Course
Machine Learning with Tree-Based Models in Python
5 hr
116.3K
Imagine searching for a particular machine learning research paper on Google. You find something interesting and want to see the code implementation, dataset, and results. You will spend hours and hours searching for them individually. Now imagine you have to repeat this step 30 more times for your thesis or research project. It can be a nightmare.
Papers With Code has got your back. It's made things far easier to read research papers, giving a quick glance at their summary, code implementation, result, and dataset. Furthermore, you can compare different models' architecture results on a similar topic using the leaderboard feature.
It is so much more than searching for a research paper. You can filter your search using tags on various tasks, sub-tasks, models, datasets, and methods to explore the topic in depth.
In this blog, we will explore Papers With Code's various key features and learn the best way to conduct research for machine learning projects.
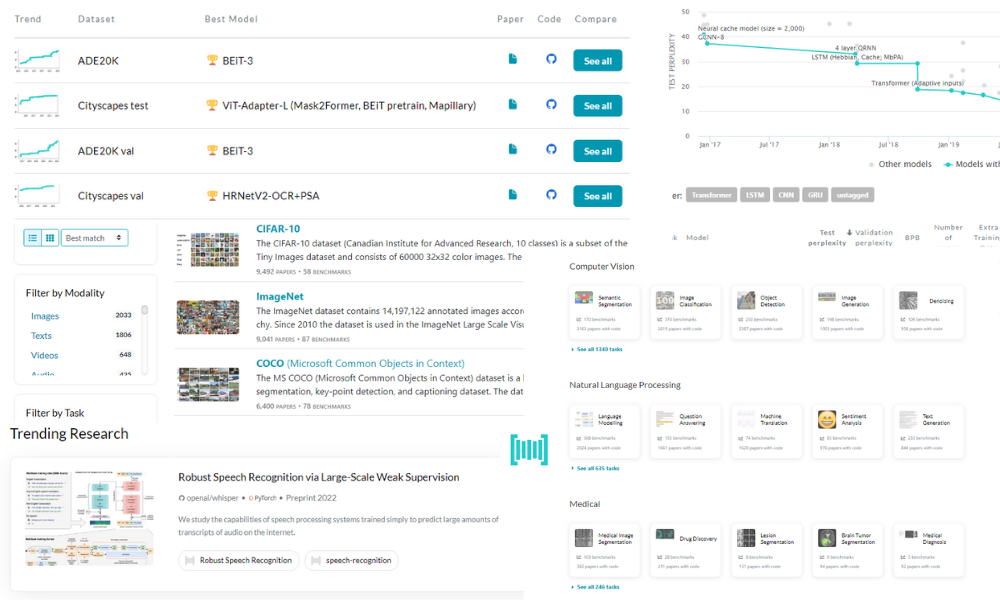
On the landing page, you will see the trending research papers based on the number of starts per hour.
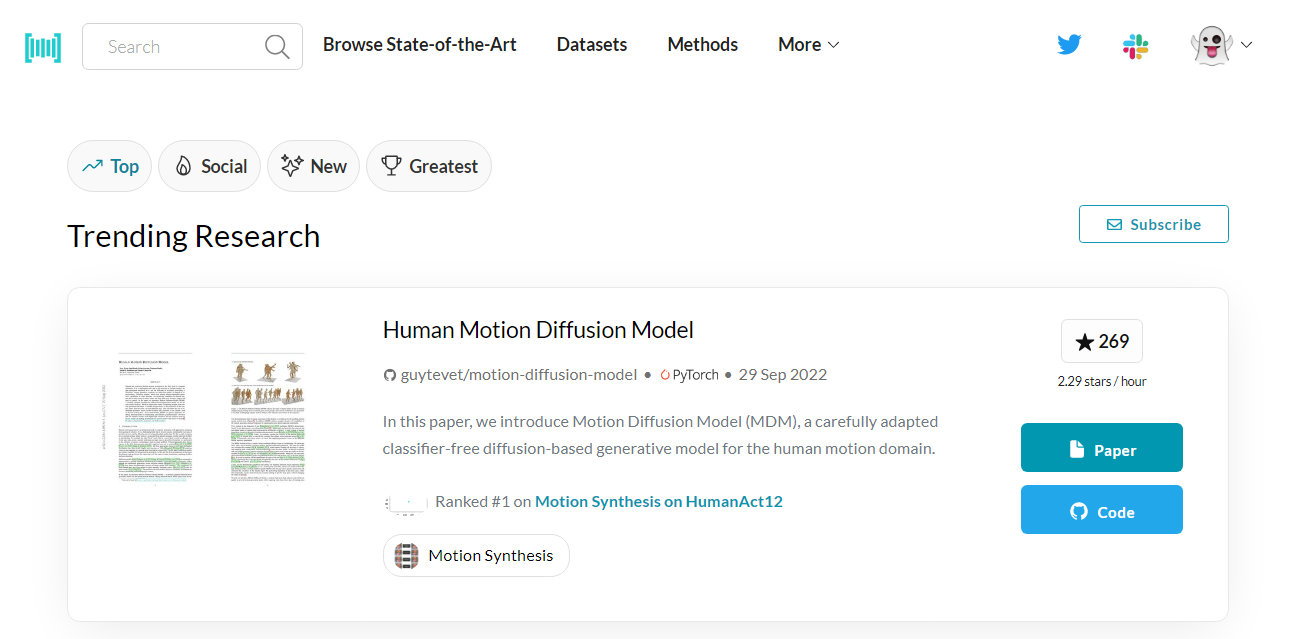
Papers With Code | Trending
If you like the research paper, click on the Paper button to read the abstract and view results, datasets, and various code implementations. Or, if you are interested in the implementation, you can click on Code and access the GitHub repository consisting of results, code implementations, and dependencies.
The trending page is similar to any social media landing page. You can keep scrolling down to see past trending papers with 1000+ stars and multiple community-contributed code implementations.
Papers With Code is a community-driven platform for learning about state-of-the-art research papers on machine learning. It provides a complete ecosystem for open-source contributors, machine learning engineers, data scientists, researchers, and students to make it easy to share ideas and boost machine learning development.
All the content on the Papers With Code is openly licensed under CC-BY-SA, and anyone can contribute using the “Edit” buttons.
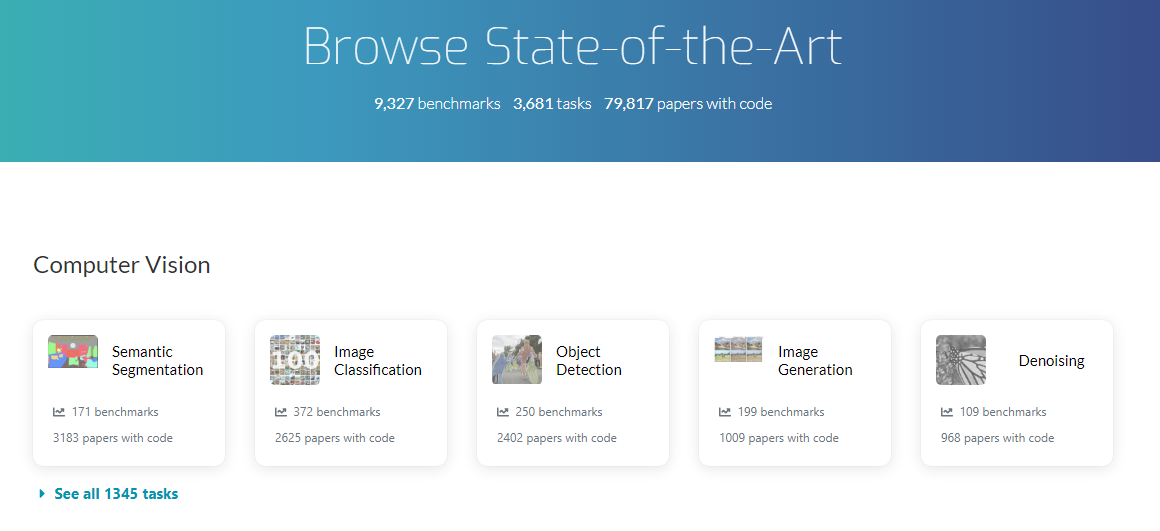
Papers With Code | Browse State-of-the-Art
By clicking on Browse State-of-the-Art tab, you will see categories and subcategories based on various machine learning fields of study. For example:
Each of the above categories has subcategories. And when you click on a subcategory card, you see a brief definition of the subcategory and the benchmark.
The primary purpose of the Browse State-of-the-Art section is to provide you with information on best-performing models on a given dataset, popular libraries, a list of datasets, sub-tasks, and most implemented papers. Furthermore, you can compare various model performance metrics on the same dataset.
If you want to learn about various categories of machine learning, check out our Machine Learning Courses page. It consists of a collection of beginner-friendly courses, machine learning with Python and R, and project-based courses. You can also look at the popular templates, tutorials, and cheat sheets.
Papers With Code | Datasets
Instead of categories and subcategories, you can search for a specific dataset or use various filters to find the dataset.
Generally, the website is interconnected, and you don’t have to find datasets individually. But, if you are working on research that requires multiple datasets on a specific machine learning problem, the Dataset tab will help you find any popular dataset using search and filter features. You can filter datasets based on modality, tasks, and languages.
The fun part starts when you click on a particular dataset. You will find various interactive sections such as:
In short, the Dataset tab is fully integrated with other parts of the website to provide a smooth user experience for conducting in-depth research.
You can also check out the Datasets section on DataCamp to download the various types of datasets. Furthermore, you can start a cloud Jupyter Notebook for free with just one click.
Papers With Code | Methods
The Methods tab is similar to the Browse State-of-the-Art tab. It has categories and subcategories in the form of display cards. The Method tab is for researchers who are looking to learn about specific machine learning methodologies. For example, Word Embedding, Image feature Extractions, and Activation functions.
It consists of 7 categories:
When you click on any method card, you will see the definition, diagram, and Methods section. In the case of the Attention method card, you will see Multi-Head Attention, Scaled Dot-Product Attention, Fixed Factorized Attention, and all of the Attention methods. Each method displays the information on the year of publication and the number of papers using this method.
After clicking the Multi-Head Attention method, you will see a page with a summary of the equation, a downloadable PDF of the paper, and source code. You will also see the Papers, Tasks, Usage Over Time, Components, and Categories sections.
It is a fun way to learn about machine learning methods, as everything is optimized to improve the researcher’s experience.

Papers With Code | Paper
At the top of the research paper page, you will see the title, author's name, date, and abstract. After that, you will see the PDF button, which will take you to the full research paper, and the Abstract button, which will take you to arxiv.org abstract page.
Furthermore, a research paper consists of 5 sections:
Reading a research paper on Papers With Code is easy and interactive. Instead of downloading and reading the entire paper, you can learn almost everything by reading tags, code implementation, tasks, and results.
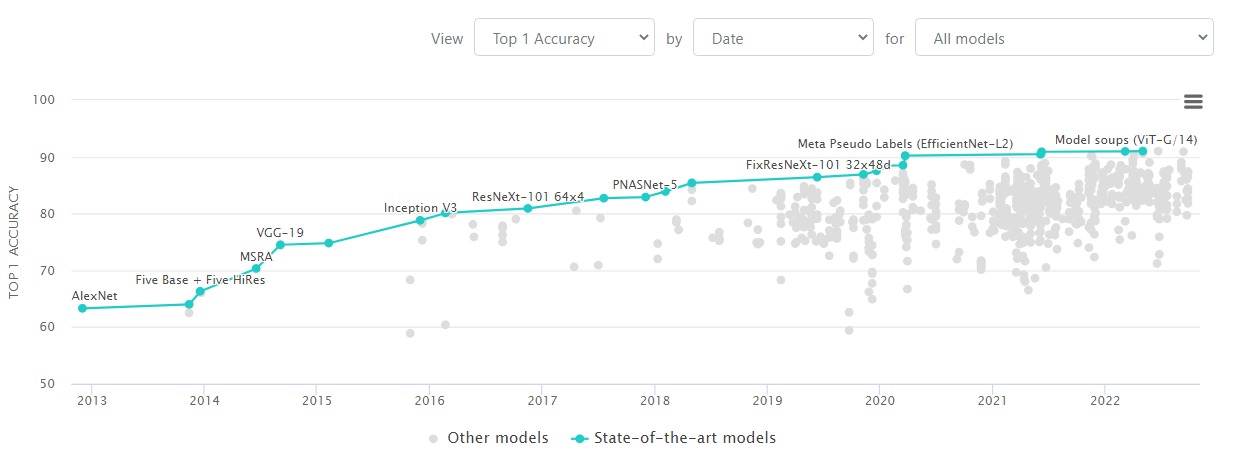
Papers With Code | Image Classification on ImageNet Leaderboard
If you look at the above image, the Teal color lines and dots are repressing the state-of-the-art image classification model on the Imagenet dataset. The gray dots are the low-performing image classification models in a particular period.
The whole ecosystem of Papers with code revolves around a leaderboard and promotes state-of-the-art research on the top. On the front page, you will see trending research based on the stars and popularity. Every tab promotes popular datasets, code implementation, and the best methodologies and research papers.
The whole vision behind leaderboards, trends, and benchmarks is to promote quality of research. In this way, we are pushing the machine learning boundaries every day to achieve state-of-the-art status.
Below, you’ll find some valuable tips on using the Papers With Code platform and optimizing your research project:
The developers are always adding new features to improve the user experience, and if you have something new to share or feature requests, you can reach them on Twitter or Slack.
The Papers With Code platform brings minds from various backgrounds. The website is maintained by Meta AI, but it is run by the community. The openness to contribute introduces inclusivity which is a pivotal factor in the rapid growth of machine learning and artificial intelligence industry.
In this blog, we have learned about the importance of an interactive and interconnective platform called Papers With Code. We have also discovered the website’s key features and tips for optimizing the research.
Paper With Code is great for machine learning research papers, code, datasets, and benchmarks. It is one of the best places to start your final year project. Even if you are new to the field, you can sign up for Machine Learning Scientist with Python or R career track to start your professional journey.
If you’re looking for some machine learning projects to work on, check out our detailed blog with ideas for learners of all levels.
Machine Learning Courses
Course
Course
Course
blog
Joleen Bothma
12 min
blog
Zoumana Keita
14 min
blog
DataCamp Team
2 min
Tutorial
Joanne Xiong
Tutorial
Moez Ali
code-along
Joe Franklin