
Course
Introduction to Statistics in Google Sheets
4 hr
47K
Hypothesis testing is a key part of statistics that helps you make informed decisions in a wide range of fields- everything from medicine to economics to social sciences. This guide will walk you through the core concepts, types, steps, and real-world applications of hypothesis testing, ensuring you can confidently interpret and present your statistical findings.
If you're ready to learn more about hypothesis testing, select the course that matches your preferred technology: Hypothesis Testing in Python, Hypothesis Testing in R, or Introduction to Statistics in Google Sheets. Also, take our Introduction to Statistics course, which is technology-agnostic.
Hypothesis testing is a statistical procedure used to test assumptions or hypotheses about a population parameter. It involves formulating a null hypothesis (H0) and an alternative hypothesis (Ha), collecting data, and determining whether the evidence is strong enough to reject the null hypothesis.
The primary purpose of hypothesis testing is to make inferences about a population based on a sample of data. It allows researchers and analysts to quantify the likelihood that observed differences or relationships in the data occurred by chance rather than reflecting a true effect in the population.
Let’s walk through how to do a hypothesis test, one step at a time.
The first step is to formulate your research question into two competing hypotheses:
For example:
Gather data through experiments, surveys, or observational studies. Ensure the data collection method is designed to test the hypothesis and is representative of the population. This step often involves:
Select a statistical test based on the type of data and the hypothesis. The choice depends on factors such as:
Common tests include:
t-tests (for comparing means)
chi-square tests (for categorical data)
ANOVA (for comparing means of multiple groups)
Use statistical software or formulas to compute the test statistic and corresponding p-value. This step quantifies how much the sample data deviates from the null hypothesis.
The p-value is an important concept in hypothesis testing. It represents the probability of observing results as extreme as the sample data, assuming the null hypothesis is true.
Compare the p-value to the predetermined significance level (α), which is typically set at 0.05. The decision rule is as follows:
It's important to note that failing to reject the null hypothesis doesn't prove it's true; it simply means there's not enough evidence to conclude otherwise.
Report the results, including the test statistic, p-value, and conclusion. Discuss whether the findings support the initial hypothesis and their implications. When presenting results, consider:
Hypothesis tests can be broadly categorized into two main types:
Parametric tests assume that the data follows a specific probability distribution, typically the normal distribution. These tests are generally more powerful when the assumptions are met. Common parametric tests include:
Non-parametric tests don't assume a specific distribution of the data. They are useful when dealing with ordinal data or when the assumptions of parametric tests are violated. Examples include:
When choosing a hypothesis test, researchers consider a few broad categories:
Based on these categories, you can select the appropriate statistical test. For instance, if your data is normally distributed and you have two independent groups with continuous data, you would use an Independent t-test. If your data is not normally distributed with two independent groups and ordinal data, a Mann-Whitney U test is recommended.
To help choose the appropriate test, consider using a hypothesis test flow chart as a general guide:
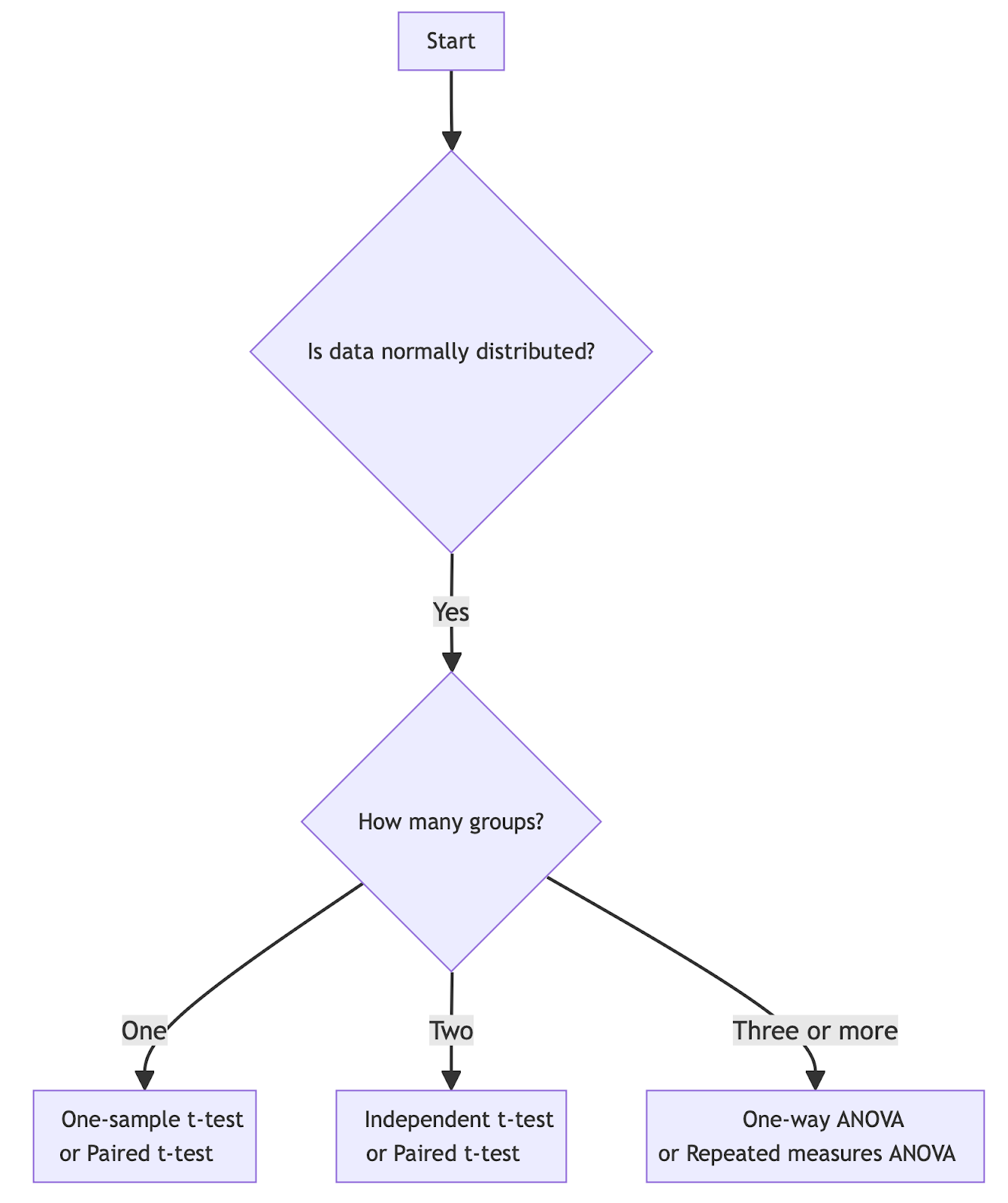
Choosing the right hypothesis test for normally distributed data. Image by Author.
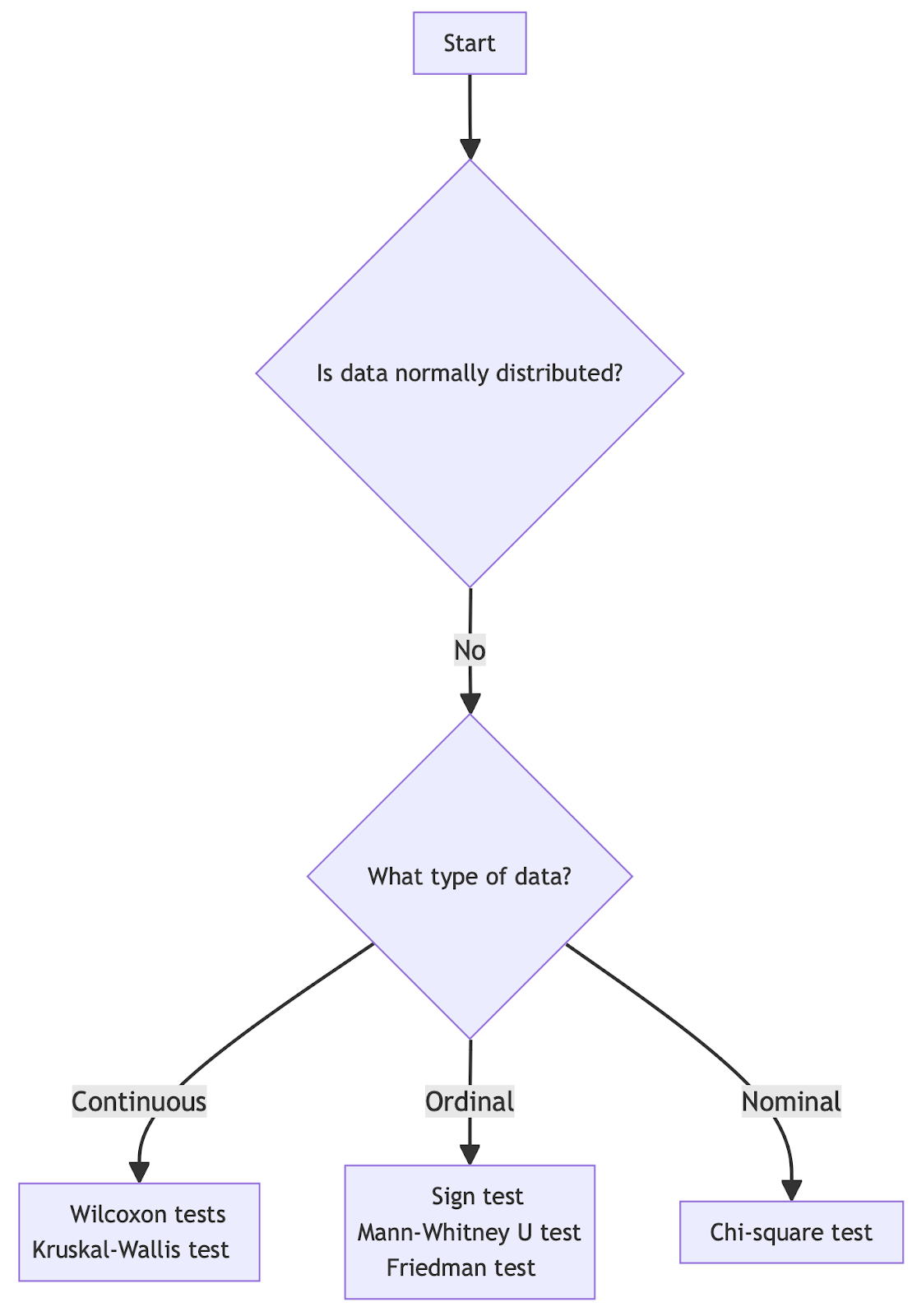
Choosing the right hypothesis test for non-normally distributed data. Image by Author.
In addition to traditional hypothesis testing methods, there are several modern approaches:
These tests involve randomly shuffling the observed data many times to create a distribution of possible outcomes under the null hypothesis. They are particularly useful when dealing with small sample sizes or when the assumptions of parametric tests are not met.
Bootstrapping is a resampling technique that involves repeatedly sampling with replacement from the original dataset. It can be used to estimate the sampling distribution of a statistic and construct confidence intervals.
Monte Carlo methods use repeated random sampling to obtain numerical results. In hypothesis testing, they can be used to estimate p-values for complex statistical models or when analytical solutions are difficult to obtain.
When conducting hypothesis tests, it's best to understand and control for potential errors:
The significance level (α) directly controls the probability of a Type I error. Decreasing α reduces the chance of Type I errors but increases the risk of Type II errors.
To balance these errors:
The file drawer effect refers to the publication bias where studies with significant results are more likely to be published than those with non-significant results. This can lead to an overestimation of effects in the literature. To mitigate this:
Remember that hypothesis testing is just one part of the statistical inference toolkit. Always consider the practical significance of your findings, not just statistical significance. As you gain experience, you'll develop an understanding of when and how to apply these techniques in various real-world scenarios.
To further enhance your statistical expertise, you might explore topics such as How to Become a Statistician in 2024, which offers insights into the evolving field and the skills needed for success. Additionally, practicing the Top 35 Statistics Interview Questions and Answers for 2024 and working through our Practicing Statistics Interview Questions in R course can help you sharpen your skills and prepare for interviews.
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Learn Hypothesis Testing with DataCamp
Course
Course
Course
blog
Richie Cotton
10 min
blog
Richie Cotton
6 min
Tutorial
Nishant Singh
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
code-along
Arne Warnke


