
Track
Python Data Fundamentals
28 hr
Imagine you are trying to find the lowest point among the hills while blindfolded. Since you are limited by your touch, you can only feel the ground immediately around you to determine which way is down. This is essentially what machine learning algorithms do when they are trying to find the best solution to a problem.
They frame the problem into a mathematical function whose inputs and outputs represent a hilly surface. Finding the minimum of this function means you’ve reached the best solution to the problem. One of the most popular algorithms for doing this process is called Stochastic Gradient Descent (SGD).
In this tutorial, you will learn everything you should know about the algorithm, including some initial intuition without the math, the mathematical details, and how to implement it in Python.
Stochastic Gradient Descent (SGD) is an optimization technique used in machine learning to minimize errors in predictive models. Unlike regular gradient descent, which uses the entire dataset to calculate the gradient and update model parameters, SGD updates the parameters using only one data point at a time. This makes it faster and more efficient for large datasets, although it can be noisier and less stable. SGD helps find the optimal values for model parameters to improve the accuracy of predictions.
The first thing we need to understand straight away is that stochastic gradient descent (SGD) is not a machine learning algorithm. Rather, it is merely an optimization technique that can be applied to ML algorithms.
So, what is optimization? To understand this, let’s work our way up from the problem statement stage of machine learning.
Let’s say we are trying to predict diamond prices based on their carat value (a carat is 0.2 grams). This is a regression problem as the model produces numeric values.
To solve the problem, we have a wide range of algorithms at our disposal, but let’s choose Simple Linear Regression, which has the simple formula of f(x) = mx + b where:
b is the base diamond pricem is the price increase per caratx is the carat value of the diamondf(x) is the predicted price of the diamondThis linear equation represents our model. Our goal is to find the best values for m and b that will make our predictions as accurate as possible across all the diamonds in our dataset.
If we had another feature in our dataset, like diamond volume, our formula would change to f(x1, x2) = m1*x1 + m2*x2 + b, where:
b is the base diamond pricem1 is the price increase per caratm2 is the price increase per unit volumex1 is the carat value of the diamondx2 is the volume of the diamondf(x) is the predicted price of the diamondNow, we would need to find the optimal values for m1, m2, and b.
In general, all machine learning models have equations like the ones above with one or more parameters. Thus, the definition of optimization in this context becomes: “Given this model and this dataset, find the optimal values for the parameters in the equation.”
There are many optimization algorithms that can perform this task, like Stochastic Gradient Descent , which is the focus of our tutorial. But to fully understand how SGD works, let’s review some fundamental ideas behind it.
To understand SGD, we need to learn the regular gradient descent algorithm (GD), which shares many of the fundamental ideas behind its stochastic version. Simple gradient descent starts with the concept of error in machine learning.
ML algorithms usually guess what the correct answer is to a problem. We call this answer a prediction and it is not always accurate. So, we introduce a new term called “error” or “loss” that represents the difference between the actual answer and the model’s prediction. Our goal is to build a model that minimizes this error.
If our model f(x) guesses $10,000 for a diamond that actually costs $12,000, the error is $2,000. We should adjust our model to decrease this error. But the model's predictions must be good for any diamond, not just a single one. So, we need a way to combine the error for all diamonds in our dataset. This is where cost functions come in.
A cost function combines all individual errors into one number that represents the overall performance of our model. Lower overall cost means our model’s predictions are better.
Cost functions change based on what kind of problem we are solving.
In regression problems, the model predicts numeric values like how much a diamond costs or how much time it takes to swim a lap. In classification, the model predicts the category to which something belongs. For example, is a mushroom edible or not, or is the object in the image a cat, dog, or horse?
There are other types of problems, but the important point is that each requires different cost functions. In this tutorial, we will focus on Mean Squared Error (MSE), which is often used in regression.
The difference between the actual values (ground truth) and the model’s predictions is called an error or loss. Consequently, a function that combines all these errors or losses is referred to as an error function, loss function, or cost function. Different sources may use these terms interchangeably; this tutorial will use the term loss function from now on.
In regression problems, it is common to see the following graph that plots actual values (ground truth) against the model's predictions.
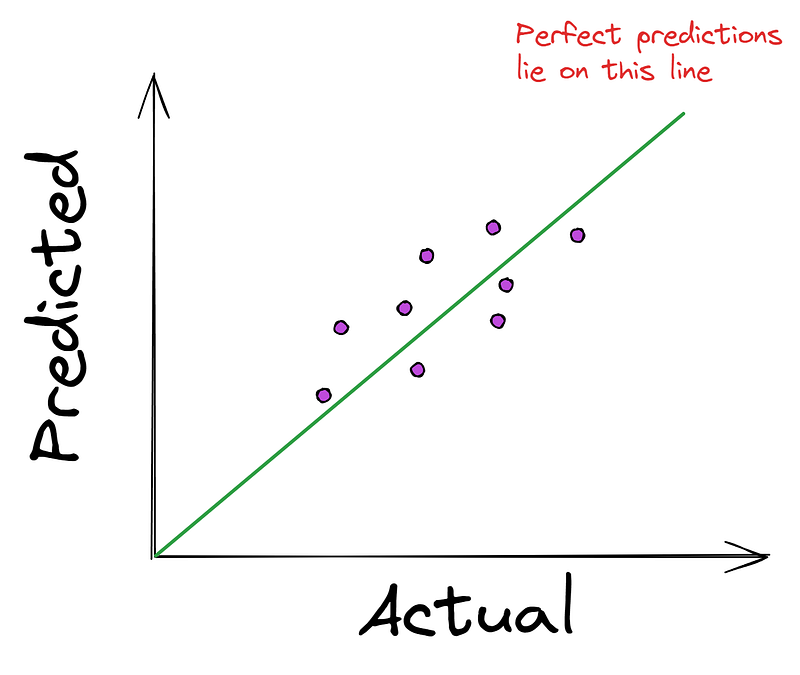
The closer the points are to the straight line, the better model predictions are. Therefore, most regression algorithms try to minimize the average distance from the points to the perfect line. And as we mentioned earlier, the minimization happens using a cost function like Mean Squared Error (MSE).
MSE takes the actual and predicted values as inputs and produces the squared average distance to the perfect line.
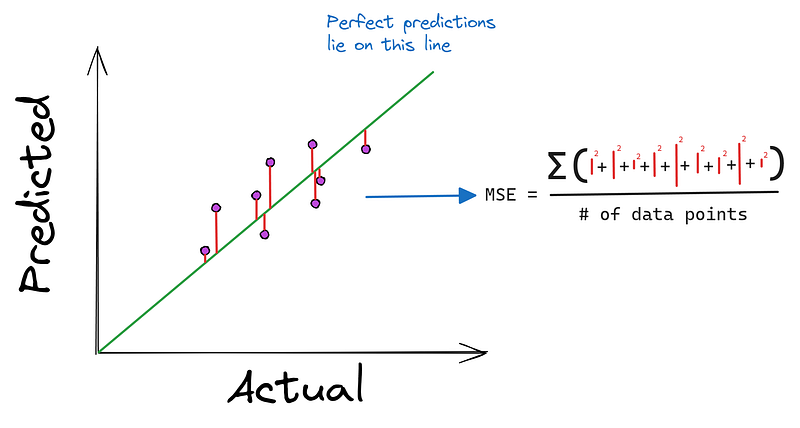
You might be asking “Why square the differences rather than taking their absolute value?”. The first reason is that it is very easy to find the derivative of a square function. Also, squaring the differences emphasizes bigger errors, penalizing the model for its worst predictions.
That’s why MSE is preferred to other alternative functions such as Mean Absolute Error (MAE), which on the surface look simpler but are harder to differentiate.
The next piece in the gradient descent puzzle is the gradient itself. Let’s go back to our “down the hill” analogy to better understand it.
We were standing on top of the hill blindfolded and wanted to reach the bottom as quickly as possible. If we poured water at our feet, which way would it flow? It would flow downhill in the direction of the steepest descent.
This is exactly what the gradient tells us, but in the opposite direction. The gradient points uphill — in the direction of the steepest ascent. When we are trying to minimize the error, we simply go in the opposite direction of the gradient to find the quickest way down.
Mathematically, gradient tells us how a function’s outputs change as we change its inputs. More specifically, it points us in the direction where the function increases most rapidly.
In the context of machine learning, where we’re trying to minimize error using a loss function, the gradient becomes our guide for finding the quickest path to reduce that error.
The gradient is represented as a vector — one for each input parameter of our function. Each number in this vector tells us how much the function would change if we made a small adjustment to the corresponding parameter.
So, how do you find the gradient of a function?
For single variable functions like f(x) = x ** 2, the gradient is the derivative of the function, which is given as a vector with one element - [2x].
For multivariable functions like f(x1, x2) = x1 ** 3 - x2 ** 2, the gradient contains the partial derivatives of the function with respect to each input. So, for the second function, the gradient vector is [3x1 ** 2, 2*x2].
Coming back to MSE, which has the following formula:
MSE = (1/n) * Σ(y - f(x))² where:
f(x) is mx + bm and b are function variablesx is the carat value of the diamondsn is the number of data pointsy is the actual price of diamondsSo, its gradient is the partial derivatives of MSE with respect to m and b:
∂/∂m (MSE) = (-2/n) * Σ(x * (y - (mx + b)))
∂/∂b (MSE) = (-2/n) * Σ(y - (mx + b))
The gradient = [∂/∂m (MSE), ∂/∂b (MSE)]Don’t worry too much about these formulas. The key idea is that they tell us how the mean squared error changes if we change m or b a tiny bit.
Now, we have everything we need to execute gradient descent or, in other words, reach the bottom of the hill as efficiently as possible. But do we jump in that direction or take small steps? Well, that’s determined by the gradient, isn’t it? The size of the gradient tells us how far we go down at each step.
But suppose the gradient is so large that instead of reaching the bottom, we shoot over and end up on top of another hill in a single step. Surprisingly, this happens a lot in gradient descent, so we introduce a parameter called step size, which controls the effects of the gradient.
Before taking a step, we simply multiply the gradient by the step size, which lowers its magnitude. For example, if our gradient tells us to take a step of 3.56 downhill, a step size of 0.1 turns the distance into 0.356.
It will take us longer to reach the bottom but now, we don’t run the risk of skipping it altogether.
Step size is usually called learning rate in machine learning and typically takes values between 0.001 and 0.3.
So, let’s see the mathematical version of this process.
First, we give m and b parameters of our model random values:
m = 0.215 # Generated randomly
b = 0.059Using these, we calculate the initial MSE on the entire dataset:
MSE = (1/n) * Σ(y - (0.215 * x + 0.059))² = ...Now, to lower this error, we need to take a small step in the opposite direction of the gradient, or in other words, we need to update m and b using the gradient and the learning rate:
m_new = 0.215 - alpha * (∂/∂m (MSE))
b_new = 0.059 - alpha * (∂/∂b (MSE))Most resources choose alpha or α (the Greek letter) to denote learning rate.
After we have new values for m and b, we calculate MSE again:
MSE_new = (1/n) * Σ(y - (m_new * x + b_new))²Now, we calculate the gradient again and continue in this fashion until we reach a stopping condition.
Learn how learning rate affects training visually by checking out this gradient descent article.
Since we are blindfolded, we can’t really see when we have reached the bottom, especially when taking small steps.
So, we need some conditions to stop our descent. Typically, these rules are used:
These rules are set by you, the ML engineer, when you are performing gradient descent. Python implementations of the algorithm usually have arguments to set these rules and we will see some of them later.
Advantages:
Challenges:
In the next section, we’ll see how Stochastic Gradient Descent addresses some of these challenges, particularly for large datasets.
Once you wrap your head around regular gradient descent, SGD becomes very easy to understand.
While gradient descent is one of the most elegant optimization algorithms out there, it has a significant disadvantage when dealing with large datasets. Remember that in each step, we calculate the gradient using all the data points in our dataset:
∂/∂m (MSE) = (-2/n) * Σ(x * (y - (mx + b)))
∂/∂b (MSE) = (-2/n) * Σ(y - (mx + b))Here, x and y are arrays containing all the carat values and actual prices of diamonds. This means that we'd be using every single diamond's information to update parameters in each step.
As you can imagine, this becomes computationally expensive and time-consuming when we have millions of data points. In the era of big data, this limitation can make regular gradient descent impractical for many real-world machine learning problems.
“Stochastic” means “randomly determined,” and that’s exactly what SGD does: it introduces randomness into our optimization process.
Instead of using all data points to calculate the gradient, SGD randomly selects one data point at each step. It uses this single point to calculate an estimate of the gradient and update the parameters.
Because SGD only looks at one data point at a time, it can make more frequent updates to the parameters. This allows it to traverse the error surface (the hill) more quickly, especially for large datasets.
However, this speed comes at a cost. Since we’re using a single data point to estimate the gradient of the entire dataset, our estimates are much noisier. This means our path down the error surface is less smooth and more erratic.
To perform SGD, we first define a stochastic cost function.
Instead of calculating the Mean Squared Error over all data points, we now look at the squared error for a single, randomly chosen point:
Cost = (y - f(x))²Where y is the actual price of the randomly chosen diamond, and f(x) = mx + b is our predicted price for that diamond.
Then, we calculate the stochastic gradient of this cost function with respect to our parameters m and b:
∂/∂m (Cost) = -2x(y - (mx + b))
∂/∂b (Cost) = -2(y - (mx + b))
The stochastic gradient = [∂/∂m (Cost), ∂/∂b (Cost)]Using this stochastic gradient, we update our parameters in the same fashion as regular gradient descent:
m_new = m_old - learning_rate * ∂/∂m (Cost)
b_new = b_old - learning_rate * ∂/∂b (Cost)The key idea in SGD is that taking each step involves a single randomly chosen data point. The rules for when to stop the descent stays the same as regular gradient descent.
In practice, vanilla SGD where parameters are updated for each training example is rarely used. The reason is that the algorithm’s updates have too high variance, which can cause the loss function to fluctuate, making it harder to converge to the exact minimum.
Regular gradient descent is powerful and provides more stable results, but as we mentioned before, it uses all data points in each step, making it impractical for current datasets.
To strike the balance between stability and speed, mini-batch gradient descent is frequently used, especially in neural networks. In mini-batch GD, instead of using a single random sample, a batch of samples are used when making parameter updates. Common batch sizes include 16, 32, 64 and so on.
So, if you use a batch size of 1, then you’ve got SGD. If your batch size is equal to the dataset size, you have regular gradient descent. Any batch size other than those values gives you mini-batch gradient descent.
Here is a table summarizing their differences and when to use each one:
| Type | Update Frequency | Computational Efficiency | Memory Requirements | Convergence Stability | Best Use Case |
| Gradient Descent (GD) | Entire dataset per update | Slowest due to full dataset usage | Requires entire dataset in memory | Most stable, but slowest | Small datasets where stability is crucial |
| Stochastic Gradient Descent (SGD) | One example per update | Fastest, processes one example at a time | Low memory requirement | High variance, can fluctuate | Large datasets needing fast updates |
| Mini-Batch Gradient Descent | Batch of examples per update | Balances efficiency and speed, more efficient than GD, slower than SGD | Requires memory for one batch | More stable than SGD, less stable than GD | Large datasets needing balance of stability and efficiency |
One important concept in any type of optimization algorithm is an epoch. It refers to one complete pass through the entire training dataset.
In an epoch, the algorithm processes every sample in the training dataset exactly once. For each sample (or mini-batch of samples), the model makes predictions, calculates the loss, and updates the weights according to the gradient of the loss. An epoch marks a cycle of improvement for the model. After each epoch, you can typically observe how the model’s performance has changed.
Training usually involves multiple epochs (at least 10 is recommended). The number of epochs is a hyperparameter that you can tune. Often, the data is shuffled before each epoch to prevent the model from learning the order of the training examples.
In our blindfolded hill exploration analogy, an epoch is one complete exploration of the entire landscape. During each epoch, you:
After each full exploration, you start over from your new position. Multiple epochs give the model repeated opportunities to explore the loss landscape, improving its chances of finding a good minimum.
However, multiple epochs don’t guarantee finding the global minimum, and the entire process can be influenced by factors such as the starting point or the complexity of the loss landscape.
In this section, we will implement SGD with support for batch size (mini-batch GD) using only Numpy.
First, let’s import the necessary libraries:
import seaborn as sns
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
np.random.seed(42)We will use 10,000 data points from the Diamonds dataset available in Seaborn. We will take only the carat feature and the price column as target:
# Load the data
dataset_size = 10_000
diamonds = sns.load_dataset('diamonds')
# Extract the target and the feature
xy = diamonds[['carat', 'price']].values
np.random.shuffle(xy) # Shuffle the data
xy = xy[:dataset_size]
xy.shape
(10000, 2)Now, let’s split the data into training and test sets, setting train size to 80% of the total.
# Split the data
np.random.shuffle(xy)
train_size = int(0.8 * dataset_size)
train_xy, test_xy = xy[:train_size], xy[train_size:]
train_xy.shape
(8000, 2)Then, let’s define our model function:
def model(m, x, b):
"""Simple linear model"""
return m * x + bWe are doing simple linear regression with only two independent variables m and b.
We should also define our loss function MSE:
def loss(y_true, y_pred):
"""Mean squared error"""
return np.mean((y_true - y_pred) ** 2)Now, we define a function called stochastic_gradient_descent that takes six arguments:
x and y represent the single feature and target in our problemepochs denotes how many times we want to perform the descent (more on this later)learning_rate is the step sizebatch_size to control how frequently we make parameter updatesstopping_threshold sets the minimum value the loss should decrease at each stepdef stochastic_gradient_descent(
x, y, epochs=100, learning_rate=0.01, batch_size=32, stopping_threshold=1e-6
):
"""
SGD with support for mini-batches.
"""To start, we initialize the parameters we want to optimize with random values and set the loss to infinity:
# Initialize the model parameters randomly
m = np.random.randn()
b = np.random.randn()
n = len(x) # The number of data points
previous_loss = np.infThen, we start a for loop using the epochs parameter. Inside the loop, we shuffle the data to make computations more robust:
for i in range(epochs):
# Shuffle the data
indices = np.random.permutation(n)
x = x[indices]
y = y[indices]Then, the actual gradient computation starts inside another for loop.
for j in range(0, n, batch_size):
x_batch = x[j:j + batch_size]
y_batch = y[j:j + batch_size]We extract the batch from x and y and compute the gradients:
# Compute the gradients
y_pred = model(m, x_batch, b)
m_gradient = -2 * np.mean(x_batch * (y_batch - y_pred))
b_gradient = -2 * np.mean(y_batch - y_pred)We use the model function we created above to make a prediction with the current values of m and b. Then, we find the partial derivatives that make up the gradient using the formula we stated in the earlier section.
Using the partial derivatives and the learning rate, we update the parameters:
# Update the model parameters
m -= learning_rate * m_gradient
b -= learning_rate * b_gradientHere is the full code so far:
def stochastic_gradient_descent(
x, y, epochs=100, learning_rate=0.01, batch_size=32, stopping_threshold=1e-6
):
"""
SGD with support for mini-batches.
"""
# Initialize the model parameters randomly
m = np.random.randn()
b = np.random.randn()
n = len(x)
previous_loss = np.inf
for i in range(epochs):
# Shuffle the data
indices = np.random.permutation(n)
x = x[indices]
y = y[indices]
for j in range(0, n, batch_size):
x_batch = x[j:j + batch_size]
y_batch = y[j:j + batch_size]
# Compute the gradients
y_pred = model(m, x_batch, b)
m_gradient = -2 * np.mean(x_batch * (y_batch - y_pred))
b_gradient = -2 * np.mean(y_batch - y_pred)
# Update the model parameters
m -= learning_rate * m_gradient
b -= learning_rate * b_gradientContinuing the function outside the inner loop, we calculate the loss for the epoch:
# Compute the loss
y_pred = model(m, x, b)
current_loss = loss(y, y_pred)If the current_loss is smaller than the stopping_threshold we stop the entire process:
if previous_loss - current_loss < stopping_threshold:
break
previous_loss = current_lossOtherwise, we set previous_loss to current_loss. In the end, we return the optimized m and b parameters:
return m, bI’ve pasted the entire code into this GitHub gist so that you can look at the whole picture.

Let’s test how well the found parameters work by running the model on the test set:
# Find the optimal parameters
m, b = stochastic_gradient_descent(train_xy[:, 0], train_xy[:, 1])
# Make predictions
y_preds = model(m, test_xy[:, 0], b)
# Compute and print the loss
mean_squared_error = loss(test_xy[:, 1], y_preds)
mean_squared_error ** 0.5
1595.3955619759456The square root of MSE is about $1,600, which means our model is off by $1,600 on average. To improve the error, we can increase the number of epochs or use a larger dataset.
The implementation of SGD in the last section is crude and inefficient. It simply serves to solidify the intuition we have built in previous sections with a coding walkthrough.
In practice, you almost never reimplement SGD manually but use already available versions in popular frameworks.
For example, Scikit-learn provides SGDRegressor and SGDClassifier estimators to train various ML algorithms such as:
with SGD as the optimization algorithm.
from sklearn.linear_model import SGDRegressor, SGDClassifier
# SGD for Linear Regression with 1000 epochs
regressor = SGDRegressor(loss='squared_loss', max_iter=1000)In PyTorch, it is available as the SGD class inside the optim module:
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=0.01)To learn training models and optimize them in PyTorch, refer to DataCamp’s Introduction to PyTorch course.
In Keras, SGD is available under the same name:
from tensorflow.keras.optimizers import SGD
optimizer = SGD(learning_rate=0.01)To learn training models and optimize them in TensorFlow, refer to DataCamp’s Introduction to TensorFlow course.
There are many best practices and tips for using SGD or similar algorithms. Below, we will outline some of them:
Today, we have learned one of the key optimization algorithms in machine learning — Stochastic Gradient Descent.
First, we have built up intuition and its fundamental ideas by considering a regular gradient descent algorithm. We’ve extensively used a hillside analogy where we are trying to find the bottom while being blindfolded.
We have learned that SGD and regular GD differ by the amount of data points used in making parameter updates. To solidify our intuition and hash out the mathematical details, we have implemented SGD in Numpy.
Please remember that SGD is only part of the entire ML training process. To learn more about its role, check out the following resources:
Top DataCamp Courses
Track
Track
Track
cheat-sheet
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Kurtis Pykes
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
code-along
George Boorman



