
The use of data science and AI in financial services is hardly news. From banks offering loans based on credit scores, insurance companies pricing policies based on risks, to investment funds offering financial advice based on projected risks and returns, data has always been a mainstay for the financial sector. However, to succeed in data science and AI, financial services organizations need to deepen their use of machine learning and AI. In a recent webinar, Shameek Kundu, former Group CDO of Standard Chartered and current Chief Strategy Officer at TruEra, outlined how to accelerate AI adoption in financial services.
AI Application is broad but shallow
Shameek explains that there is a broad set of AI and machine learning use cases in financial services today. Here are some notable real-world examples.
- AXA’s machine learning predictive underwriting streamlines the policy purchase process
- Optical Character Recognition (OCR) helps Citibank expedites their manual document processing
- Investigators at the OCBC Bank leverages machine learning to detect fraudulent transactions
However, that does not mean that financial services organizations are making the most of data science and AI, as deep adoption of these technologies is needed. Temasek reported that practically all financial services use AI in their processes to some extent. Yet, only 13% are truly using AI in a majority of their processes due to industry-wide obstacles.
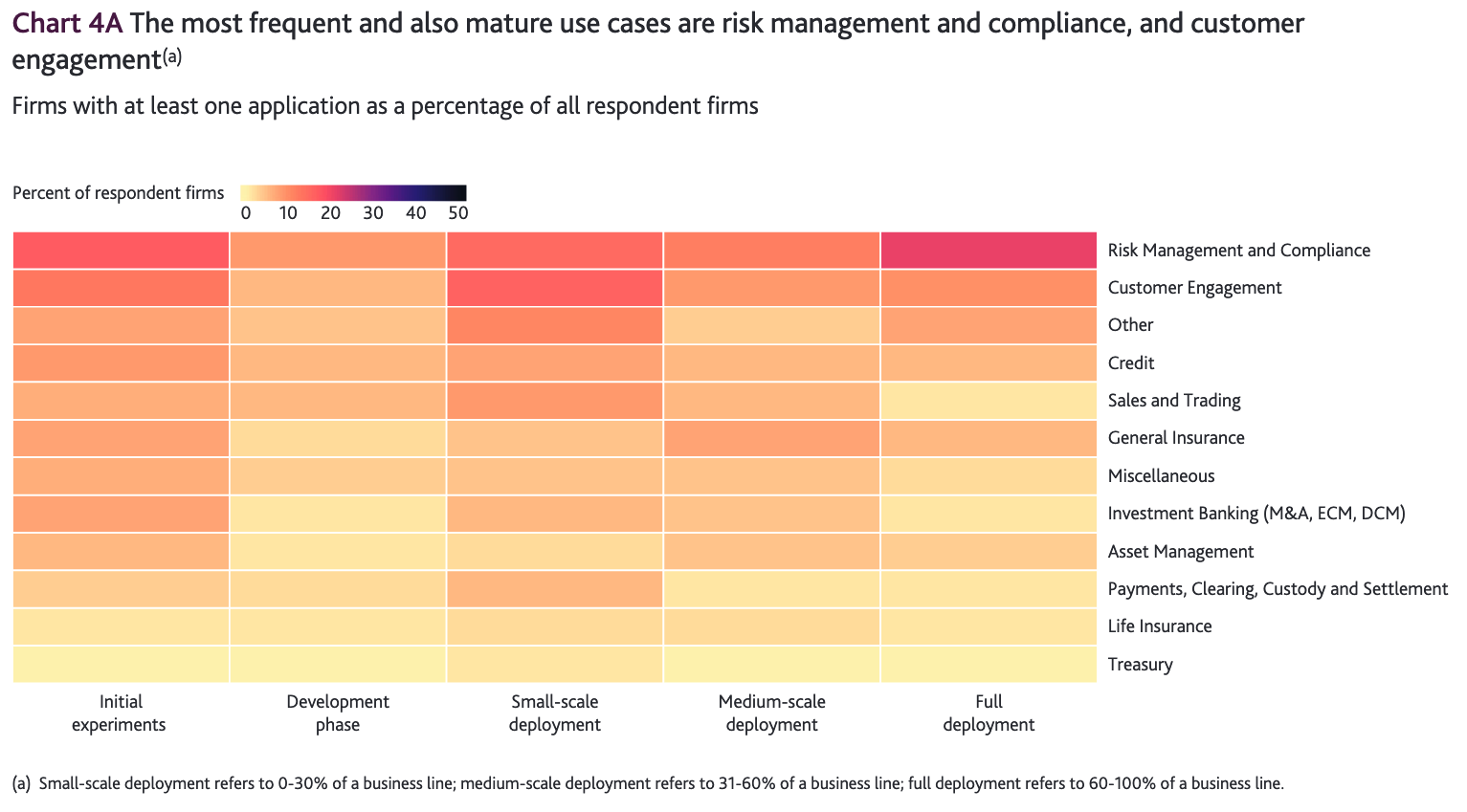 Many AI projects remain in their infancy, unable to reach the end goal of full deployment, according to the Bank of England Machine Learning Survey
Many AI projects remain in their infancy, unable to reach the end goal of full deployment, according to the Bank of England Machine Learning SurveyObstacles for Widespread Adoption of AI
Limited data quality and availability
Increasingly, regulators are scrutinizing how companies are processing data, as evident by the passing of state data privacy laws in the United States and the EU. Moreover, cross-border sharing of data remains limited due to geographical variation in the data privacy laws. Such regulations translate to limited data for machine learning models to train and make predictions.
The immature and fragmented technology landscape
As the nascent field of machine learning continues to evolve, it experiences growing pains in the form of a relatively immature and fragmented technology landscape.
Today, organizations take around one to three months to deploy a machine learning model to production, according to Algorithima’s survey. The long lead time is a symptom that arises from the lack of mature machine learning operationalization (MLOps) tools. However, it is only a matter of time before MLOps tooling grows given its rapid pace of development.
The lack of trust in machine learning
Complex machine learning models are not easy to interpret or to explain their predictions. Lacking an understanding of the black-box models, end-users find it hard to trust their outputs.
A case in point is IBM Watson. Once touted as the future of healthcare, its black-box model failed to earn trust from its end-users. These doctors rightfully refused to defer life-and-death decisions to an AI black box.
Similarly, financial services regulators and bankers working on high-stake decisions like fraud detection find it difficult to trust black-box models. This is especially so when transparency is integral in preventing discrimination and unfair outcomes, and meeting disclosure obligations. Recognizing this, Federal Reserve Gov. Brainard said in a November 2018 speech, “the challenge of explainability can translate into a higher level of uncertainty about the suitability of an AI approach,” and called for firms in the financial services to remain vigilant in applying black-box models.
Last Mile Operationalization
Machine learning projects also experience the last-mile problem – the challenge of getting results to the right people at the right time. For instance, phone app users expecting immediate gratification would not be pleased to learn that a particular recommendation takes ten minutes to load.
Resolving the problem of last-mile operationalization requires not only a maturing MLOps tooling landscape but for machine learning practitioners to pay attention to the users’ experience.
The Lack of Data Talent
The full-scale deployment of AI projects takes a team of data professionals – including data scientists, analysts, engineers, and machine learning scientists. As such, the lack of data talent remains a roadblock for machine learning adoption across industries, including the financial services industry.
A Deloitte survey reveals that 23% of the most mature AI adopters reported a significant talent skills gap for AI implementation. Addressing this skill gap requires a focused reskilling and upskilling strategy for specific talents.
Conclusion
The roadblocks listed above reveal that they can be addressed given sufficient time and effort. Addressing such problems would bring the financial services industry one step closer to unlocking its vast potential for AI adoption.
If you are interested in the application of AI in financial services, make sure to tune in to Shameek’s on-demand webinar on “Scaling AI Adoption in Financial Services”.

