
Course
Working with DeepSeek in Python
3 hr
1.2K
DeepSeek recently released DeepSeek V3.1, a large-scale hybrid reasoning model that supports both “think” and “non-think” answer modes, making it ideal for interactive document analysis.
In this blog, I’ll focus on DeepSeek V3.1’s agentic capabilities for understanding research papers. I’ll explain step by step how to turn any PDF into an interactive research assistant through a Streamlit app—I’ll walk you through:
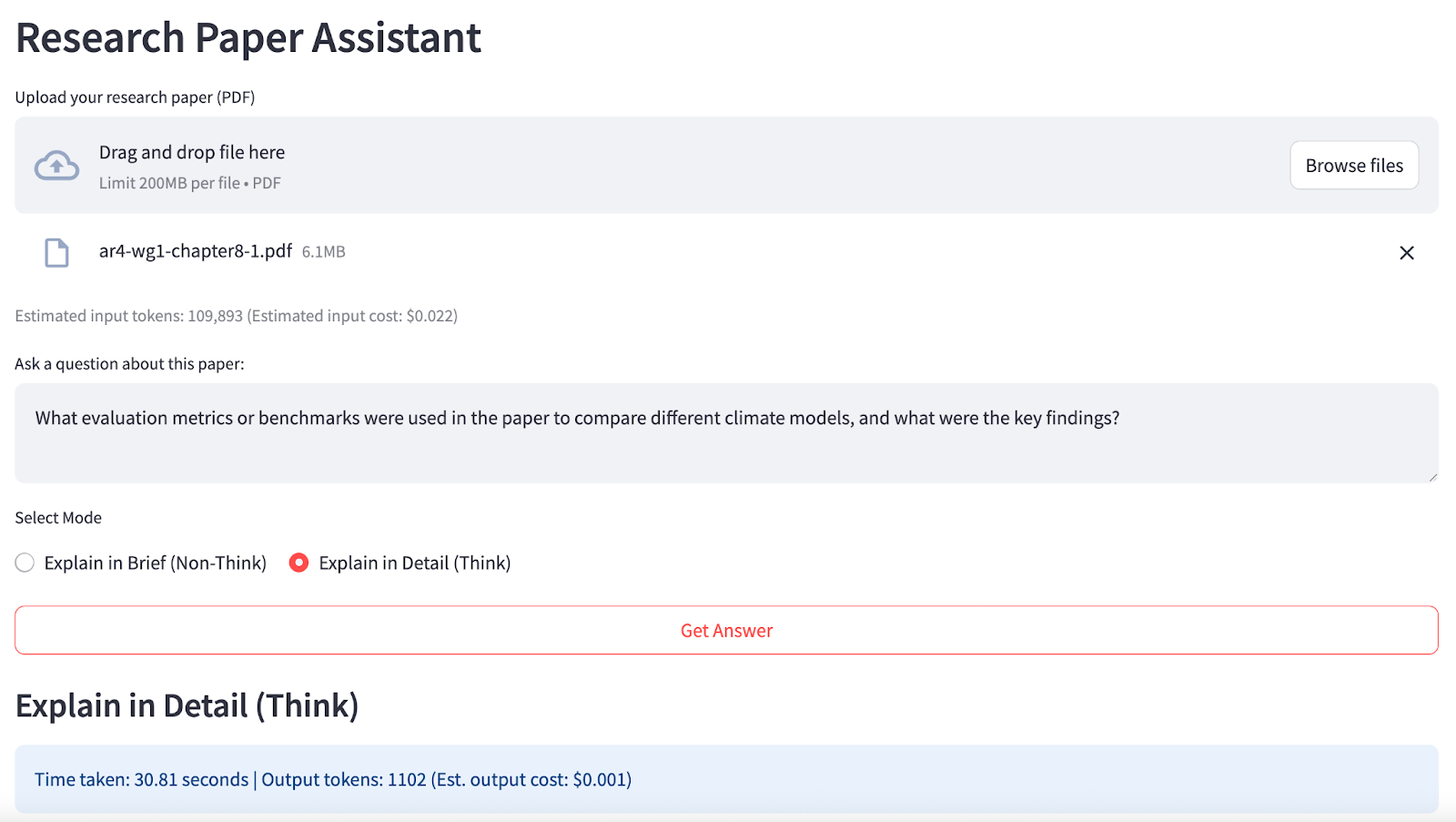
At the end, your app will look like this:
DeepSeek V3.1 is a 671B-parameter, hybrid Mixture-of-Experts (MoE) model trained for both "thinking" (detailed, reasoned) and "non-thinking" (factual, concise) answering styles. It supports 128,000-token contexts and is accessible via OpenRouter’s OpenAI-compatible API.
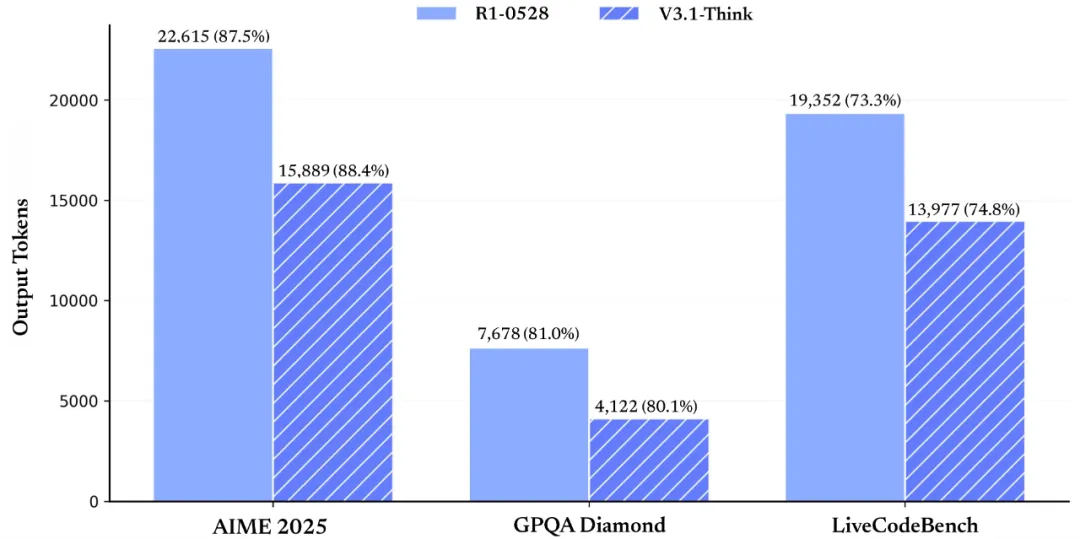
Source: DeepSeek
DeepSeek V3.1’s most important features are:
In this section, I’ll walk through how I used DeepSeek V3.1 to turn any uploaded PDF research paper into an interactive, AI-powered research assistant.
Here’s how it works:
Before running this demo, let’s make sure we have all the prerequisites in place.
First, ensure you have the following imports installed:
pip install streamlit openai pypdfThis command ensures you have all the core dependencies for UI, PDF handling, and API requests.
DeepSeek V3.1 model is available through numerous platforms along with the DeepSeek Official API. However, I used OpenRouter instead, which provides users access to multiple API keys for numerous models and was the most cost-effective for the purpose of this demo. Here are the steps to set up an API Key for DeepSeek V3.1:
Now, set your API key as an environment variable before running the app:
export OPENROUTER_API_KEY=your_api_keyThe official DeepSeek API is best suited for high-volume, automated workloads.
For most research, educational, or demo use cases, including this Streamlit Research Paper Assistant, I’d prefer OpenRouter because it is a simpler and more flexible choice. It offers predictable global pricing with no time-window restrictions or cache logic to manage, making it perfect for ad hoc analysis, unique document queries, and easy collaboration.
Note: Using DeepSeek V3.1 through the API requires only around 8 GB of memory for the UI, sparing you from the need to locally host the massive 670B-parameter model, which would otherwise require 170+ GB of disk space and a powerful GPU.
To make DeepSeek V3.1 available through a user-friendly interface, we’ll use Streamlit as our app framework and connect it to the model via OpenRouter’s OpenAI-compatible API.
This step covers environment setup, API authentication, and basic Streamlit configuration.
import streamlit as stimport pypdfimport tempfilefrom openai import OpenAIimport osimport timeimport rest.set_page_config( page_title="DeepSeek V3.1 Research Assistant", layout="wide")with st.sidebar: st.title("Research Paper Assistant") st.info("Tip: Ask about the methods, findings, or reasoning for best results.")OPENROUTER_API_KEY = os.environ.get("OPENROUTER_API_KEY", "")if not OPENROUTER_API_KEY: st.warning("Add your OpenRouter API key to an environment variable.") st.stop()client = OpenAI( base_url="https://openrouter.ai/api/v1", api_key=OPENROUTER_API_KEY,)In the above code, the st.set_page_config() function call customizes the Streamlit app’s page title and layout. The app retrieves the OpenRouter API key from environment variables and an OpenAI-compatible client is instantiated, pointing to the OpenRouter API endpoint, ensuring all subsequent LLM calls are properly routed and authenticated for DeepSeek V3.1.
Before building the main workflow, we need robust utility functions to handle document processing and resource estimation. In this step, we define helper functions to extract text from uploaded PDFs, preview document content, count the approximate number of tokens, and estimate cost based on OpenRouter’s DeepSeek V3.1 pricing.
def pdf_to_text(uploaded_file): with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as tmp_file: tmp_file.write(uploaded_file.read()) tmp_path = tmp_file.name reader = pypdf.PdfReader(tmp_path) text = "" for page in reader.pages: page_text = page.extract_text() if page_text: text += page_text + "\n" return textdef preview_pdf_text(text, max_chars=600): preview = text[:max_chars] if len(text) > max_chars: preview += "\n...\n[Preview truncated]" return previewdef count_tokens(text): return max(1, int(len(text) / 4))def estimate_cost(tokens, mode="input"): if mode == "input": return tokens / 1_000_000 * 0.20 else: return tokens / 1_000_000 * 0.80With these helper functions implemented, our backend is well-prepared to support a scalable research assistant interface:
pdf_to_text() function processes multi-page PDFs into plain text while preserving page boundaries, making the data suitable for LLM input and further downstream processing.count_tokens() function provides an approximate token count to help monitor API usage relative to DeepSeek’s high context window. While the estimate_cost() function then translates these token counts into real-time cost feedback using OpenRouter’s pricing for input and output, keeping the user informed about the computational budget for each query.preview_pdf_text() function creates truncated previews, allowing users to verify the integrity and relevance of the extracted content before incurring model costs or hitting API limits.With these building blocks in place, we can now move on to assembling the complete Streamlit app for long-context, agentic research paper Q&A.
With the core utilities in place, we can now assemble the main Streamlit user interface that brings together PDF processing, token/cost estimation, user-driven Q&A, and live interaction with DeepSeek V3.1 via OpenRouter.
st.header("Research Paper Assistant")pdf_file = st.file_uploader("Upload your research paper (PDF)", type=["pdf"])if "paper_text" not in st.session_state or st.session_state.get("last_uploaded") != pdf_file: if pdf_file is not None: with st.spinner("Extracting text from PDF..."): st.session_state.paper_text = pdf_to_text(pdf_file) st.session_state.last_uploaded = pdf_file st.success(f"PDF uploaded. Total characters extracted: {len(st.session_state.paper_text):,}") with st.expander("Preview of extracted PDF text:"): st.code(preview_pdf_text(st.session_state.paper_text), language='markdown')paper_text = st.session_state.get("paper_text")if paper_text: input_tokens = count_tokens(paper_text) st.caption(f"Estimated input tokens: {input_tokens:,} (Estimated input cost: ${estimate_cost(input_tokens):.3f})") question = st.text_area("Ask a question about this paper:", height=80, placeholder="E.g. What are the main findings?") mode = st.radio( "Select Mode", ["Explain in Brief (Non-Think)", "Explain in Detail (Think)"], horizontal=True, ) go = st.button("Get Answer", use_container_width=True) if question and go: if mode == "Explain in Brief (Non-Think)": prompt = ( f"{paper_text}\n\n" f"Question: {question}\n" "First, answer in a few sentences. Then, quote 1–2 exact sentences from the above paper that best support your answer. " "Show each quote on a new line." ) thinking_flag = False header = "Explain in Brief (Non-Think)" else: prompt = ( f"{paper_text}\n\n" f"Question: {question}\n" "First, answer in detail with reasoning and evidence. Then, quote 2–3 exact sentences from the above paper that most strongly support your answer. " "List the quotes after your answer." ) thinking_flag = True header = "Explain in Detail (Think)" with st.spinner(f"Generating answer..."): start_time = time.perf_counter() try: response = client.chat.completions.create( model="deepseek/deepseek-chat-v3.1", messages=[ {"role": "system", "content": "You are a helpful research assistant."}, {"role": "user", "content": prompt} ], max_tokens=900, extra_body={"thinking": thinking_flag}, ) answer = response.choices[0].message.content.strip() output_tokens = count_tokens(answer) except Exception as e: answer = f"Error: {e}" output_tokens = 0 end_time = time.perf_counter() elapsed_time = end_time - start_time parts = re.split(r"(?:^|\n)(Quotes?:?)", answer, flags=re.IGNORECASE) if len(parts) >= 3: main_answer = parts[0].strip() quotes = parts[2].strip() else: main_answer = answer quotes = None st.markdown(f"### {header}") st.info(f"Time taken: {elapsed_time:.2f} seconds | Output tokens: {output_tokens} (Est. output cost: ${estimate_cost(output_tokens, 'output'):.3f})") st.write(main_answer) if quotes: st.markdown("**Supporting Quotes:**") st.success(quotes)This Streamlit application implements a dynamic research paper assistant using DeepSeek V3.1, handling everything from document ingestion to context-aware LLM Q&A. Here are the key functions handled by the StreamLit application:
The user uploads a PDF file through the interface, then:
st.session_state to see if the file is new. If so, it extracts the text and caches it in session_state along with the upload reference, avoiding repeated extraction on every interaction.Once a document is loaded, the user can type a question and select between Non-think and Think mode, where the UI adapts the prompt instructions for each mode:
When the user clicks "Get Answer," then the app:
thinking parameter in the OpenRouter API request (extra_body={"thinking": thinking_flag}), ensuring the model runs in the correct reasoning mode, rather than relying on temperature.The returned answer is parsed such that the main response and supporting quotes are split (if found). Then, both the answer and the extracted quotes are rendered in the UI, highlighting the precise textual evidence from the source paper.
To try it yourself, save the code as app.py and launch:
streamlit run app.pyLearn AI with these courses!
Course
Course
Course
blog
François Aubry
8 min
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt