Course
Machine Learning with caret in R
4 hr
60.7K
Did you ever want to build a machine learning ensemble, but did not know how to get started? This tutorial will help you on your way with SuperLearner. This R package provides you with an easy way to create machine learning ensembles with the use of high level functions by offering a standardized wrapper to fit an ensemble using popular R machine learing libraries such as glmnet, knn, randomForest and many more!
In this tutorial, you'll tackle the following topics:
SuperLearner and what does this package actually do?SuperLearner: in this section, you'll learn how to install the packages you need, prepare the data and create your first ensemble model! You'll also see how you can train the mode and make predictions with it. In doing so, you'll cover Kernel Support Vector Machines, Bayes Generalized Linear Models and Bagging. Lastly, you'll see how you can tune the hyperparameters to further improve your model's performance!When you are finished, you will have fit your first ensemble, predicted new data and tuned parts of the ensemble.
All this is awesome, but what exactly is an ensemble?
An ensemble occurs when the probability predictions or numerical predictions of multiple machine models are combined by averaging, weighting each model and adding them together or using the most common observation between models. This provides a multiple vote scenario that is likely to drive a prediction to the correct class or closer to the correct number in regression models. Ensembles tend to work best when there are disagreements between the models being fit. The concept of combining multiple models also seems to perform well in practice, often above implementations of single algorithms.
Ensembles can be created manually by fitting multiple models, predicting with each of them and then combining them.
SuperLearner?Now that you have seen what ensembles are, you might ask yourself what the SuperLearner library exactly does. Well, simply put, SuperLearner is an algorithm that uses cross-validation to estimate the performance of multiple machine learning models, or the same model with different settings. It then creates an optimal weighted average of those models, which is also called an “ensemble”, using the test data performance.
But why would you use SuperLearner?
Even though you'll learn more about the power of this R package throughout the tutorial, you could already consider this list of advantages:
SuperLearner allows you to fit an ensemble model by simply adding algorithmsSuperLearner uses cross-validation, which is inherently used to estimate risk for all models. This makes SuperLearner great for model comparison!SuperLearner makes ensembling efficient by automatically estimating the weights of the ensemble. This is normally a task that can be very tedious and requires a lot of experimentation.SuperLearner automatically removes models that do not contribute to the ensemble prediction power, this leaves you free to experiment with numerous algorithms!Let's take a look at the process to use SuperLearner.
SuperLearnerSuperLearner PackageSuperLearner can be installed from CRAN with the install.packages() function and then loaded into your workspace using the library() function:
# Install the package
install.packages("SuperLearner")
# Load the package
library("SuperLearner")To illustrate SuperLearner, you will use the Pima Indian Women data set from the MASS package. The MASS package contains a training set, which is used for training a model and a test set, which is used for assessing the performance of the model on unseen data. The data set provides some descriptive factors about the Pima Indian Women such as number of pregnancies and age and whether or not they have diabetes. The purpose of the data set is to try to predict diabetes.
The type column is the column that indicates the presence of diabetes. It is a binary Yes or No column, which means that it follows a binomial distribution.
Note that, without getting too theoretical, a binomial distribution is a collection of Bernoulli trials, which are a success or failure test in probability. A binomial distribution is easily identified because there are only two possible responses, in this case Yes or No. Why are you getting into this? Well, SuperLearner requires you to define the family of problem your model should belong to. You will see that in more detail when you fit the model later in this tutorial.
# Get the `MASS` library
library(MASS)
# Train and test sets
train <- Pima.tr
test <- Pima.te
# Print out the first lines of `train`
head(train) ## npreg glu bp skin bmi ped age type
## 1 5 86 68 28 30.2 0.364 24 No
## 2 7 195 70 33 25.1 0.163 55 Yes
## 3 5 77 82 41 35.8 0.156 35 No
## 4 0 165 76 43 47.9 0.259 26 No
## 5 0 107 60 25 26.4 0.133 23 No
## 6 5 97 76 27 35.6 0.378 52 Yes # Get a summary of `train`
summary(train) ## npreg glu bp skin
## Min. : 0.00 Min. : 56.0 Min. : 38.00 Min. : 7.00
## 1st Qu.: 1.00 1st Qu.:100.0 1st Qu.: 64.00 1st Qu.:20.75
## Median : 2.00 Median :120.5 Median : 70.00 Median :29.00
## Mean : 3.57 Mean :124.0 Mean : 71.26 Mean :29.21
## 3rd Qu.: 6.00 3rd Qu.:144.0 3rd Qu.: 78.00 3rd Qu.:36.00
## Max. :14.00 Max. :199.0 Max. :110.00 Max. :99.00
## bmi ped age type
## Min. :18.20 Min. :0.0850 Min. :21.00 No :132
## 1st Qu.:27.57 1st Qu.:0.2535 1st Qu.:23.00 Yes: 68
## Median :32.80 Median :0.3725 Median :28.00
## Mean :32.31 Mean :0.4608 Mean :32.11
## 3rd Qu.:36.50 3rd Qu.:0.6160 3rd Qu.:39.25
## Max. :47.90 Max. :2.2880 Max. :63.00Tip: if you want to have more information on the variables of this data set, use the help() function, just like here:
help(Pima.tr)By running the above command, you can derive that the type column indicates diabetes.
SuperLearner also requires the response variable to be encoded if it is a classification problem. Since you are solving a binomial classification problem, you will encode the factor for the variable type to 0-1 encoding:
y <- as.numeric(train[,8])-1
ytest <- as.numeric(test[,8])-1Since the type column was a factor, R will encode it to 1 and 2, but this is not what you want: ideally, you would like to work with the type encoded as 0 and 1, which are "No" and "Yes", respectively. In the above code chunk, you subtract 1 from the whole set to get your 0-1 encoding. R will also encode this in the factor order.
The package also requires that the predictors (X) and responses (Y) to be in their own data structures. You split out Y above, now you need to split out X. You will go ahead and split out your test set as well:
x <- data.frame(train[,1:7])
xtest <- data.frame(test[,1:7])Note that some algorithms do not just require a data frame, but would require a model matrix saved as a data frame. An example is the nnet algorithm. When solving a regression problem, you will almost always use the model matrix to store your data for SuperLearner. All a model matrix does is split out factor variables into their own columns and recodes them as 0-1 values instead of text values. It does not impact numerical columns. The model matrix will increase the number of columns an algorithm has to deal with, therefore it could increase computational time. For a small data set, such as this, there is minimal impact, but larger data sets could be heavily affected. The moral of the story is to decide which algorithms you will want to try before fitting your model. For this simple example, you will just use the data frame for the existing data structure.
SuperLearnerTo start creating your first model, you can use the following command to preview what models are available in the package:
listWrappers() ## All prediction algorithm wrappers in SuperLearner:
## [1] "SL.bartMachine" "SL.bayesglm" "SL.biglasso"
## [4] "SL.caret" "SL.caret.rpart" "SL.cforest"
## [7] "SL.dbarts" "SL.earth" "SL.extraTrees"
## [10] "SL.gam" "SL.gbm" "SL.glm"
## [13] "SL.glm.interaction" "SL.glmnet" "SL.ipredbagg"
## [16] "SL.kernelKnn" "SL.knn" "SL.ksvm"
## [19] "SL.lda" "SL.leekasso" "SL.lm"
## [22] "SL.loess" "SL.logreg" "SL.mean"
## [25] "SL.nnet" "SL.nnls" "SL.polymars"
## [28] "SL.qda" "SL.randomForest" "SL.ranger"
## [31] "SL.ridge" "SL.rpart" "SL.rpartPrune"
## [34] "SL.speedglm" "SL.speedlm" "SL.step"
## [37] "SL.step.forward" "SL.step.interaction" "SL.stepAIC"
## [40] "SL.svm" "SL.template" "SL.xgboost"
##
## All screening algorithm wrappers in SuperLearner:
## [1] "All"
## [1] "screen.corP" "screen.corRank" "screen.glmnet"
## [4] "screen.randomForest" "screen.SIS" "screen.template"
## [7] "screen.ttest" "write.screen.template"You will notice there are prediction algorithm wrappers and screening algorithm wrappers. There are some popular libraries in here that can be used for either classification, regression or both. The screening algorithms are used for automated variable selection by SuperLearner.
When you want to use an algorithm from the above list, you'll need to have the package installed in your environment. That's because SuperLearner is really calling these packages and then fitting the models when the method is used. That also means that if you never use the method SL.caret, for example, you do not need to have the caret package installed.
Fitting the model is simple, but you'll go through this step-by-step with a single model example.
You will fit the Ranger algorithm, which is a faster implementation of the famous Random Forest.
Remember that a Random Forest is a powerful method which is actually an ensembling of decision trees. Decision trees work by observing your data and calculating a probability split between each variable in the model, giving you a pathway to your prediction. Decision trees have a habit of overfitting to their data, which means they do not generalize well to new data. Random Forest solves this problem by growing multiple decision trees based on numerous samples of data and then averages those predictions to find the correct prediction. It also only selects a subset of the features for each sample, which is how it differs from tree bagging. This creates a model that is not overfitting the data. Cool, right?
In this case, it could be that you first need to install the ranger library with install.packages() function before you can start fitting the model.
If you have done that, you can continue and use SL.ranger in the SuperLearner() function.
Since Random Forest -and therefore Ranger- contain random sampling in the algorithm, you will not get the same result if you fit it more than once. Therefore, for this exercise, you will set the seed so you can reproduce the examples and also compare multiple models on the same random seed baseline. R uses set.seed() to set the random seed. The seed can be any number, in this case, you will use 150.
set.seed(150)
single.model <- SuperLearner(y,
x,
family=binomial(),
SL.library=list("SL.ranger"))SuperLearner requires a Y variable, which is the response or outcome you want, an X variable, which are the predictor variables, the family to use, which can be guassian or binomial and the library to use in the form of a list. That's SL.ranger in this case.
Do you remember the whole binomial distribution discussion that you read about earlier? Now, you see why you needed to know that: using the gaussian model would not have yielded proper predictions in your 0-1 range.
Next, simply printing the model provides the coefficient, which is the weight of the algorithm in the model and the risk factor which is the error the algorithm produces. Behind the scenes, the package fits each algorithm used in the ensemble to produce the risk factor.
single.model ##
## Call:
## SuperLearner(Y = y, X = x, family = binomial(), SL.library = list("SL.ranger"))
##
##
##
## Risk Coef
## SL.ranger_All 0.1759541 1In this case, your risk factor is less than 0.20. Of course, this will need to be tested through external cross validation and in the test set, but it is a good start. The beauty of SuperLearner is that it tries to automatically build an ensemble through the use of cross validation. Of course, if there is only one model, then it gets the full weight of the ensemble.
So this single model is great, but you can do this without SuperLearner. How can you fit ensemble models?
Ensembling with SuperLearner is as simple as selecting the algorithms to use. In this case, let's add Kernel Support Vector Machines (KSVM) from the kernlab package, Bayes Generalized Linear Models (GLM) from the arm package and bagging from the ipred package.
But what are KSVM and Bayes GLM?
The KSVM uses something called "the kernel trick" to calculate distance between points. Instead of having to draw a map of the features and calculate coordinates, the kernel method calculates the inner products between points. This allows for faster computation. Then the support vector machine is used to learn the non-linear boundary between points in classification. A support vector machine attempts to create a gap between two classes in a machine learning problem that is often nonlinear. It then classifies new points on either side of that gap based on where they are in space.
The Bayes GLM model is simply an implementation of logistic regression. At least in this case, where you are classifying a 0-1 problem. Bayes GLM differs from KSVM in that it uses an augmented regression algorithm to update the coefficients at each step. Bagging is similar to random forest above without subsetting the features. This means that you will grow multiple decision trees from random samples and average them together to get your prediction.
Now let's fit your first ensemble!
Tip: don't forget to install these packages if you don't have them yet! Additionally, you might also be prompted to install other required packages.
# Set the seed
set.seed(150)
# Fit the ensemble model
model <- SuperLearner(y,
x,
family=binomial(),
SL.library=list("SL.ranger",
"SL.ksvm",
"SL.ipredbagg",
"SL.bayesglm"))
# Return the model
model ##
## Call:
## SuperLearner(Y = y, X = x, family = binomial(), SL.library = list("SL.ranger",
## "SL.ksvm", "SL.ipredbagg", "SL.bayesglm"))
##
##
## Risk Coef
## SL.ranger_All 0.1756230 0.000000
## SL.ksvm_All 0.1838340 0.000000
## SL.ipredbagg_All 0.1664828 0.524182
## SL.bayesglm_All 0.1677593 0.475818Adding these algorithms improved your model and changed the landscape. Ranger and KVSM have a coefficient of zero, which means that it is not weighted as part of the ensemble anymore. Bayes GLM and Bagging make up the rest of the weight of the model. You will notice SuperLearner is calculating this risk for you and deciding on the optimal model mix that will reduce the error.
To understand each model's specific contribution to the model and the variation, you can use SuperLearner's internal cross-validation function CV.SuperLearner(). To set the number of folds, you can use the V argument. In this case, you will set it to 5:
# Set the seed
set.seed(150)
# Get V-fold cross-validated risk estimate
cv.model <- CV.SuperLearner(y,
x,
V=5,
SL.library=list("SL.ranger",
"SL.ksvm",
"SL.ipredbagg",
"SL.bayesglm"))
# Print out the summary statistics
summary(cv.model) ##
## Call:
## CV.SuperLearner(Y = y, X = x, V = 5, SL.library = list("SL.ranger",
## "SL.ksvm", "SL.ipredbagg", "SL.bayesglm"))
##
## Risk is based on: Mean Squared Error
##
## All risk estimates are based on V = 5
##
## Algorithm Ave se Min Max
## Super Learner 0.17277 0.014801 0.16250 0.19557
## Discrete SL 0.17964 0.014761 0.16363 0.19244
## SL.ranger_All 0.17866 0.015004 0.14811 0.20518
## SL.ksvm_All 0.19382 0.020301 0.15685 0.26215
## SL.ipredbagg_All 0.17791 0.015858 0.15831 0.19244
## SL.bayesglm_All 0.16628 0.014318 0.15322 0.18022The summary of cross validation shows the average risk of the model, the variation of the model and the range of the risk.
Plotting this also produces a nice plot of the models used and their variation:
plot(cv.model)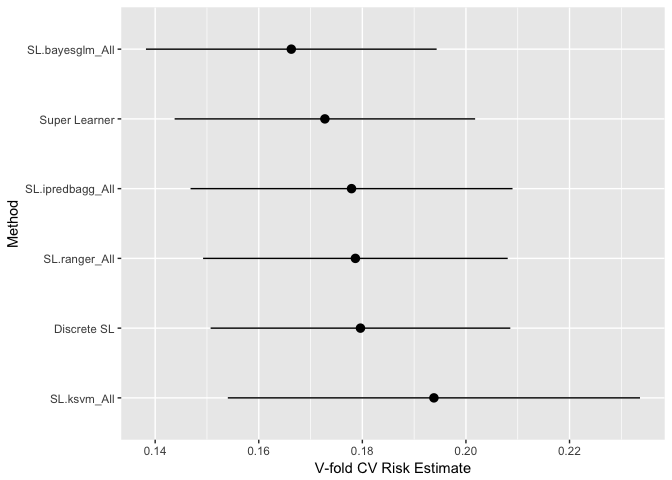
It's easy to see that Bayes GLM performs the best on average while KSVM performs the worst and contains a lot of variation compared to the other models. The beauty of SuperLearner is that, if a model does not fit well or contribute much, it is just weighted to zero! There is no need to remove it and retrain unless you plan on retraining the model in the future. Just remember that proper model training involves cross validation of the entire model. In a real-world setting, that is how you would determine the risk of the model before predicting new data.
With the specific command predict.SuperLearner() you can easily make predictions on new data sets. That means that you can not use the normal predict() function!
predictions <- predict.SuperLearner(model, newdata=xtest)The function predict.SuperLearner() takes a model argument (a SuperLearner fit model) and new data to predict on. Predictions will first return the overall ensemble predictions:
head(predictions$pred) ## [,1]
## [1,] 0.79322181
## [2,] 0.11895658
## [3,] 0.04612200
## [4,] 0.05928159
## [5,] 0.68824522
## [6,] 0.54373451It will also return the individual library predictions:
head(predictions$library.predict) ## SL.ranger_All SL.ksvm_All SL.ipredbagg_All SL.bayesglm_All
## [1,] 0.796 0.8089502 0.82086658 0.76276712
## [2,] 0.129 0.1580203 0.18586049 0.04525230
## [3,] 0.016 0.1579566 0.06255427 0.02801949
## [4,] 0.102 0.1885473 0.07238268 0.04484885
## [5,] 0.638 0.7108875 0.58791672 0.79877149
## [6,] 0.550 0.6898737 0.37488066 0.72975132This allows you to see how each model classified each observation. This could be useful in debugging the model or fitting multiple models at once to see which to use further.
You may have noticed the prediction quantities being returned. They are in the form of probabilities. That means that you will need a cut off threshold to determine if you should classify a one or zero. This only needs to be done in the binomial classification case, not regression.
Normally, you would determine this in training with cross-validation, but for simplicity, you will use a cut off of 0.50. Since this is a simple binomial problem, you will use dplyr's ifelse() function to recode your probabilities:
# Load the package
library(dplyr)
# Recode probabilities
conv.preds <- ifelse(predictions$pred>=0.5,1,0)Now you can build a confusion matrix with caret to review the results:
# Load in `caret`
library(caret)
# Create the confusion matrix
cm <- confusionMatrix(conv.preds, ytest)
# Return the confusion matrix
cm
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 199 45
## 1 24 64
##
## Accuracy : 0.7922
## 95% CI : (0.7445, 0.8345)
## No Information Rate : 0.6717
## P-Value [Acc > NIR] : 8.166e-07
##
## Kappa : 0.5044
## Mcnemar's Test P-Value : 0.01605
##
## Sensitivity : 0.8924
## Specificity : 0.5872
## Pos Pred Value : 0.8156
## Neg Pred Value : 0.7273
## Prevalence : 0.6717
## Detection Rate : 0.5994
## Detection Prevalence : 0.7349
## Balanced Accuracy : 0.7398
##
## 'Positive' Class : 0
##You are getting around 0.7921687 accuracy on this data set, which is good performance for this data set. Many algorithms have scored higher, but this is good for a quick ensemble. With some proper training with cross-validation and trying some different models, it is easy to see how you can quickly improve this score.
While model performance is not terrible, you can try to improve your performance by tuning some hyperparameters of some of the models that you have in the ensemble. Ranger was not weighted heavily in your model, but maybe that is because you need more trees and need to tune mtry parameter. Maybe you can improve bagging as well by increasing the nbagg parameter to 250 from the default of 25.
There are two methods for doing this: either you define a function that calls the learner and modifies a parameter or you use the create.Learner() function. In the next sections, you'll learn more about these options.
The first one is with the help of function(). Here, you would define a function that calls the learner and modifies a parameter. The function call uses the ellipsis ... to pass along additional arguments to a function. Those three little dots allow the modification to a formula without having to specify in the function what those modifications are. This means if you are changing 10 parameters, you do not need 10 objects in the function to map within the function. It is a generalizable way to write a function.
SL.ranger.tune <- function(...){
SL.ranger(..., num.trees=1000, mtry=2)
}
SL.ipredbagg.tune <- function(...){
SL.ipredbagg(..., nbagg=250)
}SL.ranger.tune is the name of your modified ranger method and SL.ipredbagg.tune is the name of your modified ipredbagg method. Now that you have some new learner functions created, you can pass these along to the cross validation formula to see if the performance improves.
Note that you will keep the original SL.ranger and SL.ipredbagg functions in the algorithm to see if performance improves on your tuned versions of the functions.
# Set the seed
set.seed(150)
# Tune the model
cv.model.tune <- CV.SuperLearner(y,
x,
V=5,
SL.library=list("SL.ranger",
"SL.ksvm",
"SL.ipredbagg","SL.bayesglm",
"SL.ranger.tune",
"SL.ipredbagg.tune"))
# Get summary statistics
summary(cv.model.tune) ##
## Call:
## CV.SuperLearner(Y = y, X = x, V = 5, SL.library = list("SL.ranger",
## "SL.ksvm", "SL.ipredbagg", "SL.bayesglm", "SL.ranger.tune", "SL.ipredbagg.tune"))
##
##
## Risk is based on: Mean Squared Error
##
## All risk estimates are based on V = 5
##
## Algorithm Ave se Min Max
## Super Learner 0.17272 0.014969 0.15849 0.19844
## Discrete SL 0.17250 0.014989 0.15645 0.18430
## SL.ranger_All 0.17897 0.015084 0.15388 0.19920
## SL.ksvm_All 0.19573 0.020278 0.16095 0.26304
## SL.ipredbagg_All 0.17667 0.015629 0.16473 0.18898
## SL.bayesglm_All 0.16628 0.014318 0.15322 0.18022
## SL.ranger.tune_All 0.17637 0.014882 0.15218 0.19793
## SL.ipredbagg.tune_All 0.17813 0.015869 0.16455 0.19260 # Plot the tuned model
plot(cv.model.tune)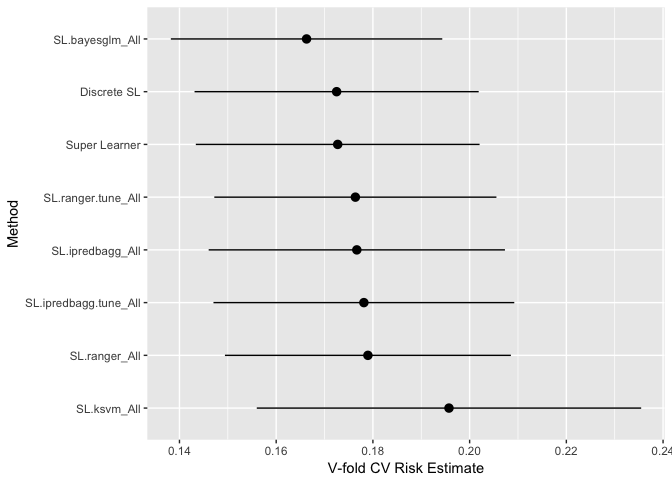
You can see from this plot that ipredbagg seems to improve as you increase the nbagg parameter as seen in SL.ipredbagg.tune. Ranger seems to get worse with tuning the parameters, but let's leave it in and see if SuperLearner finds it to be relevant.
Again, the beauty is SuperLearner will just set it to zero if it is not relevant. Remember, that the best ensembles are not composed of the best performing algorithms, but rather the algorithms that best complement each other to classify a prediction.
Let's fit the new model with tuned parameters and see how they weigh:
# Set the seed
set.seed(150)
# Create the tuned model
model.tune <- SuperLearner(y,
x,
SL.library=list("SL.ranger",
"SL.ksvm",
"SL.ipredbagg",
"SL.bayesglm",
"SL.ranger.tune",
"SL.ipredbagg.tune"))
# Return the tuned model
model.tune ##
## Call:
## SuperLearner(Y = y, X = x, SL.library = list("SL.ranger", "SL.ksvm",
## "SL.ipredbagg", "SL.bayesglm", "SL.ranger.tune", "SL.ipredbagg.tune"))
##
##
##
## Risk Coef
## SL.ranger_All 0.1748247 0.0000000
## SL.ksvm_All 0.1974033 0.0000000
## SL.ipredbagg_All 0.1745503 0.0000000
## SL.bayesglm_All 0.1634855 0.7162423
## SL.ranger.tune_All 0.1725514 0.0000000
## SL.ipredbagg.tune_All 0.1711161 0.2837577SL.bayesglm and SL.ipredbagg.tune are now the only algorithms weighted in the ensemble. Predicting on the test set gives the following result:
# Gather predictions for the tuned model
predictions.tune <- predict.SuperLearner(model.tune, newdata=xtest)
# Recode predictions
conv.preds.tune <- ifelse(predictions.tune$pred>=0.5,1,0)
# Return the confusion matrix
confusionMatrix(conv.preds.tune,ytest) ## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 200 43
## 1 23 66
##
## Accuracy : 0.8012
## 95% CI : (0.7542, 0.8428)
## No Information Rate : 0.6717
## P-Value [Acc > NIR] : 1.116e-07
##
## Kappa : 0.5271
## Mcnemar's Test P-Value : 0.01935
##
## Sensitivity : 0.8969
## Specificity : 0.6055
## Pos Pred Value : 0.8230
## Neg Pred Value : 0.7416
## Prevalence : 0.6717
## Detection Rate : 0.6024
## Detection Prevalence : 0.7319
## Balanced Accuracy : 0.7512
##
## 'Positive' Class : 0
##This gives you a little improvement on the test set and illustrates the concepts of using SuperLearner for model tuning.
create.Learner()The second method for tuning hyperparameters is to use the create.Learner() function. This allows you to customize an existing SuperLearner:
learner <- create.Learner("SL.ranger", params=list(num.trees=1000, mtry=2))
learner2 <- create.Learner("SL.ipredbagg", params=list(nbagg=250))The learner character string is the first argument to the create.Learner() function. Then you pass a list of the parameters to modify. This will create an object:
learner ## $grid
## NULL
##
## $names
## [1] "SL.ranger_1"
##
## $base_learner
## [1] "SL.ranger"
##
## $params
## $params$num.trees
## [1] 1000
##
## $params$mtry
## [1] 2Now, when passing the learner to SuperLearner, you use the names object in the learner object:
# Set the seed
set.seed(150)
# Create a second tuned model
cv.model.tune2 <- CV.SuperLearner(y,
x,
V=5,
SL.library=list("SL.ranger",
"SL.ksvm",
"SL.ipredbagg",
"SL.bayesglm",
learner$names,
learner2$names))
# Get summary statistics
summary(cv.model.tune2) ##
## Call:
## CV.SuperLearner(Y = y, X = x, V = 5, SL.library = list("SL.ranger",
## "SL.ksvm", "SL.ipredbagg", "SL.bayesglm", learner$names, learner2$names))
##
##
## Risk is based on: Mean Squared Error
##
## All risk estimates are based on V = 5
##
## Algorithm Ave se Min Max
## Super Learner 0.17272 0.014969 0.15849 0.19844
## Discrete SL 0.17250 0.014989 0.15645 0.18430
## SL.ranger_All 0.17897 0.015084 0.15388 0.19920
## SL.ksvm_All 0.19573 0.020278 0.16095 0.26304
## SL.ipredbagg_All 0.17667 0.015629 0.16473 0.18898
## SL.bayesglm_All 0.16628 0.014318 0.15322 0.18022
## SL.ranger_1_All 0.17637 0.014882 0.15218 0.19793
## SL.ipredbagg_1_All 0.17813 0.015869 0.16455 0.19260 # Plot `cv.model.tune2`
plot(cv.model.tune2)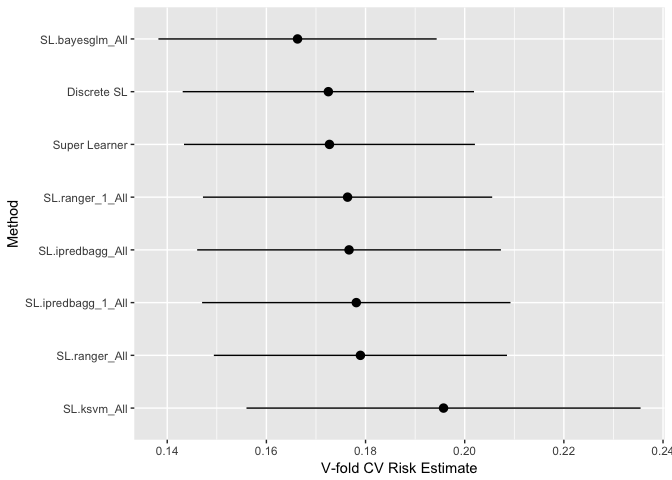
The end result is the same as if you used the first method. It is up to you to use whatever method you desire.
Wow, you covered a lot of ground! By now, you should have a good handle on the SuperLearner and should have successfully fit your first ensemble with SuperLearner. This package makes it nice and easy to add models really quickly. There are some subtlies with methods and what data form to use. However, when in doubt, a model matrix saved as a data frame almost always works.
As a reminder, you installed and loaded SuperLearner, formatted your dataset, fit a single model, fit your first ensemble, predicted with the ensemble and tuned some hyperparameters!
The next steps would be to tackle some more advanced topics with this package, such as parallelization, feature selection and screening, using model matrices, writing your own SuperLearner and ensemble cross validation.
Check out DataCamp's Machine Learning in R for beginners tutorial.
Learn more about R and Machine Learning
Course
Course
Course
Tutorial
Zoumana Keita
Tutorial
Karlijn Willems
Tutorial
James Le
Tutorial
Karlijn Willems
Tutorial
Arunn Thevapalan
Tutorial
DataCamp Team
