
Programa
Fundamentos de agentes de IA
6 h
In this section, we'll take a raw CSV of monthly sales (dummy) data and produce a complete interactive HTML dashboard without writing any code or defining any subagent instructions.
Start by installing Antigravity CLI by running a bash command. Antigravity CLI is available for multiple OS, including:
macOS and Linux
curl -fsSL https://antigravity.google/cli/install.sh | bash
Windows PowerShell
irm https://antigravity.google/cli/install.ps1 | iexWindows CMD
curl -fsSL https://antigravity.google/cli/install.cmd -o install.cmd && install.cmd && del install.cmdOnce installed, run antigravity using the following command in your terminal:
agyThen, authenticate with a Google account or a GCP Project. It will provide you with a secret key, which you add to your terminal running antigravity, and authentication will be completed.
Then set up your terminal theme accordingly and provide it access to the required files, and you are all set.
The CLI identifies itself as Antigravity CLI 1.0.0 and connects to Gemini 3.5 Flash (High) by default.
You can do this step yourself or simply ask Antigravity CLI to do it for you:
mkdir AntigravityDemo
cd AntigravityDemoThat's your entire project setup. No subdirectories, no config files, no agent definitions needed.
Save the following dummy data as sales_raw.csv directly in your AntigravityDemo folder, or use data of your choice. It intentionally includes realistic data quality issues like missing values and a $999,999 outlier placeholder, so the subagents have something meaningful to work with.
month,product,region,revenue,units_sold
2024-01,Laptop Pro,North,45200,38
2024-01,Wireless Earbuds,South,12300,205
2024-01,Mechanical Keyboard,East,8900,89
2024-02,Laptop Pro,North,47800,40
2024-02,Wireless Earbuds,South,,198
2024-02,Mechanical Keyboard,East,9100,91
2024-03,Laptop Pro,North,51200,43
2024-03,Wireless Earbuds,South,13100,218
2024-03,Mechanical Keyboard,East,,
2024-04,Laptop Pro,North,999999,42
2024-04,Wireless Earbuds,South,13800,230
2024-04,Mechanical Keyboard,East,9600,96
2024-05,Laptop Pro,North,55100,46
2024-05,Wireless Earbuds,South,14200,237
2024-05,Mechanical Keyboard,East,10100,101
2024-06,Laptop Pro,North,57300,48
2024-06,Wireless Earbuds,South,14900,248
2024-06,Mechanical Keyboard,East,10500,105Once you add this CSV file to your working directory, we can begin working within the CLI.
With your working directory primed and the sales_raw.csv dataset in place, you’re ready to invoke the Antigravity CLI orchestrator to manage the end-to-end analytical workflow. Open a terminal and run the following command:
agy
Next, let’s ask Gemini to clean, analyze, and visualize our data:
/goal I have a sales dataset at /Users/yourname/Desktop/AntigravityDemo/sales_raw.csv.
Spin up multiple subagents to clean, analyze, and visualize it.
Produce a final HTML report and save all outputs in this folder.The /goal prefix is important here as it tells the CLI to run the entire task to completion without pausing for plan approval or intermediate confirmations. Without it, the agent stops and asks, "Do you want to proceed?" before each significant step.
The autonomous workflow is immediately initiated by the orchestrator. Here are 5 detailed breakdowns of the different stages captured from profiling to assembly:
The orchestrator started by understanding its environment before writing a single line of code:
ListPermissions (confirmed read and write access to the workspace)
ListDir (/Users/aashidutt/Desktop/AntigravityDemo)
Read (sales_raw.csv)
Thought for 3s, 1.5k tokens — Analyzing Data Quality Issues
Bash (python3 --version)
Bash (python3 -c "import pandas, matplotlib, seaborn...")
Thought for 4s, 463 tokens — Initiating Implementation PlanningIt listed permissions, read the directory, loaded the CSV, checked Python was available, and verified the required libraries, all before planning anything. This upfront profiling allows the orchestrator to make informed decisions about subagent roles rather than planning blindly.
Note on permission prompt: Even with /goal, the CLI prompted for a one-time permission before running any bash commands. This is Antigravity's human-in-the-loop safety model. You approve once for a class of operation, and it doesn't ask again. It's a deliberate design choice that keeps automation from feeling like a black box and is especially useful in production contexts.
The orchestrator then created an internal implementation plan and defined three subagents:
Create (implementation_plan.md → written to ~/.gemini/ant.../ scratch folder)
DefineSubagent ("data_cleaner" defined successfully)
DefineSubagent ("data_analyzer" defined successfully)
DefineSubagent ("data_visualizer" defined successfully)The implementation_plan.mdfile gets written to an internal .gemini scratch directory, not your project folder. It's the CLI's own planning artifact, so you don't need to read or manage it. When you use /goal, it gets auto-approved, and execution continues immediately.
The three subagent names data_cleaner, data_analyzer, and data_visualizer were derived entirely by the CLI from your goal description.
The first subagent was dispatched to fix data quality issues, which imputed the two missing revenue values and the missing units_sold using product medians, then identified the $999,999 April Laptop Pro entry as a system placeholder (as expected), replacing it with $50,106 (median unit price $1,193 × 42 units), and restoring statistical accuracy before passing the cleaned data downstream.
The moment sales_clean.csv was finalized, the orchestrator immediately dispatched both remaining subagents simultaneously. The analyzer computed MoM growth rates, product breakdowns, and regional summaries, saving to analysis_summary.json, while the visualizer generated three chart PNGs concurrently. The orchestrator monitored both and reported their state in real time.

Note: When prompted to review the implementation plan or an artifact, you can use the /artifact command to open the artifact folder and review the content, or you can trust the model and run it by default.
With all subagents complete, the orchestrator spent 12 seconds of deliberate reasoning to confirm all files were present before assembling the final dashboard. The result was a fully self-contained HTML file requiring no external dependencies.
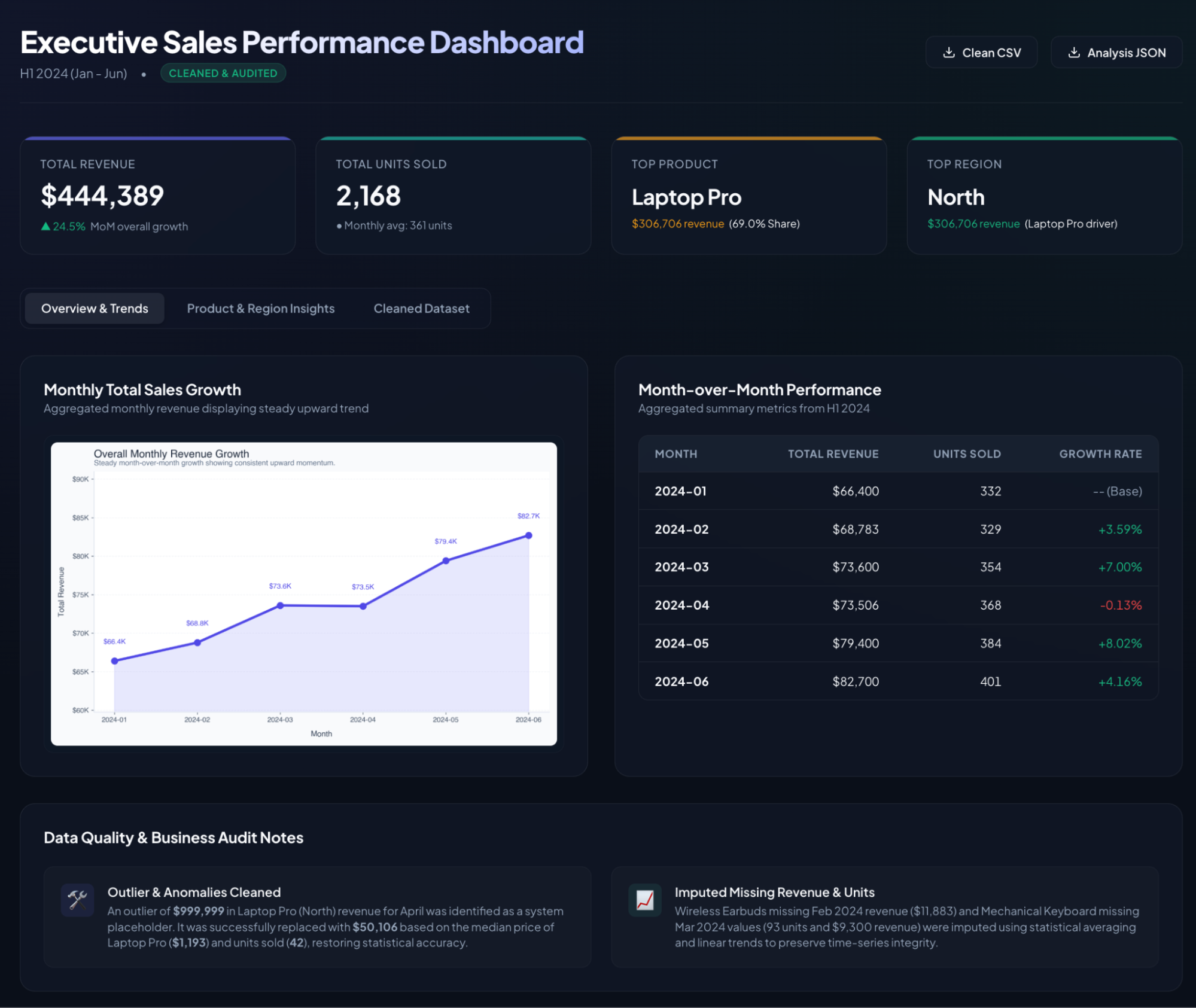
The generated dashboard isn't a static page; it's a production-grade interactive UI. Its key features include:
In this tutorial, we ran a complete multi-agent data pipeline using the Antigravity CLI in under five minutes. The orchestrator profiled the raw CSV, autonomously defined three subagents, ran two of them in parallel once the clean data was ready, and assembled a fully self-contained HTML report with tabbed navigation, KPI cards, and sortable data tables.
The subagent architecture isn't just a performance optimization; it's a design pattern that maps naturally to how complex analytical work gets done. It spins specialized agents working in parallel, each focused on what they do best, with an orchestrator synthesizing the final result. The same pattern extends well beyond data analysis into document processing, code review pipelines, research aggregation, and more.
To take this further, here are some ideas:
/schedule command to your prompt in the Antigravity 2.0 desktop app, and the pipeline re-runs automatically on a refreshed CSV every time as per your schedule./grill-me for more control if you want the CLI to ask clarifying questions before starting, and prepend /grill-me to your prompt instead of /goal.Top Agentic AI Courses
Programa
Curso
Curso
blog
Khalid Abdelaty
15 min
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Khalid Abdelaty
Tutorial
Aashi Dutt
