Lernpfad
KI für Softwareentwicklung
7 Std.
Anthropic has released Claude Opus 4.7, the latest iteration of its flagship model tier. The headline improvement is autonomy: Anthropic is pitching this as the model you can hand your hardest, longest-running coding and agent work to without close supervision.
In this release, we are also learning that there’s a ceiling above Opus 4.7. Anthropic's internal Mythos Preview scores higher on several benchmarks, but it's being held back from broad release while Anthropic tests cyber safeguards. For anyone who isn't an internal Anthropic researcher, Opus 4.7 is the current ceiling.
In this article, we'll walk through what's actually new in Opus 4.7, dig into the benchmark results, and share hands-on tests you can run yourself. You can also see our guides to recently published competitor models, such as Meta's Muse Spark, OpenAI's GPT-5.5, and Google's Gemini 3.1.
Update: On May 28, 2026, Anthropic released the successor model. Read all about it in our Claude Opus 4.8 guide.
Claude Opus 4.7 is Anthropic's latest flagship large language model, sitting at the top of the Claude model family above Sonnet and Haiku. It follows Claude Opus 4.6 and is designed for the most demanding tasks, such as complex agentic workflows and multi-step reasoning tasks that require sustained performance over long sessions.
Compared to Opus 4.6, the 4.7 release focuses on three areas:
Anthropic's internal Mythos Preview, which we mentioned earlier and also have an FAQ about, leads on several benchmarks, but it's not broadly available. Opus 4.7 is essentially a sibling model trained with cybersecurity capabilities deliberately reduced.
Anthropic reported that several capability areas have seen notable improvements in Opus 4.7.
Opus 4.7 follows instructions more closely than earlier models. This is, of course, a helpful feature for any kind of workflow that depends on reliability, but can also have unintended consequences: Anthropic urges users to re-tune their prompts and harnesses, since instructions that earlier models skipped or interpreted loosely now will be taken literally.
The vision for high-resolution was improved to support images with up to 3.75 megapixels, which is more than three times what older models accepted. Computer use agents and data extraction workflows might profit heavily from this increased granularity of detail, as they depend on readability and accuracy, sometimes up to pixel-level.
Opus 4.7 is better at file system-based memory, which refers to a pattern where the model writes notes to files as it works and reads them back on future runs.
Claude Code is the obvious setting for this: a CLAUDE.md file at the root of a project that Claude reads when a session starts, updates as decisions get made, and uses when you go back to work.
"Better" here means better judgment about what's worth writing down and more reliable recall on later turns. Anthropic says this lets new tasks "need less up-front context" — which, if you've ever re-explained your project conventions to a model for the fifth time, like we have, you'll appreciate.
So, the real upshot: If you're using Opus 4.7 for multi-session work, let it keep notes. It'll do a better job of that than Opus 4.6 did, although we did think Opus 4.6 kept pretty good notes.
Anthropic tells us that Claude Opus 4.7 has made significant improvements in these areas.
We created some of our own tests to poke at their claims.
To test Opus 4.7 instruction following, we used the following detailed prompt to stress-test it. It has 12 distinct constraints which we can check at the end.
You are writing a short briefing document for a new employee at a mid-sized accounting firm. Follow every instruction below.
Write a briefing about the firm's approach to client onboarding. The briefing must meet all of the following requirements:
The briefing must be exactly 4 paragraphs long.
-The second paragraph must begin with the word "Historically".
-Each paragraph must contain between 3 and 5 sentences. No paragraph may have fewer than 3 or more than 5.
-Do not use the words "streamline", "leverage", "robust", or "synergy" anywhere in the document.
-Include exactly two direct quotes from fictional senior partners. Attribute each quote to a named partner. Do not include any other quoted material.
-One of the partners quoted must have a surname that starts with the letter M.
-End the document with a single-sentence closing line on its own, separated from the fourth paragraph by a blank line. This closing line does not count toward the 4-paragraph requirement.
-The closing line must be a question.
-Use British English spelling throughout (e.g., "organisation", "colour", "realise").
-Do not use any bullet points, numbered lists, or headings.
-Mention a specific fictional client name exactly once, and italicise it using markdown asterisks.
-The total word count of the briefing, including the closing line, must be between 280 and 320 words. Do not include any preamble, explanation, or commentary before or after the briefing. Output only the briefing itself.And here is the result:
Welcome to Harding & Whitcombe, where client onboarding is treated as the foundation of every successful long-term engagement. Our approach centres on understanding the organisation behind the numbers before any technical work begins, which means the first two weeks are devoted almost entirely to listening. New clients are assigned a dedicated onboarding lead who coordinates introductions across tax, audit, and advisory teams. This structure ensures that every colleague touching the account shares a consistent understanding of the client's priorities and sensitivities.
Historically, the firm operated a more transactional model, with onboarding handled piecemeal by whichever partner had signed the engagement letter. That changed in 2014, when senior leadership recognised that our competitors were winning work on relationships rather than fees alone. As Helena Marchbanks, our managing partner, often reminds new hires, "A client who feels understood in week one rarely questions the invoice in month six." The revised approach has measurably improved retention and referral rates across every service line.
In practical terms, you will be expected to attend the initial discovery meeting for any client you support, even in a purely observational capacity. You should familiarise yourself with the client's sector, recent filings, and any public commentary from their leadership before that first conversation. When we onboarded Thornbury Mills Ltd last spring, the junior associate who had read three years of their annual reports was the one who spotted the inventory anomaly that shaped our entire advisory brief. Preparation of that depth is the standard we expect, not the exception.
You will also notice that we emphasise candour from the outset, particularly around scope and realistic timelines. "We would rather lose a pitch than promise something we cannot deliver," says Rupert Castellane, head of our advisory practice, and that philosophy colours every onboarding conversation. Take the time to ask questions, observe the senior partners in action, and recognise that trust accumulates slowly but pays compounding dividends.
Are you ready to meet your first client?Now is time to score it. I'll share our rubric:
|
# |
Constraint |
How to check |
|
1 |
Exactly 4 paragraphs (plus closing line) |
Count paragraph breaks |
|
2 |
Paragraph 2 starts with "Historically" |
Look at first word |
|
3 |
Every paragraph has 3–5 sentences |
Count sentences per paragraph |
|
4 |
No banned words |
Ctrl+F for each |
|
5 |
Exactly 2 quotes, both attributed, no other quoted material |
Count quotation marks |
|
6 |
One partner's surname starts with M |
Check attributions |
|
7 |
Closing line separated by blank line |
Visual check |
|
8 |
Closing line is a question |
Ends in "?" |
|
9 |
British spelling |
Ctrl+F for "organization", "color", "realize", etc. |
|
10 |
No bullets, numbers, headings |
Visual check |
|
11 |
Fictional client named once, italicised |
Ctrl+F for asterisks |
|
12 |
Word count 280–320 |
Paste into word counter |
We will save you the trouble of going through it. The model scored 11/12.
It had been doing a perfect job, but in the end, it went over the word count very slightly (325 words, and a 320-word limit).
We applied the same test to Claude Sonnet 4.6, and it also got 11/12 of the instructions correctly, with a failure on the same place (word count). But we still consider Opus 4.7 to be an improvement because Sonnet 4.6 went way, way over the limit (400 words).
For our second test, we fed Opus 4.7 a hard-to-read image:
You are analysing a degraded image that may be blurry, low-resolution,
or otherwise difficult to read. Your job is to extract as much accurate
information as possible.
Complete all of the following tasks. Do not include any preamble,
explanation, or commentary. Output only the requested deliverable.
1. Describe what type of document or visualisation this appears to be
(e.g. bar chart, dashboard, table, report page). State your confidence
as High, Medium, or Low.
2. List every number you can make out, however partial. For each one,
state what you believe it refers to and your confidence (High, Medium,
or Low). If a number is ambiguous between two readings (e.g. could be
138 or 188), state both possibilities.
3. List every piece of text you can make out — titles, labels, legends,
footnotes — quoted as precisely as possible. Where a word or character
is unclear, use [?] to mark the uncertain character, e.g. "Re[?]enue".
4. Describe the layout: how many distinct sections or panels are visible,
and what does each appear to contain?
5. State what you believe the overall subject or story of the image is,
in one sentence of no more than 25 words. Flag if your confidence is
Low.
6. List anything you attempted to read but could not make out at all.Alongside these instructions, we fed Opus 4.7 a degraded screenshot of Playfair's 1786 Scotland trade chart, which we pulled from our article on Data Visualization Examples.
We knew we could validate the output because we had a higher resolution version from Wikipedia. Here is the image that Opus 4.7 saw:
Here is Opus 4.7’s reading:
Type: Horizontal bar chart, antique engraving. Confidence: High.
Numbers: X-axis ticks: 10, 20, 30…110, 130, 150, 170, 200, 220, 240, 260, 280, L.300,000 (High, but 130/220 uncertain).
Years "1780" and "1781" in title (High). "Ten Thousand Pounds" per division (High).
Title: "Exports and Imports of SCOTLAND to and from different parts for one Year from Christmas 1780 to Christmas 1781"
Header: "Names of Places"
Places: Jersey &c., Ireland, [?]oland, Isle of Man, Gr[oe]nland, Prussia, Portugal, Holland, Sweden, Guernsey, Germany, Denmark and Norway, Flanders, West Indies, America, Russia, Ireland (duplicate?)
Footnote: "The Upright divisions are Ten Thousand Pounds each. The Black Lines are Exports the Ribbed lines Imports."
Layout: Single panel — title, plot area with ~16 paired bars, right-hand place-name column, footnote below.
Subject: A 1780–81 trade chart showing Scotland's exports and imports by partner. Confidence: High.
Couldn't read: Top-right corner mark; exact bar values; first letter of "[?]oland"; whether bottom "Ireland" is a duplicate.We knew this test might be a tricky one, since the x-axis of Playfair’s chart genuinely does switch counting partway through (every 10 up to 110, then odd tens 130/150/170, then even tens 200/220/240/260/280). But Opus 4.7 read the axis correctly on the first pass even though it was weird.
One thing that still struck us as funny: I know that we like when AI models show their uncertainty, but “[?]oland" really should have been read confidently as “Poland" and "Gr[oe]nland" should have been “Greenland.” Although we didn’t have an official rubric for this one, we can fairly give it 9/10.
Opus 4.7 was evaluated across 14 benchmarks covering coding, reasoning, tool use, computer use, and visual reasoning. The table below shows the full comparison with Opus 4.6, GPT 5.4, Gemini 3.1 Pro, and the not-yet-published Mythos Preview.
On SWE-bench Pro, Opus 4.7 scores 64.3%, ahead of GPT-5.4 at 57.7%, Gemini 3.1 Pro at 54.2%, and Opus 4.6 at 53.4%. On SWE-bench Verified, Opus 4.7 reaches 87.6% against Gemini 3.1 Pro's 80.6% and Opus 4.6's 80.8%. GPT-5.4 has no published score on SWE-bench Verified in this comparison.
SWE-bench tests a model's ability to resolve real GitHub issues in open-source Python repositories. Pro is a harder variant with more complex issues. The 10.9-point gain over Opus 4.6 on SWE-bench Pro is the largest improvement in this release (percentage point-wise) and puts Opus 4.7 clearly ahead of both major competitors on this task.
Only Anthropic's internal Mythos Preview scores 77.8% on SWE-bench Pro and 93.9% on SWE-bench Verified, which shows there is still headroom above Opus 4.7. Still, Mythos is not broadly available, so for production use, Opus 4.7 is the current ceiling.
The results in terms of Terminal-Bench 2.0, which is the go-to benchmark for agentic coding in the terminal, are quite interesting. Opus 4.7 improves slightly against its predecessor (69.4% vs. 65.4%) and overtakes Gemini 3.1 Pro, which scores 68.5%.
That being said, it can't compete with GPT-5.4 (75.1%) in this regard, even though the self-reported caveat on GPT-5.4's score is worth keeping in mind when comparing. Still, it might be disappointing for Anthropic that its newest (released) flagship model doesn't top a benchmark that is central to agentic software development.
Humanity's Last Exam is a collection of graduate-level questions across science, mathematics, and humanities, designed to be difficult for current frontier models. Opus 4.7 leads the no-tools variant, which tests raw reasoning without external retrieval. The with-tools gap in favor of GPT-5.4 (58.7%) is the clearest area where Opus 4.7 (54.7%) does not lead.
Graduate-level reasoning is usually measured in GPQA-Diamond, which is pretty saturated these days: Like all current frontier models, all four compared models achieve a score over 90% and are essentially tied.
A more interesting benchmark result targets biology, one of the fields also tested in the GPQA-Diamond, specifically. While we cannot compare it to the competitor models, the jump between Opus 4.6 (30.9%) and Opus 4.7 (74.0%) is definitely worth noting!
The results in the CharXiv benchmark, which measures visual reasoning about scientific charts and figures, mirror that this was one of the major focus areas in the development of Opus 4.7.
The 13-point no-tools improvement is the largest relative gain in this release. Without competitor scores to compare against, it is hard to say where Opus 4.7 sits in the broader field on this task, but the improvement over Opus 4.6 is substantial.
The support for higher resolution images is likely one of the reasons for the improved visual reasoning. The chart of Screenspot-Pro scores at different resolutions shows the immense accuracy boost Opus 4.7 gets from a higher resolution, especially without tool use (79.5% vs. 69.0%).
MCP-Atlas tests performance across complex, multi-tool workflows. Opus 4.7 scores 77.3% here, which is the highest of any model in the comparison. The only model that tops Opus 4.7's MCP-Atlas score very slightly is Muse Spark, which is reported at 78.3%.
OSWorld tests a model's ability to complete tasks by controlling a computer interface, clicking, typing, and navigating applications. Opus 4.7 scores 78.0%, up from 72.7% in Opus 4.6. GPT-5.4 scores 75.0%, and Gemini 3.1 Pro has no published score on this benchmark. Mythos Preview scores 79.6%, just slightly above Opus 4.7.
This is definitely one area where Opus 4.7 excels: It leads both MCP-Atlas and OSWorld-Verified by a meaningful margin over the competition flagships from Google and OpenAI, which is a strong result for anyone building production agent systems that rely on tool orchestration and computer use agents.
The model's financial analysis skills deserve an honorable mention: Opus 4.7 tops the Finance Agent v1.1 leaderboard (64.4%), being significantly ahead of both GPT-5.4 (61.5%) and Gemini 3.1 Pro (59.7%).
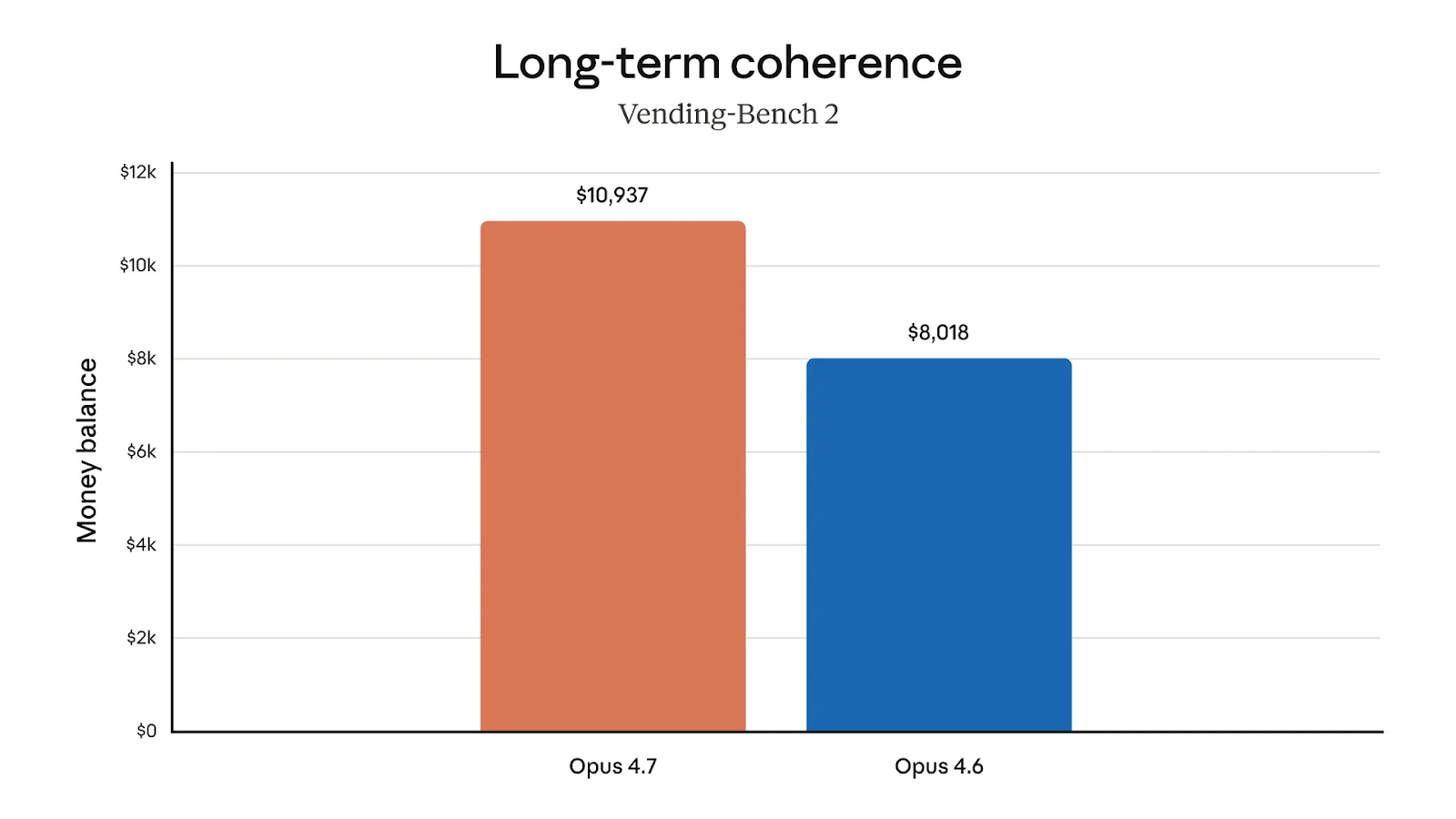
In the more practical-oriented Vending-Bench 2, we can see that Opus 4.7 is better with money, too. On average, the model ended up with an amount of $10,937, compared to $8,018 with Opus 4.6.
Anthropic is not making us wait. Opus 4.7 is now available
In all Claude products
The Claude API (claude-opus-4-7)
Vertex AI, and
Microsoft Foundry
One always worries - especially now - about inflation. But thankfully, pricing is the same as Opus 4.6. That’s $5 per million input tokens and $25 per million output tokens. (There was also no price increase between Opus 4.6 and Opus 4.7.)
As a general reminder, if you are using Opus in Claude.ai: Every message you send includes the whole conversation so far (your new question + all earlier back-and-forth) plus the model's reply. All of that gets measured in tokens. Your plan, whatever it is, has a token budget that refills on a rolling window.
Different models charge different rates against that budget. Opus is the priciest because it's the most powerful. A rough published ratio: Opus costs about 5× what Sonnet does per token.

Anthropic shipped several updates alongside the model itself that are worth knowing, at least if you use Claude Code or build on the API.
A new xhigh ("extra high") effort level now sits between high and max. This gives you another option when choosing between reasoning depth and latency. In Claude Code, the default effort level has been raised to xhigh across all plans, and Anthropic recommends starting with high or xhigh when testing Opus 4.7 on coding and agentic tasks.
Claude Code gained a new /ultrareview slash command, which runs a dedicated review pass over your changes and flags bugs or design issues that a careful human reviewer would catch. Pro and Max users get three free ultrareviews to try it out.
Max users now get access to auto mode, a permissions setting where Claude makes decisions on your behalf. It's a middle ground between approving every step and skipping permissions entirely.
Task budgets are now in public beta on the Claude API. These let developers cap Claude's token spend across a run, which is especially useful for longer agent workflows where you want the model to pace itself rather than burn through its budget.
We looked closely at the benchmark results, and those results contained in them a comparison to other models. At a high level, let's compare Opus 4.7 with GPT-5.4 directly.
The basic takeaway is that Opus 4.7 optimizes for long-horizon autonomy. GPT-5.4 is a unified general-purpose model with broader tool support and cheaper short-context pricing.
| Claude Opus 4.7 | GPT-5.4 | |
|---|---|---|
| Best at | Long coding runs, desktop computer use, dense vision |
Browser research, short-context tasks, mid-response steering |
| SWE-bench Pro | 64.3% | 57.7% |
| BrowseComp | 79.3% | 89.3% |
| Pricing | Flat rate across 1M context | Cheaper under 272K, full session reprices above |
| Context window | ~1M tokens | ~1M tokens |
For the full comparison to OpenAI's successor model, GPT-5.5, see our blog post, Claude Opus 4.7 vs. GPT-5.5.
Some users are reporting that their pipelines are acting up because Opus 4.7 is following instructions more literally than before. Anthropic warned about the need to re-tune prompts.
Other users were concerned about token usage. As part of the release, Anthropic raised rate limits for all users to account for higher token usage, but it's not totally clear if it's a true offset.
Claude Opus 4.7 is the most capable model most people can actually use right now. The improvements all point in the same direction: longer-running, less supervised agent work, with stronger coding, sharper vision, and better cross-session memory backing that up.
What makes this release interesting is the Mythos framing. Opus 4.7 is a cyber-constrained test vehicle on the way to a broader Mythos-class release, which means there's now a clear ceiling above it you can't access — but also that the safeguards shipping with 4.7 are a preview of how Anthropic plans to handle frontier releases going forward.
Learn with DataCamp
Lernpfad
Kurs
Kurs
Blog
Matt Crabtree
10 Min.
Blog
Josef Waples
10 Min.
Blog
Tom Farnschläder
11 Min.
Blog
Josef Waples
8 Min.
Blog
Derrick Mwiti
10 Min.
Blog
Derrick Mwiti
9 Min.