
Track
Data Engineer in Python
40 hr
The dbt-utils package is a powerful toolkit that simplifies and enhances your data transformation processes. In this guide, we'll introduce you to dbt-utils, showcasing how it can streamline your workflow with its pre-built macros for common SQL operations.
dbt-utils package
dbt-utils is a package in dbt which provides a toolkit of pre-built macros that enhance the functionality of dbt projects. dbt-utils reduces complexity by adding layers of abstraction, enabling more efficient and consistent data transformation.
If you’re familiar with libraries in Python and packages in R, the dbt-utils package would be something similar.
With these standardized macros used for common Structured Query Language (SQL) operations, dbt-utils ensures that all the tough work from coding all the transformations from scratch is not needed.
Leveraging these utilities eliminates reinventing the wheel by integrating a suite of community-vetted macros into your projects, enhancing maintainability and fostering a culture of best practices.
dbt-utils provides a variety of features and functionalities that make data transformation more efficient and streamlined. These include:
dbt-utils offers a wide range of pre-built macros for common SQL operations using Jinja templating, such as joins, aggregations, filtering, and more.
These macros are standardized to ensure consistency across projects and reduce the need for repetitive coding.
For example, here are some macros used by analytics engineers:
date_spine: Creates a continuous sequence of dates between two specified dates, useful for time series analysis.pivot: Transform rows into columns dynamically, simplifying crosstab operations.star: Gets all fields from specified tables in the model, excluding those in the except argument.union_relations: Combine data from multiple relations with the same structure using a union all.generate_series: Create a series of numeric data, handy for time series analysis.surrogate_key: Produce a unique identifier for rows by concatenating multiple fields.With these macros, SQL can accomplish tasks that are otherwise complex and repetitive.
dbt-utils provides helpful tools for managing schemas and documentation within data models. This makes it easier to keep track of changes and maintain organization within projects.
With dbt-utils, users can easily write tests to ensure the accuracy and quality of their data transformations. These tests can be automated and integrated into continuous integration processes, allowing for more efficient and reliable data pipelines.
So, why use this package?
Well, let’s first have a look at some of its benefits:
Let’s have a look at how the dbt-utils package can be introduced into your data workflow below.
Before using dbt-utils, familiarity with SQL and an understanding of dbt (data build tool) fundamentals are imperative. You should already have a dbt project initialized and configured.
If you need a refresher, you can check out our Introduction to dbt course and dbt tutorial.
Furthermore, a clear version alignment between your dbt core and the dbt-utils package is necessary. It is advisable to check the compatibility between dbt versions to prevent conflicts or deprecated functionalities.
To begin the integration of dbt-utils into your data stack, start by ensuring your development environment is properly set up.
First, ensure that dbt is installed in your environment. You can install dbt via pip:
pip install dbt
To install dbt-utils, add the following to your packages.yml file in your dbt project root directory.
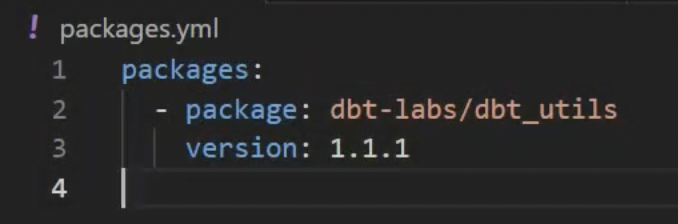
Create this file in your dbt project root if it doesn't exist, and add the following:
packages:
- package: dbt-labs/dbt_utils
version: "1.1.1" # Use the latest version compatible with your dbt versionIn this yaml file, you’ll be specifying the necessary package version as well. Make sure to use the latest version that is compatible with your installed dbt version.
After modifying, the installation is a simple command away.
The successful execution of this command will fetch and install dbt-utils, preparing you for enhanced functionality.
Run the following command in your terminal within your dbt project directory:
dbt depsThis command installs all the packages listed in your packages.yml.
The dbt-utils package provides a suite of common helper functions that streamline SQL transformations within dbt projects.
These functions help developers avoid redundancies and concentrate on their unique business logic.
Here are some functions in dbt-utils:
SQL generators in dbt-utils are useful for creating modular SQL code.
For example, the deduplicate macros are excellent for eliminating duplicate rows while maintaining the order of the data. Duplicates can be removed from models, tables and even Common Table Expressions (CTEs).
Generic tests are used to validate data in a table or view. They can be easily customized to fit specific requirements and provide valuable insights into the quality of data being processed.
For instance, the expression_is_true macro checks if a certain expression is true. This can be used flexibly to verify several conditions, such as:
Jinja helpers are useful for creating dynamic SQL queries that can be easily customized based on user input or variable data. They allow for conditional logic and looping within SQL statements.
Jinja templates are used to define and specify these macros.
One example is the pretty_time macro, which returns a string of the current timestamp.
Web macros are similar to Jinja helpers, but they are specifically designed for web-based projects. They allow for dynamic HTML generation and manipulation, making it easier to create interactive and responsive web pages.
One useful macro is the get_url_path macro, which gets the page path of the URL. Here’s how the syntax looks:
{{ dbt_utils.get_url_path(field='page_url') }}Introspective macros are macros that can access and manipulate data within the current scope. This allows for dynamic and efficient data processing, reducing the need for additional functions or code.
One example is the get_column_values macro, which returns the query results as an object.
Example scenario: A company has a large dataset containing customer information, transaction data, and product data. They need to create a report that shows the total sales for each product category in the past quarter.
Instead of writing complex SQL queries to join multiple tables and calculate the sales for each category, they can use dbt utils to easily extract relevant data and manipulate it within their macros or models.
For example, they can use get_filtered_columns_in_relation to filter out only the necessary columns related to product data and then use sum macro to calculate the total sales for each category.
This simplifies the process and makes it more efficient, saving time and reducing errors.
Code implementation:
To implement this solution in a mock database, you can follow these steps:
Use the get_filtered_columns_in_relation macro to filter only the necessary columns from the product data. This macro will help you select relevant columns efficiently.
-- models/product_data_filtered.sql
with product_data as (
select
{{ dbt_utils.get_filtered_columns_in_relation(
relation=ref('products'),
include=['product_id', 'category']
) }}
from {{ ref('products') }}
)
select * from product_dataNext, create a model to join the product, transaction, and customer data. Then use the sum function to calculate the total sales for each product category in the past quarter.
-- models/total_sales_by_category.sql
with product_data as (
select
{{ dbt_utils.get_filtered_columns_in_relation(
relation=ref('products'),
include=['product_id', 'category']
) }}
from {{ ref('products') }}
),
transaction_data as (
select
product_id,
sale_amount,
transaction_date
from {{ ref('transactions') }}
where transaction_date >= date_trunc('quarter', current_date) - interval '1 quarter'
),
joined_data as (
select
p.category,
t.sale_amount
from product_data p
join transaction_data t
on p.product_id = t.product_id
)
select
category,
sum(sale_amount) as total_sales
from joined_data
group by categoryAfter defining the models, run the dbt models to execute the transformations and generate the report.
dbt runHere’s an explanation of the code above:
The get_filtered_columns_in_relation macro helps in selecting only the necessary columns (product_id and category) from the products table, simplifying the dataset.
Next, the filtered product data is joined with the transaction data using SQL to get the sales amounts for each product. It then calculates the total sales for each product category within the last quarter using the sum aggregation function.
Example scenario:
In this use case, we will continue working with the same mock dataset from Use Case 1. However, instead of creating a report, our goal is to ensure data quality by running generic tests on the data.
Code implementation:
Below are examples of how to implement these tests for your dataset:
In this generic test, we will assert only values that fit the non-null proportion that we specify. We will do this using the not_null_proportion test.
# models/products.yml
version: 2
models:
- name: products
columns:
- name: product_id
tests:
- dbt_utils.not_null_proportion:
at_least: 0.95In this example, we included an additional optional argument at_least to set the non-null proportion to have a maximum of 0.95.
In this example, we’ll use the not_empty_string test to check for empty strings in the product_id field.
# models/products.yml
version: 2
models:
- name: products
columns:
- name: product_id
tests:
- dbt_utils.not_empty_stringUsing the relationships_where function will ensure that every product_id in the transactions table exists in the products table.
# models/transactions.yml
version: 2
models:
- name: transactions
columns:
- name: product_id
tests:
- dbt_utils.relationships_where:
to: ref('products')
field: product_idIn this example, we ensure that all the product_id values in the transactions table correspond to valid entries in the table. This is a basic relationship integrity check.
Do take note that you can also combine multiple tests at the same time so you can cover several integrity checks.
Once all the tests are defined in your yaml config file, use the dbt test command to execute all the defined schema tests.
dbt testWhen using dbt, it's important to follow best practices to ensure that your project runs efficiently and effectively. When using dbt-utils, there are a few key points to keep in mind:
Here are some common pitfalls that users may encounter when using dbt-utils, along with tips on how to avoid them:
dbt-utils is a powerful tool for streamlining, testing, and automating tasks in your data modeling process. It is an essential part of using dbt and can save you time and effort in developing your data models.
You might also find this dbt tutorial or this list of alternative data engineering tools useful.
If you’re interested in getting started with dbt, and would like some further learning, explore our Introduction to dbt Course too!
Continue Your dbt Learning Journey Today!
Track
Track
Course
blog
Abid Ali Awan
10 min
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Laiba Siddiqui
Tutorial
Laiba Siddiqui
Tutorial
Sayak Paul


