
Cursus
Principes fondamentaux des agents IA
6 h
Les compétences intégrées d’OpenClaw couvrent les workflows les plus courants, et ClawHub en héberge beaucoup d’autres. Mais celles qui comptent le plus sont souvent celles que personne n’a encore créées : des automatisations taillées pour vos projets et vos outils.
Ce tutoriel montre comment construire deux compétences personnalisées. La première encapsule un script Python qui convertit des notebooks Jupyter en documents Word. Si vous rédigez dans des notebooks mais remettez des fichiers .docx à des éditeurs ou des parties prenantes, cela transforme une exportation manuelle en commande slash. La seconde génère des images avec Nano Banana Pro via l’API Replicate, en ajoutant la gestion des identifiants et le ciblage d’environnement au-delà des bases.
Le tutoriel couvre également l’isolation via Docker, le filtrage par métadonnées et la publication des compétences sur ClawHub. Pour un aperçu plus large de la plateforme OpenClaw, consultez OpenClaw Projects : ce que vous pouvez construire ainsi que notre guide des meilleures compétences d’agent.
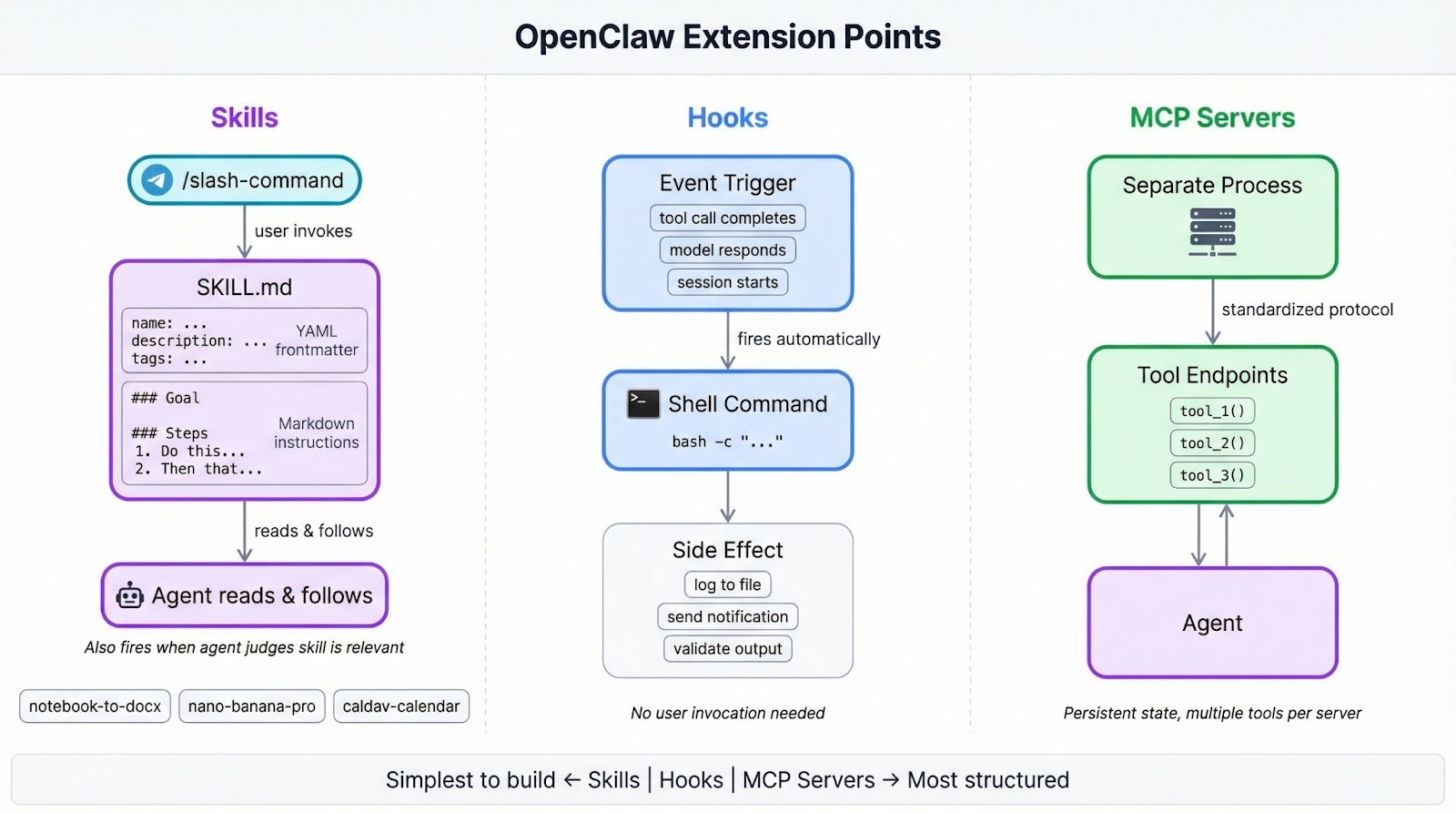
Les compétences sont le moyen d’ajouter de nouveaux comportements à l’agent OpenClaw. Une compétence peut être aussi simple qu’une commande slash qui reformate du code, ou aussi aboutie qu’un workflow multi-étapes qui relit des PR et publie des commentaires dans Jira ou Slack.
Si vous avez utilisé des serveurs MCP (Model Context Protocol) dans Claude Code ou des outils similaires, les compétences jouent un rôle différent. Les serveurs MCP sont des processus séparés exposant des outils via un protocole standardisé, idéal pour les intégrations nécessitant un état persistant ou plusieurs points d’accès.
Les compétences s’affranchissent de tout cela : vous écrivez des consignes en langage naturel que l’agent lit et exécute à l’exécution, ce qui les rend plus rapides à construire quand vous avez juste un besoin précis à automatiser. La comparaison OpenClaw vs Claude Code détaille davantage les compromis.
Les hooks, l’autre point d’extension, se déclenchent automatiquement lorsqu’un événement survient, comme l’achèvement d’un appel d’outil ou la génération d’une réponse par le modèle. Les compétences restent inactives jusqu’à ce que vous tapiez une commande slash ou que l’agent juge l’une d’elles pertinente pour la tâche en cours.
OpenClaw regroupe 49 compétences couvrant l’e-mail, les agendas, GitHub, l’automatisation du navigateur, et plus encore. La communauté en a publié des milliers supplémentaires sur ClawHub. Pour comprendre l’évolution de la plateforme, consultez l’historique de MoltBot à ClawdBot.
Vous aurez besoin :
Si vous préférez exécuter OpenClaw avec des modèles locaux, le tutoriel OpenClaw avec Ollama couvre cette configuration.
Cette première compétence encapsule un script Python qui convertit des notebooks Jupyter en documents Word, en gérant la mise en forme Markdown, les blocs de code, les images, les tableaux et les hyperliens afin que la sortie .docx préserve la structure du notebook d’origine. Si vous transmettez régulièrement le contenu d’un notebook à des personnes travaillant dans Word, cela transforme l’exportation manuelle en une simple commande slash.
Créez le dossier de la compétence dans le répertoire des compétences gérées d’OpenClaw :
mkdir -p ~/.openclaw/skills/notebook-to-docxLes compétences dans ~/.openclaw/skills sont disponibles dans toutes vos sessions. Vous pouvez aussi les placer dans un projet à <project>/skills pour les limiter à cet espace de travail ; si un nom existe aux deux endroits, la copie de l’espace de travail a priorité sur la version gérée, qui elle-même surpasse toute compétence intégrée portant le même nom.
Chaque compétence a besoin d’un seul fichier : SKILL.md. Le front matter YAML en tête définit comment OpenClaw charge la compétence, et le corps en Markdown en dessous contient les instructions que l’agent suit à l’exécution.
Créez ~/.openclaw/skills/notebook-to-docx/SKILL.md, en commençant par le front matter :
---
name: notebook-to-docx
description: Convertir des notebooks Jupyter en documents Word avec une mise en forme soignée
user-invocable: true
metadata: {"openclaw": {"requires": {"bins": ["uv"]}}}
---name sert aussi de commande slash (/notebook-to-docx). description donne à l’agent une phrase lui permettant d’évaluer la pertinence par rapport à la tâche en cours. Définir user-invocable: true enregistre la commande slash dans votre discussion Telegram. Le JSON metadata gère le filtrage au chargement : requires.bins indique à OpenClaw d’ignorer cette compétence si uv n’est pas dans le PATH système, plutôt que d’échouer à l’exécution.
Si vous voulez l’inverse, à savoir que la compétence ne se déclenche jamais sans taper explicitement la commande slash, définissez disable-model-invocation: true.
Astuce : le front matter YAML n’accepte que des valeurs sur une seule ligne. Les chaînes multi-lignes ou blocs scalaires provoquent des erreurs d’analyse, c’est pourquoi metadata est un objet JSON sur une seule ligne plutôt qu’un YAML imbriqué.
Sous le front matter, ajoutez le corps des instructions :
# Convertisseur Notebook vers DOCX
Convertit des notebooks Jupyter (.ipynb) en documents Word (.docx) avec une mise en forme soignée.
## Utilisation
Exécutez le script de conversion :
uv run --with nbformat --with python-docx --with Pillow python {baseDir}/notebook_to_docx.py <notebook_path> [output_path]
Si output_path n’est pas précisé, crée un fichier .docx portant le même nom que le notebook.
## Fonctionnalités
- Mise en forme Markdown préservée en styles Word (gras, italique, titres)
- Backticks conservés autour du code inline avec police monospace
- Blocs de code avec triple backticks et nom du langage, police Courier New
- Texte hors code en police Poppins
- Images intégrées avec texte alternatif
- Hyperliens conservés et cliquables
- Tableaux Markdown convertis en tableaux Word
## Prérequis
- nbformat
- python-docx
- Pillow{baseDir} est une variable de gabarit qui pointe vers le dossier de la compétence à l’exécution, vous évitant de coder en dur l’emplacement. C’est utile lorsqu’une autre personne installe votre compétence dans un répertoire différent.
Les indicateurs uv run --with récupèrent les trois bibliothèques nécessaires au script, ce qui rend la compétence autonome sans supposer que ces packages existent déjà dans l’environnement de l’utilisateur.
Le script Python se place dans le même dossier que SKILL.md. Avec environ 490 lignes, il est trop long pour figurer ici ; récupérez le script complet depuis ce gist et placez-le en tant que notebook_to_docx.py dans ~/.openclaw/skills/notebook-to-docx/. Il couvre tout ce qui est listé dans la section Fonctionnalités du SKILL.md ci-dessus.
Voici le point d’entrée pour comprendre la logique globale :
def convert_notebook_to_docx(notebook_path, output_path=None):
notebook_path = Path(notebook_path)
if output_path is None:
output_path = notebook_path.with_suffix('.docx')
else:
output_path = Path(output_path)
with open(notebook_path, 'r', encoding='utf-8') as f:
nb = nbformat.read(f, as_version=4)
doc = Document()
create_styles(doc)
style = doc.styles['Normal']
style.font.name = 'Poppins'
style.font.size = Pt(11)
base_path = notebook_path.parent
for cell in nb.cells:
if cell.cell_type == 'markdown':
process_markdown_cell(doc, cell.source, base_path)
elif cell.cell_type == 'code':
process_code_cell(doc, cell.source, cell.get('outputs', []))
doc.save(output_path)
print(f'Converted: {notebook_path} -> {output_path}')
return output_pathOpenClaw fige la liste des compétences au démarrage de la session, mais un watcher intégré détecte les nouveaux fichiers SKILL.md en environ 250 ms. Si la compétence n’apparaît pas, redémarrez la session.
Voici le notebook que nous utiliserons pour le test :
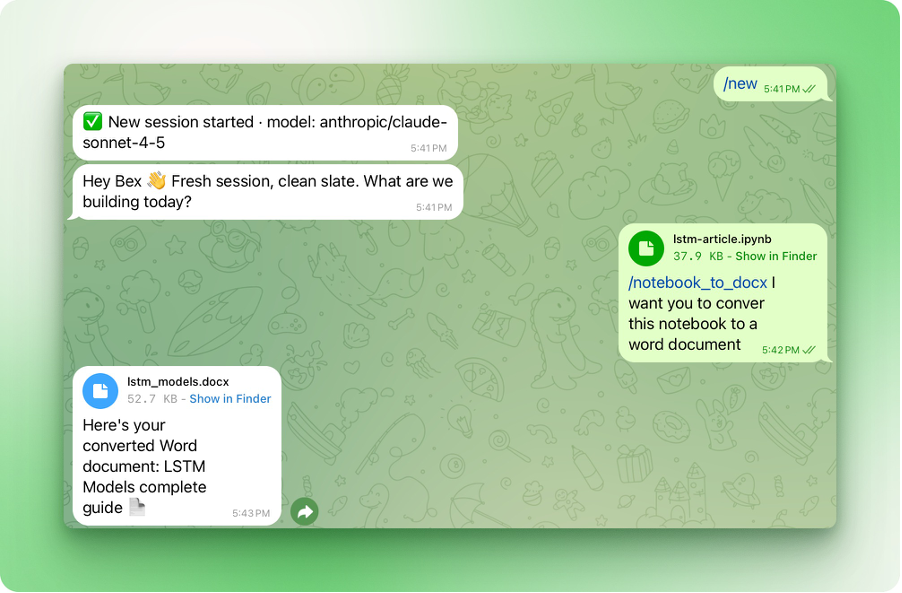
Ouvrez votre discussion Telegram avec OpenClaw et tapez /notebook-to-docx, puis indiquez quel notebook convertir :
Le document Word obtenu :
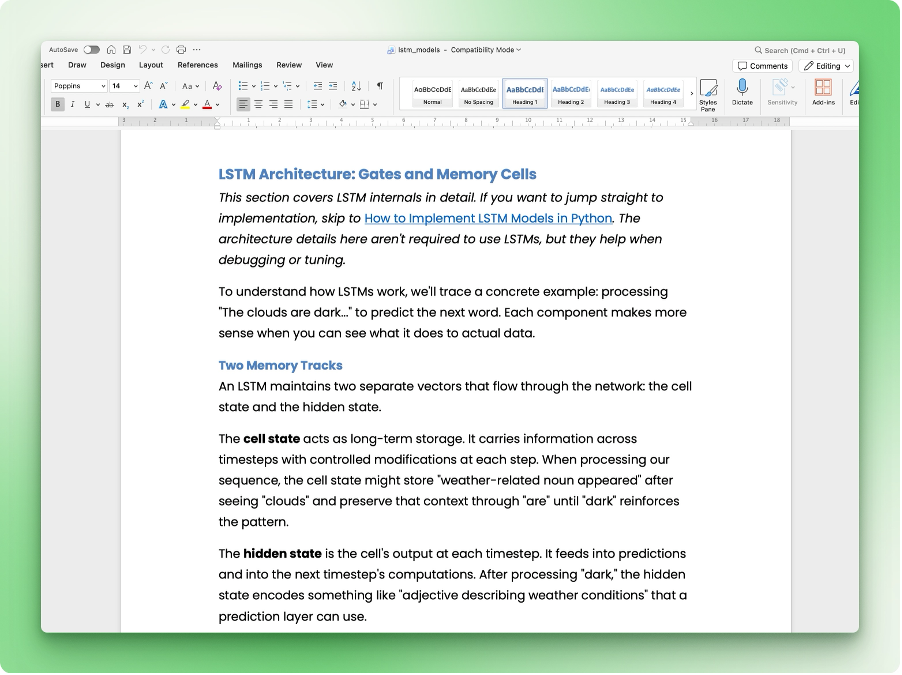
Les titres, blocs de code, mises en forme inline et hyperliens sont correctement restitués en styles Word. Si quelque chose semble incorrect, vérifiez que la liste des fonctionnalités dans votre SKILL.md correspond bien à ce que le script prend en charge.
OpenClaw peut exécuter des outils dans des conteneurs Docker, ce qui limite ce qu’une compétence défaillante ou compromise peut toucher sur votre machine. Le paramètre se trouve dans agents.defaults.sandbox dans ~/.openclaw/openclaw.json, avec trois modes au choix :
"off" est la valeur par défaut : les outils s’exécutent directement sur l’hôte, sans couche d’isolation."non-main" garde votre session de discussion principale sur l’hôte mais déplace les sessions en arrière-plan et automatisées dans des conteneurs."all", chaque session s’exécute dans un conteneur, quel que soit le contexte.En plus du mode, vous choisissez un niveau d’accès à l’espace de travail qui détermine la visibilité du système de fichiers. Par défaut, "none" attribue au bac à sable son propre répertoire isolé sous ~/.openclaw/sandboxes sans accès à vos fichiers de projet.
Avec "ro", votre espace de travail est monté en lecture seule à /agent, l’agent peut donc lire votre code sans rien modifier. "rw" va plus loin et accorde un accès complet en lecture-écriture à /workspace.
Une configuration fonctionnelle qui isole les sessions d’arrière-plan tout en leur donnant un accès en écriture ressemble à ceci :
{
"agents": {
"defaults": {
"sandbox": {
"mode": "non-main",
"scope": "session",
"workspaceAccess": "rw"
}
}
}
}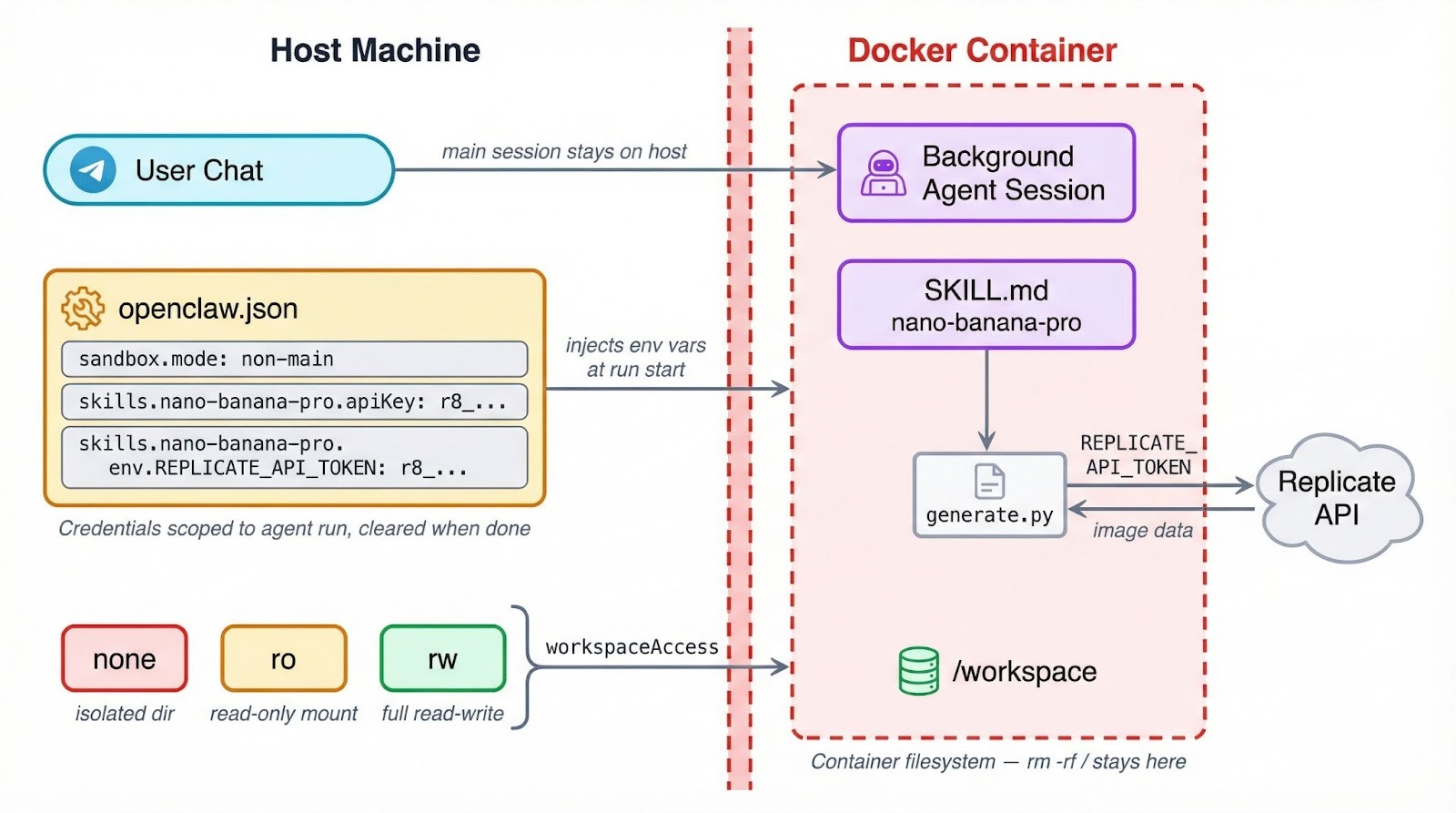
Ce point devient crucial dès que vos compétences appellent des API ou gèrent des identifiants.
Quand une compétence s’exécute dans un conteneur, les variables d’environnement de l’hôte ne sont pas présentes automatiquement. Un REPLICATE_API_TOKEN exporté dans .bashrc n’existera pas dans le bac à sable ; les secrets doivent donc passer par le système de configuration d’OpenClaw, que nous allons mettre en place dans la section suivante.
Astuce : si votre compétence utilise requires.bins dans ses métadonnées pour vérifier un outil CLI, ce contrôle s’effectue sur l’hôte au chargement. Mais si l’agent est isolé, le binaire doit aussi exister dans le conteneur. Installez-le via sandbox.docker.setupCommand ou intégrez-le dans une image Docker personnalisée.
L’isolation limite aussi l’impact en cas d’erreurs sur les fichiers ou les commandes shell. Une compétence qui lancerait par inadvertance rm -rf / toucherait le système de fichiers du conteneur plutôt que votre machine réelle, ce qui justifie déjà d’activer l’option, même si vous faites confiance à votre propre code.
Pour en savoir plus sur la façon dont les workflows d’agents IA gèrent les frontières de sécurité, consultez AI Agent Workflows with Claude CoWork.
La seconde compétence génère des images avec le modèle Nano Banana Pro (Gemini 3 Pro Image) de Google via l’API Replicate, ce qui implique de câbler la gestion des identifiants et le ciblage d’environnement en plus des bases du SKILL.md.
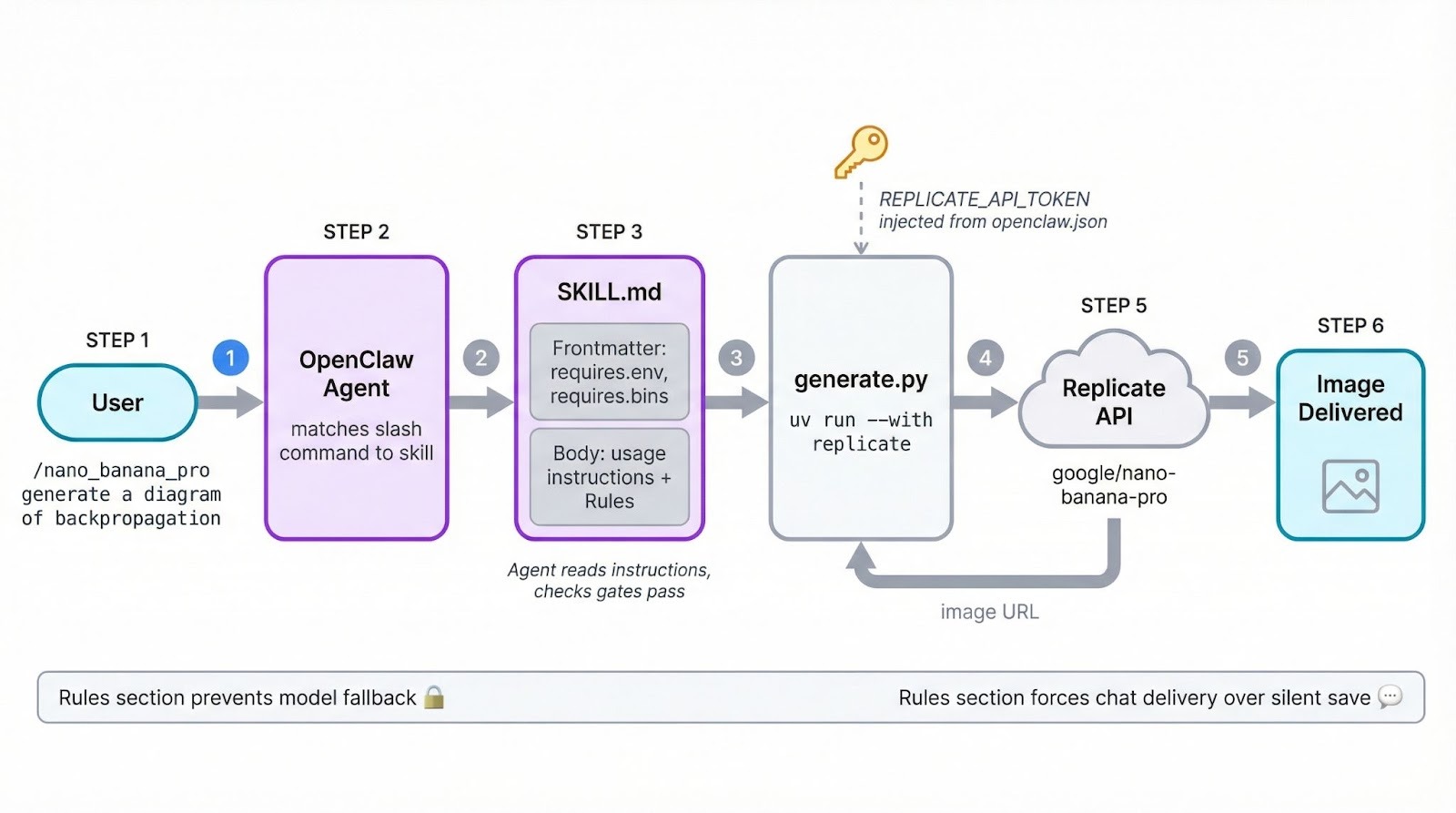
Créez le dossier de la compétence :
mkdir -p ~/.openclaw/skills/nano-banana-proCréez ~/.openclaw/skills/nano-banana-pro/SKILL.md, en commençant par le front matter :
---
name: nano-banana-pro
description: Générer ou modifier des images via Gemini 3 Pro Image sur Replicate
user-invocable: true
metadata: {"openclaw": {"emoji": "🎨", "requires": {"env": ["REPLICATE_API_TOKEN"], "bins": ["uv"]}, "primaryEnv": "REPLICATE_API_TOKEN"}}
---La structure est identique à la première compétence, mais le champ metadata fait davantage. Il inclut deux contrôles : requires.env vérifie l’existence de REPLICATE_API_TOKEN avant de charger la compétence, et requires.bins vérifie la présence de uv. Si l’un des deux manque, la compétence est ignorée sans bruit.
Le champ emoji définit une icône dans la liste des commandes slash Telegram. Et primaryEnv associe REPLICATE_API_TOKEN au raccourci apiKey dans la configuration (voir la section sur les identifiants ci-dessous).
Si vous voulez que l’interface macOS Skills propose l’installation en un clic des binaires requis, ajoutez un tableau install aux métadonnées :
metadata: {"openclaw": {"requires": {"bins": ["uv"]}, "install": [{"id": "brew", "kind": "brew", "formula": "uv", "bins": ["uv"], "label": "Install uv (brew)"}]}}Sur Linux, gérez l’installation manuellement ou via sandbox.docker.setupCommand.
Sous le front matter, ajoutez le corps des instructions :
# Générateur d’images Nano Banana Pro
Générez et modifiez des images avec le modèle Nano Banana Pro de Google via l’API Replicate.
## Utilisation
Exécutez le script de génération :
uv run --with replicate python {baseDir}/generate.py --prompt "<user prompt>" [--aspect-ratio 1:1] [--output image.png]
## Options
- --prompt : la description de l’image (obligatoire)
- --aspect-ratio : ratio du type 1:1, 4:3, 16:9 (par défaut : 1:1)
- --output : chemin du fichier de sortie (par défaut : generated_image.png)
## Conseils
- Pour du texte dans l’image, précisez la police, la taille et l’emplacement
- Le modèle prend en charge des résolutions jusqu’à 2K
- Le filtrage de sécurité est activé par défautLe corps est plus court que celui de la première compétence, car le script de génération gère l’essentiel de la complexité. La variable de gabarit {baseDir} fonctionne de la même manière, en pointant vers le dossier de la compétence à l’exécution.
Ajoutez ~/.openclaw/skills/nano-banana-pro/generate.py :
import replicate
import urllib.request
import argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--prompt", required=True)
parser.add_argument("--aspect-ratio", default="1:1")
parser.add_argument("--output", default="generated_image.png")
args = parser.parse_args()
output = replicate.run(
"google/nano-banana-pro",
input={
"prompt": args.prompt,
"aspect_ratio": args.aspect_ratio,
"output_format": "png",
"safety_filter_level": "block_only_high",
},
)
# Replicate renvoie un FileOutput ; télécharger l’image
url = str(output[0]) if isinstance(output, list) else str(output)
urllib.request.urlretrieve(url, args.output)
print(f"Image saved to {args.output}")
if __name__ == "__main__":
main()Il analyse les arguments, appelle replicate.run() avec le nom du modèle et les paramètres d’entrée, puis télécharge l’image résultante. La bibliothèque replicate lit automatiquement REPLICATE_API_TOKEN dans l’environnement.
Ajoutez une entrée dans ~/.openclaw/openclaw.json :
{
"skills": {
"entries": {
"nano-banana-pro": {
"enabled": true,
"apiKey": "r8_your_replicate_token_here",
"env": {
"REPLICATE_API_TOKEN": "r8_your_replicate_token_here"
}
}
}
}
}Il y a deux manières de fournir l’identifiant ici. Le champ apiKey est un raccourci mappé à ce que primaryEnv déclare dans les métadonnées de la compétence. Le bloc env offre un contrôle plus fin, vous permettant d’injecter plusieurs variables d’environnement si la compétence en a besoin.
Les deux approches limitent la portée des valeurs à l’exécution de l’agent. Elles sont définies au démarrage de l’exécution et vidées à la fin, sans fuite dans votre environnement shell global.
Démarrez une nouvelle session OpenClaw et invoquez la compétence :
/nano_banana_pro generate a beautiful and accurate diagram of how backpropagation worksVoici le schéma produit par la compétence via Nano Banana Pro sur Replicate :
L’image est bien arrivée, mais il a fallu un détour pour y parvenir. La première version de ce SKILL.md n’avait pas de section ## Rules, ce qui laissait de la latitude à l’agent. Quand Nano Banana Pro a renvoyé une erreur « service indisponible » en raison d’une forte demande, l’agent a décidé de lui-même d’essayer google/nano-banana (la variante non Pro) comme solution de repli et a généré l’image avec ce modèle.
Du point de vue de l’agent, le choix se tenait : accomplir la tâche par tous les moyens disponibles. Du vôtre, ce n’était pas ce que vous aviez demandé. La solution a été d’ajouter des contraintes de comportement dans le corps des instructions :
## Rules
- Utilisez uniquement le modèle google/nano-banana-pro. Ne basculez jamais vers d’autres modèles comme google/nano-banana ou une alternative. Si le modèle est indisponible ou soumis à des limites de débit, signalez l’erreur à l’utilisateur et arrêtez-vous.
- Après la génération, envoyez le fichier image directement dans le chat. Ne vous contentez pas de l’enregistrer silencieusement dans l’espace de travail.L’agent traite les instructions du SKILL.md comme des lignes directrices plutôt que des limites absolues, et comblera les vides par son propre jugement. Tout ce que vous ne lui interdisez pas explicitement, il peut décider de l’essayer.
Si un comportement compte pour vous — quel modèle utiliser, où envoyer la sortie, si l’on doit retenter en cas d’échec —, explicitez-le dans une section Rules.
ClawHub est le registre public des compétences OpenClaw, librement consultable et installable. La publication nécessite un compte GitHub âgé d’au moins une semaine.
Installez le CLI ClawHub globalement :
npm i -g clawhubPuis authentifiez-vous :
clawhub loginVotre navigateur s’ouvre pour l’authentification GitHub. Une fois connecté, vous pouvez rechercher, installer et publier des compétences depuis le terminal.
Pour publier la compétence de génération d’images :
clawhub publish ~/.openclaw/skills/nano-banana-pro \
--slug nano-banana-pro \
--name "Nano Banana Pro" \
--version 1.0.0 \
--tags latestLe --slug est l’identifiant unique sur ClawHub et doit être unique sur tout le registre. Si quelqu’un a déjà publié une compétence avec ce slug, la commande échouera avec « seul le propriétaire peut publier des mises à jour ». Dans ce cas, choisissez un autre slug, par exemple yourname-nano-banana-pro.
L’argument --version suit le versionnage sémantique. À chaque publication, incrémentez le numéro de version et, si besoin, ajoutez un journal des modifications :
clawhub publish ~/.openclaw/skills/nano-banana-pro \
--slug nano-banana-pro \
--version 1.1.0 \
--changelog "Ajout de l’édition d’images avec l’option --image-input"ClawHub conserve l’historique des versions afin que les utilisateurs puissent auditer les changements et revenir en arrière si nécessaire.
Pour des opérations en masse, clawhub sync --all parcourt votre répertoire de compétences et publie d’un coup toutes les compétences nouvelles ou mises à jour :
clawhub sync --all --bump patchPour installer une compétence publiée par un tiers :
clawhub search "calendar"
clawhub install caldav-calendarLes compétences installées vont par défaut dans ./skills, qu’OpenClaw détecte comme compétences de l’espace de travail à la prochaine session.
En janvier 2026, des chercheurs en sécurité chez Koi ont découvert 341 compétences malveillantes sur ClawHub, dans ce qui a été appelé l’ incident ClawHavoc. Des attaquants ont utilisé des noms de compétences proches (typosquatting) et de fausses étapes d’installation « prérequises » pour distribuer l’outil de vol AMOS (Atomic macOS Stealer), des reverse shells et des charges utiles d’exfiltration d’identifiants.
À la mi-février 2026, le nombre dépassait 824 compétences signalées dans des dizaines de catégories.
Avant d’installer une compétence communautaire, lisez son SKILL.md et ses fichiers associés. Méfiez-vous des étapes d’installation « prérequises » suspectes, du code obscurci ou des commandes encodées en base64. ClawHub masque automatiquement les compétences avec trois signalements utilisateurs ou plus, mais de nouvelles compétences malveillantes peuvent apparaître plus vite que la modération ne les rattrape.
Des outils comme Clawdex peuvent analyser vos compétences installées en les comparant à une base de données de paquets malveillants connus.
Traitez les compétences tierces avec la même prudence que tout code tiers : passez-les en revue avant exécution.
Entre le format SKILL.md, la portée des identifiants via openclaw.json et le CLI ClawHub, vous disposez de tout le cycle de vie, de l’automatisation locale au paquet partagé.
L’essentiel du travail pour créer une nouvelle compétence OpenClaw consiste à rédiger des instructions claires dans le corps Markdown et à décider quoi filtrer dans les métadonnées. Le code proprement dit, qu’il s’agisse d’un script de conversion ou d’un appel d’API, reste dans des fichiers séparés que vous pouvez tester et itérer indépendamment.
Pour aller au-delà de ce que couvre ce tutoriel, les compétences intégrées dans le dépôt OpenClaw montrent comment l’équipe cœur structure des workflows plus avancés. La présentation de Claude Opus 4.6 explique comment le choix des modèles influe sur le comportement de l’agent, et le cours Introduction to Claude Models propose des exercices pratiques sur les modèles derrière des agents comme OpenClaw.
Meilleurs cours DataCamp
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Zoumana Keita
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Kurtis Pykes
