Euclidean distance, a concept that traces its roots back to ancient Greek mathematics, has become an essential tool in modern data science, machine learning, and spatial analysis. Named after the famous Euclid, this metric provides a fundamental way to measure the straight-line distance between points in space, whether in two dimensions or many more.
What is Euclidean Distance?
Euclidean distance represents the shortest path between two points in Euclidean space. It's the distance you would measure with a ruler, extended to any number of dimensions. This concept is deeply rooted in the Pythagorean theorem, which states that in a right-angled triangle, the square of the length of the hypotenuse equals the sum of squares of the other two sides.

“Philosopher teaching Euclidean distance.” Image by Dall-E
The Euclidean Distance Formula
Let's break down the Euclidean distance formula for different dimensions:
2D Euclidean distance
In a two-dimensional plane, the Euclidean distance between points A(x₁, y₁) and B(x₂, y₂) is given by:
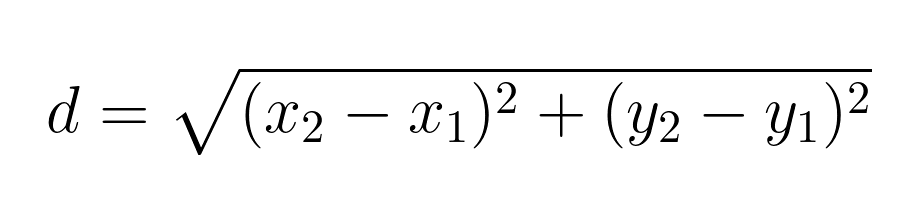
For example, let's calculate the distance between points A(1, 2) and B(4, 6):
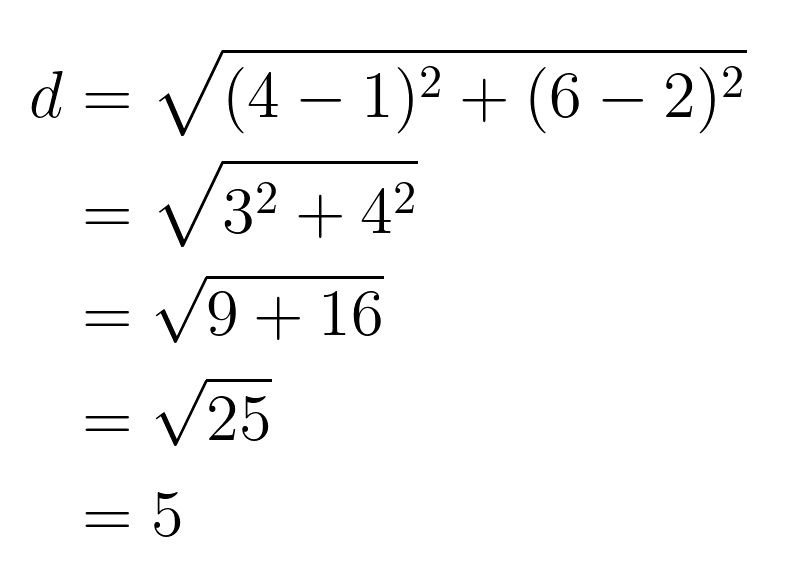
2D Euclidean distance visualization
To better understand 2D Euclidean distance, let's visualize it:
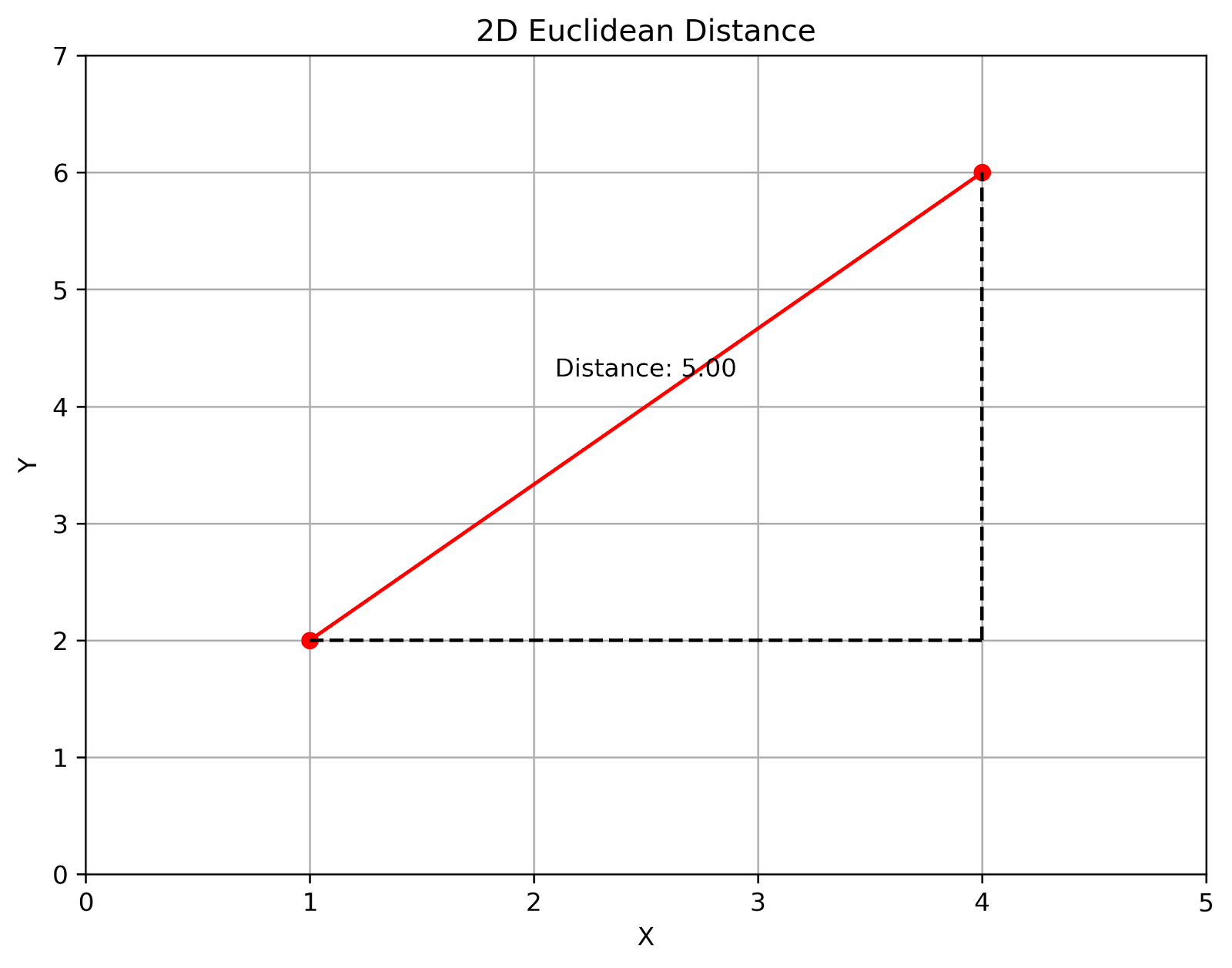
2D Euclidean distance. Image by Author
This visualization shows the Euclidean distance between two points in a 2D plane. The red line represents the direct distance, while the dashed lines form a right triangle, illustrating the Pythagorean theorem in action.
3D Euclidean distance
Extending to three dimensions, for points A(x₁, y₁, z₁) and B(x₂, y₂, z₂), the formula becomes:
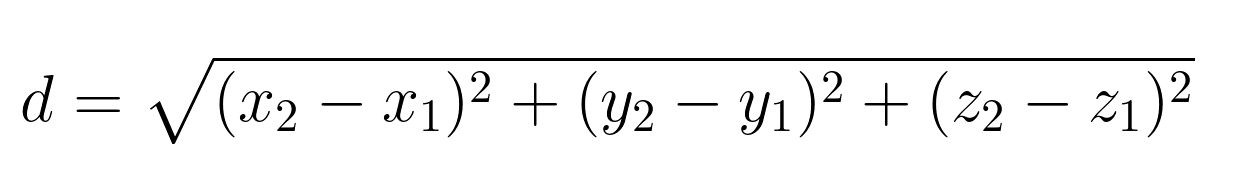
3D Euclidean distance visualization
Let's visualize the 3D Euclidean distance:
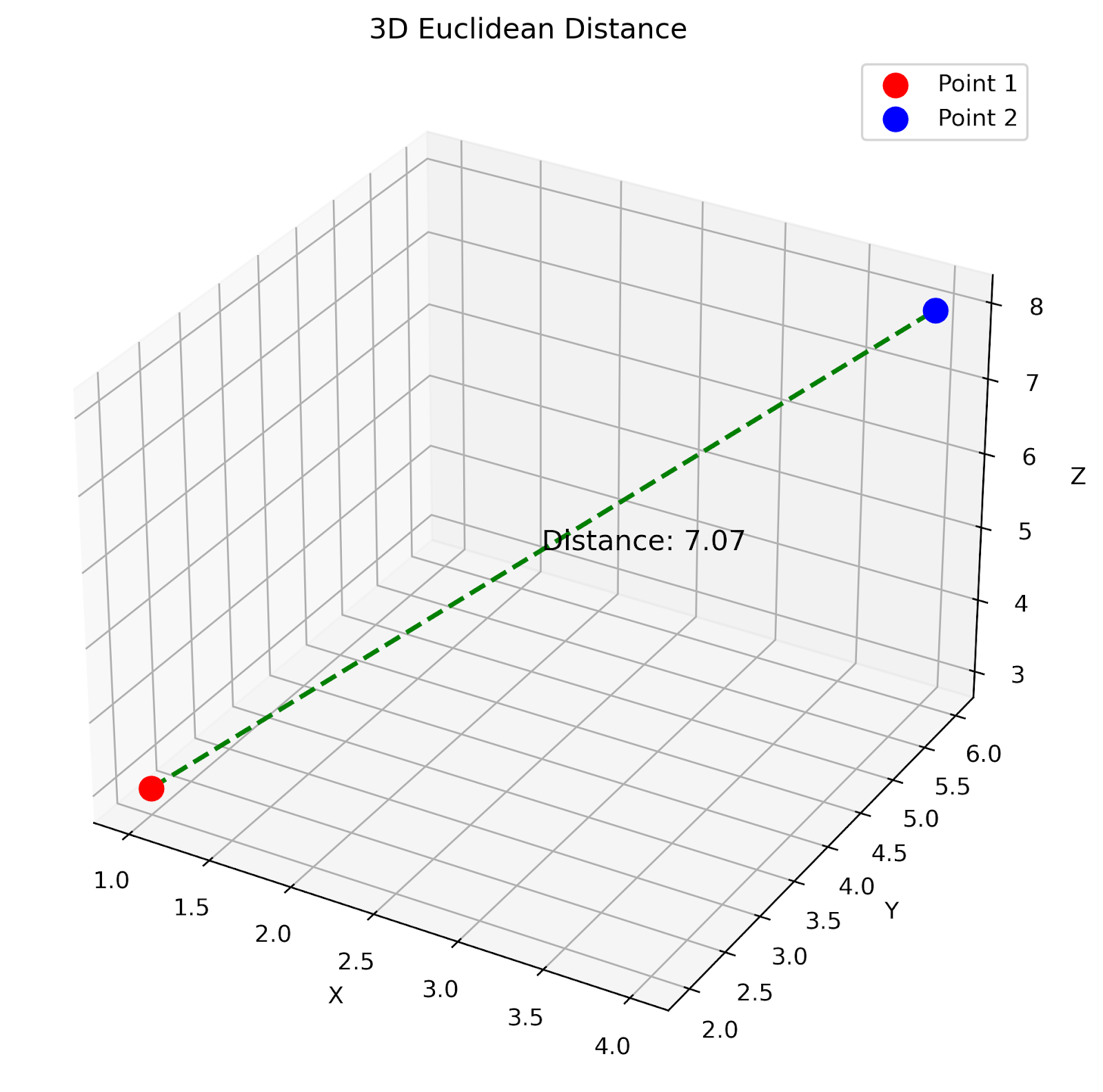
3D Euclidean distance. Image by Author
This 3D plot shows the Euclidean distance between two points in three-dimensional space. The green dashed line represents the direct distance between the points.
N-dimensional Euclidean distance
In a space with n dimensions, the Euclidean distance between points A(a₁, a₂, ..., aₙ) and B(b₁, b₂, ..., bₙ) is:
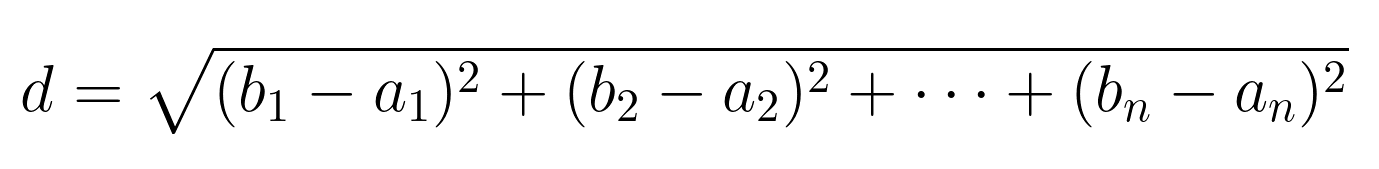
This can be more concisely written using summation notation:
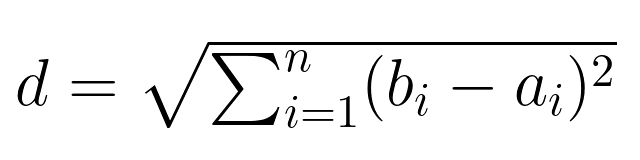
Relationship to Linear Algebra Concepts
Understanding Euclidean distance goes beyond just knowing how to measure the shortest path between two points. It's also about seeing these distances through the lens of linear algebra, a field that helps us describe and solve problems about space and dimensions using vectors and their properties. For more insights into this subject, explore the Linear Algebra for Data Science in R course, which covers these concepts comprehensively.
Euclidean distance as a vector norm
Euclidean distance measures how far apart two points are in space. Imagine you have two points, one at the start of a hiking trail and another at the top of a hill. The straight-line path you'd walk from the start to the top can be thought of as the Euclidean distance. In linear algebra, this is like finding the length of an arrow (or vector) that points straight from the beginning of the trail (point A) to the top of the hill (point B). This length is called the vector's "norm," and it's just a fancy term for the length of this straight-line path.
Dot product and the cosine of the angle
When dealing with directions, the dot product helps us understand the angle between any two arrows. For instance, if you're at the intersection of two roads, the dot product would tell you how much one road points toward the other. This is calculated using the lengths of each road (like the norms we talked about) and the angle between them. The closer this value is to 0, the more the roads approach being perpendicular to each other. When you relate this to distance, the formula for the dot product helps break down the Euclidean distance into components that are easier to manage, showing how changes in direction affect the overall distance.
Euclidean distance and vector subtraction
To find the Euclidean distance between two points using vectors, you essentially subtract one point from another to create a new vector. This new vector points directly from one point to the other and its length is the Euclidean distance you're interested in. It's like plotting a direct route on a map from your house to the nearest grocery store by subtracting their coordinates; this gives you a straight line (or vector) that shows the shortest path you can take.
Calculating Euclidean Distance in Python and R
Let's explore implementations of Euclidean distance calculations using both Python and R. We'll examine how to create custom functions and utilize built-in libraries to enhance efficiency.
Python example
In Python, we can leverage the power of NumPy for efficient array operations and SciPy for specialized distance calculations. Here's how we can implement Euclidean distance:
import numpy as np
from scipy.spatial.distance import euclidean
def euclidean_distance(point1, point2):
return np.sqrt(np.sum((np.array(point1) - np.array(point2))**2))
# 2D example
point_a = (1, 2)
point_b = (4, 6)
distance_2d = euclidean_distance(point_a, point_b)
print(f"2D Euclidean distance: {distance_2d:.2f}")
# 3D example
point_c = (1, 2, 3)
point_d = (4, 6, 8)
distance_3d = euclidean_distance(point_c, point_d)
print(f"3D Euclidean distance: {distance_3d:.2f}")
# Using SciPy for efficiency
distance_scipy = euclidean(point_c, point_d)
print(f"3D Euclidean distance (SciPy): {distance_scipy:.2f}")When we run this code, we expect to see output similar to:
2D Euclidean distance: 5.00
3D Euclidean distance: 7.07
3D Euclidean distance (SciPy): 7.07The SciPy function is generally faster and more optimized, especially for high-dimensional data, but our custom function helps illustrate the underlying calculation.




