
Curso
Extreme Gradient Boosting com XGBoost
4 h
60.7K
Python é uma das linguagens de programação mais populares usadas em várias áreas da tecnologia, especialmente em ciência de dados e machine learning. Python é uma linguagem fácil de programar, orientada a objetos e de alto nível, com um monte de bibliotecas para vários casos de uso. Tem mais de 200.000 bibliotecas.
Uma das razões pelas quais o Python é tão valioso para a ciência de dados é sua vasta coleção de bibliotecas de manipulação de dados, visualização de dados, machine learning e aprendizado profundo. Como o Python tem um ecossistema tão rico de bibliotecas de ciência de dados, é quase impossível falar de tudo em um único artigo. A lista das principais bibliotecas aqui se concentra em apenas cinco áreas principais:
Tem várias outras áreas que não estão nessa lista; tipo, MLOps, Big Data e Visão Computacional. A lista neste blog não segue nenhuma ordem específica e não pretende ser vista de forma alguma como um tipo de classificação.
O NumPy é uma das bibliotecas Python de código aberto mais usadas e serve principalmente para cálculos científicos. As funções matemáticas integradas permitem cálculos super rápidos e podem lidar com dados multidimensionais e grandes matrizes. Também é usado em álgebra linear. A matriz NumPy costuma ser usada em vez das listas, porque usa menos memória e é mais prática e eficiente.
De acordo com o site do NumPy, trata-se de um projeto de código aberto que visa possibilitar a computação numérica com Python. Foi criado em 2005 e baseado no trabalho inicial das bibliotecas Numeric e Numarray. Uma das grandes vantagens do NumPy é que ele foi lançado sob a licença BSD modificada e, portanto, sempre será gratuito para todos usarem.
O NumPy é desenvolvido abertamente no GitHub com o consenso da comunidade NumPy e da comunidade científica Python em geral. Você pode saber mais sobre isso no nosso curso introdutório do Numpy.
⭐ GitHub Stars: 25K | Total de downloads: 2,4 bilhões
Pandas é uma biblioteca de código aberto que todo mundo usa na ciência de dados. É usado principalmente para análise, manipulação e limpeza de dados. O Pandas permite modelar dados e fazer análises de dados de forma simples, sem precisar escrever muito código. Como dizem no site deles, o pandas é uma ferramenta de análise e manipulação de dados de código aberto que é rápida, poderosa, flexível e fácil de usar. Algumas das principais características desta biblioteca incluem:
Começar a usar o pandas é simples e direto. Você pode conferir o curso Analisando a atividade policial com pandas do DataCamp para aprender a usar o pandas em conjuntos de dados reais.
⭐ GitHub Stars: 41K | Total de downloads: 1,6 bilhão
Enquanto o Pandas continua sendo o padrão para pequenos volumes de dados, o Polars se tornou o padrão para o processamento de dados de alto desempenho. Escrito em Rust, ele usa um mecanismo de “avaliação preguiçosa” para processar conjuntos de dados (10 GB–100 GB+) que normalmente travariam máquinas com RAM limitada. Diferente do Pandas, que faz as operações uma atrás da outra, o Polars otimiza as consultas do começo ao fim e as executa ao mesmo tempo em todos os núcleos de CPU disponíveis.
Ele foi feito pra ser uma atualização fácil pra cargas de trabalho pesadas, com uma sintaxe que geralmente é mais fácil de ler e de 10 a 50 vezes mais rápida que os DataFrame tradicionais.
Aqui está um exemplo de código para liderar uma seleção filtrada, agrupada e agregada a partir de um conjunto de dados CSV gigante:
import polars as pl
# Lazy evaluation: Nothing runs until .collect() is called
# allowing Polars to optimize the query plan beforehand
q = (
pl.scan_csv("massive_dataset.csv")
.filter(pl.col("category") == "Technology")
.group_by("region")
.agg(pl.col("sales").sum())
)
df = q.collect() # Executes in parallel⭐ GitHub Stars: Mais de 40 mil | Status: Padrão de alto desempenho
Matplotlib é uma biblioteca bem completa pra criar visualizações fixas, interativas e animadas em Python. Um monte de pacotes de terceiros ampliam e melhoram as funcionalidades do Matplotlib, incluindo várias interfaces de plotagem de nível superior (Seaborn, HoloViews, ggplot, etc.).
O Matplotlib foi feito pra ser tão funcional quanto o MATLAB, com a vantagem extra de poder usar Python. Ele também tem a vantagem de ser gratuito e de código aberto. Permite ao usuário visualizar dados usando vários tipos diferentes de gráficos, incluindo, entre outros, gráficos de dispersão, histogramas, gráficos de barras, gráficos de erros e gráficos de caixa. Além disso, todas as visualizações podem ser feitas com só algumas linhas de código.
Exemplos de gráficos criados com o Matplotlib
Comece a usar o Matplotlib com este tutorial passo a passo.
⭐ GitHub Stars: 18,7 mil | Total de downloads: 653 milhões
Outra estrutura popular de visualização de dados Python baseada em Matplotlib, o Seaborn é uma interface de alto nível para criar visuais estatísticos esteticamente atraentes e valiosos, que são essenciais para estudar e entender os dados. Essa biblioteca Python está bem ligada às estruturas de dados NumPy e pandas. O princípio fundamental por trás do Seaborn é tornar a visualização um componente essencial da análise e exploração de dados; assim, seus algoritmos de plotagem usam estruturas de dados que abrangem conjuntos de dados inteiros.
Galeria de exemplos do Seaborn
Este tutorial do Seaborn para iniciantes é um ótimo recurso para te ajudar a se familiarizar com essa biblioteca de visualização dinâmica.
⭐ GitHub Stars: 11,6 mil | Total de downloads: 180 milhões
A biblioteca gráfica de código aberto super popular Plotly pode ser usada para criar visualizações de dados interativas. O Plotly é construído com base na biblioteca JavaScript Plotly (plotly.js) e pode ser usado para criar visualizações de dados baseadas na web que podem ser salvas como arquivos HTML ou exibidas em notebooks Jupyter e aplicativos web usando o Dash.
Ele oferece mais de 40 tipos de gráficos exclusivos, como gráficos de dispersão, histogramas, gráficos de linha, gráficos de barras, gráficos de pizza, barras de erro, gráficos de caixa, eixos múltiplos, minigráficos, dendrogramas e gráficos 3D. O Plotly também oferece gráficos de contorno, que não são tão comuns em outras bibliotecas de visualização de dados.
Se você quer visualizações interativas ou gráficos tipo painel, o Plotly é uma boa alternativa ao Matplotlib e ao Seaborn. Atualmente, está disponível para uso sob a licença MIT.
Você pode começar a dominar o Plotly hoje mesmo com este curso de visualização do Plotly.
⭐ GitHub Stars: 14,7 mil | Total de downloads: 190 milhões
Os termos machine learning e scikit-learn são inseparáveis. O Scikit-learn é uma das bibliotecas de machine learning mais usadas em Python. Feita com NumPy, SciPy e Matplotlib, é uma biblioteca Python de código aberto que pode ser usada comercialmente com a licença BSD. É uma ferramenta simples e eficiente para tarefas de análise preditiva de dados.
Lançado inicialmente em 2007 como um projeto do Google Summer of Code, o Scikit-learn é um projeto comunitário; no entanto, subsídios institucionais e privados ajudam a garantir sua sustentabilidade.
A melhor coisa sobre o scikit-learn é que ele é super fácil de usar.
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
# Load the diabetes dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)Crédito: Código copiado da documentação oficial do scikit-learn.
Você pode experimentar o scikit-learn por conta própria com este tutorial introdutório ao scikit-learn.
⭐ GitHub Stars: 57K | Total de downloads: 703 milhões
Já se foram os dias em que os cientistas de dados só entregavam relatórios PDF estáticos. O Streamlit transforma scripts Python em aplicativos web interativos e compartilháveis em poucos minutos. Não precisa saber nada de HTML, CSS ou JavaScript. É muito usado em 2025 pra criar ferramentas internas, protótipos de painéis e demonstrações de modelos interativos pra quem está interessado.
Com chamadas simples de API como st.write() e st.slider(), você pode criar um front-end que reage às mudanças de dados em tempo real, fazendo a ponte entre a análise e a engenharia.
⭐ GitHub Stars: Mais de 42 mil | Status: Essencial para a entrega
Originalmente uma ferramenta de desenvolvimento web, o Pydantic agora é um dos pilares da pilha de IA. Ele faz a validação de dados e gerencia as configurações usando anotações de tipo Python. Na era dos LLMs, é super importante garantir que os dados (e os resultados dos modelos) correspondam exatamente a um esquema específico.
O Pydantic é o motor que alimenta bibliotecas como LangChain e Hugging Face, garantindo que as saídas JSON confusas dos modelos de IA sejam transformadas em objetos Python estruturados e válidos que não vão danificar seu código downstream.
⭐ GitHub Stars: Mais de 26 mil | Status: Infraestrutura crítica
O LightGBM é uma biblioteca de código aberto super popular que usa algoritmos baseados em árvores para aumentar o gradiente. Tem as seguintes vantagens:
Pode ser usado tanto para tarefas de classificação supervisionada quanto para tarefas de regressão. Você pode conferir a documentação oficial ou o GitHub deles para saber mais sobre essa incrível estrutura.
⭐ GitHub Stars: 15,8 mil | Total de downloads: 162 milhões
O XGBoost é outra biblioteca de reforço de gradiente distribuído muito usada, criada para ser portátil, flexível e eficiente. Permite a implementação de algoritmos de machine learning dentro da estrutura de reforço de gradiente. O XGBoost oferece árvores de decisão com reforço de gradiente (GBDT), um reforço paralelo de árvores que dá soluções rápidas e precisas para muitos problemas de ciência de dados. O mesmo código funciona nos principais ambientes distribuídos (Hadoop, SGE, MPI) e pode resolver vários problemas.
O XGBoost ficou bem popular nos últimos anos porque ajudou pessoas e equipes a ganhar praticamente todas as competições de dados estruturados do Kaggle. As vantagens do XGBoost incluem:
O XGBoost foi desenvolvido e é mantido por membros ativos da comunidade e está licenciado para uso sob a licença Apache. Este tutorial do XGBoost é um ótimo recurso se você quiser saber mais.
⭐ GitHub Stars: 25,2 mil | Total de downloads: 179 milhões
Catboost é uma biblioteca rápida, escalável e de alto desempenho para reforço de gradiente em árvores de decisão, usada para classificação, regressão e outras tarefas de machine learning para Python, R, Java e C++. Ele suporta cálculos em CPU e GPU.
Como sucessor do algoritmo MatrixNet, é muito usado para tarefas de classificação, previsão e recomendações. Graças ao seu caráter universal, pode ser aplicado em uma ampla gama de áreas e a uma variedade de problemas.
As vantagens do CatBoost, de acordo com o repositório deles, são:
⭐ GitHub Stars: 7,5 mil | Total de downloads: 53 milhões
O Statsmodels oferece classes e funções que permitem aos usuários estimar vários modelos estatísticos, fazer testes estatísticos e explorar dados estatísticos. Depois, aparece uma lista completa de estatísticas de resultados para cada estimador. A precisão dos resultados pode então ser testada em relação aos pacotes estatísticos existentes.
A maioria dos resultados dos testes na biblioteca foi verificada com pelo menos um outro pacote estatístico: R, Stata ou SAS. Algumas características do statsmodels são:
Este curso introdutório sobre modelos estatísticos é um excelente ponto de partida se você quiser aprender mais.
⭐ GitHub Stars: 9,2 mil | Total de downloads: 161 milhões
O conjunto de bibliotecas de software de código aberto RAPIDS executa pipelines completos de ciência de dados e análise inteiramente em GPUs. Ele se adapta perfeitamente desde estações de trabalho com GPU até servidores com várias GPUs e clusters com vários nós com o Dask. O projeto tem o apoio da NVIDIA e também conta com o Numba, o Apache Arrow e vários outros projetos de código aberto.
O cuDF é uma biblioteca GPU DataFrame usada para carregar, juntar, agregar, filtrar e manipular dados. Foi desenvolvido com base no formato de memória colunar encontrado no Apache Arrow. Ele oferece uma API parecida com a do pandas, que os engenheiros e cientistas de dados já conhecem, o que permite que eles acelerem seus fluxos de trabalho sem precisar se preocupar com os detalhes da programação CUDA.
O cuML é um conjunto de bibliotecas que implementa algoritmos de machine learning e funções matemáticas primitivas que compartilham APIs compatíveis com outros projetos RAPIDS. Isso permite que cientistas de dados, pesquisadores e engenheiros de software executem tarefas tradicionais de ML tabular em GPUs sem se aprofundar nos detalhes da programação CUDA. A API Python do cuML geralmente corresponde à API scikit-learn.
Essa estrutura de otimização de hiperparâmetros de código aberto é usada principalmente para automatizar pesquisas de hiperparâmetros. Ele usa loops, condicionais e sintaxe Python pra procurar automaticamente os hiperparâmetros ideais e pode pesquisar em espaços grandes e eliminar tentativas sem futuro pra resultados mais rápidos. O melhor de tudo é que é fácil fazer a paralelização e a escalabilidade em grandes conjuntos de dados.
Principais recursos, de acordo com o repositório GitHub:
⭐ GitHub Stars: 9,1 mil | Total de downloads: 18 milhões
Essa biblioteca de machine learning de código aberto super popular automatiza fluxos de trabalho de machine learning em Python usando pouquíssimo código. É uma ferramenta completa para gerenciamento de modelos e machine learning que pode acelerar bastante o ciclo de experimentos.
Comparado com outras bibliotecas de machine learning de código aberto, o PyCaret oferece uma solução de baixo código que pode substituir centenas de linhas de código por apenas algumas. Isso torna as experiências exponencialmente rápidas e eficientes.
O PyCaret está disponível para uso sob a licença MIT. Pra saber mais sobre o PyCaret, dá uma olhada na documentação oficial ou no repositório GitHub deles, ou confere esse tutorial introdutório do PyCaret.
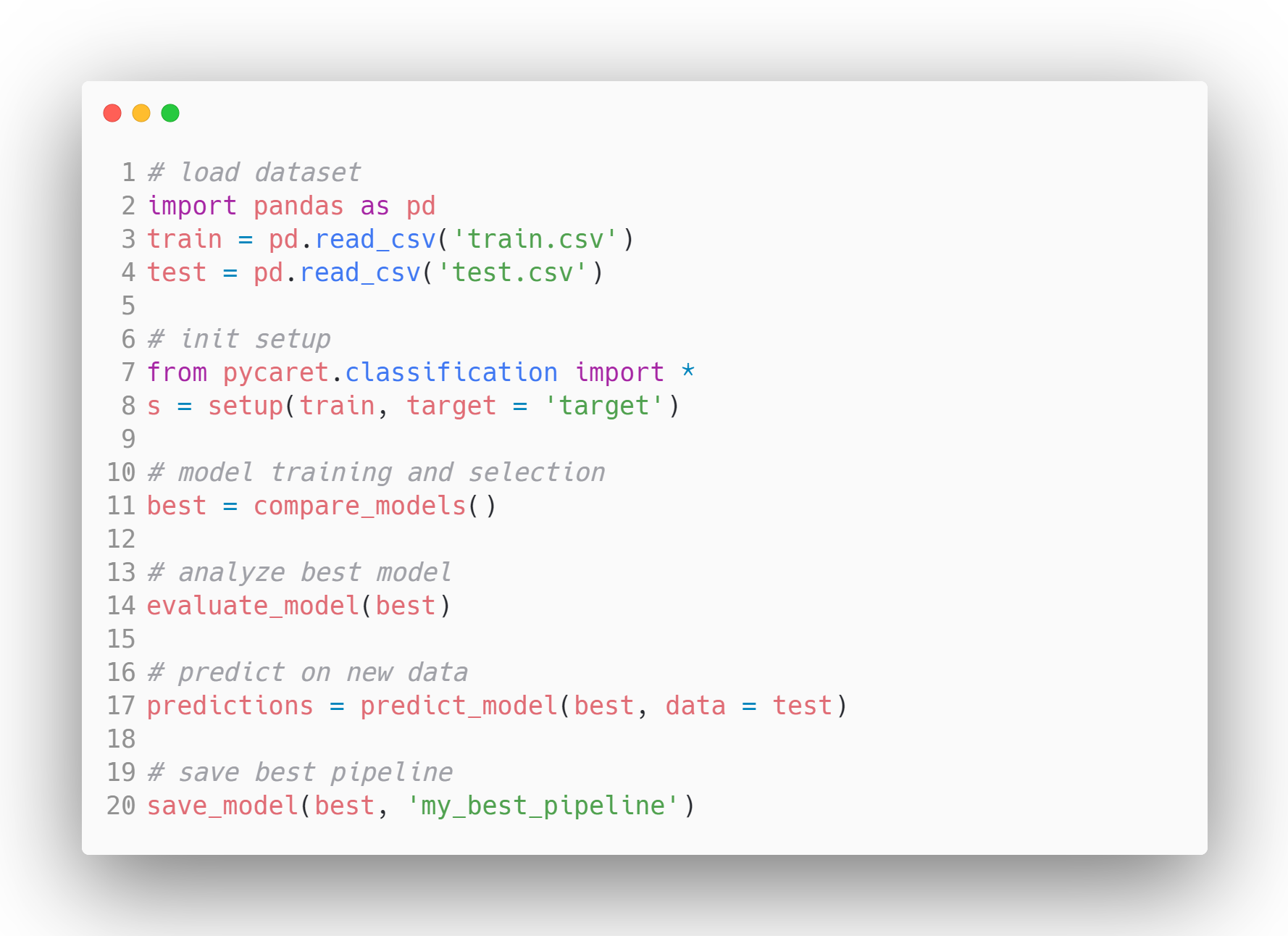
Exemplo de fluxo de trabalho do modelo em PyCaret - Fonte
⭐ GitHub Stars: 8,1 mil | Total de downloads: 3,9 milhões
H2O é uma plataforma de machine learning e análise preditiva que permite a construção de modelos de machine learning em big data. Ele também facilita a produção desses modelos em um ambiente empresarial.
O código principal do H2O é escrito em Java. Os algoritmos usam a estrutura Java Fork/Join para multithreading e são implementados sobre a estrutura distribuída Map/Reduce da H2O.
O H2O é licenciado sob a Licença Apache, Versão 2.0, e está disponível para as linguagens Python, R e Java. Para saber mais sobre o H2O AutoML, dá uma olhada na documentação oficial deles.
⭐ GitHub Stars: 10,6 mil | Total de downloads: 15,1 milhões
O Auto-sklearn é um kit de ferramentas de machine learning automatizado e um substituto legal para o modelo scikit-learn. Ele faz o ajuste de hiperparâmetros e a seleção de algoritmos automaticamente, economizando um tempão para quem trabalha com machine learning. Seu design mostra os avanços recentes em metaaprendizagem, construção de conjuntos e otimização bayesiana.
Criado como um complemento para o scikit-learn, o auto-sklearn usa um procedimento de pesquisa de otimização bayesiana para identificar o pipeline de modelos com melhor desempenho para um determinado conjunto de dados.
É super fácil usar o auto-sklearn, e ele pode ser usado tanto para tarefas de classificação supervisionada quanto para tarefas de regressão.
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)Fonte: Exemplo tirado da documentação oficial do auto-sklearn.
Pra saber mais sobre o auto-sklearn, dá uma olhada no repositório GitHub deles.
⭐ GitHub Stars: 7,3 mil | Total de downloads: 675K
FLAML é uma biblioteca leve de Python que identifica automaticamente modelos precisos de machine learning. Ele escolhe os alunos e os hiperparâmetros automaticamente, economizando um monte de tempo e esforço para quem trabalha com machine learning. De acordo com o repositório GitHub, algumas funcionalidades do FLAML são:
Com só três linhas de código, você consegue um estimador no estilo scikit-learn com esse motor AutoML rápido.
from flaml import AutoML
automl = AutoML()
automl.fit(X_train, y_train, task="classification")Fonte: Exemplo tirado do repositório oficial do GitHub
⭐ GitHub Stars: 3,5 mil | Total de downloads: 456K
Enquanto outras bibliotecas AutoML se concentram na velocidade, o AutoGluon (desenvolvido pela Amazon) se concentra na robustez e na precisão de ponta. É famoso pela sua estratégia de “montagem em camadas múltiplas”, que muitas vezes permite superar os modelos ajustados por humanos em benchmarks de dados tabulares.
Ele suporta não só dados tabulares, mas também problemas multimodais. Isso quer dizer que você pode treinar um único preditor em um conjunto de dados com colunas de texto, imagens e números ao mesmo tempo, sem precisar fazer engenharia de recursos complicada.
O trecho de código a seguir mostra a sintaxe do AutoGluon:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='class').fit(train_data)
# AutoGluon automatically trains, tunes, and ensembles multiple models⭐ GitHub Stars: Mais de 10 mil | Status: Precisão de primeira
O TensorFlow é uma biblioteca de código aberto super popular para cálculos numéricos de alto desempenho, desenvolvida pela equipe Google Brain do Google, e é um dos pilares na área de pesquisa de aprendizado profundo.
Como tá no site oficial, o TensorFlow é uma plataforma de código aberto completa pra machine learning. Oferece uma ampla e versátil variedade de ferramentas, bibliotecas e recursos comunitários para pesquisadores e desenvolvedores de machine learning.
Algumas das características do TensorFlow que o tornaram uma biblioteca de deep learning popular e amplamente utilizada:
Pra saber mais sobre o TensorFlow, dá uma olhada no guia oficial deles ou no repositório GitHub, ou tenta usar você mesmo seguindo este tutorial passo a passo do TensorFlow.
⭐ GitHub Stars: 180 mil | Total de downloads: 384 milhões
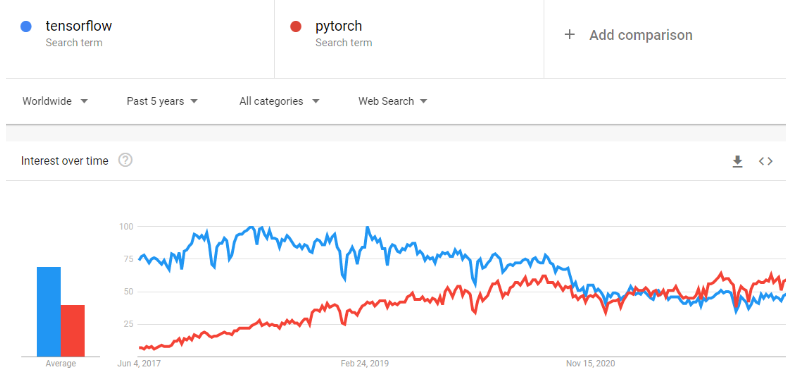
O PyTorch é uma estrutura de machine learning que acelera bastante a jornada desde a prototipagem da pesquisa até a implantação da produção. É uma biblioteca de tensores otimizada para aprendizado profundo usando GPUs e CPUs, e é vista como uma alternativa ao TensorFlow. Com o tempo, a popularidade do PyTorch cresceu e passou o TensorFlow nas tendências do Google.
Foi desenvolvido e é mantido pelo Facebook e está atualmente disponível para uso sob a licença BSD.
De acordo com o site oficial, as principais características do PyTorch são:
⭐ GitHub Stars: 74K | Total de downloads: 119 milhões
FastAI é uma biblioteca de deep learning que oferece aos usuários componentes de alto nível que podem gerar resultados de última geração sem esforço. Também inclui componentes de baixo nível que podem ser trocados para desenvolver novas abordagens. O objetivo é fazer essas duas coisas sem comprometer muito a facilidade de uso, a flexibilidade ou o desempenho.
Características:
Pra saber mais sobre o projeto, dá uma olhada na documentação oficial deles.
⭐ GitHub Stars: 25,1 mil | Total de downloads: 6,1 milhões
Keras é uma API de deep learning feita para pessoas, não para máquinas. O Keras segue as melhores práticas para reduzir a carga cognitiva: oferece APIs consistentes e simples, minimiza o número de ações do usuário necessárias para casos de uso comuns e fornece mensagens de erro claras e acionáveis. O Keras é tão intuitivo que o TensorFlow adotou o Keras como sua API padrão na versão TF 2.0.
O Keras oferece um jeito mais simples de expressar redes neurais e também inclui algumas das melhores ferramentas para desenvolver modelos, processar conjuntos de dados, visualizar gráficos e muito mais.
Características:
Pra saber mais sobre o Keras, dá uma olhada na documentação oficial deles ou faz esse curso introdutório: Aprendizado profundo com Keras.
⭐ GitHub Stars: 60,2 mil | Total de downloads: 163 milhões
O PyTorch Lightning oferece uma interface de alto nível para o PyTorch. Sua estrutura leve e de alto desempenho pode organizar o código PyTorch para separar a pesquisa da engenharia, tornando os experimentos de deep learning mais fáceis de entender e reproduzir. Foi desenvolvido para criar modelos de deep learning escaláveis que podem ser executados perfeitamente em hardware distribuído.
De acordo com o site oficial, o PyTorch Lightning foi feito pra você poder dedicar mais tempo à pesquisa e menos à engenharia. Uma refatoração rápida vai te ajudar a:
Pra saber mais sobre essa biblioteca, dá uma olhada no site oficial dela.
⭐ GitHub Stars: 25,6 mil | Total de downloads: 18,2 milhões
JAX é uma biblioteca de computação numérica de alto desempenho desenvolvida pelo Google. Enquanto o PyTorch é o padrão fácil de usar, o JAX é o “carro de Fórmula 1” usado por pesquisadores (incluindo a DeepMind) que precisam de velocidade extrema. Permite que o código NumPy seja compilado automaticamente para rodar em aceleradores (GPUs/TPUs) via XLA (Algebra Linear Acelerada).
A capacidade de fazer diferenciação automática em funções nativas do Python faz dele um dos favoritos para desenvolver novos algoritmos do zero, principalmente em modelagem generativa e simulações físicas.
⭐ GitHub Stars: Mais de 35 mil | Status: Padrão de pesquisa
O spaCy é uma biblioteca de processamento de linguagem natural de código aberto e de nível industrial em Python. O spaCy é ótimo para tarefas de extração de informações em grande escala. Foi escrito do zero em Cython, com gerenciamento cuidadoso da memória. O spaCy é a biblioteca ideal para usar se o seu aplicativo precisa processar grandes volumes de dados da web.
Características:
Pra saber mais sobre o spaCy, dá uma olhada no site oficial deles ou no repositório GitHub. Você também pode se familiarizar rapidamente com as funcionalidades usando esta prática folha de dicas do spaCY.
⭐ GitHub Stars: 28K | Total de downloads: 81 milhões
Hugging Face Transformers é uma biblioteca de código aberto da Hugging Face. Os transformadores permitem que as APIs baixem e treinem facilmente modelos pré-treinados de última geração. Usar modelos pré-treinados pode reduzir seus custos de computação, pegada de carbono e economizar tempo, já que você não precisa treinar um modelo do zero. Os modelos são adequados para uma variedade de modalidades, incluindo:
A biblioteca de transformadores dá suporte à integração perfeita entre três das bibliotecas de deep learning mais populares: PyTorch, TensorFlow e JAX. Você pode treinar seu modelo em três linhas de código em uma estrutura e carregá-lo para inferência com outra. A arquitetura de cada transformador é definida dentro de um módulo Python independente, tornando-os facilmente personalizáveis para experimentos e pesquisas.
A biblioteca está disponível para uso sob a Licença Apache 2.0.
Pra saber mais sobre transformadores, dá uma olhada no site oficial deles ou no repositório GitHub e confere nosso tutorial sobre como usar Transformers e Hugging Face.
⭐ GitHub Stars: 119K | Total de downloads: 62 milhões
LangChain é a estrutura de orquestração padrão da indústria para Modelos de Linguagem de Grande Porte (LLMs). Isso permite que os desenvolvedores “encadeiem” diferentes componentes, por exemplo, conectando um LLM (como o GPT 5.2) a outras fontes de computação ou conhecimento.
Ele simplifica a complexidade de trabalhar com prompts, permitindo que você crie facilmente “Agentes” que podem usar ferramentas (como uma calculadora, Pesquisa Google ou um REPL Python) para resolver problemas de raciocínio com várias etapas.
from langchain.chains import LLMChain
# Example: Creating a chain that takes user input and formats it
# before sending to an LLM
chain = prompt | llm | output_parser
result = chain.invoke({"topic": "Data Science"})⭐ GitHub Stars: 123 mil+ | Status: GenAI Essential
Enquanto o LangChain cuida do raciocínio, o LlamaIndex cuida dos dados. É a estrutura líder para RAG (Geração Aumentada por Recuperação). É especialista em pegar, indexar e recuperar seus dados pessoais (PDFs, bancos de dados SQL, planilhas Excel) para que os LLMs possam responder perguntas sobre eles com precisão.
Em 2025, “conversar com seus documentos” é um requisito padrão nos negócios, e o LlamaIndex oferece estruturas de dados otimizadas para tornar isso eficiente e sem alucinações.
⭐ GitHub Stars: Mais de 35 mil | Status: Padrão RAG
Para fazer com que os LLMs “lembrem” as informações, você precisa de um banco de dados vetorial. O ChromaDB é um banco de dados vetorial de código aberto e nativo de IA que virou o padrão para desenvolvedores Python. Ele lida com a complexidade de incorporar texto (transformar palavras em listas de números) e armazená-las para pesquisa semântica.
Diferente dos bancos de dados SQL tradicionais que procuram palavras-chave exatas, o ChromaDB te deixa fazer consultas por significado, o que o torna o backend de memória de longo prazo para aplicativos modernos de IA.
⭐ GitHub Stars: Mais de 25 mil | Status: Padrão de armazenamento de vetores
Escolher a biblioteca Python certa para suas tarefas de ciência de dados, machine learning ou processamento de linguagem natural é uma decisão importante que pode afetar bastante o sucesso dos seus projetos. Com uma grande variedade de bibliotecas disponíveis, é essencial pensar em vários fatores para fazer uma escolha certa. Aqui estão algumas considerações importantes para te ajudar:
Ao avaliar cuidadosamente esses fatores, você pode tomar uma decisão informada ao escolher bibliotecas Python para seus projetos de ciência de dados ou machine learning. Lembre-se de que a melhor biblioteca para o seu projeto depende dos requisitos específicos e dos objetivos que você quer alcançar.
Para dar o pontapé inicial na sua carreira em ciência de dados, siga o programa de Cientista de Dados em Python.
Cursos sobre bibliotecas Python en DataCamp
Curso
Curso
Curso
blog
Bekhruz Tuychiev
15 min
blog
Thaylise Nakamoto
9 min
blog
Abid Ali Awan
9 min
blog
Yuliya Melnik
15 min
Tutorial
Adel Nehme
Tutorial
Abid Ali Awan

