
Course
Image Modeling with Keras
4 hr
39.8K
SAM 2 isn’t just for basic photo or video edits—its powerful features can be used in many different areas like digital art, healthcare, or self-driving cars.
SAM 2 can change image and video editing by simplifying tasks like object removal, background replacement, and advanced compositing.
For instance, creating a surreal landscape by combining elements from different sources becomes a straightforward process with SAM 2, making complex edits almost effortless.
Beyond traditional editing, SAM 2 is also great in generative AI, providing precise control over elements within generated images and videos. This feature sparks new ideas in content creation, making it easier to produce unique and personalized results.
Plus, SAM 2’s integration into social media platforms like Instagram could enable the development of new filters or effects that adapt to objects and scenes in real time, improving user engagement and creativity.
In medical imaging, SAM 2 can be crucial for accurately identifying and separating different body parts in scans.
Scientists can also use SAM 2 to closely monitor how a tumor changes in size when testing a new drug, leading to more accurate results and a better understanding of the treatment's effectiveness.
But SAM 2 isn't just useful in medicine. It can also help in other scientific areas like environmental studies. For instance, it can precisely analyze satellite images to track deforestation, melting glaciers, or changes in cities over time. This makes SAM 2 a great tool for researchers who need highly accurate visual data.
The automotive industry stands to gain significantly from SAM 2’s real-time, accurate object segmentation. SAM 2 can help in the precise identification and tracking of pedestrians, other vehicles, and obstacles, which is crucial for safe navigation in complex driving environments, by improving the perception systems of autonomous vehicles.
Imagine a self-driving car navigating through a bustling city. SAM 2’s advanced segmentation ensures that the vehicle can accurately detect and respond to potential hazards, significantly improving safety on the road. This capability improves the reliability of autonomous vehicles and contributes to the broader adoption of autonomous driving technology.
SAM 2 has great potential in augmented reality (AR). With its ability to precisely track objects in real time, virtual elements can blend seamlessly with the real world, creating more immersive AR experiences. This technology could greatly enhance AR applications in gaming, education, and even remote work, offering users more interactive and responsive tools.
Another key use for SAM 2 is in creating annotated datasets (composed of images and videos). SAM 2 automates the segmentation process on large datasets, cutting down the time and effort needed for manual work. This speeds up AI development and improves the quality of the training data, resulting in stronger and more accurate models.
Let’s have a look at how SAM 2 works behind the scenes.
SAM 2 is built upon a sophisticated architecture that comprises three core components: an image encoder, a flexible prompt encoder, and a fast mask decoder. These components work together to efficiently process both images and videos.
A standout feature of SAM 2 is its use of a memory attention module, which is crucial for video segmentation. This module allows the model to remember and use information from previous frames, enhancing its ability to track objects consistently across a video.
To better understand this, let’s examine the original SAM architecture:
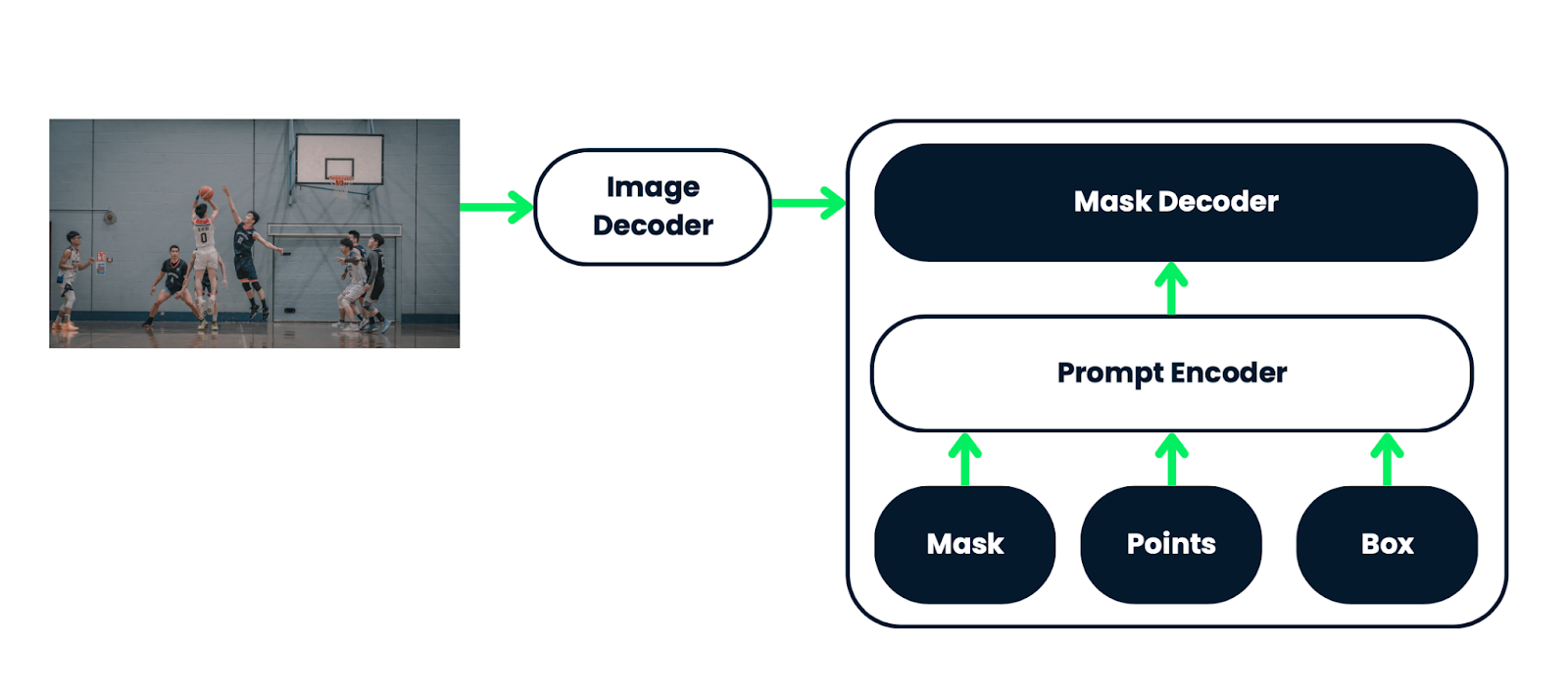
SAM 2 extends the SAM architecture from images to videos, allowing it to segment objects across video frames. It uses various prompts, like clicks or bounding boxes, to define the object's extent in a frame. A lightweight mask decoder processes these prompts and image embeddings to create a segmentation mask, which is then propagated across all video frames to form a "masklet."
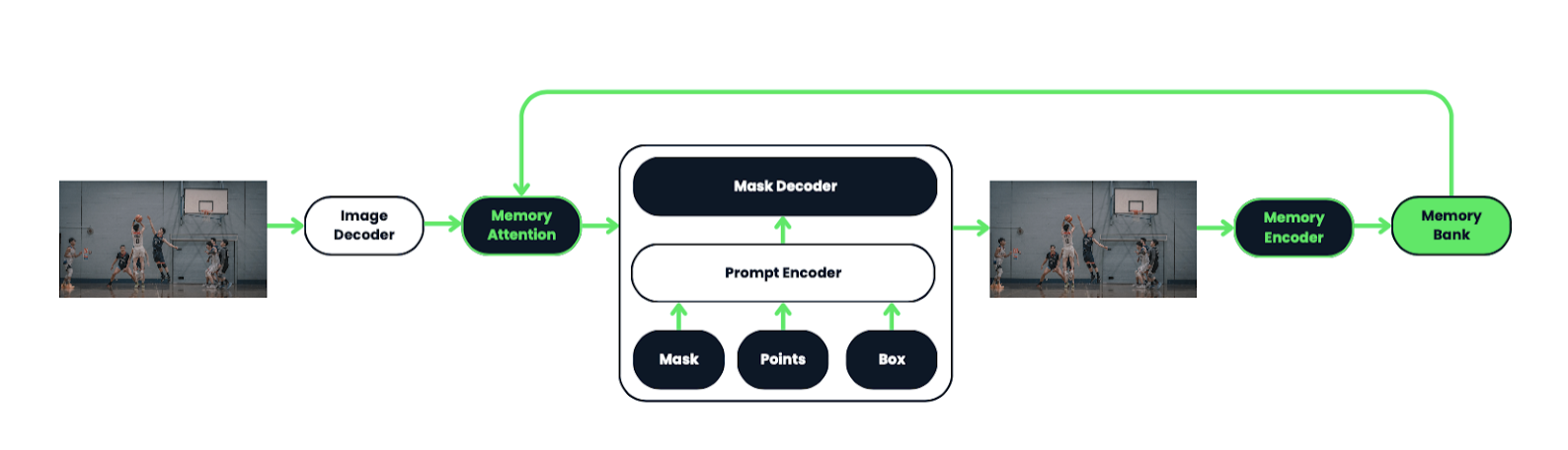
The system includes a memory mechanism with a memory encoder, bank, and attention module, enabling it to store and use information about objects and user interactions to improve mask predictions in subsequent frames.
The memory encoder updates the memory bank with each frame's mask prediction, allowing SAM 2 to refine its predictions as more frames are processed. The architecture is designed to handle real-time, streaming video processing efficiently, making it suitable for applications like robotics and dataset annotation.
SAM 2 also functions with images by treating them as a single-frame video. In this mode, the memory mechanism is deactivated. When processing images, SAM 2 generates segmentation masks without utilizing the memory components, effectively handling the task as a simplified case where only the current frame (image) is considered.
Thanks to its optimized architecture and efficient processing techniques, SAM 2 can operate at approximately 44 frames per second. This real-time capability makes it suitable for a wide range of applications, from live video editing to interactive AI systems.
SAM 2 was trained on an extensive and diverse dataset, including the newly introduced SA-V dataset, which contains over 600,000 masklet annotations across 51,000 videos. This large and varied dataset enables SAM 2 to generalize across various scenarios, from everyday objects to highly specialized domains.
While SAM 2 is highly advanced, it is not without limitations.
SAM 2, while effective for segmenting objects in images and short videos, has limitations in challenging scenarios. It can struggle with tracking objects through drastic viewpoint changes, long occlusions, crowded scenes, or extended videos. To address this, the model allows manual corrections through interactive prompts.
In crowded scenes, SAM 2 might confuse similar-looking objects, especially if the target object is only specified in one frame. However, additional prompts in subsequent frames can help correct this.
The model's efficiency decreases when segmenting multiple objects simultaneously, as it processes each object separately without inter-object communication. Plus, SAM 2 may miss fine details in fast-moving objects, and its predictions can be unstable across frames due to the lack of enforced temporal smoothness.
While SAM 2 has advanced automatic masklet generation, human annotators are still needed for tasks like verifying mask quality and identifying frames that need correction. Further automation and improvements are needed, and the developers encourage the AI community to build upon SAM 2 to advance the research and create new applications.
To download the model weights and code, visit the Meta AI website. SAM 2 is released under an Apache 2.0 license, making it open-source and accessible for developers and researchers. You can download the model and code here.
However, if you want to try out SAM2, you can try the interactive demo here.
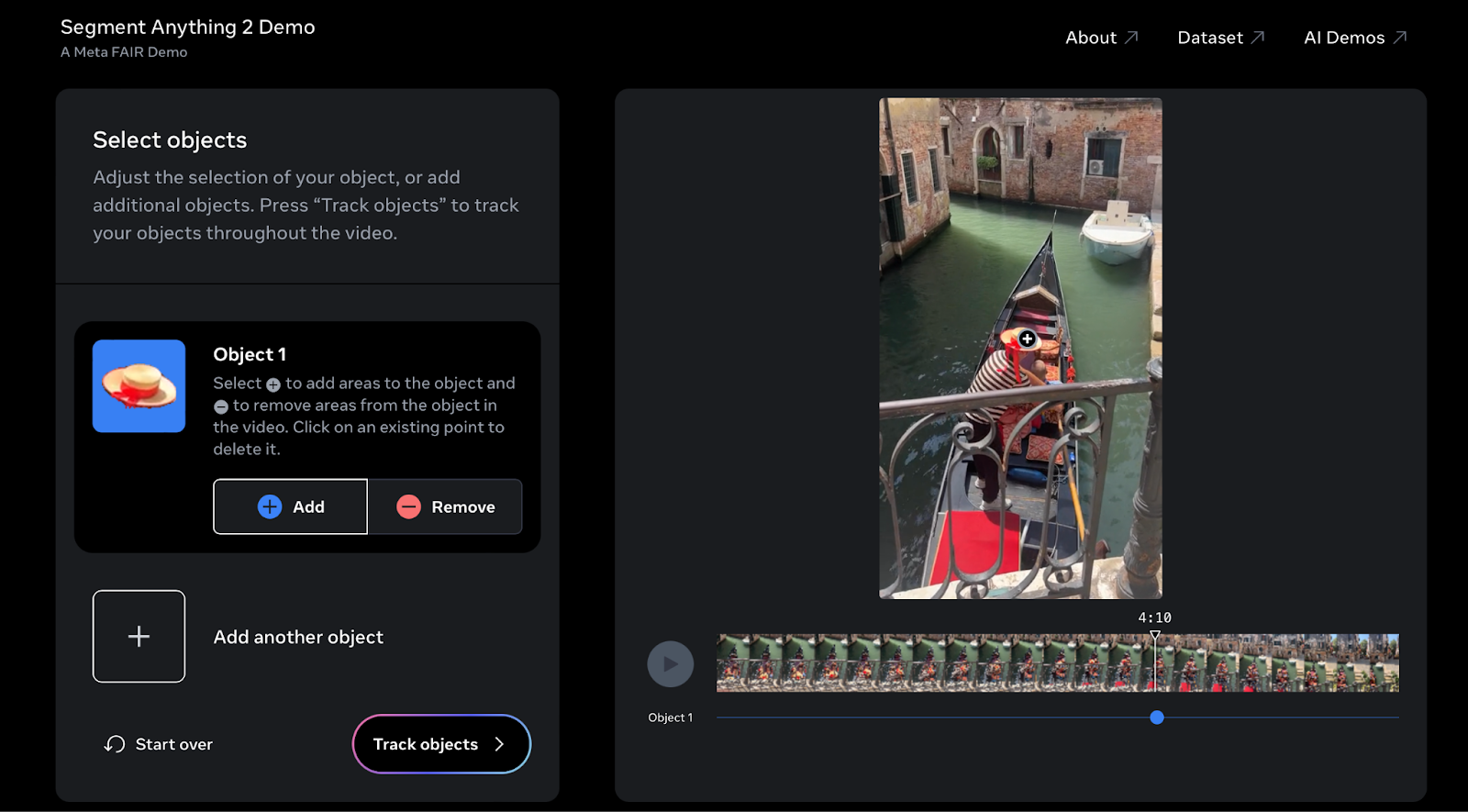
I tried SAM 2 on a video from my last holiday in Venice. You can try it out with your own videos to easily select and track objects throughout your footage.
For a deeper understanding of the model’s architecture, training process, and applications, you can access the official research paper. The paper provides detailed insights into the innovations behind SAM 2.
If you want to dive deeper into SAM 2, there are plenty of resources available to help you out. You can find official documentation, tutorials, and more on the Meta AI website. It’s packed with everything you need, from details on the model architecture to step-by-step implementation guides.
The community is also actively involved in improving SAM 2 by contributing to its open-source projects. Staying connected with the latest updates and being part of the community can help shape the future of SAM 2 and take advantage of its new features as they come out.
To stay on top of all these updates, it’s a good idea to follow the Meta AI blog and check in on their GitHub repository regularly. These platforms provide news about new features, real-world applications, and even sneak peeks into what’s coming next. Being informed not only helps you make the most of SAM 2 but also gives you a chance to contribute to its evolution.
As with any powerful technology, we need to think carefully about how we use SAM 2. Because it relies on large datasets, there’s a risk of bias in its predictions, which is something we need to watch out for, especially in sensitive areas like surveillance and autonomous vehicles.
There are also privacy concerns to consider, particularly in how SAM 2 might be used in monitoring or tracking people. To make sure SAM 2 is used responsibly, it’s important to have open discussions and set clear ethical guidelines. This will help ensure that SAM 2 is used in ways that are beneficial and fair for everyone.
It’s also important to remember that AI models like SAM 2 are only as good as the data they’re trained on. This makes it crucial to use diverse and balanced datasets to train SAM 2, minimizing the risk of unfair outcomes.
Ongoing evaluation and transparency in how SAM 2 is used will also be key in maintaining public trust and ensuring that this technology is applied in a way that respects people’s rights and enhances societal well-being.
Segment Anything Model 2 (SAM 2) is making a significant impact in the world of computer vision, offering advanced segmentation capabilities for both images and videos.
Its ability to track objects in real time, combined with improved accuracy and user-friendly prompting techniques, makes it a valuable tool across various industries.
As SAM 2 continues to develop, it opens up new opportunities in creative design, scientific research, and more. Offering an interactive demo and open-source access to the model and its extensive training dataset, Meta AI encourages innovation and collaboration within the AI community, setting the stage for future advancements in visual understanding and interactive applications.
Learn AI with these courses!
Course
Course
Course
blog
Stanislav Karzhev
10 min
blog
Abid Ali Awan
8 min
blog
Richie Cotton
8 min
podcast
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev

