Course
Machine Learning for Time Series Data in Python
4 hr
53.3K
With recent advancements in deep learning based computer vision models, object detection applications are easier to develop than ever before. Besides significant performance improvements, these techniques have also been leveraging massive image datasets to reduce the need for large datasets. In addition, with current approaches focussing on full end-to-end pipelines, performance has also improved significantly, enabling real-time use cases.
Similar to the blogpost I wrote on the different image classification architectures, I will go over two object detection architectures. I will discuss SSD and Faster RCNN, which are currently both available in the Tensorflow Detection API.
First I will go over some key concepts in object detection, followed by an illustration of how these are implemented in SSD and Faster RCNN.
People often confuse image classification and object detection scenarios. In general, if you want to classify an image into a certain category, you use image classification. On the other hand, if you aim to identify the location of objects in an image, and, for example, count the number of instances of an object, you can use object detection.
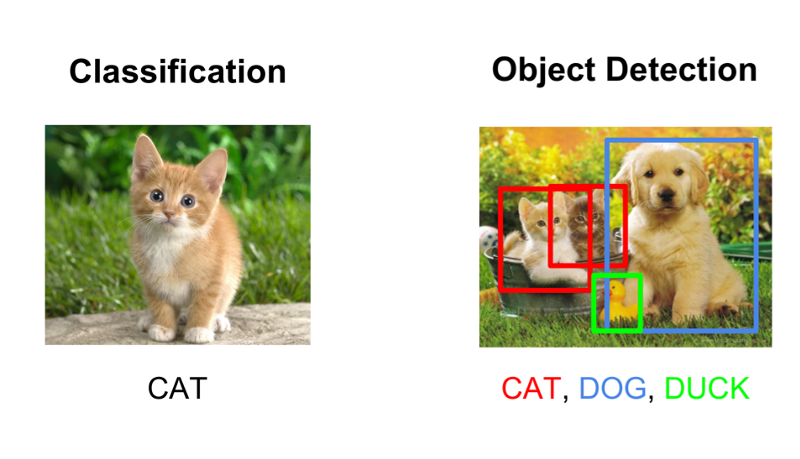
There is, however, some overlap between these two scenarios. If you want to classify an image into a certain category, it could happen that the object or the characteristics that are required to perform categorisation are too small with respect to the full image. In that case, you would achieve better performance with object detection instead of image classification even if you are not interested in the exact location or counts of the object.
Imagine you need to check circuit boards and classify them as either defect or correct. While it is essentially a classification problem, the defects might be too small to be noticeable with an image classification model. Constructing an object detection dataset will cost more time, yet it will result most likely in a better model.

With an image classification model, you generate image features (through traditional or deep learning methods) of the full image. These features are aggregates of the image. With object detection, you do this on a more fine-grained, granular, regional level of the image. In the former you might lose track of the classification signal, whereas in the latter the signal might be preserved in a way that is more suitable for the use case.
In order to train a custom model, you need labelled data. Labelled data in the context of object detection are images with corresponding bounding box coordinates and labels. That is, the bottom left and top right (x,y) coordinates + the class .

A question that is always asked is the following: in order to do object detection on problem X, how many pictures do I need? Instead, it is more important to properly understand in which scenarios the model will be deployed. It is crucial that a large number (for example, > 100 and potentially >1000) representative images are available per class. Representative in this context means that they should corresponds with the range of scenarios in which the model will be used. If you are building a traffic sign detection model that will run in a car, you have to use images taken under different weather, lighting and camera conditions in their appropriate context. Object detection models are not magic and actually rather dumb. If the model does not have enough data to learn general patterns, it won’t perform well in production.

Typically, there are three steps in an object detection framework.
Several different approaches exist to generate region proposals. Originally, the ‘selective search’ algorithm was used to generate object proposals. Lillie Weng provides a thorough explanation on this algorithm in her blog post. In short, selective search is a clustering based approach which attempts to group pixels and generate proposals based on the generated clusters.

Other approaches use more complex visual features extracted from the image to generate regions (for example, based on the features from a deep learning model) or adopt a brute-force approach to region generation. These brute-force approaches are similar to a sliding window that is applied to the image, over several ratios and scales. These regions are generated automatically, without taking into account the image features.

An important trade-off that is made with region proposal generation is the number of regions vs. the computational complexity. The more regions you generate, the more likely you will be able to find the object. On the flip-side, if you exhaustively generate all possible proposals, it won’t be possible to run the object detector in real-time, for example. In some cases, it is possible to use problem specific information to reduce the number of ROI’s. For example, pedestrians typically have a ratio of approximately 1.5, so it is not useful to generate ROI’s with a ratio of 0.25.
The goal of feature extraction is to reduce a variable sized image to a fixed set of visual features. Image classification models are typically constructed using strong visual feature extraction methods. Whether they are based on traditional computer vision approaches, such as for example, filter based approached, histogram methods, etc., or deep learning methods, they all have the exact same objective: extract features from the input image that are representative for the task at hands and use these features to determine the class of the image. In object detection frameworks, people typically use pretrained image classification models to extract visual features, as these tend to generalise fairly well. For example, a model trained on the MS CoCo dataset is able to extract fairly generic features. In order to improve the model however, it is advised to experiment with different approaches. My blog post on transfer learning provides a clear distinction between the different types of transfer learning as well as their advantages and disadvantages.
The general idea of non-maximum suppression is to reduce the number of detections in a frame to the actual number of objects present. If the object in the frame is fairly large and more than 2000 object proposals have been generated, it is quite likely that some of these will have significant overlap with each other and the object. Watch this video on Coursera to learn more about NMS. NMS techniques are typically standard across the different detection frameworks, but it is an important step that might require hyperparameter tweaking based on the scenario.

The most common evaluation metric that is used in object recognition tasks is ‘mAP’, which stands for ‘mean average precision’. It is a number from 0 to 100 and higher values are typically better, but it’s value is different from the accuracy metric in classification.
Each bounding box will have a score associated (likelihood of the box containing an object). Based on the predictions a precision-recall curve (PR curve) is computed for each class by varying the score threshold. The average precision (AP) is the area under the PR curve. First the AP is computed for each class, and then averaged over the different classes. The end result is the mAP.
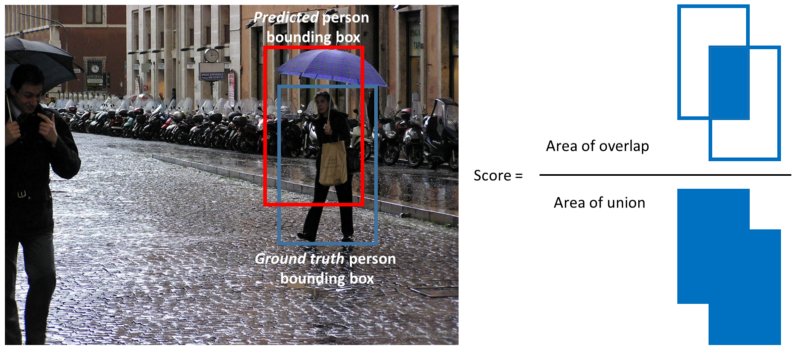
Note that a detection is a true positive if it has an ‘intersection over union’ (IoU or overlap) with the ground-truth box greater than some threshold (usually 0.5). Instead of using mAP we typically use mAP@0.5 or mAP@0.25 to refer to the IoU that was used.
The Tensorflow Detection API brings together a lot of the aforementioned ideas together in a single package, allowing you to quickly iterate over different configurations using the Tensorflow backend. With the API, you are defining the object detection model using configuration files, and the Tensorflow Detection API is responsible for structuring all the necessary elements together.
In order to have a better understanding of what the different supported components are, have a look at the ‘protos folder’ which contains the function definitions. Especially, the train, eval, ssd, faster_rcnn and preprocessing protos are important when fine-tuning a model.
The SSD architecture was published in 2016 by researchers from Google. It presents an object detection model using a single deep neural network combining regional proposals and feature extraction.
A set of default boxes over different aspect ratios and scales is used and applied to the feature maps. As these feature maps are computed by passing an image through an image classification network, the feature extraction for the bounding boxes can be extracted in a single step. Scores are generated for each object category in every of the default bounding boxes. In order to better fit the ground truth boxes adjustment offsets are calculated for each box.
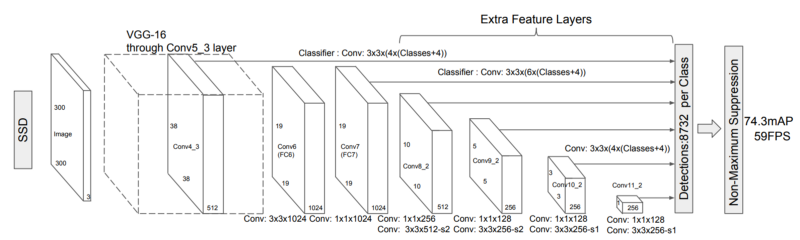
Different feature maps in the convolutional network correspond with different receptive fields and are used to naturally handle objects at different scales . As all the computation is encapsulated in a single network and fairly high computational speeds are achieved (for example, for 300 × 300 input 59 FPS).
For the usage we will investigate the different sample configuration files for SSD. Several parameters are important when leveraging the SSD architecture and we will go over them one by one.
First, different classification networks have different strengths and weaknesses (see this blog post for an overview). The Inceptionv3 network for example is trained to detect objects well at different scales, whereas the ResNet architecture achieves very high accuracy overall. Mobilenet on the other is a network that was trained to minimise the required computational resources. The performance of the feature extraction network on ImageNet, the number of parameters and the original dataset it was trained on are a good proxy for the performance/speed tradeoff. The feature extractor is defined in the ‘feature_extractor’ section.
A second obvious set of parameters are the settings for the default boxes and aspect ratios. Depending on the type of problem, it is worthwhile to analyse the various aspect ratios and scales of the bounding boxes of the labeled data. Setting the aspect ratios and scales will ensure that the network does not do unnecessary calculations. You can tweak these in the ‘ssd_anchor_generator’ section. Note that adding more scales and aspect ratios will lead to better performance, but typically with diminishing returns.
Thirdly, when training the model it is important to set the image size and data augmentation options in the ‘data_augmentation_options’ and ‘image_resizer’ sections. A larger image size will perform better as small object are often hard to detect, but it will have a significant computational cost. Data augmentation is especially important in the context of SSD in order to be able to detect objects at different scales (even at scales which might not be present in the training data).
Finally, tweaking the ‘train_config’, setting the learning rates and batch sizes is important to reduce overfitting, and will highly depend on the size of the dataset you have.
Faster R-CNN was developed by researchers at Microsoft. It is based on R-CNN which used a multi-phased approach to object detection. R-CNN used Selective search to determine region proposals, pushed these through a classification network and then used an SVM to classify the different regions.
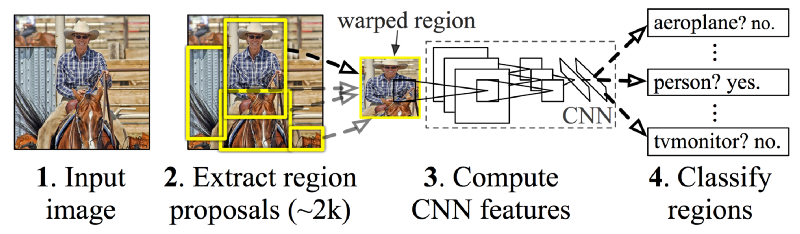
Faster R-CNN, similar to SSD, is an end-to-end approach. Instead of using default bounding boxes, Faster R-CNN has a Region Proposal Network (RPN) to generate a fixed set of regions. The RPN uses the convolutional features from the the image classification network, enabling nearly cost-free region proposals. The RPN is implemented as a fully convolutional network that predicts object bounds and objectness scores at each position.
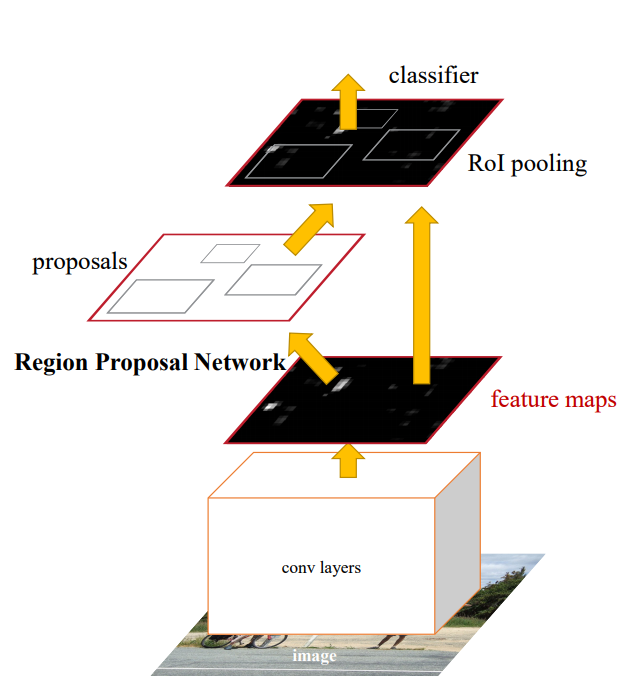
Note that the RPN has a similar setup as the the SSD network (i.e. it does not predict bounding boxes out of thin air). The RPN network works with sliding windows across the feature maps. At each sliding-window location or anchor, a set of proposals are computed with various scales and aspect ratios. Similar to SSD, the outcome of the RPN are ‘adjusted’ bounding boxes, based on the anchors.
The different components are combined in a single setup and are trained either end-to-end or in multiple phases (to improve stability). Another interpretation of the RPN is that it guides the networks ‘attention’ to interesting regions.
Most of the usage details of Faster R-CNN are similar as the ones for SSD. In terms of raw mAP, Faster R-CNN typically outperforms SSD, but it requires significantly more computational power.
An important section for the Fast-RCNN detector, is the ‘first_stage_anchor_generator’ which defines the anchors generated by the RPN. The strides in this section defines the steps of the sliding window. Note that especially when attempting to detect small objects (if the stride is too large, you might miss them).
Although no extensive data augmentation was used by the authors of the Faster-RCNN paper, it is still advised to use it when working with smaller datasets.
There are several more object detection architectures, which I haven’t touched upon. Especially when looking at real-time applications, Yolov2 is often coined as an important architecture (fairly similar to SSD). I will update this blog post whenever it is added to the Tensorflow Detection API.
If you have any questions, I’ll be happy to read them in the comments. Follow me on Medium or Twitter if you want to receive updates on my blog posts!
Learn more about Machine Learning
Course
Course
Course
blog
Zoumana Keita
15 min
Tutorial
Bex Tuychiev
Tutorial
Natassha Selvaraj
Tutorial
Karlijn Willems
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita


