
Course
Building AI Agents with Google ADK
1 hr
6.5K
Qwen3-Coder is an advanced agentic code model designed to empower developers with enhanced capabilities for code generation and automation. It is available in multiple sizes, with the flagship release being the Qwen3-Coder-480B-A35B-Instruct.
This 480-billion-parameter Mixture-of-Experts model features 35 billion active parameters and sets a new standard for open-source code models. It delivers state-of-the-art performance in Agentic Coding, Agentic Browser Use, and foundational coding tasks, with results comparable to leading models like Claude Sonnet.
In this tutorial, we will learn how to run Qwen3-Coder locally, use it with Msty chat applications, integrate it with the VSCode Copilot, set up the Kilo Code extension for advanced agentic code workflows, and finally, use the Python framework to integrate it into a local application.
You can check out our separate guides to Qwen3 and Qwen Code CLI to learn more.
Ollama has seen significant improvements in recent months, now offering a user-friendly chat application similar to ChatGPT. With the new app, you can easily download and run AI models directly from the graphical interface, making local AI more accessible than ever.
Source: Ollama's new app
For Windows and macOS: Visit the download page and download the installer for your operating system. The installation process is straightforward; just follow the prompts to get started.
Source: Download Ollama
For Linux: Open your terminal and run the following command. This command will automatically download and install Ollama on your system.
curl -fsSL https://ollama.com/install.sh | sh If you see a message about the GPU not being detected, you’ll need to install a couple of system utilities:
sudo apt update
sudo apt install -y pciutils lshwFor NVIDIA GPU support, install the driver and CUDA toolkit:
sudo apt install -y nvidia-driver-525 nvidia-cuda-toolkitOnce installed, you can launch the Ollama app and start downloading models or chatting directly from the UI. This makes it easy to experiment with local AI models, whether you are on Windows, macOS, or Linux.
To get started with Qwen3-Coder, head to the Models tab on the Ollama website and search for “qwen3-coder”.
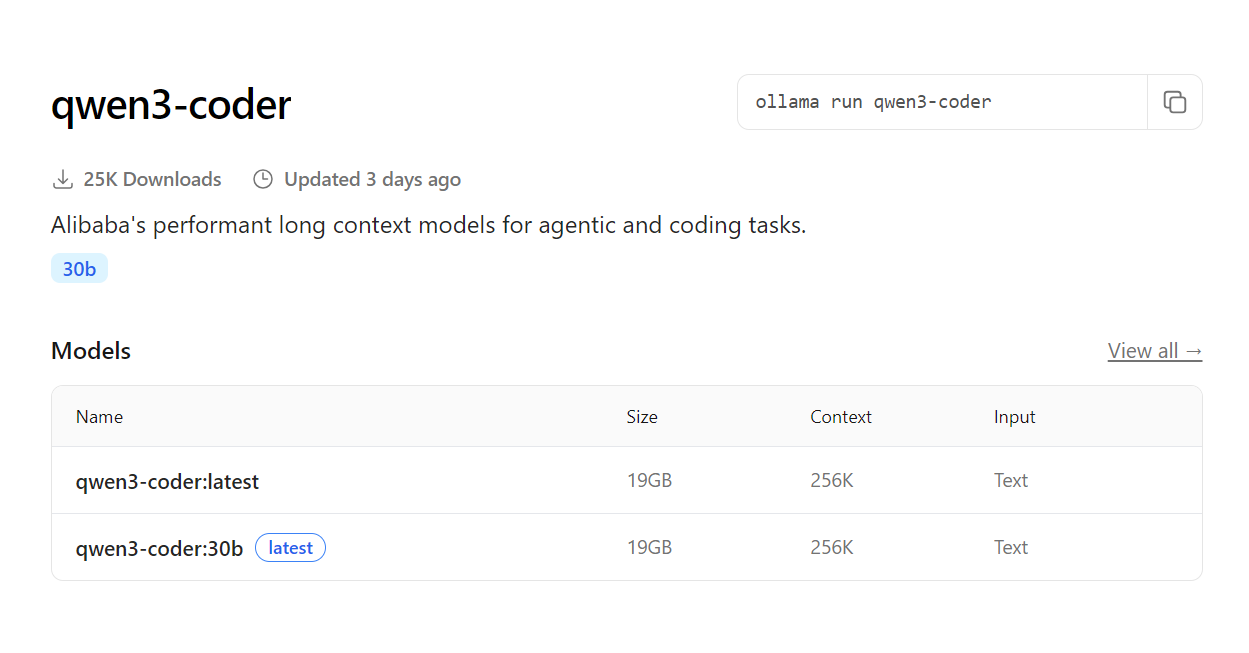
Source: qwen3-coder
Once you find it, copy the installation command and run it in your terminal to download and run the model:
ollama run qwen3-coderDepending on your internet speed, the download may take a few minutes. Once complete, the model will be ready to use directly from your terminal.
You can start chatting or ask it to help you build an app right away.
While Ollama now includes a built-in chat application, you can unlock even more potential by integrating Qwen3-Coder with advanced tools and applications.
To do this, you will need to serve the model as an API endpoint:
ollama serveThis command starts an OpenAI-compatible server at http://localhost:11434/, making it easy to connect Qwen3-Coder with your favorite development tools and workflows.
Msty is my go-to app for testing local and proprietary large language models. It’s packed with features you’ll love, making it a perfect match for integrating with the Ollama server. Visit the official Msty website and install the app for your platform.
Then,
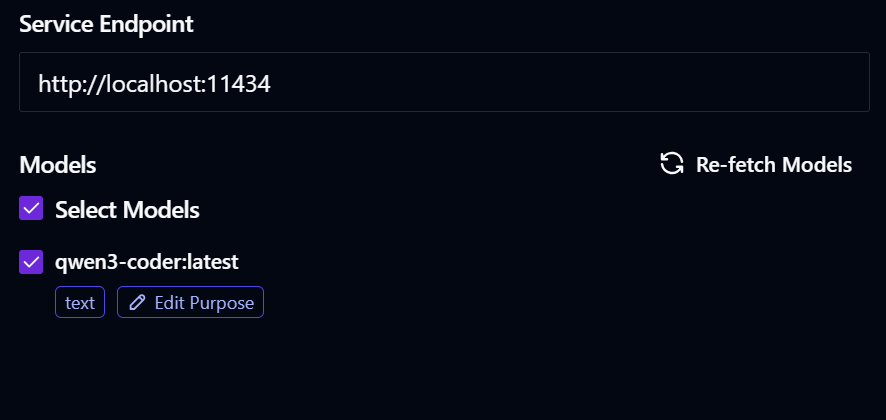
This integration is simple and versatile. By running Ollama serve, you can connect Ollama models to multiple apps and tools, unlocking even more creative possibilities.
As you know, Qwen3-Coder is specifically designed for coding and agentic workflows. If we do not integrate it into our code editor, we are wasting its potential.
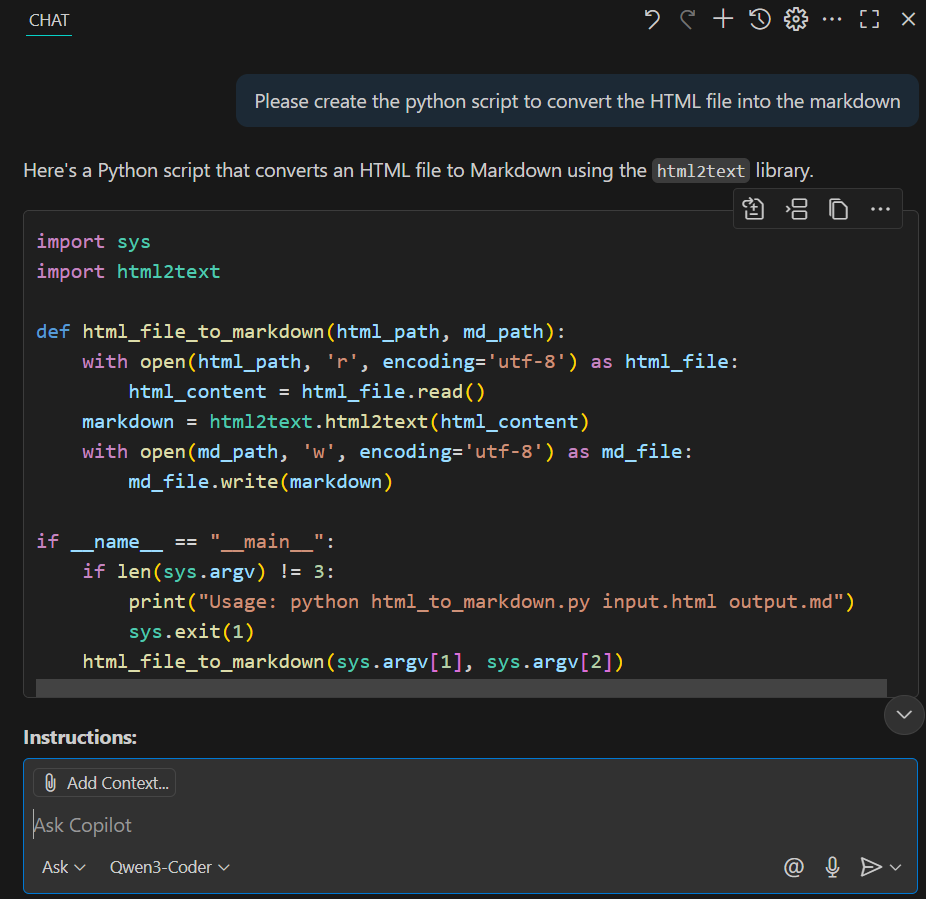
We will now integrate Qwen3-Coder into GitHub Copilot in VS Code. The new VS Code installation already comes with the Copilot extension. All you have to do is click on the model selection menu at the bottom, then select the “Manage Models” link, and choose Ollama as the model provider. This will show you the available models. Simply select the Qwen3-Coder model and start using the GitHub Copilot chat as you normally would.
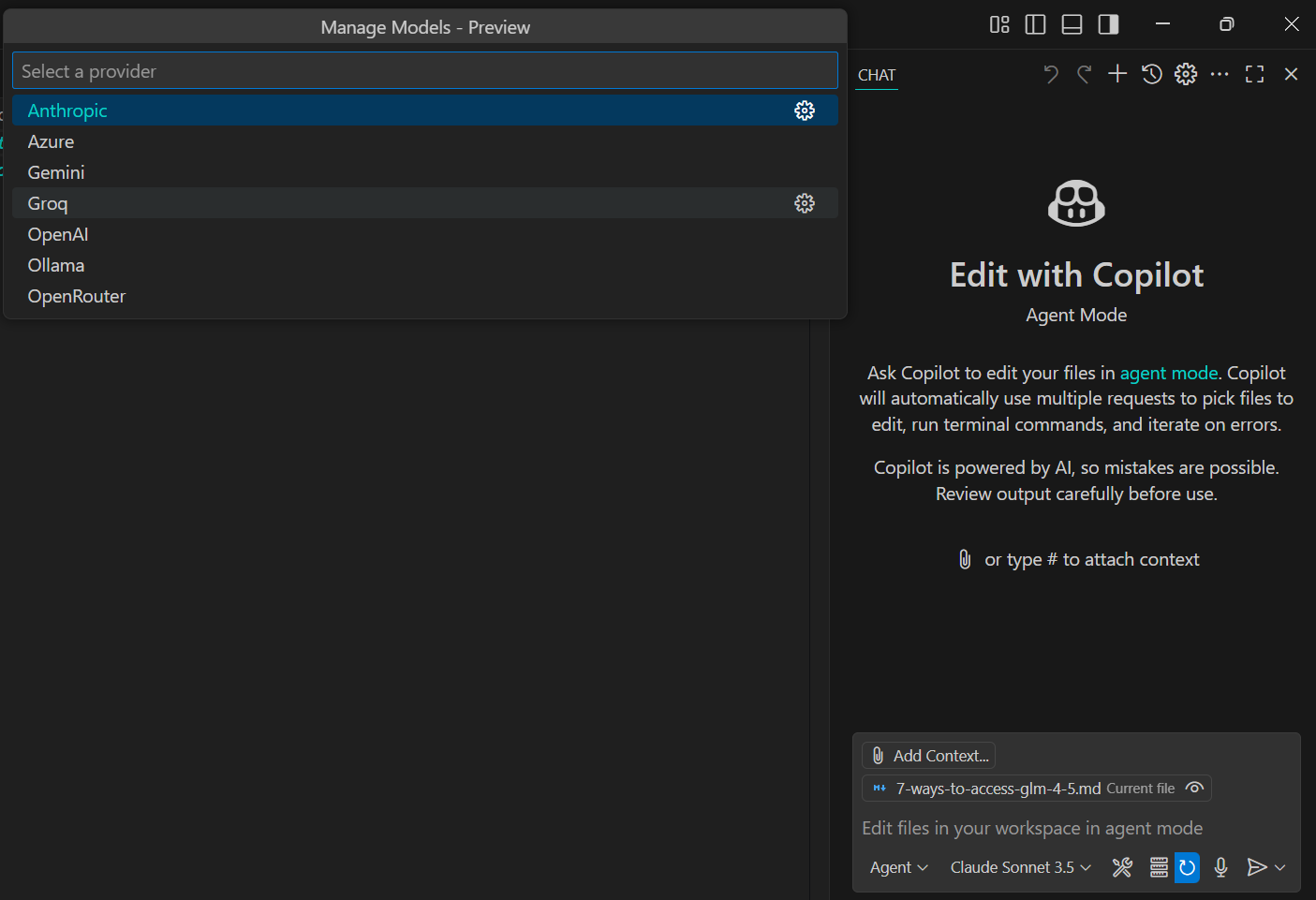
We asked it to create a script that would convert HTML to Markdown, and it took only 10 seconds to generate the complete response.
It is fast, local, and easy to use.
The Kilo-Org/kilocode VSCode extension is gaining popularity as one of the best open-source AI coding assistants for planning, building, and fixing code.
To integrate our locally run Qwen3-Coder model, first, install the necessary extensions, and then navigate to the settings. Change the API provider to Ollama, and it will automatically detect the model from the default URL.
After that, return to the chat and ask the AI to build a simple AI server. It will first examine all the files in the project and then provide you with the best solution for your query.
Integrating Qwen3-Coder into your Python applications is simple with the ollama/ollama-python Python package. This allows you to run powerful AI models locally and embed them directly into your workflows
To get started, just install the Ollama package:
pip install ollamaHere is a minimal example of how to use Qwen3-Coder in your Python code, similar to calling OpenAI’s API:
from ollama import chat
def main():
# Define a system + user prompt
messages = [
{"role": "system", "content": "You are a helpful coding assistant."},
{
"role": "user",
"content": (
"Please write a Python function `quicksort(arr)` "
"that takes a list of integers and returns it sorted."
),
},
]
# Stream the response from Qwen3-Coder
stream = chat(
model="Qwen3-Coder",
messages=messages,
stream=True
)
# Print chunks as they arrive
for chunk in stream:
# chunk is a dict-like with ['message']['content']
print(chunk["message"]["content"], end="", flush=True)
# Finish with a newline
print()
if __name__ == "__main__":
main()The response starts streaming almost instantly. This quicksort solution below took just 15 seconds to generate:
Here's a Python implementation of the quicksort algorithm:
```python
def quicksort(arr):
"""
Sorts a list of integers using the quicksort algorithm.
Args:
arr: List of integers to be sorted
Returns:
A new list containing the sorted integers
"""
# Base case: arrays with 0 or 1 element are already sorted
if len(arr) <= 1:
return arr
# Choose pivot (using the middle element)
pivot = arr[len(arr) // 2]
# Partition the array into three parts
left = [x for x in arr if x < pivot] # Elements less than pivot
middle = [x for x in arr if x == pivot] # Elements equal to pivot
right = [x for x in arr if x > pivot] # Elements greater than pivot
# Recursively sort left and right parts, then combine
return quicksort(left) + middle + quicksort(right)
# Example usage:
if __name__ == "__main__":
# Test cases
print(quicksort([64, 34, 25, 12, 22, 11, 90])) # [11, 12, 22, 25, 34, 64, 90]
print(quicksort([5, 2, 8, 1, 9])) # [1, 2, 5, 8, 9]
print(quicksort([1])) # [1]
print(quicksort([])) # []
print(quicksort([3, 3, 3, 3])) # [3, 3, 3, 3]
```This guide highlights how accessible local AI has become. Today, you can run open-source models on an old laptop and integrate them with your code editors, chat applications, or even build custom local AI apps using the Ollama Python SDK.
There are other options too, such as using Qwen Code CLI (covered in our separate guide: Qwen Code CLI: A Guide With Examples | DataCamp), or serving models on a local server and accessing them via SSH from multiple computers. The possibilities are expanding rapidly, making local AI more practical and versatile than ever.
Top AI Courses
Course
Course
Course
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan