
Course
Unsupervised Learning in Python
4 hr
179.7K
In machine learning, there are two techniques available to achieve the feat of separating objects into distinct groups: classification and clustering. This often creates plenty of confusion among early practitioners.
On the surface, classification and clustering appear to be similar. They both use algorithms that leverage the features of a given dataset to uncover patterns and separate instances into distinct groups. But from a practical standpoint, they are quite different.
In this article, we are going to cover each technique, the different algorithms associated with them, their applications, and, most importantly, how they differ.
Classification tasks fall into a category of problems called “supervised learning.” Such problems involve developing models that learn from historical data to make predictions on new instances.
More formally, supervised learning tasks are problems in which a function is learned to map an input to an output based on example input-output pairs. Thus, the objective is to approximate the mapping function (f) from the inputs (X) to the output (y) — If you come from a mathematics background, you may know this as the problem of function approximation.
It’s important to note that supervised learning comes in two different forms: regression and classification.
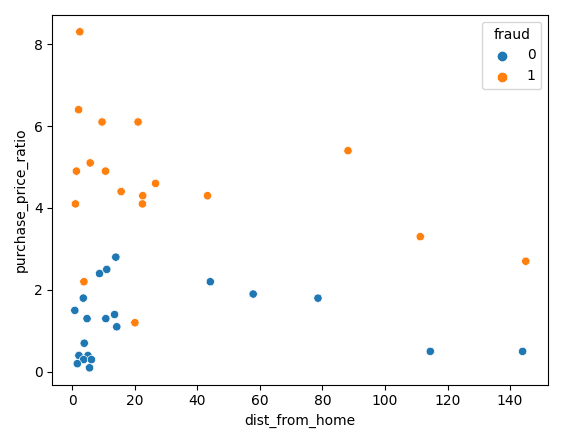
In classification problems, the objective of the learning algorithm is to approximate the mapping function from a set of features to predict a discrete output (i.e., predict whether the image is a cat or dog) – our Understanding text classification in Python tutorial for a hands-on demonstration.
There are several problems that involve the application of classification algorithms, such as:
Let’s check out some classification algorithms.
Many often, understandably, mistake logistic regression for a regression algorithm. Technically, they are not wrong. Logistic regression does not perform statistical classification. All it does is estimate the parameters of a logistic model.
The reason we’re able to use logistic regression for classification is due to a decision boundary that’s inserted to separate the classes. Thus, in its most simple form, logistic regression uses a logistic function to model binary dependent variables.
Source: Logistic Function by Scikit-Learn
KNN is one of the least complex machine learning algorithms and differs from logistic regression because you can use it for both classification and regression tasks.
Namely, it’s a non-parametric, lazy learning algorithm. This means KNN doesn’t make assumptions about the characteristics of the sample or whether the data being observed is quantitative or qualitative (non-parametric), and all computation is deferred until function evaluation (lazy learner).
Source: Nearest Neighbors with Scikit-learn
The decision tree algorithm is a popular non-parametric algorithm that’s also capable of performing regression and classification. Much of its popularity is due to its intelligibility and simplicity — since it’s one of the easier algorithms to visualize and interpret.
Conceptually, you may consider a decision tree in a flow-like state, flowing from root to leaves. The path to a leaf from the root defines a decision rule made on the features.
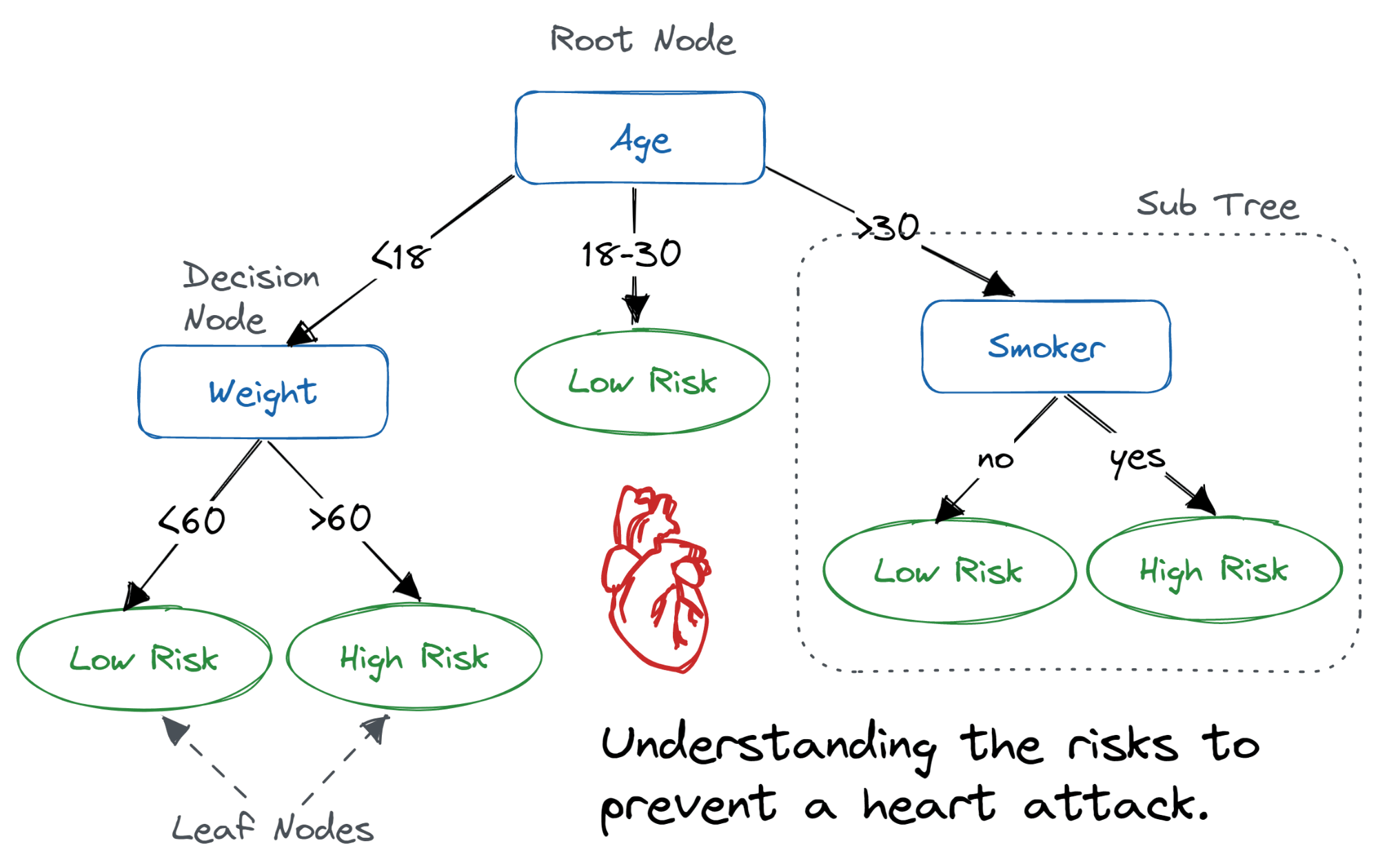
Source: Decision Tree Classification in Python Tutorial
The random forest is an ensemble model comprised of two or more decision trees. The technique leverages bootstrap aggregation and the random subspace method to grow individual trees in order to achieve a powerful aggregated predictor capable of both classification and regression.
Note, bootstrap aggregation, or bagging, is merely a technique used to generate multiple versions of a predictor that can be leveraged to build an aggregated predictor. The goal is to reduce the correlation between the predictors for an aggregated model that generalizes better.
Randomness is introduced into each predictor by randomly sampling instances from the training set with replacement and using the bootstrapped data for training.
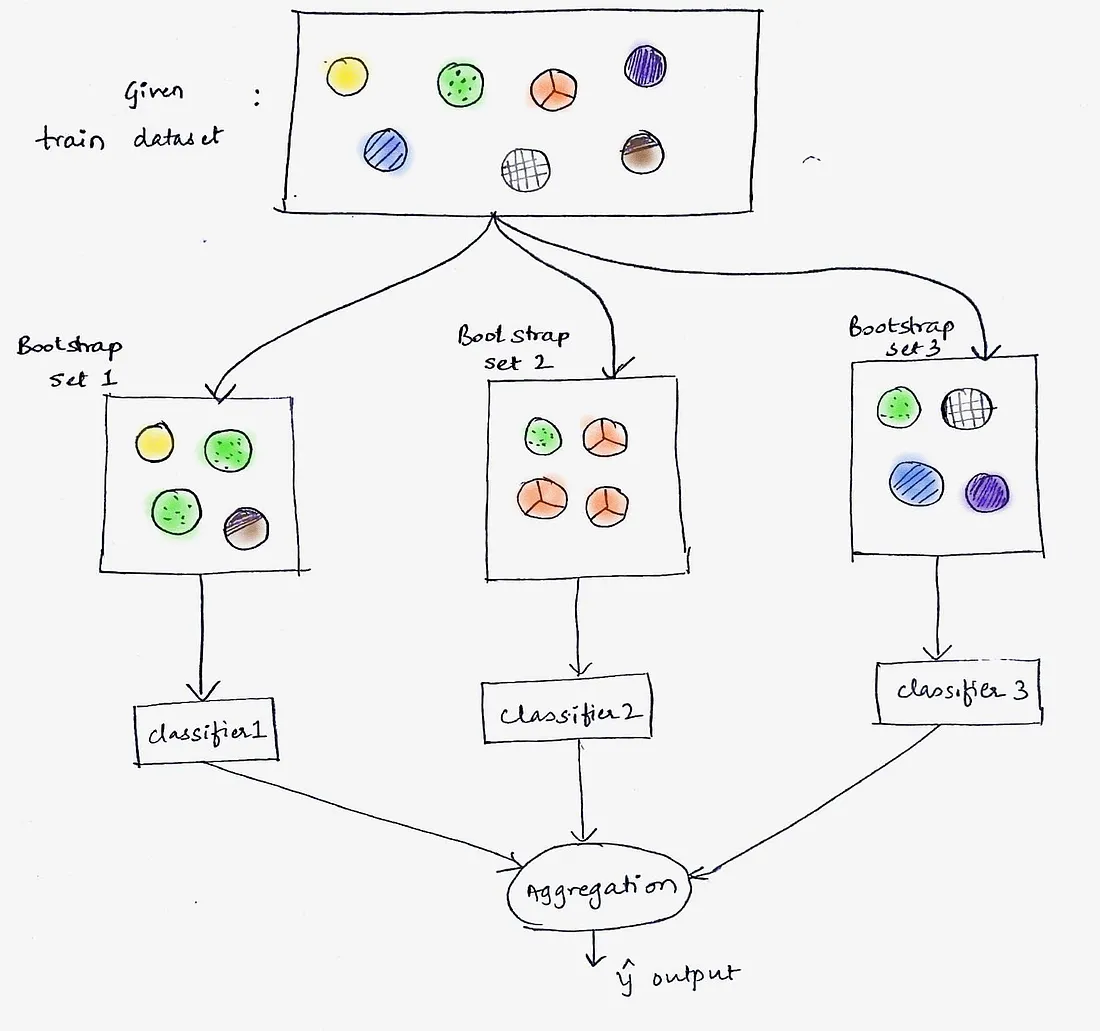
Source: Bagging: Machine Learning through visuals. #1: What is “Bagging” ensemble learning?
The random subspace method is also used to reduce the correlation between the predictors within the ensemble. It’s often referred to as “feature bagging” since it takes the same approach as bagging except with the features. That is: the random subspace method reduces correlation by building each predictor within the ensemble on a random sample of the features with replacement.
The Naive Bayes classifier is a probabilistic algorithm based on Bayes' theorem, which is a mathematical rule for updating probabilities based on new data.
In the context of Naive Bayes, the "naive" assumption is that all the features (or variables) in the dataset are independent of each other when predicting the outcome. This is a simplification because, in reality, features can be dependent. However, despite this naive assumption, the algorithm often performs surprisingly well in many classification tasks.
So, Bayes' theorem itself doesn't make any assumptions about the independence of variables. It's the Naive Bayes classifier that makes this assumption for the sake of simplicity and computational efficiency.
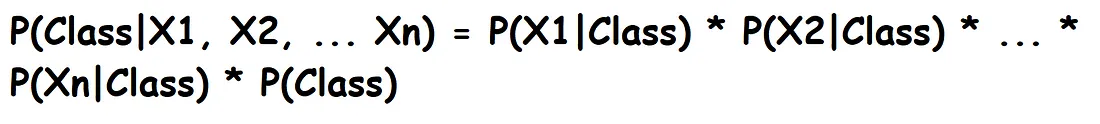
To understand clustering, we must start from the definition of unsupervised learning. Unsupervised learning is an approach used to discover the underlying structure of data, except unsupervised learning algorithms don’t require input-to-output mappings to achieve this feat.
Unsupervised learning is typically leveraged to uncover existing patterns in data such that instances are grouped without a need for labels. It assumes instances that fall within the same group have similar features. Thus, clustering is an unsupervised learning technique used to group unlabelled data based on their similarities or differences.
Clustering use cases include:
Here are few different types of clustering algorithms:
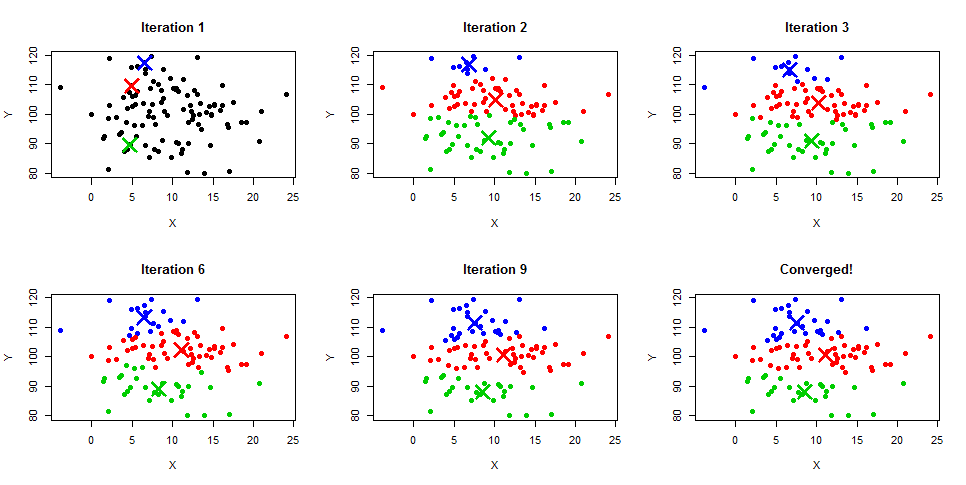
One of the most popular and widely used algorithms for clustering tasks is k-means. It’s a centroid-based, iterative algorithm that creates non-overlapping clusters.
Another way to construct clusters is by building a hierarchy of clusters, hence the name “hierarchical clustering.” There are two ways to build a hierarchy of clusters: .
Agglomerative
This is a bottom-up approach where each observation is treated as its own cluster in the initial stages. As the hierarchy is built from the ground up, each observation is merged into pairs, and pairs are merged into clusters.
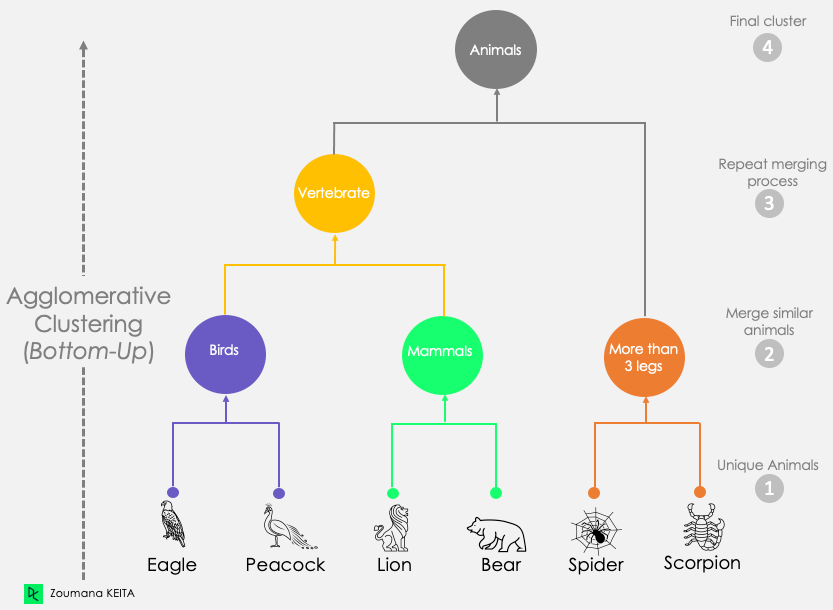
Source: An introduction to Hierarchical clustering in Python
Divisive
Divisive clustering is a top-down approach to clustering where all observations start in one cluster, and splits are performed recursively to build the hierarchy from top to bottom.
Source: An introduction to Hierarchical clustering in Python
One of the big appeals of Density-Based Spatial Clustering of Applications with Noise, or DBSCAN for short, is its robustness to outliers – it’s also the most well-known density-based clustering algorithm.
DBSCAN assumes clusters are dense regions in space separated by lower-density regions. Unlike K-Means, DBSCAN infers the number of clusters based on the data, and it can discover clusters of arbitrary shape so the number of clusters does not need to be passed as a parameter.
The OPTICS acronym stands for Odering Points to Identify the Clustering Structure. Like DBSCAN, it’s a density-based algorithm developed by the same research group. However, OPTICS seeks to overcome one of the major pitfalls of DBSCAN – identifying clusters in data of varying density – by disregarding the assumption that the data’s density is consistent.
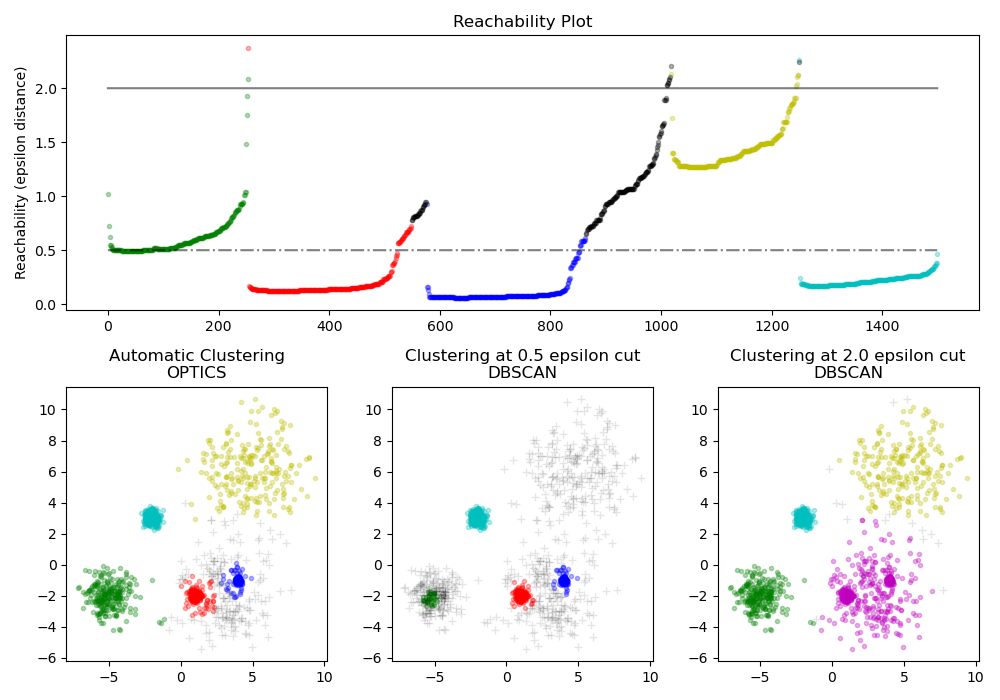
Source: Scikit-learn Demo of OPTICS clustering algorithm
Classification is a form of supervised learning. Supervised learning problems involve learn a function that maps an input to output based on input-output pairs. In contrast, unsupervised learning tasks employ methods, such as clustering, to discover hidden patterns in unlabeled data.
Both classification and clustering tasks require training data to learn patterns. However, it’s good practice to have testing data for classification tasks to evaluate the performance of the machine learning model’s predictions.
Clustering algorithms depend on input data to model the underlying structure of the data to discover insights. In other words, there’s no teacher to inform the algorithm of the correct answers – it’s just what the algorithm learns. In contrast, classification algorithms require input and output data to learn the mapping function, such that it may be used to predict the output of new input data.
|
Classification |
Clustering |
|
|
Supervised |
Yes |
No |
|
Labeled |
Yes |
No |
|
Purpose |
Approximate the mapping function (f) from a set of input (X) to a discrete output (y) such that it may be used to predict the output of new inputs. |
Learn the underlying patterns within the inputs (X) to suggest groups they instances may be separated into. |
|
Algorithms |
Logistic regression, K-nearest neighbors, Decision Tree, Random Forest, Naive bayes |
K-means, agglomerative clustering, divisive clustering, DBSCAN, OPTICS |
|
Use cases |
Customer churn, loan approval, spam filtering, facial recognition |
Market segmentation, image segmentation, social network analysis, recommendation engines. |
While both classification and clustering aim to segregate instances into discrete groups, their approaches are fundamentally different. Classification relies on predefined labels and a supervisor to guide the learning process, making it ideal for tasks like customer churn prediction or spam filtering. On the other hand, clustering operates without a supervisor and is more exploratory, finding its applications in market segmentation or recommendation systems. Understanding these nuances can significantly impact the effectiveness of your machine learning project.
Want to dive deeper? Check out these DataCamp courses to enhance your understanding and skills:
Dive Deeper Intro Classification & Clustering
Course
Course
Course
blog
Zoumana Keita
14 min
blog
Moez Ali
15 min
blog
Matt Crabtree
10 min
blog
Kurtis Pykes
9 min
blog
Moez Ali
8 min
Tutorial
Matt Crabtree
