aktionsfolge, die den Gesamtnutzen maximiert.
Dieser Ansatz ist bei Empfehlungssystemen und Optimierungsproblemen ziemlich verbreitet. Das kann zum Beispiel sein, die beste Route zu einem Ort zu finden, die richtigen Produkte zu empfehlen oder sogar die beste Analyse für einen bestimmten Nutzer zu erstellen.
Lernende Agenten sind so gemacht, dass sie ihr Verhalten mit der Zeit verbessern, ohne dass man sie extra neu programmieren muss.
Bei jedem Durchlauf kriegt ein Agent Feedback und nutzt diese Infos, um seine Leistung zu verbessern. Sie arbeiten in Umgebungen, in denen das optimale Verhalten nicht im Voraus bekannt ist, und brauchen keine explizite Neuprogrammierung für jede neue Situation.
Es gibt zwei Hauptkomponenten: einen „Kritiker“ und ein „Lernelement“. Der „Kritiker“ checkt die Ergebnisse und gibt Feedback. Das „Lernelement“ nutzt dieses Feedback, um zukünftige Entscheidungen anzupassen. Mit der Zeit passt sich der Agent immer mehr an die Vorlieben der Nutzer oder die Bedingungen der Umgebung an.
Stell dir zum Beispiel einen LLM-Agenten vor, der die täglichen Nachrichten für dich zusammenfasst. Es könnte dein Verhalten beobachten und sich deinen Vorlieben anpassen. Wenn der Agent merkt, dass du selten die Zusammenfassungen zum Thema „Sport“ öffnest, aber Interesse an „Essen und Trinken“ hast, stellt er vielleicht die Sportzusammenfassungen ein und konzentriert sich stattdessen auf dein Interesse an bestimmten Gerichten oder Restaurants.
Die folgende Tabelle zeigt die Unterschiedezwischen den verschiedenen Arten von LLM-Agenten.
|
Agent |
Kernidee |
Speicher |
Planung |
Lernen |
Komplexität |
Beispiel |
|
Einfacher Reflexagent |
Ordnet eine Bedingung direkt einer Aktion zu |
Nein |
Keiner |
Nein |
Sehr niedrig |
E-Mails, die das Wort „Abbestellen“ haben, automatisch archivieren |
|
Modellbasierter Reflexagent |
Hält ein internes Modell der Umgebung aufrecht |
Ja (Statusverfolgung) |
Minimal |
Nein |
Niedrig |
IDE-Assistent, der sich Variablen oder Dateien merkt, die früher in einer Sitzung definiert wurden |
|
Zielorientierter Agent |
Macht Sachen, um ein bestimmtes Ziel zu erreichen |
Ja |
Ja |
Nein |
Mittel |
Flüge, Hotels und Transport für eine Geschäftsreise buchen |
|
Nutzenbasierter Agent |
Wählt das beste Ergebnis basierend auf den Vorlieben aus |
Ja |
Ja |
Nein |
Mittel bis hoch |
Reisebüro, das Kosten, Dauer und Komfort optimiert |
|
Lernagent |
Verbessert das Verhalten mit der Zeit durch Feedback |
Ja |
Ja |
Ja |
Hoch |
Nachrichtenagent, der Inhalte je nach dem, wie Leute sich verhalten, anpasst |
Hier geht's um die gängigen Frameworks, die man zum Bau von LLM-Agentensystemen benutzt.
LangChain bietet ein modulares Framework zum Aufbau von LLM-gestützten Systemen. Die Grundidee ist, dass man komplexe Abläufe aus einfachen Teilen zusammenbauen kann. Es geht darum, mit verschiedenen LLMs zu kommunizieren und diesen Prozess für den Nutzer über Python-Objekte zu abstrahieren.
Das Hauptkonzept von LangChain ist das Konzept der „Chains“, die Prompts, Modelle und Parser zu wiederholbaren Arbeitsabläufen verbinden. Die Idee ist zum Beispiel, dass du ein „ PromptTemplate “ nimmst, das in das LLM eingespeist und von einem „ OutputParser “ verarbeitet wird.
LCEL (LangChain Expression Language) hat eine Syntax, mit der man Pipes (|) benutzen kann, um Ketten visuell zusammenzustellen. Anstatt also klassische Python-Workflows zu verwenden, bei denen du Anweisungen explizit in dein Modell eingeben musst, kannst du einfach chain = prompt | model schreiben und LangChain die Vorlagenerstellung übernehmen lassen.
Für komplexere Funktionen kannst du mit LangChain Tools wie Wikipedia, Python-REPLsund Google Search zu ihren Agenten hinzufügen.
LangGraph baut auf den Funktionen von LangChain auf und kombiniert diese Konzepte mit Speicher, um zustandsbehaftete, produktionsreife Agentenarchitekturen mit expliziter Kontrolle über den Ausführungsfluss zu unterstützen.
Über LangGraph hinaus hat sich das LangChain-Ökosystem weiter gewachsen und bietet jetzt Möglichkeiten, Agenten einfacher zu beobachten (LangSmith) und sogar Drag-and-Drop-Schnittstellen (LangFlow).
LlamaIndex ist super für dokumentenbasierte Arbeitsabläufe, weil es supergenaue OCR und Parsing für über 90 unstrukturierte Dateitypen bietet, optional kombiniert mit agentenbasierten Workflows für intelligentes Abrufen und Extrahieren.
Die Datenkonnektoren machen es einfacher, Daten aus vielen Quellen zu erfassen, und die Indexierungsstrukturen sorgen dafür, dass das Abrufen von Daten optimiert wird. Der VectorStoreIndex ist die häufigste Wahl für die semantische Suche.
Abfrage-Engines kümmern sich um das Abrufen und Generieren von Daten, während Router wie kleine Helfer entscheiden, welche Datenquelle für eine bestimmte Abfrage am besten passt.
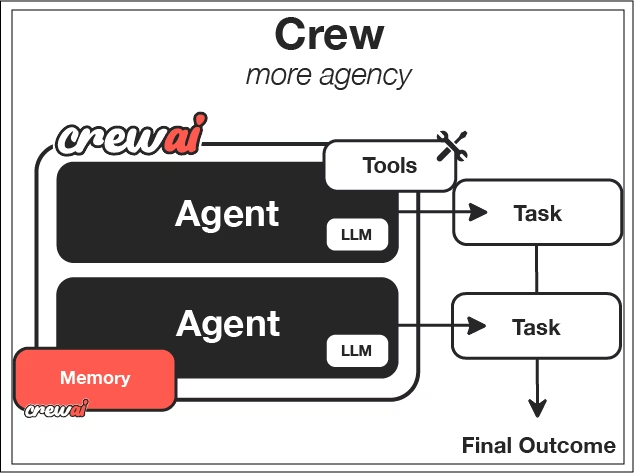
CrewAI ist auf Zusammenarbeit ausgelegt. Statt nur einem Agenten können mehrere Agenten mit unterschiedlichen Aufgaben zusammenarbeiten.
Es dreht sich alles um das Konzept der „Crews“, also einer bestimmten Gruppe von Agenten. Jedem Agenten werden eine Persönlichkeit, ein Ziel und eine Hintergrundgeschichte zugewiesen, die sein Verhalten beeinflussen.
Aufgaben sagen dir, was zu tun ist und wie Erfolg aussieht. Du legst fest, wie eine einzelne Aufgabe aussieht, gibst ein paar Parameter an, was als Ergebnis erwartet wird und welche Agenten an dieser Aufgabe arbeiten sollen.
Prozesse bestimmen, wie Aufgaben erledigt werden: nacheinander, in einer bestimmten Reihenfolge oder mit Orchestrator-Worker-Mustern, bei denen ein Hauptakteur komplexe Aufgaben dynamisch aufteilt und dabei menschliche Teams nachahmt.
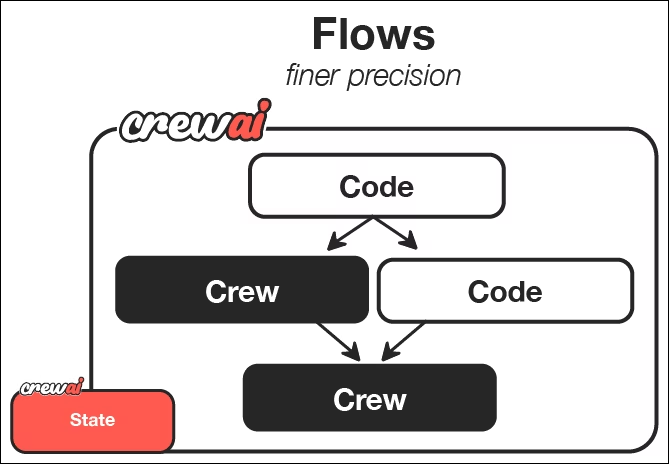
Aus der CrewAI-Dokumentationkönnen wir sehen, dass Flows eine Möglichkeit bieten, Crews zu koordinieren und auszulösen. Jedes Team nutzt LLM-Agenten mit festgelegten Rollen und Aufgaben, um bestimmte Arbeiten zu erledigen und die gewünschten Ergebnisse zu erzielen.
Die Wahl eines Frameworks hängt von deinem Problemfeld und deinen Einschränkungen ab. Jedes der vorgestellten Frameworks hat seine eigenen Stärken:
Denk mal über die Komplexität deiner Daten, den benötigten Grad an Autonomie und die betrieblichen Einschränkungen nach. Es gibt keine allgemeingültige richtige Wahl.
Um dir bei deiner Entscheidung zu helfen, kannst du auch unsere Artikel lesen, in denen wir LangChain mit Llamaindex vergleichen, bzw. CrewAI mit LangGraph.
Die Einsatzmöglichkeiten für LLM-Agenten sind echt unbegrenzt und hängen nur von deiner Fantasie ab.
Moderne Programmierassistenten nutzen automatisierte Abläufe, um Änderungen zu planen, durchzuführen und zu überprüfen. Sie können einen Code untersuchen, Lösungen finden, Tests machen und Fehler immer wieder beheben.
Zum Beispiel Cursor nativ in deine IDE und hilft dir dabei, Zeilen zu vervollständigen oder Änderungen an Pipelines mit Auswirkungen auf nachgelagerte Prozesse zu korrigieren. Claude Code kann dir beim Schreiben von Tests helfen, ganze Skripte erstellen oder Unstimmigkeiten in deinem Code in einem Repository finden. Wir können GitHub Copilot nutzen, um beim Schreiben von Pull-Anfragen und beim Testen von Code als Teil eines Anfrage-Workflows zu helfen.
Dadurch ändert sich die Rolle der Entwickler: Sie schreiben nicht mehr jede Zeile selbst, sondern kümmern sich um die Überwachung und Steuerung intelligenter Systeme. Für Leute, die mit Daten arbeiten, kann das das Experimentieren und Prototyping echt beschleunigen.
Ich empfehle dir, den Kurs „Softwareentwicklung mit GitHub Copilot” zu machen, wenn du mit LLM-basierten Programmierassistenten loslegen willst.
Mit agentenbasierten BI-Systemen kannst du Fragen in natürlicher Sprache stellen und bekommst dann umsetzbare Infos. Der Agent kann Fragen in SQL übersetzen, Abfragen ausführen und Ergebnisse erklären.
Du kannst mit deinen Daten reden, als würdest du mit einem erfahrenen Teammitglied sprechen, und so in Echtzeit neue Erkenntnisse und Visualisierungen bekommen. Das macht dich weniger abhängig von Dashboards und ermöglicht auch Leuten ohne technischen Hintergrund, sich mit der Datenanalyse zu beschäftigen.
Recherche-Agenten machen das Sammeln und Zusammenfassen von Infos automatisch. Sie suchen im Internet, finden Quellen und fassen die Ergebnisse zusammen; manche Systeme haben einfache Filter für die Qualität der Quellen. Sie können sogar interne Dokumente anschauen, die auf Websites wie Notion gehostet werden, oder Nachrichten innerhalb von Slack.
Mit dem Zugriff auf all diese Infos können LLM-Agenten nicht nur schnell Infos zusammenfassen, sondern auch ganze Dokumente und Zusammenfassungen erstellen, damit Teams Infos schnell austauschen können.
Das ist besonders wichtig in Bereichen, wo sich alles schnell ändert und statische Datensätze schnell veralten. Agenten liefern ständig aktualisierte Einblicke.
Weitere Ideen, wie Leute KI-Agenten nutzen, findest du in unserem Leitfaden zu den Top 10 der KI-Agenten-Projekte.
Agentische Workflows sind zwar super und echt leistungsstark, bringen aber auch ihre eigenen Herausforderungen mit sich. Agenten können Schritte falsch interpretieren, Tool-Ausgaben falsch verstehen oder in lange oder ungewollte Schleifen geraten. Sicherheitsvorkehrungen, Validierung und Beobachtbarkeit sind für Produktionssysteme echt wichtig.
Jede Aktion eines Agenten braucht oft einen LLM-Aufruf. Komplizierte Aufgaben können viele Anrufe erfordern, was die Latenz und die API-Kosten erhöht. Außerdem musst du vielleicht für zusätzliche Infrastruktur wie Cloud-Speicher, Cloud-Computing und andere Kosten aufkommen, um den LLM-Agenten zu unterstützen.
Autonome Systeme sind schwieriger zu debuggen als deterministischer Code. Um zu verstehen, warum ein Agent eine Entscheidung getroffen hat, muss man seinen Zustand, sein Gedächtnis und seine Gedankengänge nachverfolgen.
Je nachdem, welches Agent-Framework du benutzt, kann das echt schwierig sein. Einige Frameworks, wie zum Beispiel CrewAI, sind viel komplexer als einfachere Frameworks wie LangChain, bei denen es darum geht, den Zugriff auf deine LLMs zu vereinfachen.
Wir wechseln von einzelnen Chatbots zu Workflows, die selbstständig denken, planen und handeln können. Auch wenn es noch früh ist, verändert dieses Paradigma schon jetzt, wie Datensysteme aufgebaut sind und genutzt werden.
Für angehende Datenfachleute ist es echt hilfreich, sich schon jetzt mit LLM-Agenten zu beschäftigen, um für die Jobs von morgen gut gerüstet zu sein. Diese Systeme sind echt die Zukunft der intelligenten Automatisierung.
Fang an, diese LLM-Agenten mit unserem Designing Agentic Systems with LangChain !
LLM-Agentenkurse
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
Derrick Mwiti
Tutorial
Matt Crabtree