This tutorial is a valued contribution from our community and has been edited for clarity and accuracy by DataCamp.
Interested in sharing your own expertise? We’d love to hear from you! Feel free to submit your articles or ideas through our Community Contribution Form.
The evolution of machine learning has led to the development of foundation models, a class of models pre-trained on extensive data, serving as a versatile base for a myriad of applications. These models, epitomized by the likes of GPT and BERT in Natural Language Processing (NLP), have demonstrated unprecedented capabilities in tasks such as zero-shot and few-shot learning.
In this article, we delve into the realm of image-text foundation models, exploring the innovative Contrastive Captioner (CoCa) model. We will dissect its architecture, understand its unique approach combining contrastive and generative objectives, and see how it embeds the capabilities of models like CLIP and SIMVLM into a singular, cohesive model.
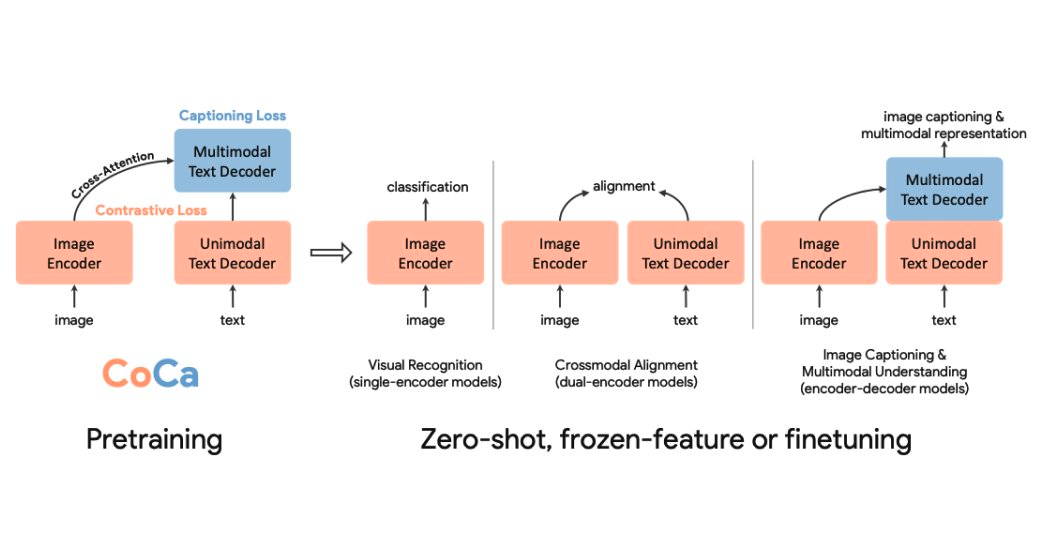
Fig-1 - Contrastive Captioner - (CoCa)
The Rise of Foundation Models
The idea of foundation models is nothing new in machine learning. In deep learning, the techniques that enable the training of these models allow us to adapt the models in the future for downstream tasks. In NLP, there has been a boom in foundation models such as GPT and BERT, trained on noisy internet-scale data, that have demonstrated remarkable zero-shot and few-shot capabilities.
Research attempts to build vision and vision-language foundation models have explored three main paths: single-encoder models, image-text dual-encoder models with contrastive loss, and encoder-decoder models with a generative objective. Before we explore the CoCa model, let’s take a look at these research lines on building foundation models and their weaknesses.
Glossary
- Foundation Models. Pre-trained models serving as a starting point for various applications in machine learning, adaptable for specific tasks.
- Contrastive Loss. A loss function that trains models to learn similar representations for similar input pairs and dissimilar ones for dissimilar pairs.
- Cross-Modal Interaction. The interaction between different types of data modalities (e.g., image and text) to generate a joint representation.
- Encoder-Decoder Architecture. A neural network structure with an encoder to process input data and a decoder to generate the output, used for sequence-to-sequence tasks.
- Causal Masking. A technique in transformer models to prevent access to future tokens in the sequence during training.
- Attention Mechanism. A component allowing models to weigh and prioritize different parts of the input when processing information.
- Zero-Shot Learning. A learning paradigm where models make predictions or classifications on data classes not seen during training.
- Visual Question Answering (VQA). A task where models answer questions about the content of images, combining computer vision and natural language processing.
- Unimodal and Multimodal Representations. Unimodal representations capture information from one type of data modality, while multimodal representations integrate information from multiple modalities.
- Contrastive Language-Image Pre-training (CLIP). A model trained using contrastive learning to align images and text in a shared representation space.
Single Encoder Models
If you’ve dabbled in computer vision before, chances are you’ve come across this class of models. These models learn representations of images that can be later adapted for downstream vision tasks by training on a large dataset of annotated images with a cross-entropy loss.
These models have empirically been shown to excel in vision-related tasks such as detection but are inferior on tasks involving vision language due to their heavy reliance on human annotations, which prevents baking into them human natural language.
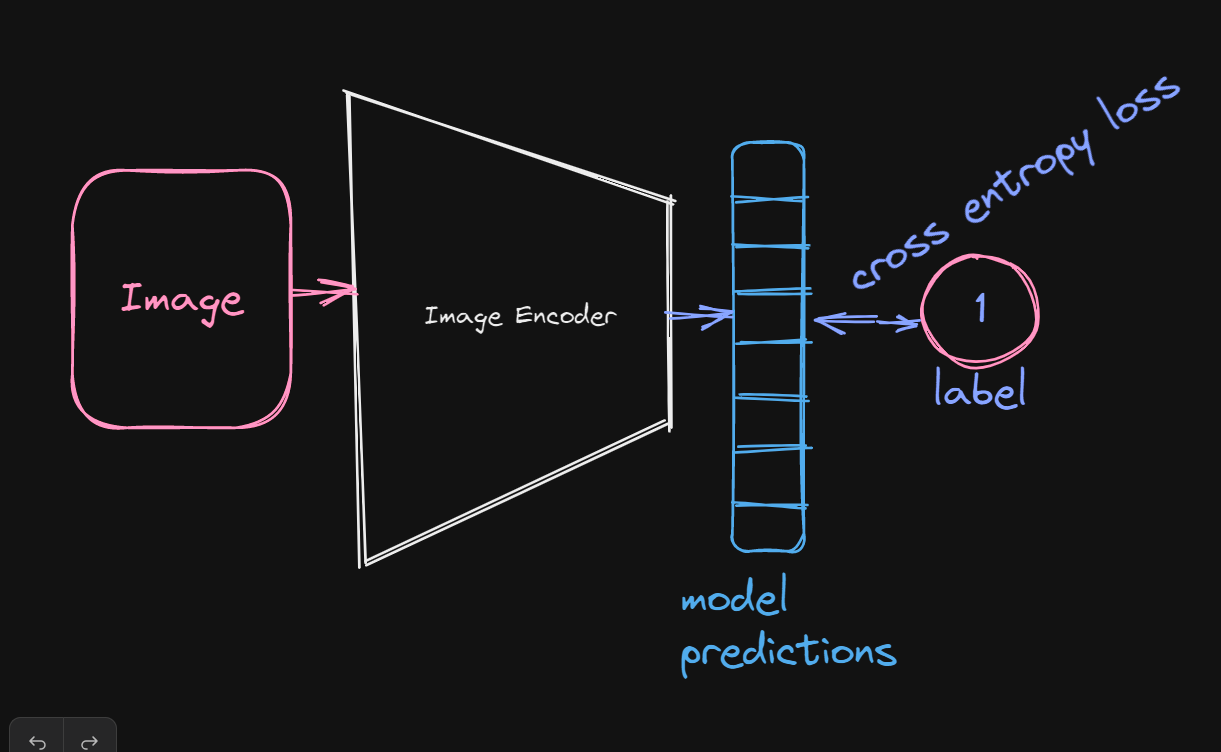
Image-Text Dual-Encoder Models with Contrastive Loss
Popular models of this class of vision-language foundation models include CLIP (Contrastive Language-Image Pre-training) and ALIGN.
During pre-training, we learn an alignment task by jointly training an image and language model using a contrastive loss.
The idea behind their pre-training objective is quite simple: cluster together the representations of image-text pairs(they are related) and push apart representations of images and texts that are not related(pairs) in the same latent space. The resulting dual-encoder model can then be set up to perform zero-shot classification tasks and image retrieval.
Recent models of this class of models, like CLIP, have been shown to achieve remarkable performances on various vision language tasks but are almost impossible to use on tasks that require the fused representation of images and texts, such as visual question answering since we only learn to align the representations of images and text and not generate a unified representation that encodes information of both image and text input.
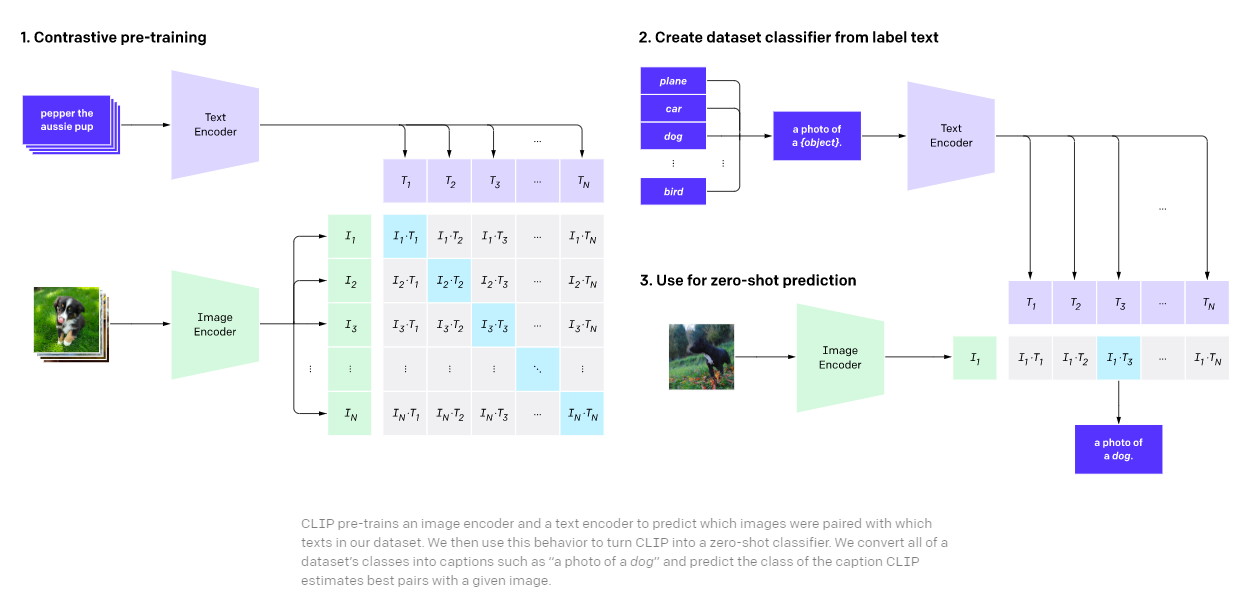
Fig-3 - Contrastive Language-Image Pre-training (CLIP)
Generative Pre-training with Encoder-Decoder Architecture
These models employ cross-modal interaction between image and text-hidden representations to generate a joint representation.
During pre-training, we generate a unified representation of image and text through cross-modal interactions between hidden text representation and output of the image encoder and apply a Language Modelling loss on decoder output.
In recent machine learning architecture, cross-modal interaction is mostly performed through a cross-attention mechanism in transformers using image encoder outputs as query and hidden text representations as key and value.
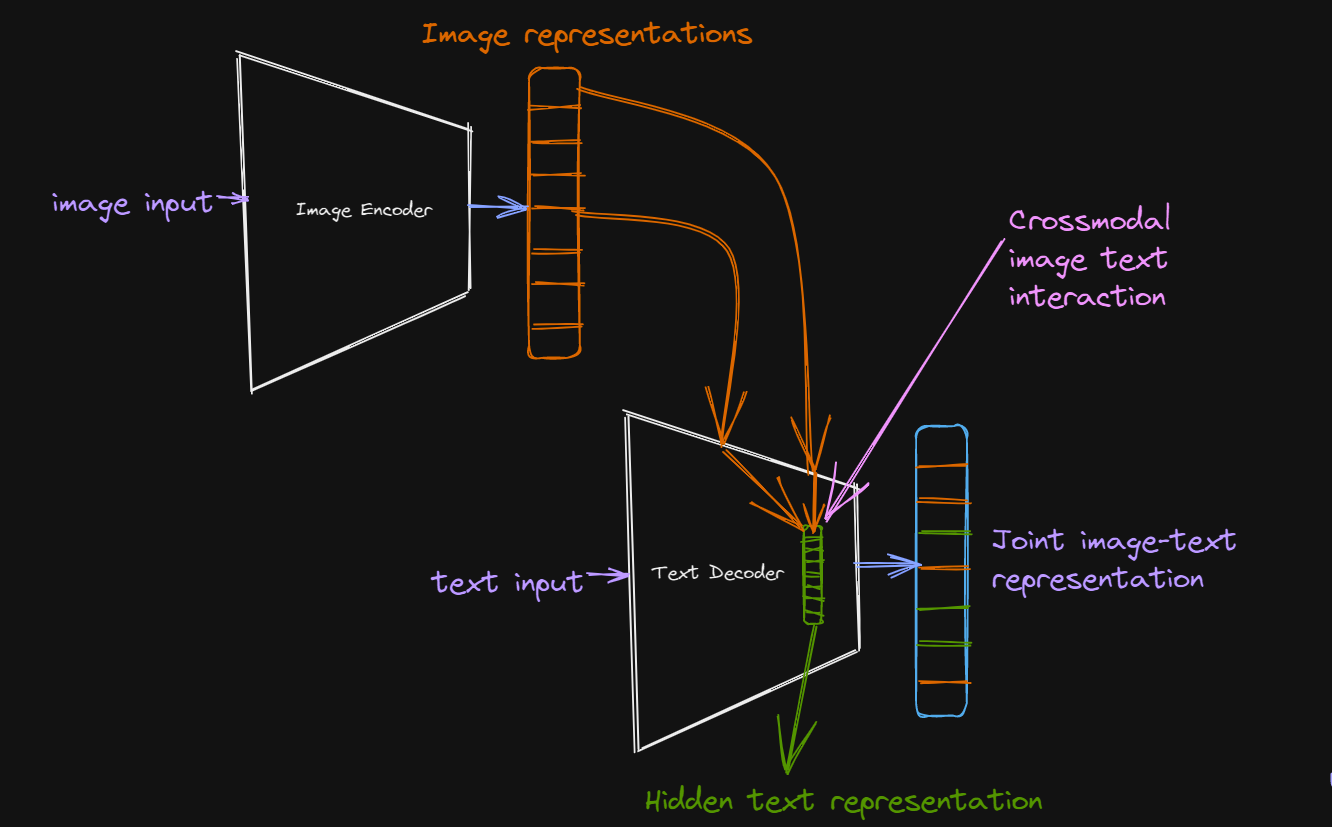
For downstream tasks, we can take the decoder output, which is a joint representation of image and text, and perform various multimodal image-text understanding tasks such as Visual Question Answering. One recent model that uses this paradigm is the Simple Visual Language Model (SIMVLM).
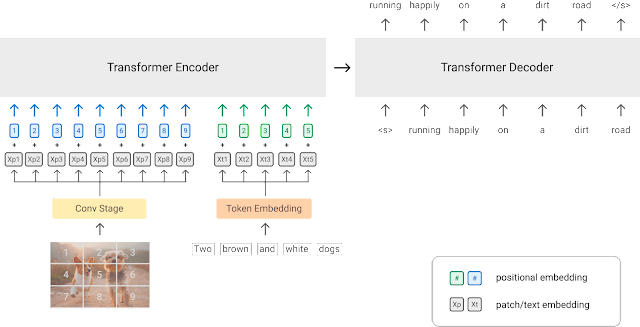
Fig-5 - Simple Visual Language Model (SIMVLM)
Motivation Behind CoCa
The authors of the CoCa model sought to subsume the capabilities of the different paradigms of building image-text foundation models in a simple model. The design of the CoCa leverages a contrastive loss to learn to align image and text representations in one vector space and a generative objective (captioning loss) to learn a joint image-text representation, hence embedding the capabilities of models such as CLIP and SIMVLM into one single model.
Model Architecture
CoCa employs the standard encoder-decoder approach and, like most models of this sort, encodes the image with a neural network such as a convolutional neural network or a transformer.
The uniqueness of the CoCa architecture begins at the output of its encoder and its entire decoder setup.
Recall that the aim of the CoCa paper is to combine the capabilities of two paradigms of vision-language models (contrastive and generative objective) into a single model. The contrastive objective paradigm requires that our text decoder outputs a unimodal text representation, which is then projected into a similar vector space as the image representation to learn the alignment task.
The generative object, on the other hand, allows the decoder to take in image representations from the encoder and auto-regressively generate text conditioned on the image representations and text input.
Do note that both decoder parts apply causal masking to prevent the model from looking at tokens ahead of time.
To achieve this, the authors cleverly adapted a decoupled decoder setup, the first part which learns to produce a unimodal text representation for the contrastive objective and the second part which learns to generate a multi-modal image-text representation.
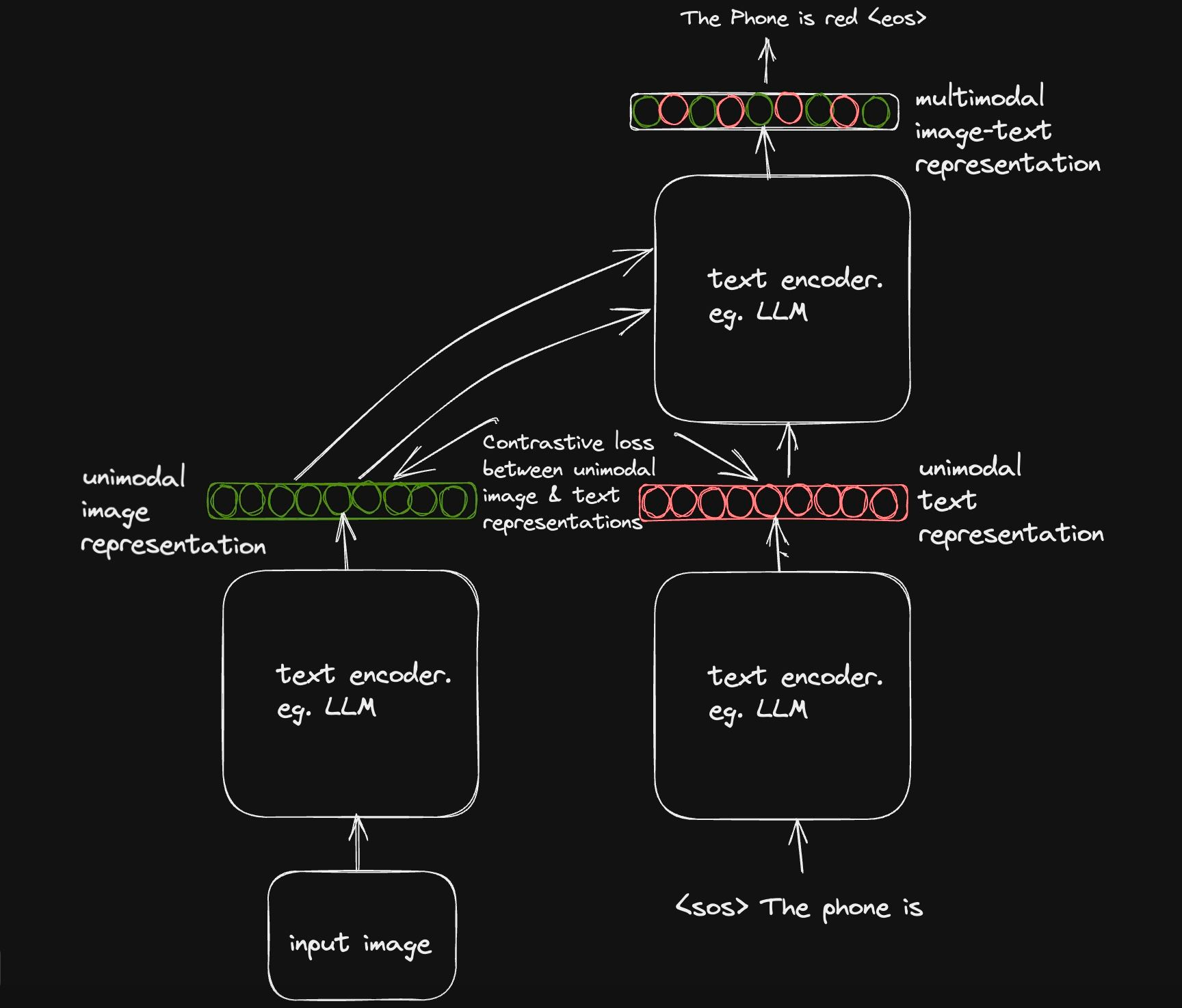
Contrastive Objective
The idea behind the contrastive objective, as used in several models like CLIP and ALIGN, is quite simple. The idea is to learn a representation for different modalities, such as image and text, such that similar pairs are closer to each other in the representation space and dissimilar pairs are further away from each other.
At each training step, we draw a sample of image-text pairs from the dataset and drive the weights of our encoders to cluster together sample pairs and push away non-pairs.
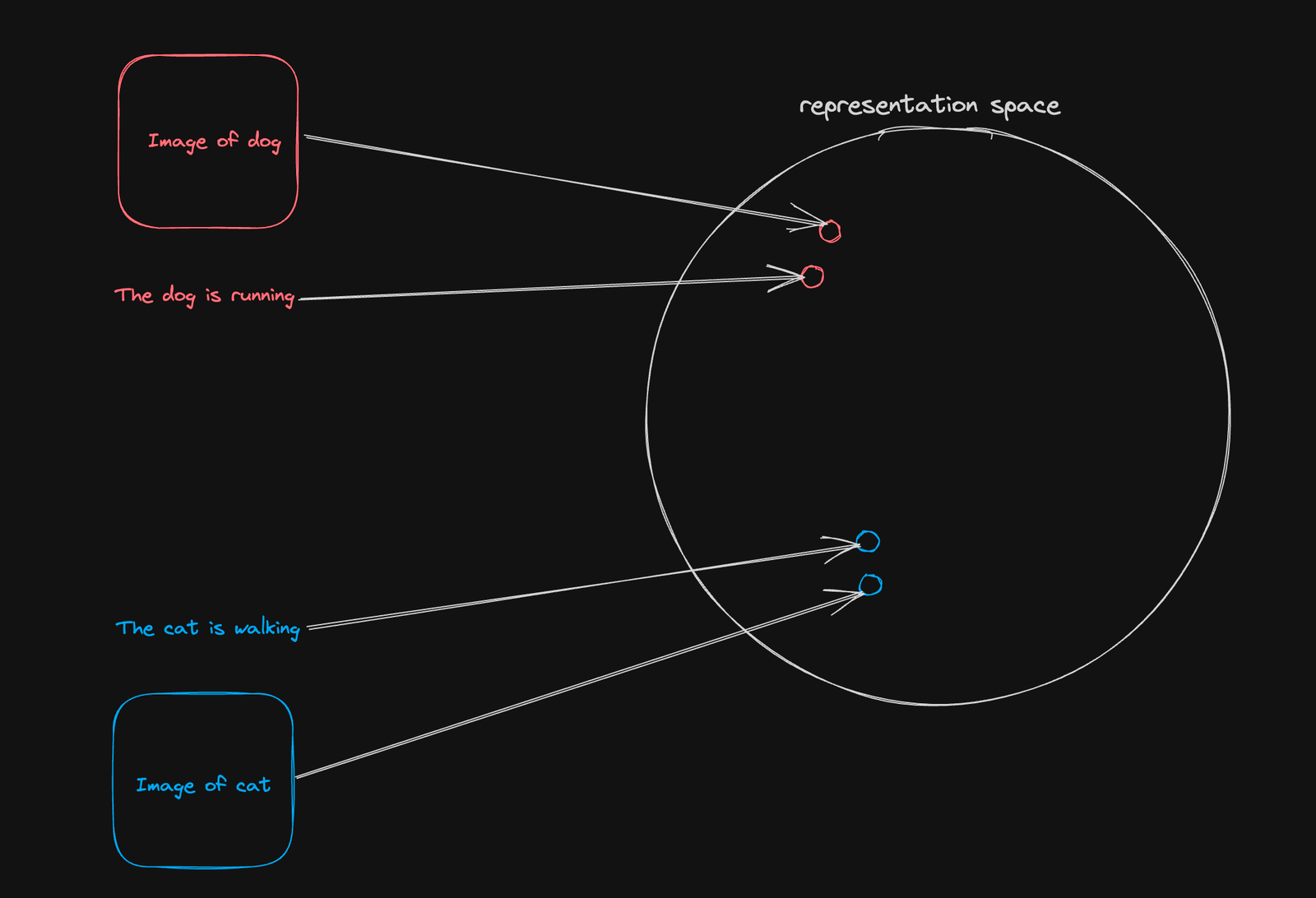
As mentioned earlier, the contrastive objective requires unimodal representations of both image and text modalities. To achieve this on the text encoder side, we apply a classic technique used in the BERT language model.
As part of the input sequence, we introduce a learnable classification token [CLS] at the end of the input sequence and hope that the output vector mapped to this token will capture the semantic meaning of the entire input sequence.
Since our decoders apply causal masking to their attention maps, adding the classification token at the end of the sequence ensures that there is an attention connection between the classification token and all other tokens in the input sequence hence capturing the semantic meaning of the entire sentence.
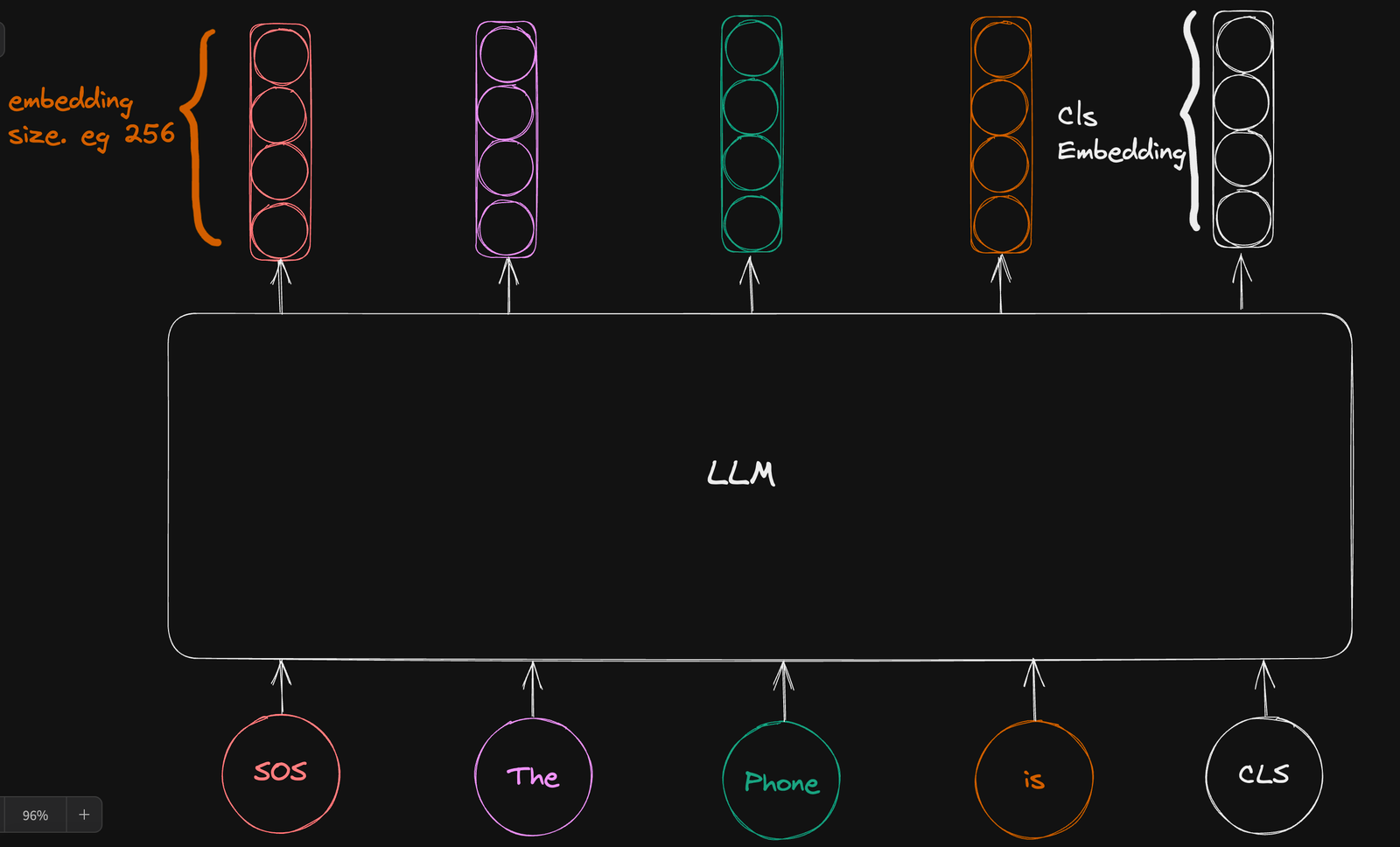
We ignore the vector representation of the other input tokens and use the vector representation of the classification token to estimate the contrastive loss.
On the image encoder side, things are a bit different.
In the image from Fig-6, you can see that part of the output of the image encoder is used together with the classification token embedding to estimate the contrastive loss, and part of it is sent to the upper part of the decoupled setup to estimate the joint representation.
In fact, only a single embedding output of the image is needed to estimate the contrastive objective while the entire sequence of embedding output of the image encoder is used to estimate the generative objective.
The authors argue that they were able to empirically determine that a single pooled embedding output helps to capture the global representation of the image (which is exactly what we want for the contrastive objective), and a sequence of embedding outputs helps in tasks that require a more fine-grained representation of the image.
To achieve this, an attentional pooling layer, which is a single multi-head attention layer, is employed to customize the image encoder output for different objectives through a learnable query parameter. By setting the query parameter to a specific integer value, we can adapt our whole encoder setup to output an embedding sequence whose length is the query parameter.
In the case of the contrastive objective, we set the query parameter to one to obtain just a single embedding to calculate the contrastive loss and in our generative objective case, we set it to an arbitrary value which is ideally equal to the sequence length of our text. In the CoCa paper, the authors chose 256 for the generative objective.
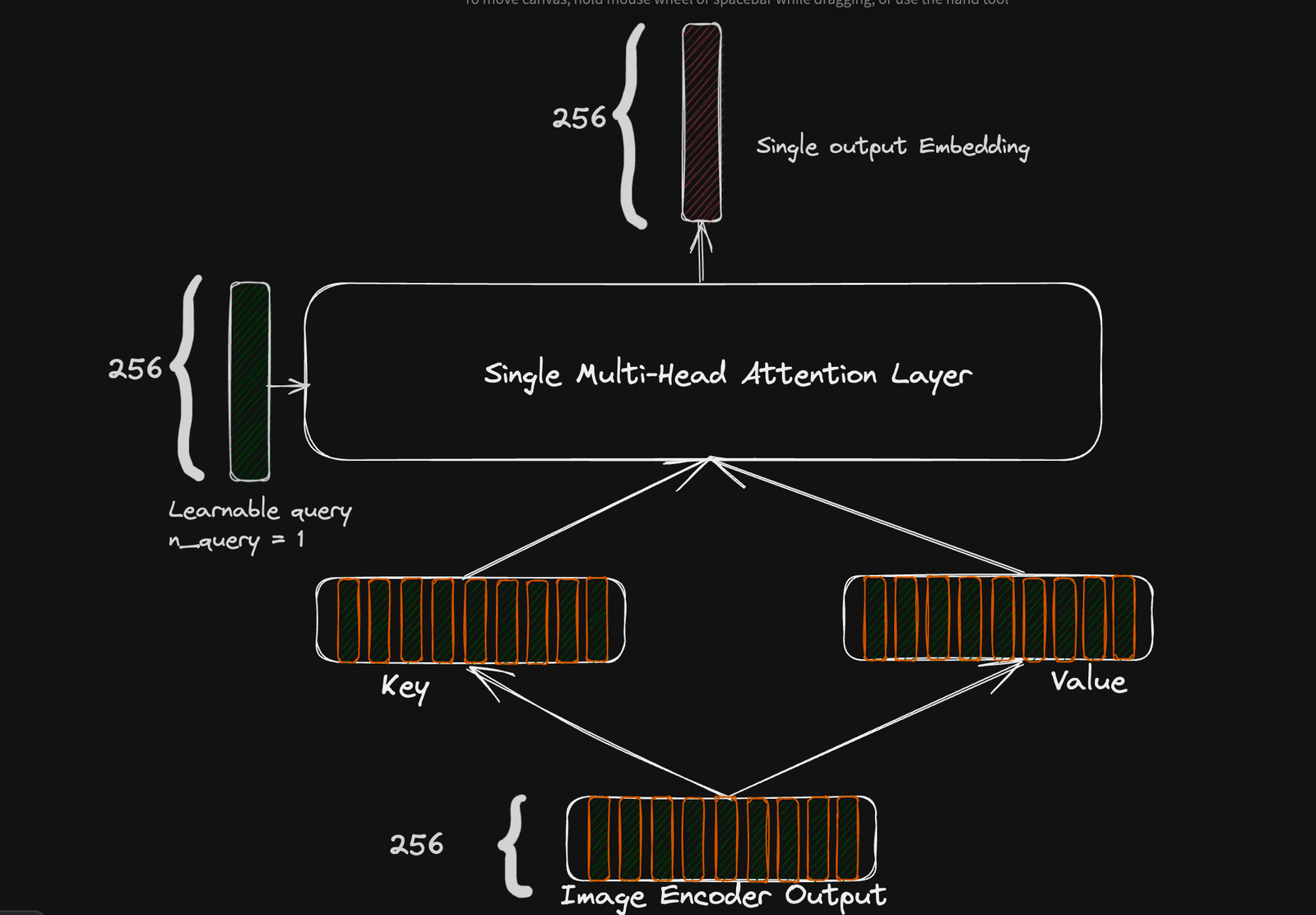
Attention pooling setup for contrastive loss. Output of attention layer is a single 256-dimension embedding.
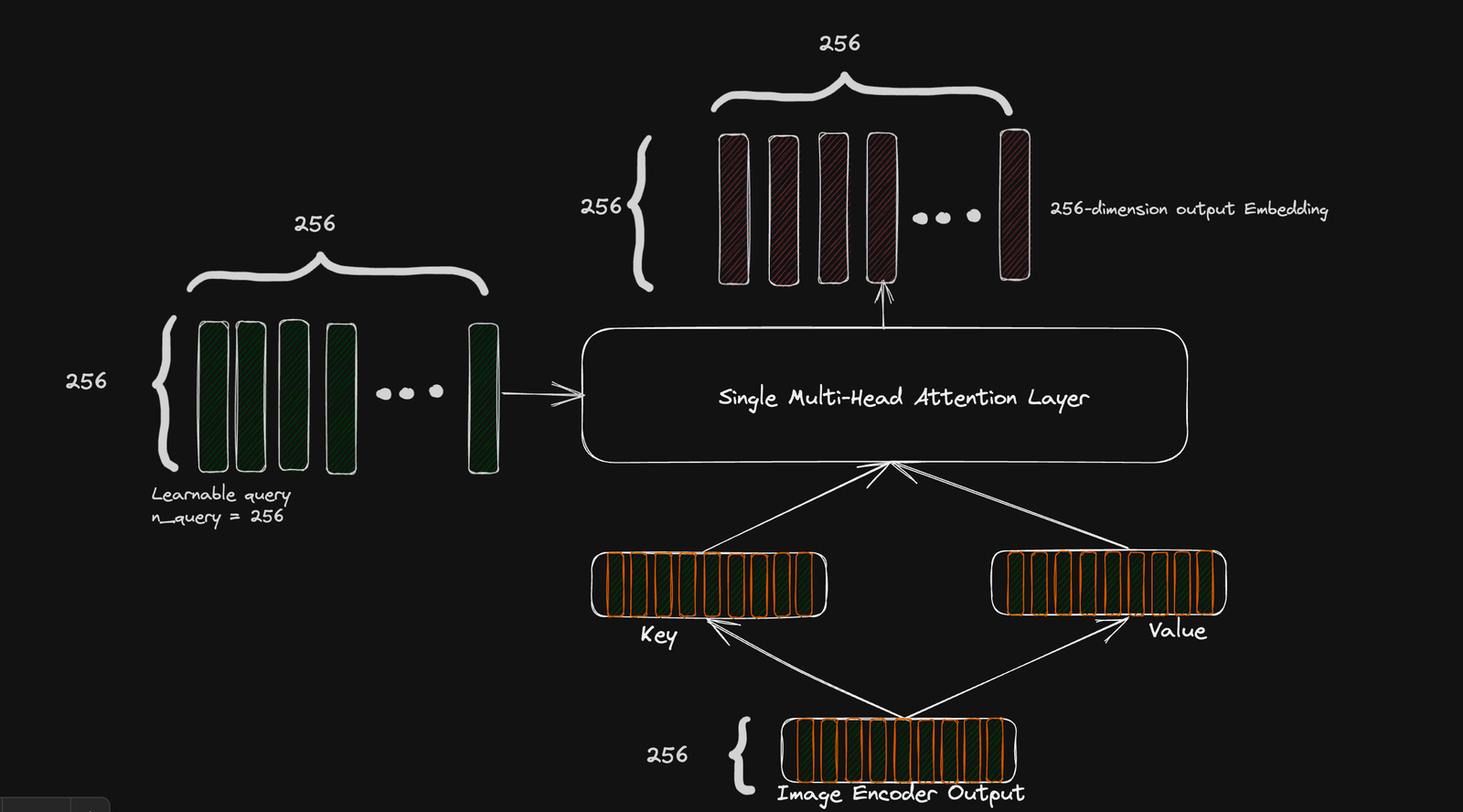
Generative Objective
Unlike the contrastive objective, which only requires a global representation of the image, the generative objective is more effective when we generate a more fine-grain representation of the image.
As already explained, we obtain the fine-grain image representation by setting the query parameter to an arbitrary number (256 in the CoCa paper) which generates a 256 x 256 rich representation of the image.
This representation is passed to the upper part of the decoupled decoder setup, and through cross-modal interaction with the unimodal text representation (ignoring the CLS representation), we obtain a unified image-text representation which is used to predict a probability distribution of the vocabulary through an autoregression factorization.
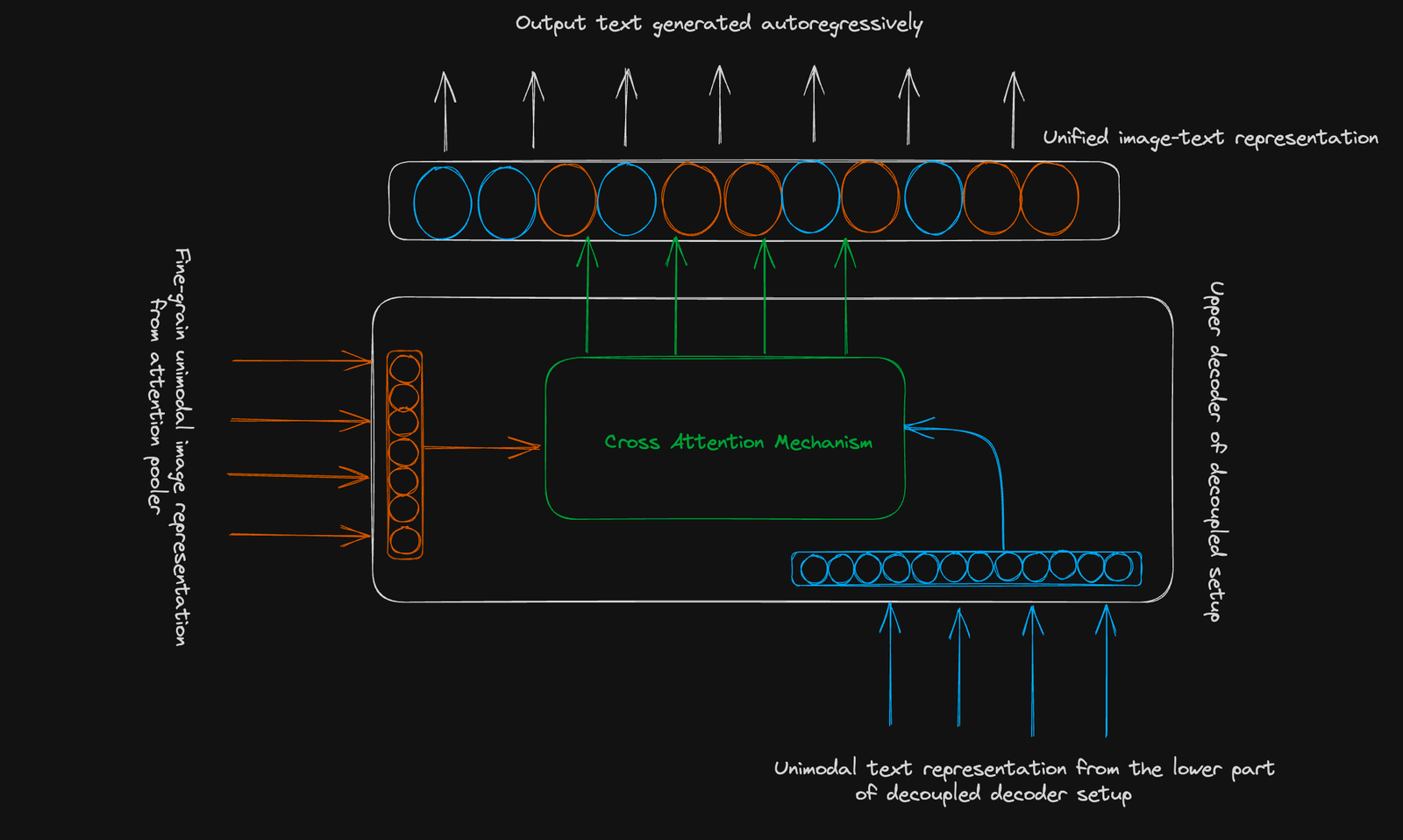
As illustrated in the previous two sections of this writing, the architectural setup of the CoCa model allows for subsuming the capabilities of a class of models that excel at zero-shot learning tasks such as image classification and cross-modal retrieval, and another class of models that excel at VQA and image captioning. The CoCa model can also be fine-tuned on several downstream vision and language tasks.
Final Thoughts
The advent of foundation models like CoCa marks a significant stride in the field of machine learning. CoCa amalgamates the strengths of various paradigms, offering a unified model capable of aligning image and text representations and generating joint image-text representations.
This model stands as a testament to the potential of integrating contrastive and generative objectives, paving the way for enhanced performance in tasks like Visual Question Answering and image captioning. It subsumes the capabilities of models excelling at zero-shot learning tasks and those proficient at multimodal image-text understanding tasks, providing a versatile tool for numerous downstream vision and language tasks.
For those who are keen to delve deeper into advanced concepts in machine learning and explore the intricacies of deep learning, the Advanced Deep Learning with Keras Course on DataCamp will equip you with the knowledge and skills to solve a variety of problems using the versatile Keras functional API, allowing you to explore and understand advanced models like CoCa and their underlying principles in greater depth.





