
Course
Preprocessing for Machine Learning in Python
4 hr
66.6K
Machine learning models have hyperparameters that significantly affect their performance. These parameters can be described as the right temperature to bake a cake or the right angle to flip a pancake. In reinforcement learning, hyperparameters affect the policy and reward approximations, and with better-tuned results, hyperparameter optimization can drastically improve the results.
This article will explore Optuna, a powerful open-source framework for optimizing hyperparameters. If you are new to the topic, consider starting with Understanding Machine Learning, which offers a no-code introduction. To practice while using Python, try our Machine Learning Fundamentals with Python course, which uses scikit-learn. Then, MLOps Concepts will help you understand how to transition machine learning models from local notebooks to production environments. Finally, try Preprocessing for Machine Learning in Python, a highly relevant course for this article because it teaches you to clean and prepare your data for machine learning models.
Optuna is an open-source tool for hyperparameter optimization framework for automating hyperparameter search. It can be used with any machine learning or deep learning framework. Some of the key capabilities of Optuna include:
Finding the optimal path. Source: Image by Author
Reinforcement learning (RL) combines machine learning and optimal control. It concerns how an intelligent agent should act in a dynamic environment to maximize its cumulative reward. Simply, reinforcement learning is about teaching an intelligent agent to make the most optimal decisions that maximize its rewards in an environment. The reward for any step it takes can be positive or negative as it approaches the desired destination.
Unlike machine learning, reinforcement learning algorithms make decisions to achieve the most optimal results, similar to the trial-and-error learning process that we use to achieve our goals. Deep reinforcement learning differs from reinforcement learning because it uses deep neural networks to approximate complex functions. We could also say that regular reinforcement learning focuses on more deterministic approaches, while deep reinforcement learning uses stochastic approaches.
In an environment, there can be many routes to reaching the destination. Given that compared with supervised learning, deep reinforcement learning is far more sensitive to the choice of hyper-parameters such as learning rate, gamma, number of steps, and so on.
Poor choice of hyper-parameters can lead to poor/unstable convergence. This challenge is compounded by the variability in performance across random seeds (used to initialize the network weights and the environment).
In this section, we will walk through the process of setting up Optuna and related dependencies, defining the search space, and running the optimization for the MountainCarContinuous-v0 algorithm. The MountainCarContinuous-v0 algorithm is one of the RL algorithms in RL-Zoo, a training framework that provides scripts for evaluating agents and plotting results. The MountainCarContinous-v0 algorithm models an environment where the agent (a car) tries to achieve its goal (reaching the flag).

Representation of the tuned MountainCarContinuous-v0 algorithm. Image by Author.
To get started, you need to:
After creating a new virtual environment, we install our packages. As a note, Optuna supports Python 3.7 or newer. If you would like to review setting up a virtual enviornment, read our Virtual Environment in Python tutorial.
pip install optunapip install stable-baselines3pip install sb3-contribWe will use the gym package to create the environment where the agent will perform actions.
from stable_baselines3.common.env_util import make_vec_envfrom stable_baselines3 import A2Cimport gymimport optunafrom optuna.pruners import MedianPrunerfrom optuna.samplers import TPESamplerfrom optuna.visualization import plot_optimization_history, plot_param_importancesfrom typing import Any, Dictimport torchimport torch.nn as nnprint(optuna.__version__)This project will use the MountainCarContinuous-v0 algorithm from Advantage Actor-Critic (A2C). Advantage Actor-Critic (A2C) - one of the Actor-Critic algorithms, is a hybrid architecture combining value-based (measures the reward for an action taken) and policy-based (control the agent actions) methods that help to stabilize the training by reducing the variance.
Let us set the configurations to be used in this task.
N_TRIALS = 100 # Maximum number of trialsN_JOBS = 1 # Number of jobs to run in parallelN_STARTUP_TRIALS = 5 # Stop random sampling after N_STARTUP_TRIALSN_EVALUATIONS = 2 # Number of evaluations during the trainingN_TIMESTEPS = 100000 # Training budgetEVAL_FREQ = int(N_TIMESTEPS / N_EVALUATIONS)N_EVAL_ENVS = 5N_EVAL_EPISODES = 10TIMEOUT = int(60 * 15) # 15 minutesENV_ID = "MountainCarContinuous-v0"DEFAULT_HYPERPARAMS = { "policy": "MlpPolicy", "env": ENV_ID,}We will suggest a range of values for the hyperparameters.
def a2c_hyper_params(trial: optuna.Trial) -> dict: """Sample A2C hyperparameters for Optuna trial.""" return { "learning_rate": trial.suggest_float("learning_rate", 1e-5, 1e-2), "gamma": trial.suggest_float("gamma", 0.9, 0.9999), "n_steps": trial.suggest_int("n_steps", 5, 2048), "ent_coef": trial.suggest_float("ent_coef", 1e-8, 1e-2), "vf_coef": trial.suggest_float("vf_coef", 0.1, 1.0), "max_grad_norm": trial.suggest_float("max_grad_norm", 0.3, 10) }A CallBack function TrialEvalCallback() was defined because we want to return the period evaluation results of the optimization tasks. Check the Google Colab notebook for the callback implementation.
def objective(trial: optuna.Trial) -> float: """ This will be used by Optuna to evaluate one set of hyperparameters at a time.Given a trial object, it will sample hyperparameters, evaluate it and report the result. :param trial: Optuna trial object :return: Mean episodic reward after training """ kwargs = DEFAULT_HYPERPARAMS.copy() # 1. Sample hyperparameters and update the keyword arguments kwargs.update(a2c_hyper_params(trial)) # 2. Create the RL model model = A2C(**kwargs) # 3. Create envs used for evaluation using make_vec_env, ENV_ID and N_EVAL_ENVS eval_envs = make_vec_env(ENV_ID, n_envs=N_EVAL_ENVS) # 4. Create the TrialEvalCallback callback eval_callback = TrialEvalCallback( eval_envs, trial, n_eval_episodes=N_EVAL_EPISODES, eval_freq=EVAL_FREQ, deterministic=True, verbose=0, ) nan_encountered = False try: # Train the model model.learn(N_TIMESTEPS, callback=eval_callback) except AssertionError as e: # Sometimes, random hyperparams can generate NaN print(e) nan_encountered = True finally: # Free memory model.env.close() eval_envs.close() # Tell the optimizer that the trial failed if nan_encountered: return float("nan") if eval_callback.is_pruned: raise optuna.exceptions.TrialPruned() return eval_callback.last_mean_rewardPruning refers to cutting back on parameters or regions of the search space that are less likely to give an optimal result, and in this case, pruning after a specific budget. In Optuna, pruning removes trials that perform worse at the early stages of the training. This cuts down the set of parameters and the time to reach the optimal search space. Optuna has a couple of pruners, including the Median Pruner, which uses the median stopping rule. You can read more about Optuna Pruners from the Optuna documentation.
The Median Pruner algorithm prunes if the current best result is worse than the median of previous results. The division by three is used because we only want to prune after 1/3 of the maximum budget is used.
pruner = MedianPruner(n_startup_trials=N_STARTUP_TRIALS, n_warmup_steps=N_EVALUATIONS // 3)Select the sampler, which can be random, TPESampler, CMAES, etc.
sampler = TPESampler(n_startup_trials=N_STARTUP_TRIALS)We are now ready to create an Optuna study.
study = optuna.create_study(sampler=sampler, pruner=pruner, direction="maximize")try:study.optimize(objective, n_trials=N_TRIALS, n_jobs=N_JOBS, timeout=TIMEOUT)except KeyboardInterrupt: passprint("Number of finished trials: ", len(study.trials))print("Best trial:")trial = study.best_trialprint(f" Value: {trial.value}")print(" Params: ")for key, value in trial.params.items(): print(f" {key}: {value}")print(" User attrs:")for key, value in trial.user_attrs.items(): print(f" {key}: {value}")Let’s take a look at some of Optuna’s more advanced features.
Optuna provides a dashboard that allows us to visualize, track, and analyze previous and current runs. In the past, you might have had to connect your tracking tool, like MLFlow, to manage the results.
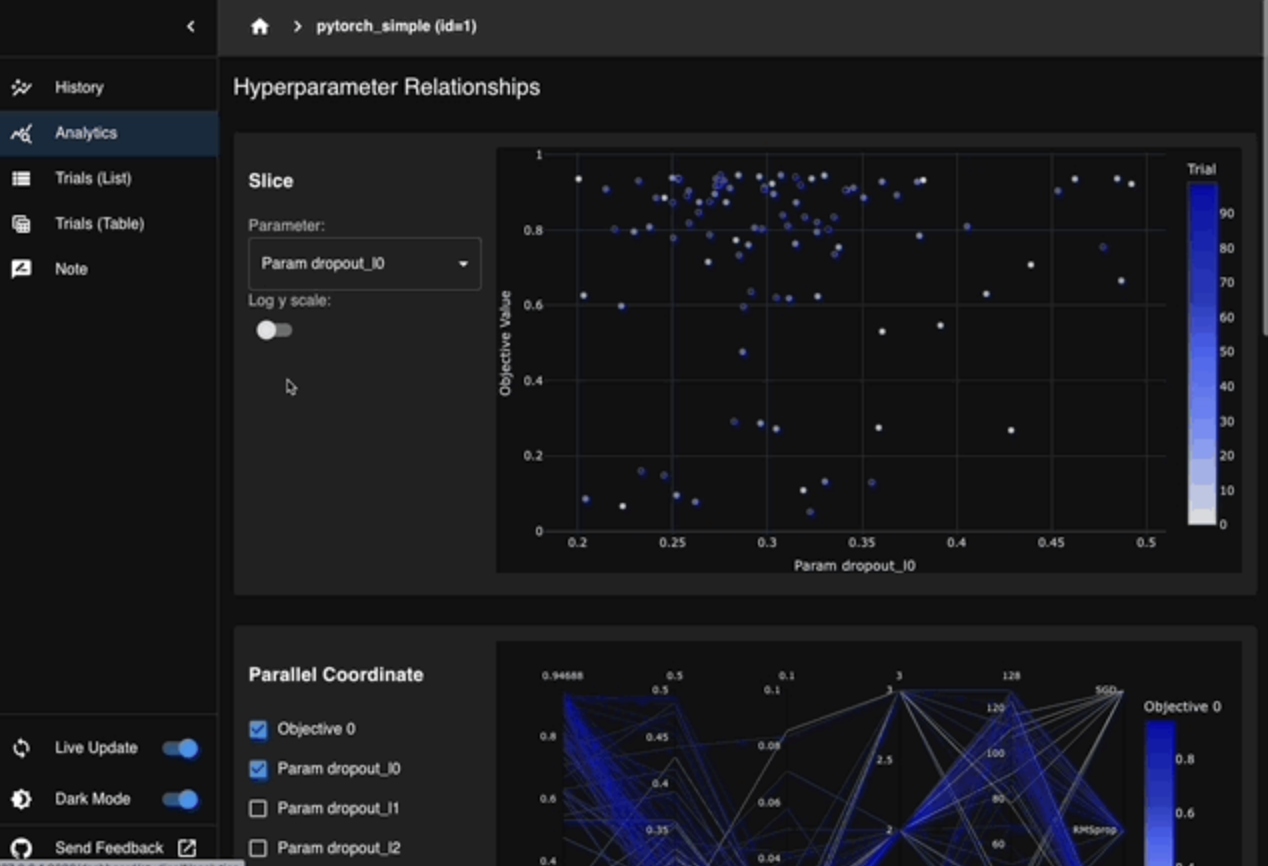
Optuna Dashboard. Source: Optuna
Optuna's support for distributed training allows you to connect your distributed backend, like Kubernetes or Dask, to leverage more compute resources for large-scale experiments. You can also connect your storage backend to store and manage your session's results. You can use cloud storage like Dask storage or SQLite for local runs.
Here are some tips to avoid common pitfalls in hyperparameter tuning:
Learn Machine Learning with DataCamp
Course
Course
Course
Tutorial
Zoumana Keita
Tutorial
Sayak Paul
Tutorial
Karlijn Willems
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
code-along
Folkert Stijnman

