
Course
Understanding Data Science
2 hr
857.3K
Distance metrics provide essential ways to measure differences between objects. While metrics like Euclidean or Manhattan distance measure spatial differences, Hamming distance takes a different approach: It counts the positions where two sequences differ. This makes it particularly valuable for error detection, data validation, and information theory.
Originally developed by Richard Hamming in 1950 while working on code verification systems at Bell Labs, Hamming distance has evolved beyond its telecommunications roots. Today, it serves as a key metric in diverse fields including:
In this guide, we'll explore how Hamming distance works, examine its practical applications, and implement it in Python and R. The concepts and implementations we'll cover will enhance your ability to solve problems in data validation, bioinformatics, and machine learning.
Hamming distance measures the number of positions at which two strings of equal length have different symbols. Think of it as counting the minimum number of substitutions needed to transform one string into another.
For example, comparing two binary strings:
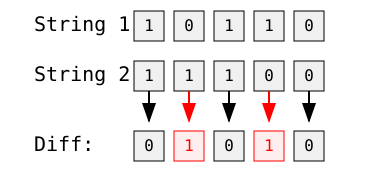
Image by Author
The Hamming distance here is 2 because the strings differ at two positions - the second and fourth bits.
Mathematically, for two strings x and y of equal length n, the Hamming distance D(x,y) is expressed as:
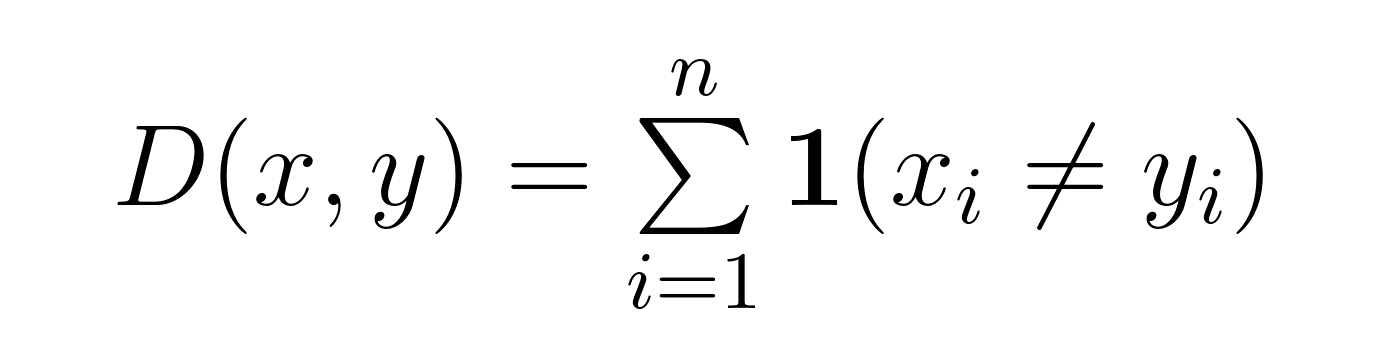
This formula counts positions where xᵢ ≠ yᵢ. For binary strings, this simplifies to counting where bits differ. For other types of sequences (like DNA or text), it counts positions with different symbols.
Two key properties to be aware of:
These properties make Hamming distance ideal for scenarios where:
Let's explore how to calculate Hamming distance through examples, starting with simple binary strings and moving to more complex applications.
The most straightforward application of Hamming distance is comparing binary strings. Let's analyze two 8-bit strings:
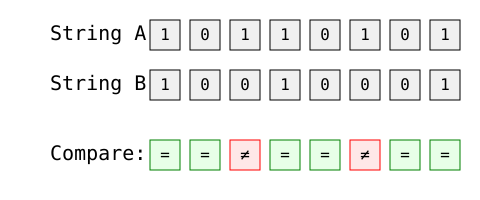
Image by Author
Step-by-step calculation:
The Hamming distance is 2, as there are two positions where the strings differ (positions 3 and 6).
Hamming distance is frequently used in bioinformatics to compare genetic sequences. Consider two DNA fragments:
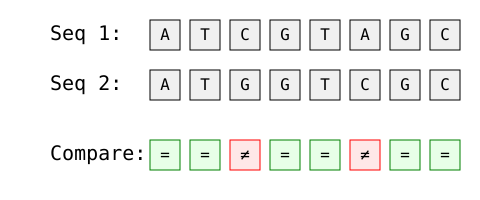
Image by Author
Step-by-step analysis:
This comparison helps biologists quantify genetic mutations and analyze DNA similarity.
Hamming distance also works with regular text strings of equal length:
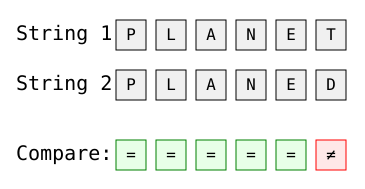
Image by Author
The Hamming distance here is 1, with the only difference at the last position ('T' vs 'D').
This type of comparison is useful in:
Each example demonstrates how Hamming distance provides a simple yet effective way to quantify differences between sequences, regardless of the type of data being compared. The key insight is that it looks at position-wise differences while ignoring the specific nature of the changes.
Hamming distance laid the foundation for error-detecting and error-correcting codes in digital communications. By strategically adding parity bits to create minimum distances between valid codewords, systems can detect when received data doesn't match valid patterns and even correct errors by mapping to the nearest valid codeword. This principle powers modern technologies like ECC (Error-Correcting Code) memory in computers, QR code error correction, and deep space communication systems where data integrity is critical.
Information theory uses Hamming distance to design reliable communication systems. When creating error-handling codes, engineers ensure valid messages (codewords) differ by specific minimum numbers of bits. For example, if valid messages always differ by at least two bits, the system can detect when a single bit gets corrupted during transmission. If valid messages differ by at least three bits, the system can even correct single-bit errors by identifying the closest valid message. These principles help create robust communication systems used in everything from satellite communications to data storage.
Genetic researchers use Hamming distance to analyze DNA sequences and quantify mutations. By comparing genetic sequences position by position, scientists can identify point mutations, track evolutionary changes, and study genetic diversity. This application proves particularly valuable in studying disease mutations, where understanding the exact positions of genetic changes helps researchers track how diseases evolve and spread through populations.
In machine learning, Hamming distance serves as a similarity metric for binary or categorical data. It helps compare feature vectors in pattern recognition tasks, measure similarity in recommendation systems, and analyze categorical data in classification problems. The metric's simplicity and efficient computation make it particularly valuable when working with high-dimensional binary data or when quick similarity calculations are needed for large datasets.
Hamming distance forms a mathematical metric space, which means it follows four fundamental rules. First, the distance is always non-negative - you can't have a negative number of positions where strings differ. Second, the distance between two sequences is zero if and only if they're identical. Third, the distance exhibits symmetry - comparing sequence A to B gives the same result as comparing B to A. Finally, it satisfies the triangle inequality: the distance between sequences A and C cannot be greater than the sum of distances from A to B and B to C.
When working with binary strings, Hamming distance takes on special characteristics that make it particularly useful for error detection. For any two binary strings of length n, their Hamming distance can't exceed n, occurring only when the strings are complements of each other. The probability of a specific Hamming distance “d” between two random binary strings follows a binomial distribution, with the most likely distance being n/2. This property helps in designing error-detecting codes that can recognize when bits have been flipped during transmission.
Python offers both built-in library functions and custom implementations for calculating Hamming distance. The SciPy library provides the most efficient solution through its spatial distance functions:
from scipy.spatial.distance import hamming
# For working with strings
string1 = "1010101"
string2 = "1000101"
# Convert to list of integers for hamming function
arr1 = [int(bit) for bit in string1]
arr2 = [int(bit) for bit in string2]
# Calculate Hamming distance
distance = hamming(arr1, arr2) * len(arr1) # Multiply by length because SciPy returns fraction
print(f"Hamming distance: {int(distance)}") # Output: Hamming distance: 1
# For DNA sequences
sequence1 = "ATCGTACT"
sequence2 = "ATCGCACT"
distance = hamming(list(sequence1), list(sequence2)) * len(sequence1)
print(f"Hamming distance: {int(distance)}") # Output: Hamming distance: 1For those who prefer a custom implementation:
def hamming_distance(str1: str, str2: str) -> int:
"""Calculate Hamming distance between two strings."""
if len(str1) != len(str2):
raise ValueError("Strings must be of equal length")
return sum(c1 != c2 for c1, c2 in zip(str1, str2))
# Example usage
print(hamming_distance("1010101", "1000101")) # Output: 1R provides a simple way to calculate Hamming distance using base functions:
hamming_distance <- function(str1, str2) {
if (nchar(str1) != nchar(str2)) {
stop("Strings must be equal length")
}
sum(strsplit(str1, "")[[1]] != strsplit(str2, "")[[1]])
}
# Example usage
hamming_distance("1010101", "1000101")
# [1] 1
# For DNA sequences
hamming_distance("ATCGTACT", "ATCGCACT")
# [1] 1To build on these coding examples and explore more applications of distance metrics in practice, check out these comprehensive resources:
These courses will help you move beyond basic implementations to understand how distance metrics impact machine learning applications, regardless of your preferred programming language.

Image by Author
The Levenshtein distance represents the minimum number of single-character edits required to change one string into another. Unlike Hamming distance, it can handle strings of different lengths by considering insertions and deletions alongside substitutions. This flexibility makes it particularly valuable for spell checkers, DNA sequence alignment, and fuzzy string matching, though this versatility comes at the cost of higher computational complexity. When comparing strings like "planet" and "plan", Levenshtein distance would count the deletion of 'e' and 't' as two operations, while Hamming distance couldn't make this comparison at all.
Building upon the standard Levenshtein distance, the Damerau-Levenshtein distance adds transposition of adjacent characters as a valid operation. This addition makes it especially effective at catching common typing errors where characters are accidentally swapped. For instance, in comparing "form" with "from", it would count this as a single transposition rather than two separate substitutions. This metric has found widespread use in natural language processing applications, particularly in automated spelling correction systems where character transposition is a common typing error.
The Jaro-Winkler distance takes a unique approach by focusing on character position weights, particularly favoring matches at the beginning of strings. Instead of counting edit operations, it produces a similarity score between 0 and 1, where 1 indicates a perfect match. This metric excels in comparing proper nouns and short strings, making it ideal for record linkage and deduplication tasks. For example, when comparing names like "Martha" and "Marhta", it would assign a higher similarity score because the differing characters appear later in the string.
Different scenarios call for different distance metrics. Consider these key factors when selecting your approach:
This structured comparison shows how each distance metric serves distinct purposes, with Hamming distance particularly valuable in scenarios where its simplicity and speed align with fixed-length comparison requirements.
Hamming distance's elegance lies in its simplicity. By counting positions where sequences differ, it provides a robust way to measure dissimilarity, whether you're detecting errors in transmitted data or analyzing genetic mutations. This metric shines particularly bright in domains where every position matters equally and substitutions are the primary concern.
As you explore distance metrics in your own work, consider Hamming distance when:
To continue building your expertise with distance metrics and other fundamental data science concepts, explore our Data Scientist Certification program, available in both Python and R.
Learn with DataCamp
Course
Course
Course
Tutorial
Vinod Chugani
Tutorial
Vinod Chugani
Tutorial
Vinod Chugani
Tutorial
Vinod Chugani
Tutorial
Vinod Chugani
Tutorial
Vinod Chugani



