Course
Introduction to R
4 hr
3M
Give Ramnath Vaidyanathan a follow on Twitter. This analysis was originally published on Google Colab.
Kevin Systrom published a really interesting article on estimating $R_t$, the measure known as effective reproduction number. In his article, Kevin describes this number as:
The number of people who become infected per infectious person at time 𝑡
Kevin was kind enough to publish his code as a notebook on github. I wanted to do more with his model, and also apply it to other countries. However, given that I am a lot more proficient in R, I wanted to first replicate his results in R.
Before you read the rest of this post, I would strongly recommend that you read the original article to get a more detailed sense of the modeling approach used, as this post is more focused on the code.
All credit for the modeling approach and code goes to Kevin 👍. This notebook is my humble attempt at translating his model into R. Any mistakes that remain are solely mine.
We will use the same approach outlined by Kevin in his article, which uses the paper by Bettencourt & Ribeiro as its underlying basis.
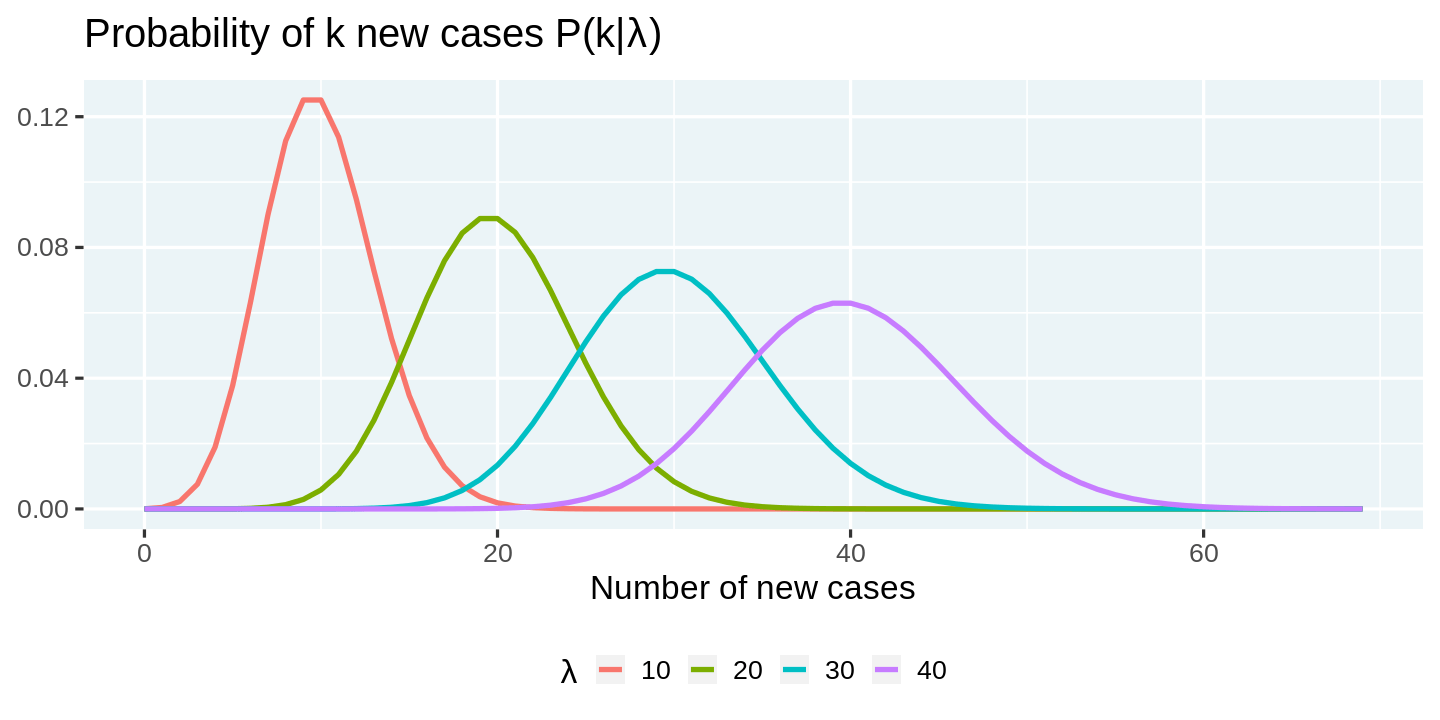
The first step is to model the 'arrival' process of infections. A popular choice for the distribution of arrivals amongst statisticians is the Poisson Distribution. Accordingly, if we let $\lambda$ represent the average rate of infections per day, then the probability that we are likely to see $k$ new cases on a day, is given by
$$P(k|\lambda) = \frac{\lambda^k e^{-\lambda}}{k!}$$
Given this setup, we can construct the probability distribution of new cases for a set of $\lambda$s. Before we can start writing code, we need to load the tidyverse set of packages, and customize some plotting options (plot dimensions, plotting them etc). You can feel free to skip reading this section, as it is not critical to the narrative, but do make sure to execute the code.
# Load packages
library(tidyverse)
# Plot options
## Jupyter notebooks use the repr package to create viewable representations
## of R objects (https://github.com/IRkernel/repr). I am updating the default
## plot dimensions to 12 x 6.
options(repr.plot.width = 12, repr.plot.height = 6)
## We will use ggplot2 for all plots. I am defining a custom theme here
## that mainly updates the backgrounds and legend position. We set this
## custom theme as the default, and also update the default for line size.
theme_custom <- function(base_size, ...){
ggplot2::theme_gray(base_size = base_size, ...) +
ggplot2::theme(
plot.title = element_text(face = 'bold'),
plot.subtitle = element_text(color = '#333333'),
panel.background = element_rect(fill = "#EBF4F7"),
strip.background = element_rect(fill = "#33AACC"),
legend.position = "bottom"
)
}
ggplot2::theme_set(theme_custom(base_size = 20))
ggplot2::update_geom_defaults("line", list(size = 1.5))
# Utility functions
## We will use a utility function to display the head of dataframes.
## Note that we need this hack mainly to add the class 'dataframe' to
## the tables that are printed. This should ideally be handled
## by the `repr` package, and I will be sending a PR.
display_df <- function(x){
d <- as.character(
knitr::kable(x, format = 'html', table.attr = "class='dataframe'")
)
IRdisplay::display_html(d)
}
display_head <- function(x, n = 6){
display_df(head(x, n))
}
display_random <- function(x, n = 6){
display_df(dplyr::sample_n(x, n))
}
── [1mAttaching packages[22m ─────────────────────────────────────── tidyverse 1.3.0 ──
[32m✔[39m [34mggplot2[39m 3.3.0 [32m✔[39m [34mpurrr [39m 0.3.3
[32m✔[39m [34mtibble [39m 3.0.0 [32m✔[39m [34mdplyr [39m 0.8.5
[32m✔[39m [34mtidyr [39m 1.0.2 [32m✔[39m [34mstringr[39m 1.4.0
[32m✔[39m [34mreadr [39m 1.3.1 [32m✔[39m [34mforcats[39m 0.5.0
── [1mConflicts[22m ────────────────────────────────────────── tidyverse_conflicts() ──
[31m✖[39m [34mdplyr[39m::[32mfilter()[39m masks [34mstats[39m::filter()
[31m✖[39m [34mdplyr[39m::[32mlag()[39m masks [34mstats[39m::lag()
We can use the crossing function from purrr to compute probability densities across a combination of $k$s and $\lambda$s. This is an elegant approach, although computationally suboptimal, since we are not really taking advantage of the vectorization capabilities of dpois. You will see a more computationally efficient approach in a later section.
# Number of new cases observed in a day
k = 0:69
# Arrival rate of new infections per day
lambda = c(10, 20, 30, 40)
poisson_densities = crossing(lambda = lambda, k = k) %>%
mutate(p = dpois(k, lambda))
display_head(poisson_densities)
| lambda | k | p |
|---|---|---|
| 10 | 0 | 0.0000454 |
| 10 | 1 | 0.0004540 |
| 10 | 2 | 0.0022700 |
| 10 | 3 | 0.0075667 |
| 10 | 4 | 0.0189166 |
| 10 | 5 | 0.0378333 |
We can visualize these probabilities using ggplot2. Note how we make use of expression to render math symbols in plots. You can read more about this in the documentation for plotmath.
poisson_densities %>%
# We convert lambda to a factor so that each line gets a discrete color
mutate(lambda = factor(lambda)) %>%
ggplot(aes(x = k, y = p, color = lambda)) +
geom_line() +
labs(
title = expression(paste("Probability of k new cases P(k|", lambda, ")")),
x = 'Number of new cases',
y = NULL,
color = expression(lambda)
)
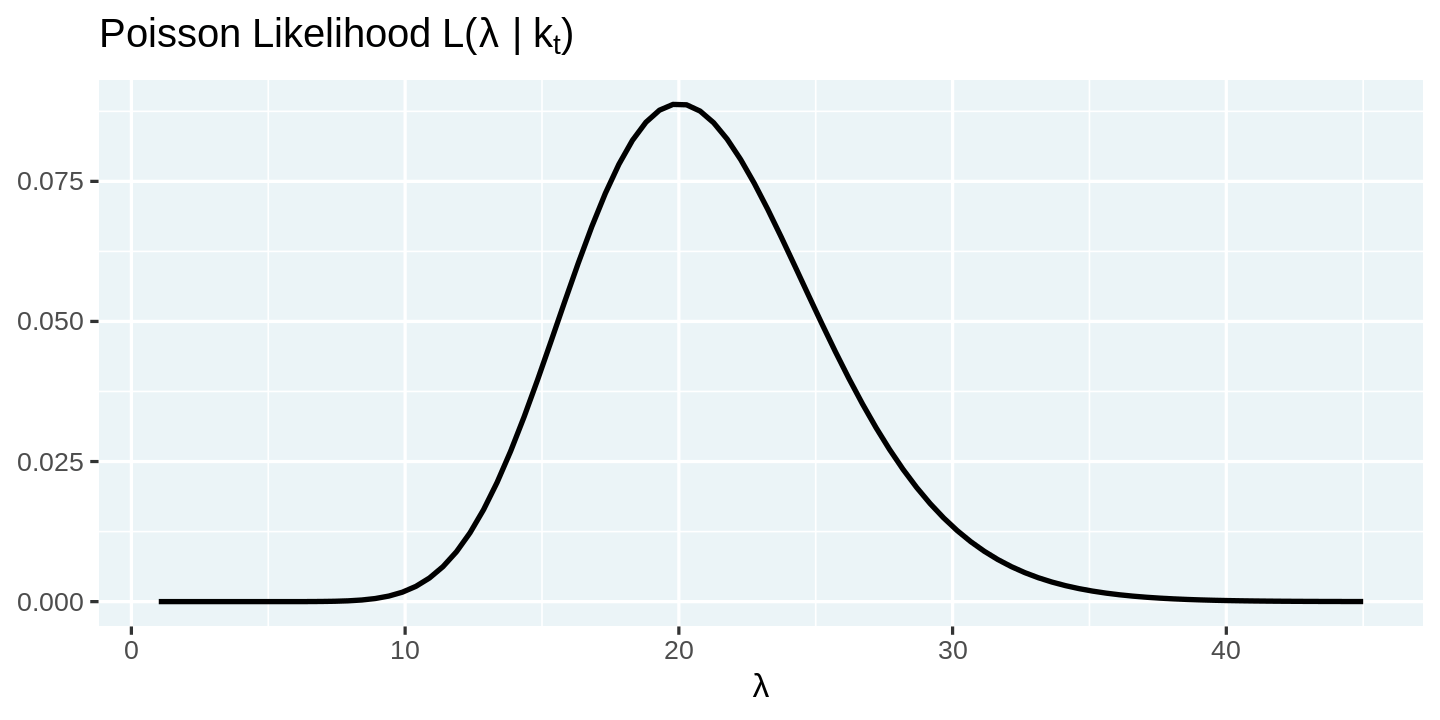
Modeling the arrival process as a Poisson distribution allows us to predict the distribution of new cases in a day as a function of the arrival rate $\lambda$. However, in reality, we only observe the number of arrivals. So the key question now is how do we go from the observed number of arrivals to get a sense of the distribution of $\lambda$. Thankfully, the answer to this question is simple.
$$L(\lambda| k) = \frac{\lambda^k e^{-\lambda}}{k!}$$
The distribution of $\lambda$ over k is called the likelihood function, and it has the same mathematical expression as the probability mass function we used earlier. We can visualize the likelihood function by fixing the number of new cases observed (k), and computing the likelihood function over a range of values of $\lambda$.
# Number of new cases observed in a day
k = 20
# Arrival rates of new infections per day
lambdas = seq(1, 45, length = 90)
# Compute likelihood and visualize them
tibble(lambda = lambdas, p = dpois(k, lambdas)) %>%
ggplot(aes(x = lambda, y = p)) +
geom_line(color = 'black') +
labs(
title = expression(paste("Poisson Likelihood L(", lambda, " | k"[t], ")")),
x = expression(lambda),
y = NULL
)
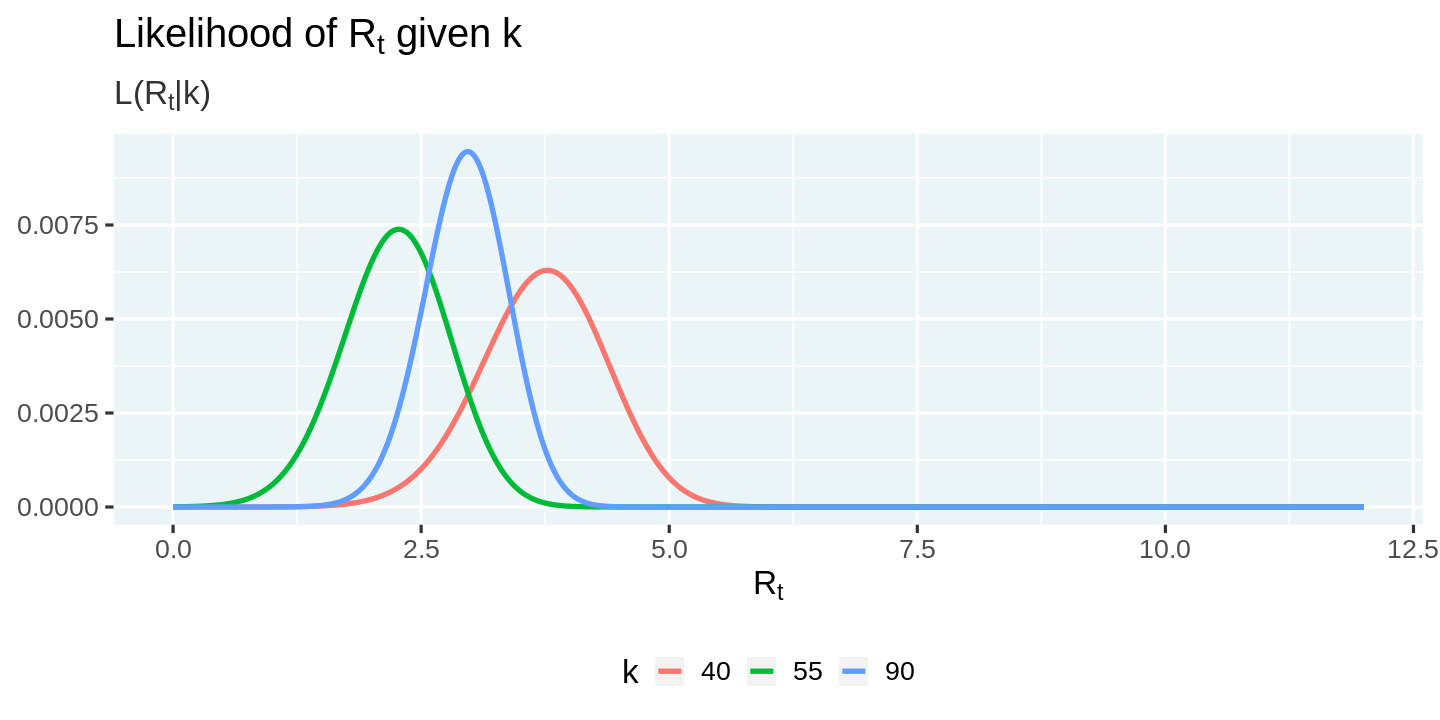
All this is good, but you might be wondering where is the effective infection rate, $R_t$, we talked about in the beginning. How is it related to the arrival rate $\lambda$. According to this paper by Bettencourt & Ribeiro, the relationship is rather simple
$$ \lambda = k_{t-1}e^{\gamma(R_t-1)}$$
Note that $\gamma$ here is the reciprocal of the serial interval (about 4 days for COVID19), and $k_{t-1}$ is the number of new cases observed in the time interval $t-1$.
We can use this expression for $\lambda$ and reformulate the likelihood function in terms of $R_t$.
$$\mathcal{L}\left(R_t|k\right) = \frac{\lambda^k e^{-\lambda}}{k!}$$
Before we move on, let us set up some core parameters.
# r_t_range is a vector of possible values for R_t
R_T_MAX = 12
r_t_range = seq(0, R_T_MAX, length = R_T_MAX*100 + 1)
# Gamma is 1/serial interval
# https://wwwnc.cdc.gov/eid/article/26/6/20-0357_article
GAMMA = 1/4
# New cases by day
k = c(20, 40, 55, 90)
The code below showcases a more computationally efficient way to compute the likelihoods. Rather than generating the lambdas and likelihoods for each combination separately, we use the vectorized nature of functions in R, and the ability to have nested dataframes. This allows us to generate a vector of lambdas and likelihoods for each day, and then use tidyr::unnest to unpack it into a flat table.
Apart from the computational efficiency, I would argue that this code is more readable and translates the mathematical formulae with minimal overhead.
likelihoods <- tibble(day = seq_along(k) - 1, k = k) %>%
# Compute a vector of likelihoods
mutate(
r_t = list(r_t_range),
lambda = map(lag(k, 1), ~ .x * exp(GAMMA * (r_t_range - 1))),
likelihood_r_t = map2(k, lambda, ~ dpois(.x, .y)/sum(dpois(.x, .y)))
) %>%
# Ignore the 0th day
filter(day > 0) %>%
# Unnest the data to flatten it.
select(-lambda) %>%
unnest(c(r_t, likelihood_r_t))
display_random(likelihoods)
| day | k | r_t | likelihood_r_t |
|---|---|---|---|
| 1 | 40 | 7.26 | 0.0000000 |
| 1 | 40 | 2.54 | 0.0011292 |
| 2 | 55 | 3.54 | 0.0003426 |
| 2 | 55 | 5.62 | 0.0000000 |
| 1 | 40 | 7.03 | 0.0000000 |
| 3 | 90 | 10.84 | 0.0000000 |
We can now plot the likelihood conditional on the number of new cases observed.
likelihoods %>%
ggplot(aes(x = r_t, y = likelihood_r_t, color = factor(k))) +
geom_line() +
labs(
title = expression(paste("Likelihood of R"[t], " given k")),
subtitle = expression(paste("L(R"[t], "|k)")),
x = expression("R"[t]),
y = NULL, color = 'k'
)
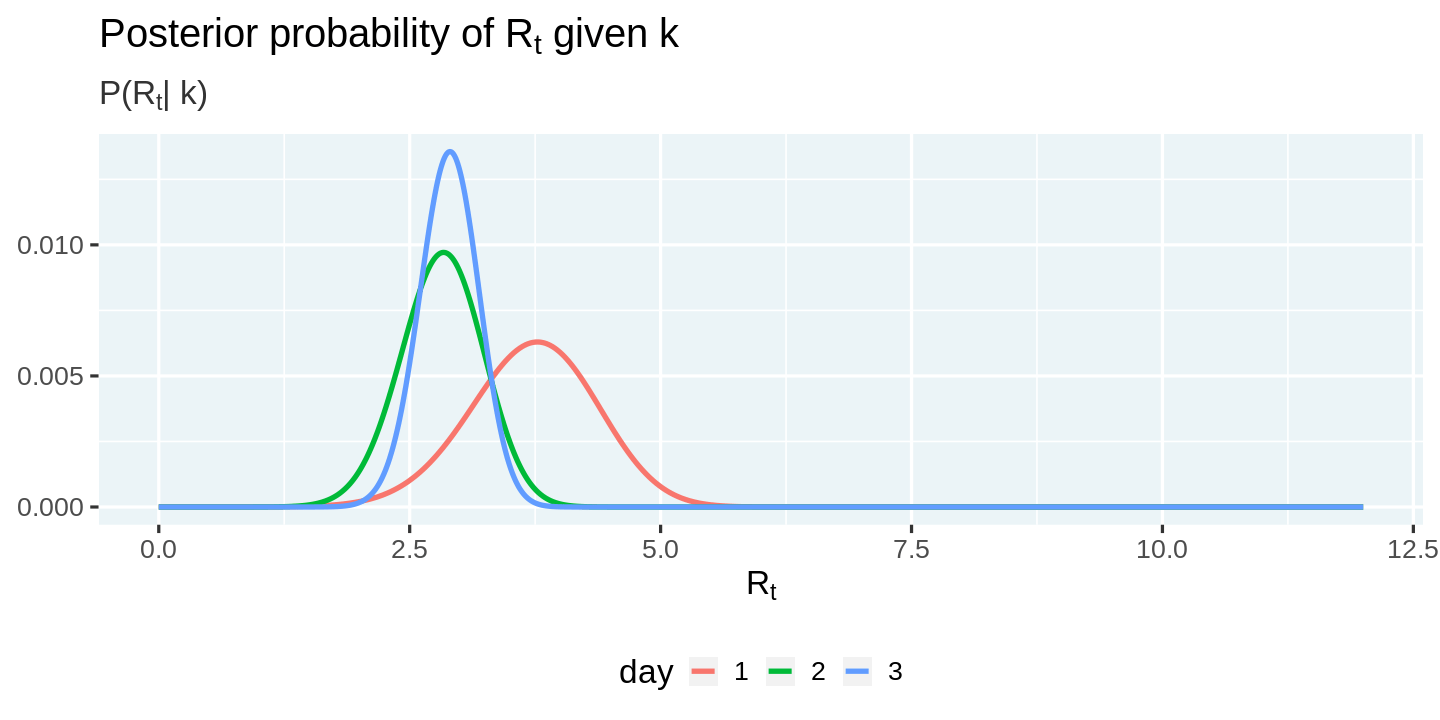
We have made good progress in linking the number of new cases, $k$, and the effective infection rate, $R_t$. However, we still don't have a tangible approach to estimate its values from the time series of observed new cases. Here is where the ubiquitous Bayes' rule comes extremely handy. Bettencourt & Ribeiro express the probability distribution of $R_t$ as
$$ P(R_t|k_t)=\frac{P(R_t)\cdot\mathcal{L}(k_t|R_t)}{P(k_t)} $$
Kevin unpacks this complex equation in much simpler terms.
This says that, having seen 𝑘 new cases, we believe the distribution of 𝑅𝑡 is equal to:
- The prior beliefs of the value of $P(R_t)$ without the data ...
- times the likelihood of seeing $k$ new cases given $R_t$ ...
- divided by the probability of seeing this many cases in general.
If we use the posterior probability of the previous period, $P(R_{t-1} | k_{t-1})$, as the prior, $P(R_t)$, for the current period, then we can rewrite the previous equation as:
$$ P(R_t|k_t) \propto P(R_{t-1}|k_{t-1})\cdot\mathcal{L}(k_t|R_t) $$
Iterating across periods all the way back to $t = 0$, we get
$$ P(R_t|k_t) \propto P(R_0) \cdot {\displaystyle \prod^{T}_{t=0}}\mathcal{L}(k_t|R_t) $$
With a uniform prior $P(R_0)$, this reduces to:
$$ P(R_t|k_t) \propto {\displaystyle \prod^{T}_{t=0}}\mathcal{L}\left(k_t|R_t\right) $$
We can now use this mathematical expression to compute the posterior from the likelihoods. Once again, we use the vectorized function cumprod to generate posteriors for all days at once, and then normalize it.
posteriors <- likelihoods %>%
group_by(r_t) %>%
arrange(day) %>%
mutate(posterior = cumprod(likelihood_r_t)) %>%
group_by(k) %>%
mutate(posterior = posterior / sum(posterior)) %>%
ungroup()
display_random(posteriors)
| day | k | r_t | likelihood_r_t | posterior |
|---|---|---|---|---|
| 3 | 90 | 5.85 | 0.0000000 | 0.0000000 |
| 3 | 90 | 2.35 | 0.0033847 | 0.0025235 |
| 3 | 90 | 7.68 | 0.0000000 | 0.0000000 |
| 2 | 55 | 0.01 | 0.0000047 | 0.0000000 |
| 1 | 40 | 0.79 | 0.0000009 | 0.0000009 |
| 3 | 90 | 10.81 | 0.0000000 | 0.0000000 |
We can now visualize the posterior distribution.
posteriors %>%
ggplot(aes(x = r_t, y = posterior, color = factor(day))) +
geom_line() +
labs(
title = expression(paste("Posterior probability of R"[t], " given k")),
subtitle = expression(paste("P(R"[t], "| k)")),
x = expression("R"[t]), y = NULL, color = 'day'
)
These posteriors now allow us to answer the all-important question:
What is the most likely value of $R_t$ each day?
While estimating any quantity, it is very important to provide a sense of the error surrounding the estimate. A popular way of doing this is to use highest density intervals.
Another way of summarizing a distribution is the highest density interval, which summarizes the distribution by specifying an interval that spans most of the distribution, say 95% of it, such that every point inside the interval has higher credibility than any point outside the interval.
In his article, Kevin implemented a brute force algorithm to compute HDI. R users are more fortunate that there is already a package, HDInterval, out there with an implementation 🎉.
We will now estimate the most likely value of $R_t$, and the highest density interval surrounding it. Since the HDInterval::hdi function only works with a vector of random values from a distribution, and we only estimated the posterior probabilities, we will need to simulate random values of $R_t$ using the posterior probabilities in order to compute the highest-density intervals.
# Install and load HDInterval package
install.packages("HDInterval")
library(HDInterval)
# Compute the most likely value of r_t and the highest-density interval
estimates <- posteriors %>%
group_by(day) %>%
summarize(
r_t_simulated = list(sample(r_t_range, 10000, replace = TRUE, prob = posterior)),
r_t_most_likely = r_t_range[which.max(posterior)]
) %>%
mutate(
r_t_lo = map_dbl(r_t_simulated, ~ hdi(.x)[1]),
r_t_hi = map_dbl(r_t_simulated, ~ hdi(.x)[2])
) %>%
select(-r_t_simulated)
display_head(estimates)
Installing package into ‘/usr/local/lib/R/site-library’
(as ‘lib’ is unspecified)
| day | r_t_most_likely | r_t_lo | r_t_hi |
|---|---|---|---|
| 1 | 3.77 | 2.45 | 4.96 |
| 2 | 2.84 | 2.04 | 3.65 |
| 3 | 2.90 | 2.28 | 3.44 |
We can visualize these estimates and the uncertainty surrounding them using a line plot with ribbons.
estimates %>%
ggplot(aes(x = day, y = r_t_most_likely)) +
geom_point(color = "#ffc844", size = 5) +
geom_line(color = 'black') +
geom_ribbon(aes(ymin = r_t_lo, ymax = r_t_hi), fill = "#ffc844", alpha = 0.3) +
labs(
title = expression(paste('R'[t], ' by day')),
subtitle = "The band represents the highest density interval",
x = 'Day', y = NULL
)
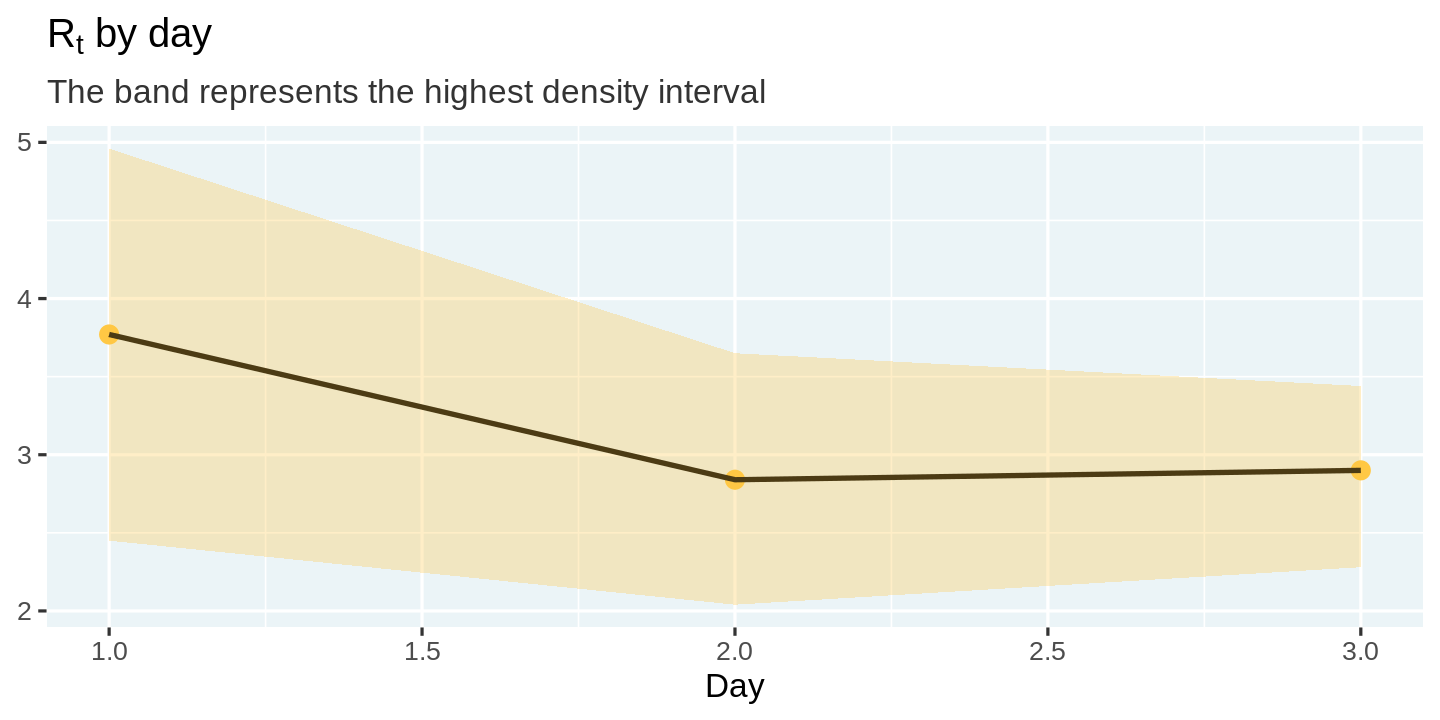
While Bettencourt and Ribeiro's approach works fine, Kevin points out a practical problem with it (that is also noted in the paper), that it is possible for the posterior to get stuck and asympotically approach 1, due to its inability to forget the times with a high $R_t$.
To counter this problem, Kevin suggests the following approach.
So, I propose to only incorporate the last $m$ days of the likelihood function. By doing this, the algorithm's prior is built based on the recent past which is a much more useful prior than the entire history of the epidemic. So this simple, but important change leads to the following: $$ P(R_t|k_t) \propto {\displaystyle \prod^{T}_{t=T-m}}\mathcal{L}\left(k_t|R_t\right) $$
We will use this modification to estimate the values of $R_t$ across different states in the US.
It is now time to take all this machinery we built and apply it on COVID data from US states to estimate the effective infection rate, $R_t$. Let us begin by fetching the data. We will use the COVID dataset for the US constructed by the New York Times.
url = 'https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-states.csv'
covid_cases <- readr::read_csv(url)
display_head(covid_cases)
Parsed with column specification:
cols(
date = [34mcol_date(format = "")[39m,
state = [31mcol_character()[39m,
fips = [31mcol_character()[39m,
cases = [32mcol_double()[39m,
deaths = [32mcol_double()[39m
)
| date | state | fips | cases | deaths |
|---|---|---|---|---|
| 2020-01-21 | Washington | 53 | 1 | 0 |
| 2020-01-22 | Washington | 53 | 1 | 0 |
| 2020-01-23 | Washington | 53 | 1 | 0 |
| 2020-01-24 | Illinois | 17 | 1 | 0 |
| 2020-01-24 | Washington | 53 | 1 | 0 |
| 2020-01-25 | California | 06 | 1 | 0 |
The first step is to prepare the data by computing the number of new cases every day, and smoothing it over a rolling window. The smoothing is essential to account for lags in reporting. The lag has been found to be especially pronounced over weekends.
Following Kevin's approach, I utilize a gaussian smoother with a 7-day rolling window.
Note that we will implement all data processing steps as standalone functions. While this adds some overhead, it will allow us to compose these steps cleanly, and also apply them across one or more states, which will come very handy.
We will apply these steps to one selected state, so it is easier to look at the results and make sense out of them. I have selected New York, but feel free to switch it to a state of your choice!
# Install the smoother package
install.packages("smoother")
#' Compute new cases and smooth them
smooth_new_cases <- function(cases){
cases %>%
arrange(date) %>%
mutate(new_cases = c(cases[1], diff(cases))) %>%
mutate(new_cases_smooth = round(
smoother::smth(new_cases, window = 7, tails = TRUE)
)) %>%
select(state, date, new_cases, new_cases_smooth)
}
state_selected <- "New York"
covid_cases %>%
filter(state == state_selected) %>%
smooth_new_cases() %>%
display_head()
Installing package into ‘/usr/local/lib/R/site-library’
(as ‘lib’ is unspecified)
| state | date | new_cases | new_cases_smooth |
|---|---|---|---|
| New York | 2020-03-01 | 1 | 1 |
| New York | 2020-03-02 | 0 | 2 |
| New York | 2020-03-03 | 1 | 4 |
| New York | 2020-03-04 | 9 | 9 |
| New York | 2020-03-05 | 11 | 15 |
| New York | 2020-03-06 | 22 | 23 |
Let us plot the raw values as well as the smoothed values for new_cases so we can visualize what the smoothing process is doing.
🎩 It is always good practice to visualize the results after you make some data transformations. This allows you to build intuition and also sanity check that your transformation is doing what you intended it to do!
plot_new_cases <- function(cases){
cases %>%
ggplot(aes(x = date, y = new_cases)) +
geom_line(linetype = 'dotted', color = 'gray40') +
geom_line(aes(y = new_cases_smooth), color = "#14243e") +
labs(
title = "New cases per day",
subtitle = unique(cases$state),
x = NULL, y = NULL
)
}
covid_cases %>%
filter(state == state_selected) %>%
smooth_new_cases() %>%
plot_new_cases()
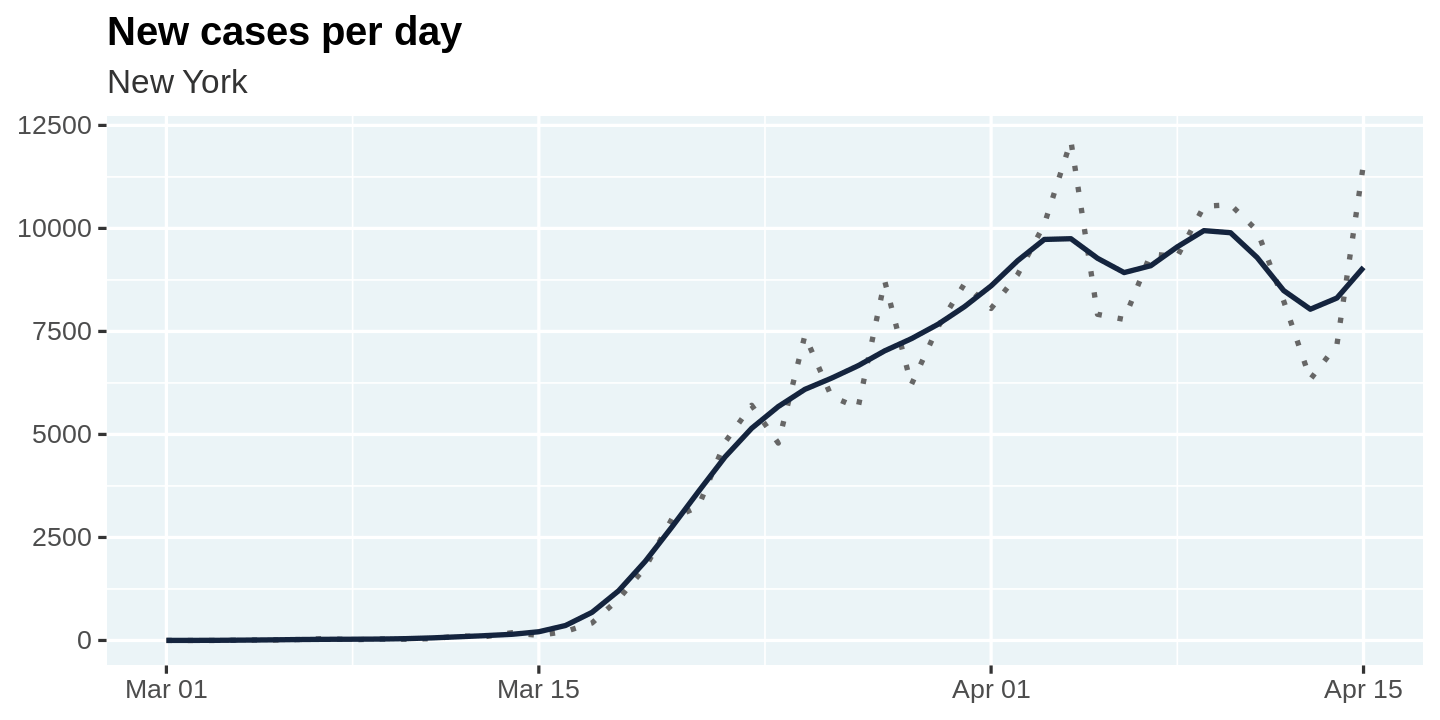
The second step is to compute the likelihoods. We will use the same approach we followed previously, but with one notable difference. We will compute log-likelihoods instead of the likelihoods. This will make it easier to smooth them over a rolling window to apply the modification suggested by Kevin, of only using the latest $m$ intervals to compute $R_t$.
As before, we will compute the likelihoods for each day as a nested list and then flatten the results to a table using tidyr::unnest.
🎩 List columns are extremely handy when working with data. The design pattern used here is very useful in many situations.
compute_likelihood <- function(cases){
likelihood <- cases %>%
filter(new_cases_smooth > 0) %>%
mutate(
r_t = list(r_t_range),
lambda = map(lag(new_cases_smooth, 1), ~ .x * exp(GAMMA * (r_t_range - 1))),
likelihood_r_t = map2(new_cases_smooth, lambda, dpois, log = TRUE)
) %>%
slice(-1) %>%
select(-lambda) %>%
unnest(c(likelihood_r_t, r_t))
}
covid_cases %>%
filter(state == state_selected) %>%
smooth_new_cases() %>%
compute_likelihood() %>%
display_random()
| state | date | new_cases | new_cases_smooth | r_t | likelihood_r_t |
|---|---|---|---|---|---|
| New York | 2020-03-24 | 4790 | 5677 | 5.36 | -4010.9111 |
| New York | 2020-03-21 | 3254 | 3614 | 7.33 | -5054.4656 |
| New York | 2020-04-07 | 9378 | 9094 | 5.90 | -10331.2552 |
| New York | 2020-03-13 | 95 | 118 | 7.01 | -144.3349 |
| New York | 2020-04-10 | 10575 | 9895 | 11.69 | -107594.6949 |
| New York | 2020-04-10 | 10575 | 9895 | 8.46 | -35816.2131 |
The third step is to compute the posterior probabilities. Recall that
$$ P(R_t|k_t) \propto {\displaystyle \prod^{T}_{t=T-m}}\mathcal{L}\left(k_t|R_t\right) $$
We can rewrite this in terms of the log-likelihoods
$$ P(R_t|k_t) \propto {\displaystyle \exp \big( \sum^{T}_{t=T-m}}\log(\mathcal{L}\left(k_t|R_t\right)) \big) $$
We can use the rollapplyr function from the zoo package to compute a rolling 7-day sum of the log likelihoods, and then exponentiate it to compute the posterior. Finally, we normalize the posteriors to 1.0.
compute_posterior <- function(likelihood){
likelihood %>%
arrange(date) %>%
group_by(r_t) %>%
mutate(posterior = exp(
zoo::rollapplyr(likelihood_r_t, 7, sum, partial = TRUE)
)) %>%
group_by(date) %>%
mutate(posterior = posterior / sum(posterior, na.rm = TRUE)) %>%
# HACK: NaNs in the posterior create issues later on. So we remove them.
mutate(posterior = ifelse(is.nan(posterior), 0, posterior)) %>%
ungroup() %>%
select(-likelihood_r_t)
}
covid_cases %>%
filter(state == state_selected) %>%
smooth_new_cases() %>%
compute_likelihood() %>%
compute_posterior() %>%
display_random()
| state | date | new_cases | new_cases_smooth | r_t | posterior |
|---|---|---|---|---|---|
| New York | 2020-04-14 | 7177 | 8311 | 0.51 | 0.0000000 |
| New York | 2020-03-19 | 1770 | 1921 | 11.62 | 0.0000000 |
| New York | 2020-03-25 | 7401 | 6094 | 5.46 | 0.0000000 |
| New York | 2020-03-22 | 4812 | 4455 | 0.53 | 0.0000000 |
| New York | 2020-03-20 | 2950 | 2753 | 8.64 | 0.0000000 |
| New York | 2020-03-05 | 11 | 15 | 2.44 | 0.0020211 |
Let us visualize the posterior probabilities we computed. Note how we set alpha = 0.2 to reduce the amount of overplotting. This allows us to visualize the shifting posteriors.
plot_posteriors <- function(posteriors){
posteriors %>%
ggplot(aes(x = r_t, y = posterior, group = date)) +
geom_line(alpha = 0.2) +
labs(
title = expression(paste("Daily Posterior of R"[t], " by day")),
subtitle = unique(posteriors$state),
x = '',
y = ''
) +
coord_cartesian(xlim = c(0.4, 4)) +
theme(legend.position = 'none')
}
covid_cases %>%
filter(state == state_selected) %>%
smooth_new_cases() %>%
compute_likelihood() %>%
compute_posterior() %>%
plot_posteriors()
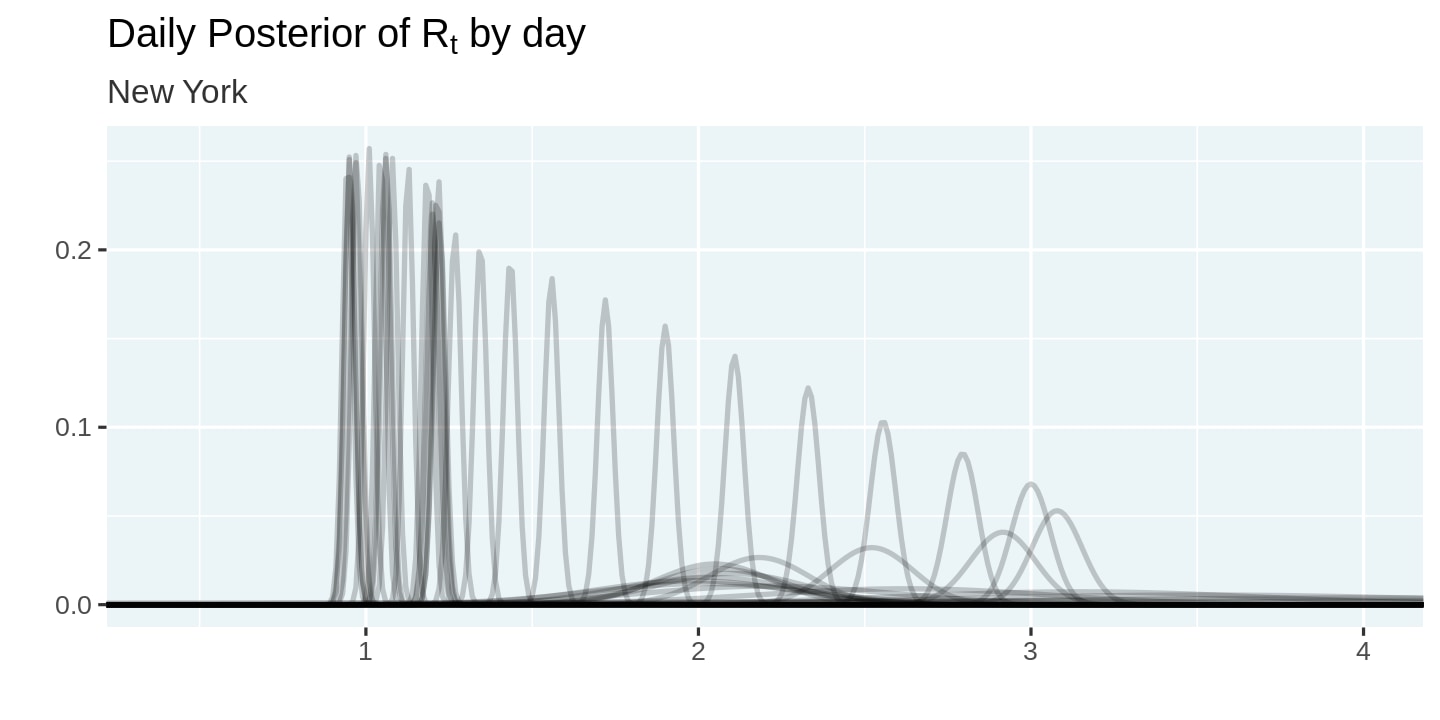
The final step is to estimate the values of $R_t$ and the highest density intervals surrounding them. Recall that we need to simulate random values for $r_t$ using the posterior probabilities in order to apply the HDIInterval::hdi function to compute the highest density intervals.
# Estimate R_t and a 95% highest-density interval around it
estimate_rt <- function(posteriors){
posteriors %>%
group_by(state, date) %>%
summarize(
r_t_simulated = list(sample(r_t_range, 10000, replace = TRUE, prob = posterior)),
r_t_most_likely = r_t_range[which.max(posterior)]
) %>%
mutate(
r_t_lo = map_dbl(r_t_simulated, ~ hdi(.x)[1]),
r_t_hi = map_dbl(r_t_simulated, ~ hdi(.x)[2])
) %>%
select(-r_t_simulated)
}
covid_cases %>%
filter(state == state_selected) %>%
smooth_new_cases() %>%
compute_likelihood() %>%
compute_posterior() %>%
estimate_rt() %>%
display_random()
| state | date | r_t_most_likely | r_t_lo | r_t_hi |
|---|---|---|---|---|
| New York | 2020-03-14 | 2.05 | 1.68 | 2.36 |
| New York | 2020-03-22 | 2.33 | 2.27 | 2.39 |
| New York | 2020-03-07 | 2.62 | 1.73 | 3.46 |
| New York | 2020-03-09 | 2.01 | 1.32 | 2.63 |
| New York | 2020-04-04 | 1.18 | 1.15 | 1.21 |
| New York | 2020-04-06 | 1.08 | 1.05 | 1.11 |
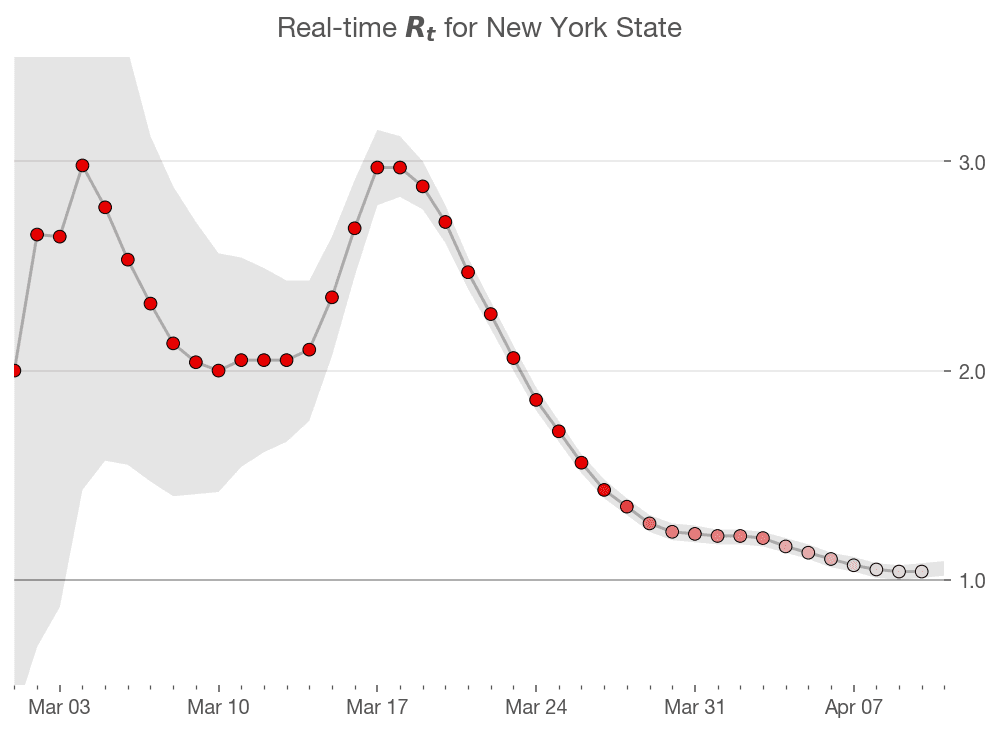
Finally, we come to the moment of truth! Let us visualize the estimated values of $R_t$
plot_estimates <- function(estimates){
estimates %>%
ggplot(aes(x = date, y = r_t_most_likely)) +
geom_point(color = "darkorange", alpha = 0.8, size = 4) +
geom_line(color = "#14243e") +
geom_hline(yintercept = 1, linetype = 'dashed') +
geom_ribbon(
aes(ymin = r_t_lo, ymax = r_t_hi),
fill = 'darkred',
alpha = 0.2
) +
labs(
title = expression('Real time R'[t]), x = '', y = '',
subtitle = unique(estimates$state)
) +
coord_cartesian(ylim = c(0, 4))
}
covid_cases %>%
filter(state == state_selected) %>%
smooth_new_cases() %>%
compute_likelihood() %>%
compute_posterior() %>%
estimate_rt() %>%
plot_estimates()
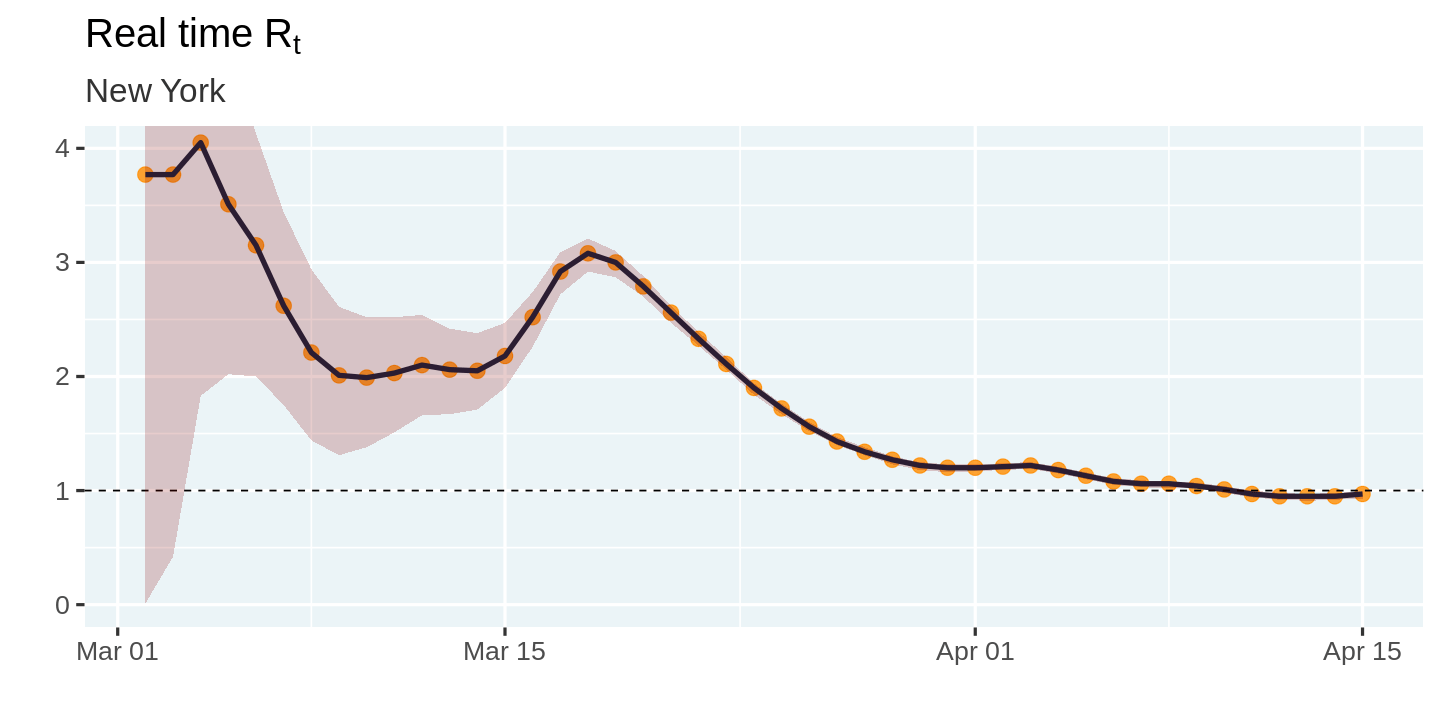
So how does this compare with the estimates from Kevin's article. It seems like the initial estimates in my model are off from Kevin's estimates. However, that could be a function of differences in the smoothing algorithm, or the large uncertainty surrounding the initial estimates. The overall shape of the curve and the peaks seem to match up pretty closely. Mission accomplished! 🎉
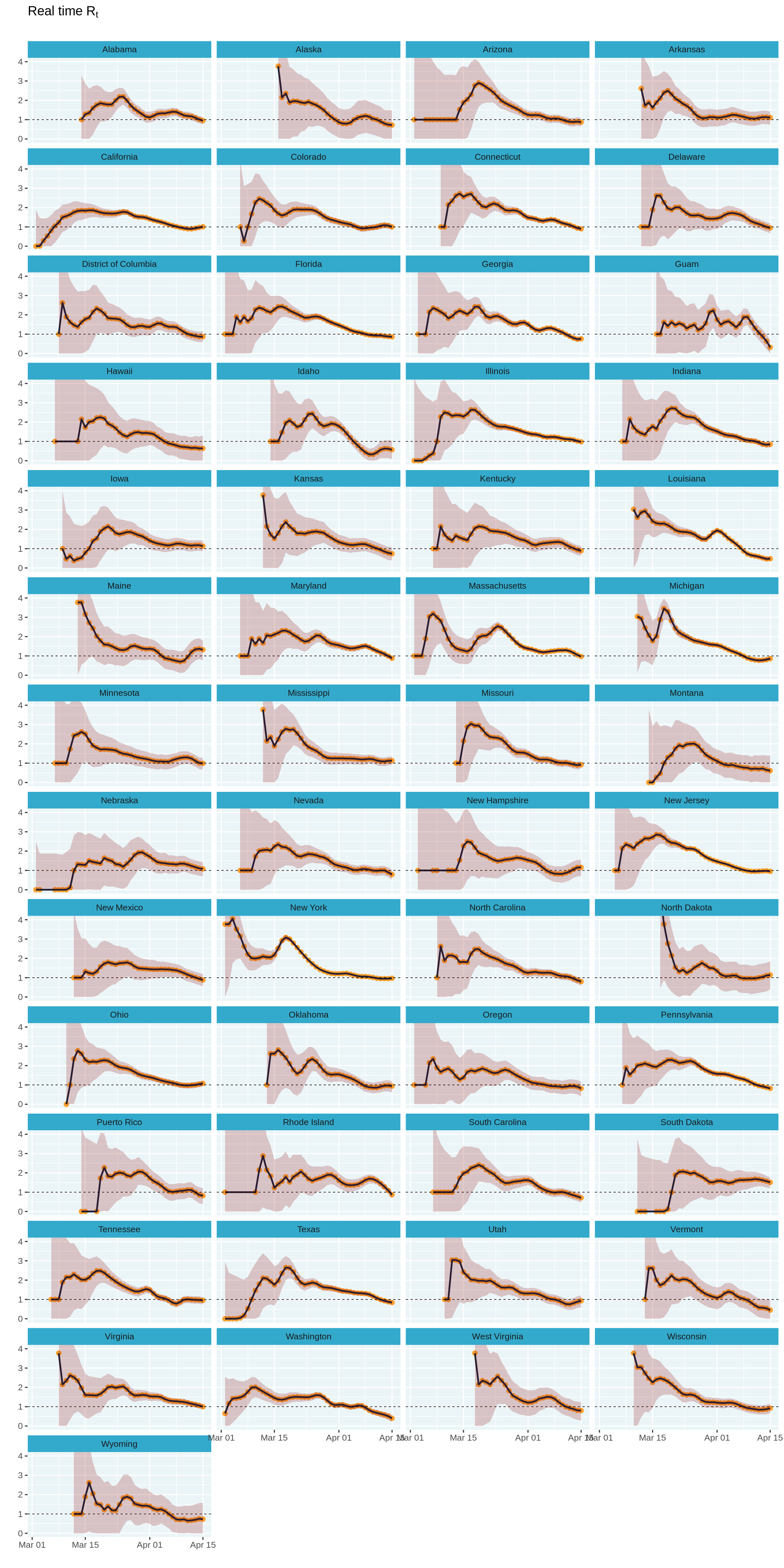
It is now time to loop across all states and compute these estimates. We can do this easily by grouping by state, splitting the data into one table per state, and using purrr::map_df to estimate $R_t$ for each state and combine them back into a single table.
# ⚠️This function can take a couple of minutes to run
# as it loops across all states
estimates_all <- covid_cases %>%
filter(date >= "2020-03-01") %>%
group_by(state) %>%
# Ignore states that have not reached 100 infections
filter(max(cases) > 100 ) %>%
group_split() %>%
map_df(~ {
.x %>%
smooth_new_cases() %>%
compute_likelihood() %>%
compute_posterior() %>%
estimate_rt()
}) %>%
ungroup()
estimates_all %>%
display_random()
| state | date | r_t_most_likely | r_t_lo | r_t_hi |
|---|---|---|---|---|
| New Jersey | 2020-03-15 | 2.72 | 2.01 | 3.42 |
| Alaska | 2020-04-02 | 0.80 | 0.04 | 1.54 |
| Maryland | 2020-03-12 | 1.67 | 0.00 | 3.33 |
| Washington | 2020-03-10 | 2.01 | 1.49 | 2.52 |
| New Mexico | 2020-03-28 | 1.58 | 0.89 | 2.17 |
| South Dakota | 2020-04-08 | 1.63 | 1.12 | 2.09 |
We can now create a small multiples plot of the estimates across all states. The use of ggplot2 makes this really easy and all we had to add was an extra line of code!
# Increase plot height and width
options(repr.plot.height = 40, repr.plot.width = 20)
estimates_all %>%
plot_estimates() +
facet_wrap(~ state, ncol = 4) +
labs(subtitle = "")
# Reset plot dimensions
options(repr.plot.height = 12, repr.plot.width = 8)
While the small multiples plot is perfect, it is hard to navigate to a state based on its geographic location. What if we could plot each state close to its geographic location?
Thankfully, Ryan Hafen has created the geofacet package that allows us to lay out these small multiples on a geographic grid with a single line of code.
⚠️ Unfortunately, I was not able to install the geofacet package on colab (I suspect it is because of system dependencies required by the sf package), and hence the code chunk below will fail to execute. I have included a saved version of the plot I generated locally, so you can get a sense of how it looks.
# ⚠️ CAUTION: This code will error on colab
# options(repr.plot.height = 40, repr.plot.width = 20)
# estimates_all %>%
# mutate(state = state.abb[match(state, state.name)]) %>%
# plot_estimates() +
# geofacet::facet_geo(~ state, ncol = 4) +
# labs(subtitle = "") +
# theme(strip.text = element_text(hjust = 0))
# options(repr.plot.height = 12, repr.plot.width = 8)

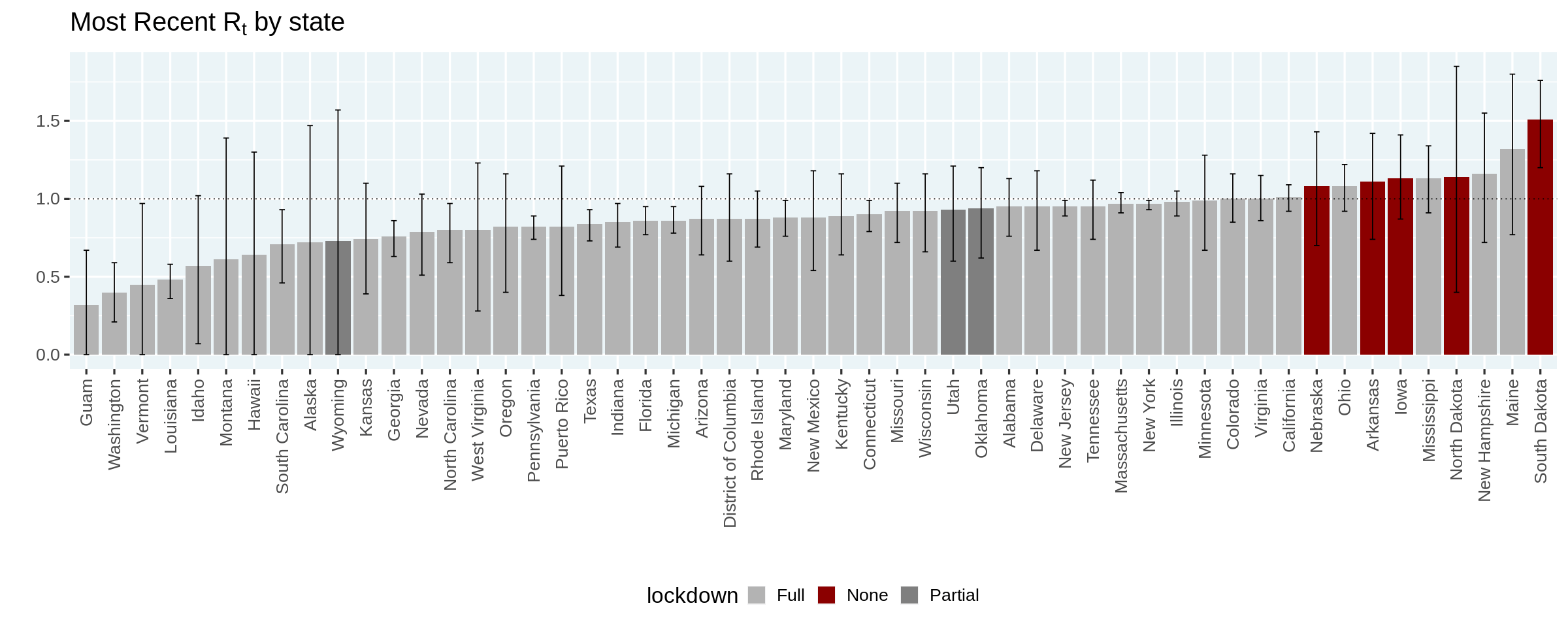
Finally, let us recreate the plot in Kevin's article that orders the states based on the most likely estimated value of $R_t$, and colors them based on the state of lockdown.
⚠️ Please note that this is a purely descriptive plot and one cannot draw any conclusions on the efficacy of lockdowns
options(repr.plot.width = 20, repr.plot.height = 8)
no_lockdown = c('North Dakota', 'South Dakota', 'Nebraska', 'Iowa', 'Arkansas')
partial_lockdown = c('Utah', 'Wyoming', 'Oklahoma')
estimates_all %>%
group_by(state) %>%
filter(date == max(date)) %>%
ungroup() %>%
mutate(state = forcats::fct_reorder(state, r_t_most_likely)) %>%
mutate(lockdown = case_when(
state %in% no_lockdown ~ 'None',
state %in% partial_lockdown ~ 'Partial',
TRUE ~ "Full"
)) %>%
ggplot(aes(x = state, y = r_t_most_likely)) +
geom_col(aes(fill = lockdown)) +
geom_hline(yintercept = 1, linetype = 'dotted') +
geom_errorbar(aes(ymin = r_t_lo, ymax = r_t_hi), width = 0.2) +
scale_fill_manual(values = c(None = 'darkred', Partial = 'gray50', Full = 'gray70')) +
labs(
title = expression(paste("Most Recent R"[t], " by state")),
x = '', y = ''
) +
theme(axis.text.x.bottom = element_text(angle = 90, hjust = 1, vjust = 0.5))
options(repr.plot.width = 12, repr.plot.height = 5)
In this article, we replicated Kevin's analysis in R, using the tidyverse. We learned some useful tricks to compute likelihoods and posteriors. I learned a ton in this process!
I can think of several next steps, but will highlighting one major one that comes to mind. Given that the functions developed in this article rely on a fairly simple input table with three columns: location, date, cases, an interesting next step would be to turn this into an R package. This will make it easier to estimate $R_t$ for other geographies.
I would like to end by thanking Kevin Systrom for publishing an interesting post and sharing his code. I would also like to thank my colleagues at DataCamp for their excellent feedback on an initial version of this article.
If you have any feedback/comments on this article, or would like to suggest other extensions, you can find me on twitter @ramnath_vaidya and github. To learn more about R programming

Learn more about R
Course
Course
Course
Tutorial
Łukasz Deryło
Tutorial
Karlijn Willems
Tutorial
Salin Kc
Tutorial
Daniel Schütte
Tutorial
Hugo Bowne-Anderson
Tutorial
Ryan Sheehy