
Course
Introduction to MongoDB in Python
3 hr
24K
If you’re planning to start a new digital application, you will likely need to collect and store some data. Where and how to store that data is one of the most important decisions you will have to make, for the whole software will rely on that data to work.
Traditionally, data has been stored in tables with rows and columns connected through certain relationships (i.e., common columns). Databases that store relational data are called relational databases, or SQL databases, for most, if not all, rely on SQL for all kinds of operations.
However, in recent decades, new database management systems have evolved to address the rapid increase in the volume and variety of data that is created every second. The so-called NoSQL databases (Not only SQL) propose new schemas and strategies to effectively collect data based on specific use cases, while still relying to some extent on SQL.
In this article, we will analyze two popular database management systems: PostgreSQL vs MongoDB. The former is one of the most popular SQL databases, whereas the latter is the most famous NoSQL database.
We will cover the key features and strengths of both databases, their most compelling use cases, and good things to remember in case you’re considering migrating your data to one of these databases.
If you’re looking to get hands-on and try out each method, be sure to check out our courses, Creating PostgreSQL Databases and Introduction to MongoDB in Python.
Choosing the right database is crucial for any digital application. PostgreSQL, a powerful SQL-based relational database, excels in structured data scenarios requiring consistency, complex joins, and ACID transactions. MongoDB, a flexible NoSQL document database using BSON, is ideal for handling dynamic, unstructured data, offering greater scalability through horizontal sharding. Selecting between PostgreSQL and MongoDB ultimately depends on your project's data structure, scalability needs, and consistency requirements.
Let’s analyze the main differences between PostgreSQL and MongoDB in terms of data model architecture.
Relational database management systems, like PostgreSQL, organize data into tables, where each table consists of rows and columns. These tables can be linked through keys, allowing for complex data relationships through SQL joins and efficient querying.
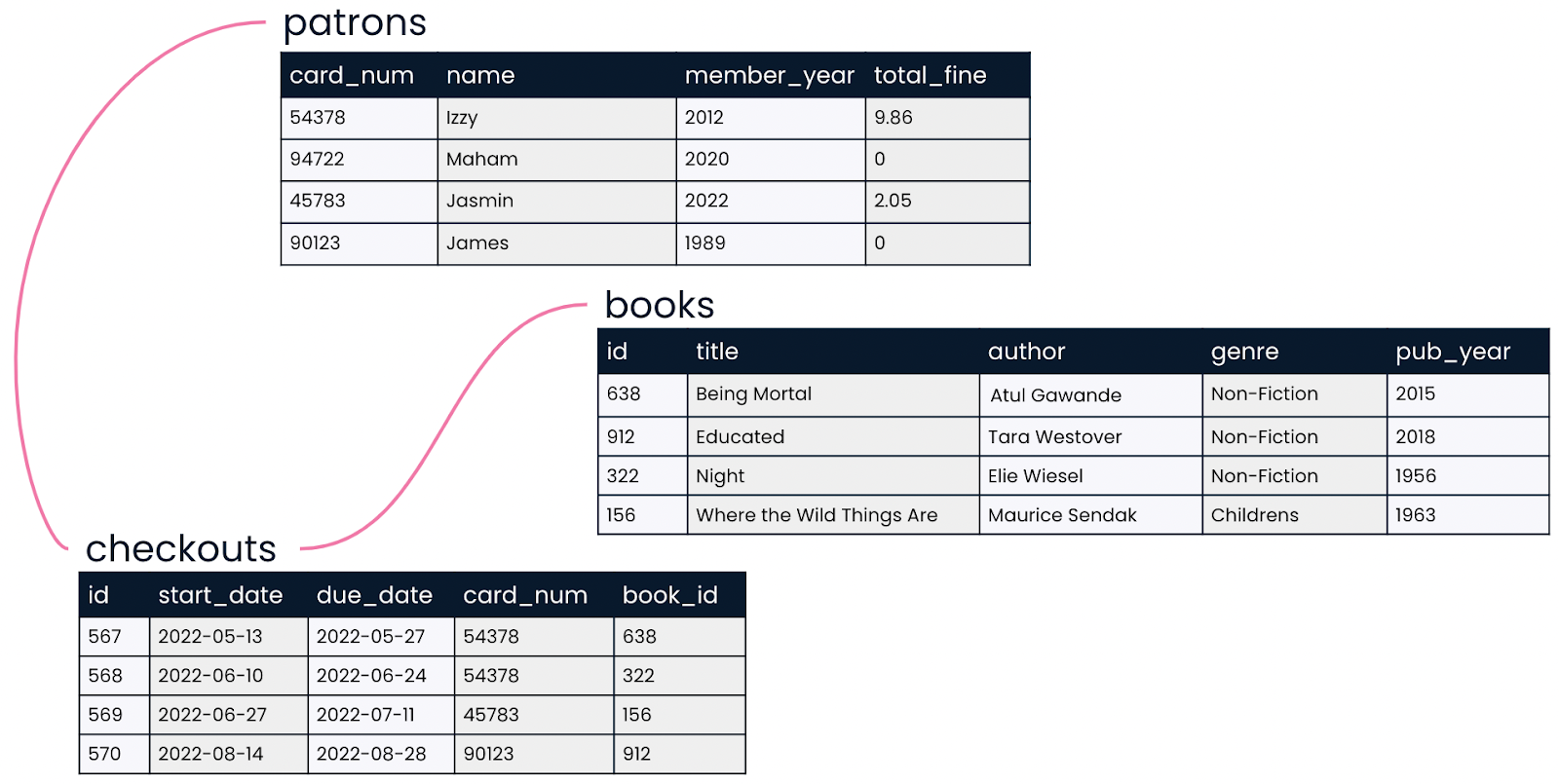
Relational database. Source: DataCamp
Thanks to its simplicity, unique efficiency, and strong consistency, relational databases have been extremely successful and widely adopted in the last decades.
However, they might not be the best option when you work with unstructured data that doesn’t fit neatly into a tabular format (e.g., social media posts, sensor data) or when scalability is a must; that is, when your application needs to scale horizontally across numerous servers.
Here is where NoSQL databases join the scene. Unlike their relational counterparts, NoSQL databases can handle unstructured or semi-structured data without the constraints of a fixed schema.
Particularly, MongoDB is a so-called document database, a type of NoSQL database that stores data in collections of JSON-like documents using a format called BSON (Binary JSON). In simple terms, documents are similar to JSON key-value objects, with additional capabilities to store and manipulate data provided by BSON.
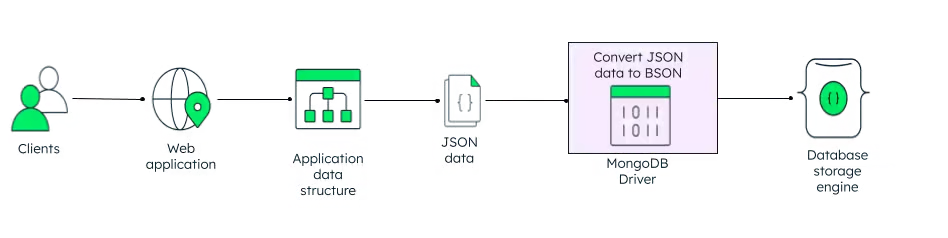
How MongoDB stores data as BSON. Source: DataCamp
The flexible nature of BSON enables the creation of dynamic document schemas whose structure and data can vary on the fly. We will see more on this in the next subsection.
Relational databases like PostgreSQL provide robust schemas that are hard to alter once you create your tables. This is a great feature if the data you’re working with has a tabular nature and always arrives in your application in the same format. However, if you deal with semi-structured or unstructured data whose content can vary from one piece to another, such as social media posts or sensor data, you may need some level of flexibility to digest your data.
In contrast with PostgreSQL, MongoDB comes with so-called schema-less designs, which offer exceptional flexibility for handling diverse and evolving data. MongoDB’s schema-less design organizes data into documents and collections:
Unlike traditional relational databases, where adding a new field requires altering the entire table structure, MongoDB allows documents within the same collection to have completely different fields and structures. This eliminates the need for rigid schemas and makes it easier to store varied data without forcing uniformity.
No matter the database you’re using, whether PostgreSQL or MongoDB, you will need to learn the language to communicate and manage your databases. In PostgreSQL, this is SQL, an extremely popular, standardized, and easy-to-use programming language. You can get started with SQL in our Introduction to SQL course.
By contrast, MongoDB primarily relies on its own MongoDB Query Language (MQL) for interacting with the database. However, it’s also possible to use other popular programming languages, such as Python, C, and Java, to connect and interact with MongoDB databases.
Let’s analyze the main differences between SQL and MQL.
One of the greatest advantages of PostgreSQL compared to MongoDB is the use of SQL. SQL (stands for “Structured Query Language) is an essential language for building and maintaining relational databases.
It’s a simple, domain-specific programming language that is used by nearly all relational database systems, such as MySQL, SQL Server, SQLite, and, of course, PostgreSQL.
SQL is extremely powerful, allowing you to perform all kinds of data operations, from data retrieval and aggregation to data cleaning and joining operations. However, when it comes to PostgreSQL, the possibilities are even greater, for PostgreSQL comes with a set of advanced capabilities for complex analysis, including:
By contrast, although MongoDB doesn’t rely on SQL, it has powerful querying, indexing, and aggregation capabilities, as well as other functions to insert, update, or delete information in document databases. Hence, if you are familiar with JSON or Python dictionaries, it won’t take you much to become familiar with MQL syntax.
MQL is specifically designed to handle the dynamic nature of documents. As a result, it’s a much more flexible language compared to SQL. Also, as documents can embed other documents inside, in MongoDB, there is no need to use complex and inefficient join operations, which is often the case in relational databases.
Indexes are database objects that improve the speed of data retrieval operations. They serve as pointers to quickly locate rows in a table, enhancing the performance of queries.
PostgreSQL comes with strong indexing capabilities, supporting multiple index types, including:
MongoDB also supports indexing to find documents in collections without having to scan all the documents in a collection. However, its capabilities are limited, lacking the variety and sophistication of indexing available in relational databases like PostgreSQL. This includes:
Using indexes in your SQL and NoSQL databases is key to increasing performance and reducing query times, especially on large datasets.
However, remember that adding an index can also have a negative performance impact for write operations. For tables or collections with a high write-to-read ratio, indexes are expensive because each insert must also update any indexes.
MongoDB and PostgreSQL are great database tools, but there is no point in choosing one over the other based on their properties. Instead, you should always make your choice considering the particularities of your use case. Having this in mind, let’s analyze the differences in performance and scalability of MongoDB and PostgreSQL.
Like other popular relational database systems, PostgreSQL ensures high levels of data integrity and quality through its robust typing system and support for ACID (Atomicity, Consistency, Isolation, Durability) transactions.
ACID transactions are a set of properties that guarantee the reliable processing of database transactions. They ensure that data remains accurate and secure even in the face of errors, crashes, or concurrent access. These properties are vital for maintaining data quality in any project.
While ACID transactions have long been the gold standard for ensuring data integrity in relational databases, NoSQL databases like MongoDB often prioritize flexibility and scalability over strict transactional consistency. This results in relaxing some of the ACID properties found in relational databases.
For example, some MongoDB databases prioritize eventual consistency over immediate consistency, meaning that changes might not be reflected across all nodes instantly. The trade-off in terms of consistency, availability, and performance allows for better performance and scalability but requires careful consideration when designing applications that rely on strict data consistency.
Scaling involves the use of several techniques to address increases in data volume and traffic. In simple terms, we can do this through vertical scaling and horizontal scaling. The former involves improving and adding resources to the same server to handle increased load. The latter is achieved by adding more servers or nodes to a distributed system, which then helps increase capacity.
PostgreSQL primarily relies on vertical scaling to increase capacity. However, unlike other popular SQL databases, PostgreSQL also permits horizontal scaling through partitioning, yet it requires complex configurations. You can learn all the technicalities of partitioning in PostgreSQL in our Improving Query Performance in PostgreSQL Course.
By contrast, in NoSQL systems like MongoDB, the go-to strategy to handle growing data traffic and volume is horizontal scaling. MongoDB is designed to leverage sharding, a technique that involves dividing a database into smaller, more manageable pieces called "shards” and distributing them across multiple servers, enabling the system to handle large datasets and high volumes of traffic.
Check out our Sharding vs Partitioning article to know everything about these popular scaling techniques.
Now that we know the key features and strengths of PostgreSQL and MongoDB, it’s time to analyze the scenarios where they are more useful.
PostgreSQL is a great choice when your project will require:
To give some compelling examples, PostgreSQL is a sound idea in:
MongoDB works best in cases when it's useful to have flexible data structures that can dynamically adapt to new information and schemas, when scalability and performance are important, and for unstructured data. MongoDB’s schema-less design, paired with horizontal scaling, makes it great for use cases like:
There may be use cases where you need to combine the strengths of MongoDB and PostgreSQL to advance a comprehensive solution for diverse data requirements. Creating hybrid architectures combining SQL and NoSQL databases is possible, and a great idea if you need to combine strong consistency on your transactions with some degree of flexibility.
For example, you can use MongoDB for fast writes in real-time analytics while using PostgreSQL for complex relational operations and storing structured data. However, there isn’t currently such a way to “merge” the functionalities of both databases. You will be just using two different databases at the same time, which will increase the complexity of your system, requiring careful analysis before implementing it.
If you are planning to migrate data from MongoDB to PostgreSQL or the other way round, you will have to consider several elements:
If you’re migrating from MongoDB to PostgreSQL, before migrating the data, you will have to create a table or multiple tables with a predefined schema, that is, a list of columns with their assigned data types and potential constraints. If you want to move your data into Mongo, you will need to define how the data will be incorporated into the documents. Despite the flexible nature of documents, some data modeling will be essential to place the existing data.
The data you want to export may not have the desired format. If that’s the case, before migrating, you will have to establish some sort of data pipeline to transform the data into the right format before inserting it into the PostgreSQL or MongoDB database.
There are several ways to do a migration process. You can do it manually for basic export/import steps, but it can be a time-consuming, complex, and prone-to-error process, especially if the database you want to migrate contains a lot of data. That's why choosing an ELT to get the job done may be a better solution. There are many available solutions out there, both from migrating from PostgreSQL to Mondo and vice versa.
Considering techniques to increase performance during migration is crucial, especially in complex migration processes. Again, depending on the source and the destination, PostgreSQL and MongoDB offer specific techniques and strategies to speed up the process, including connection pooling, partitioning, shard key selection, and covered queries.
Protecting your database deployment is critical to ensuring data integrity, availability, and compliance. Both MongoDB and PostgreSQL offer diverse methods to secure your databases. In this section, we cover some of the most common techniques.
PostgreSQL comes with a range of authentication methods, which can be managed effectively through roles. Roles are entities that can own database objects and have database privileges. Roles can be used for authentication purposes, permission management, and defining user access levels. In PostgreSQL, a role can function as a user or as a group of users.
You can also create roles in MongoDB to prevent unauthorized access. The role-based control follows the principle of least privilege to minimize security risks. MongoDB comes with several authentication mechanisms, with Salted Challenge Response Authentication Mechanism (SCRAM) being the default mechanism for secure password-based authentication.
MongoDB offers a good number of encryption practices to secure your data, including:
As for PostgreSQL, it also offers encryption at several levels and provides flexibility in protecting data from disclosure due to database server theft, unscrupulous administrators, and insecure networks. Some options include:
Both MongoDB and PostgreSQL are highly popular tools, with growing communities of users and thriving ecosystems. Let’s have a look at them.
PostgreSQL extensions in PostgreSQL are add-on modules that expand the capabilities of the database. They are like packages in Python or R. Over the last years, a rich ecosystem of extensions has sprung up to boost the potential of PostgreSQL in all kinds of scenarios, disciplines, and use cases. Most of them can be found in the PostgreSQL Extension Network.
By contrast, MongoDB comes with a more limited set of extensions and is mostly restricted to enabling the use of MongoDB with other technologies and frameworks, such as IDEs like Visual Studio Code, and cloud systems like Google Cloud. However, other third-party packages may be available for the different programming languages you normally use to manage MongoDB.
Both PostgreSQL and MongoDB are living golden times, as depicted in the following image with the trends of database engines based on data from DB-Engines.
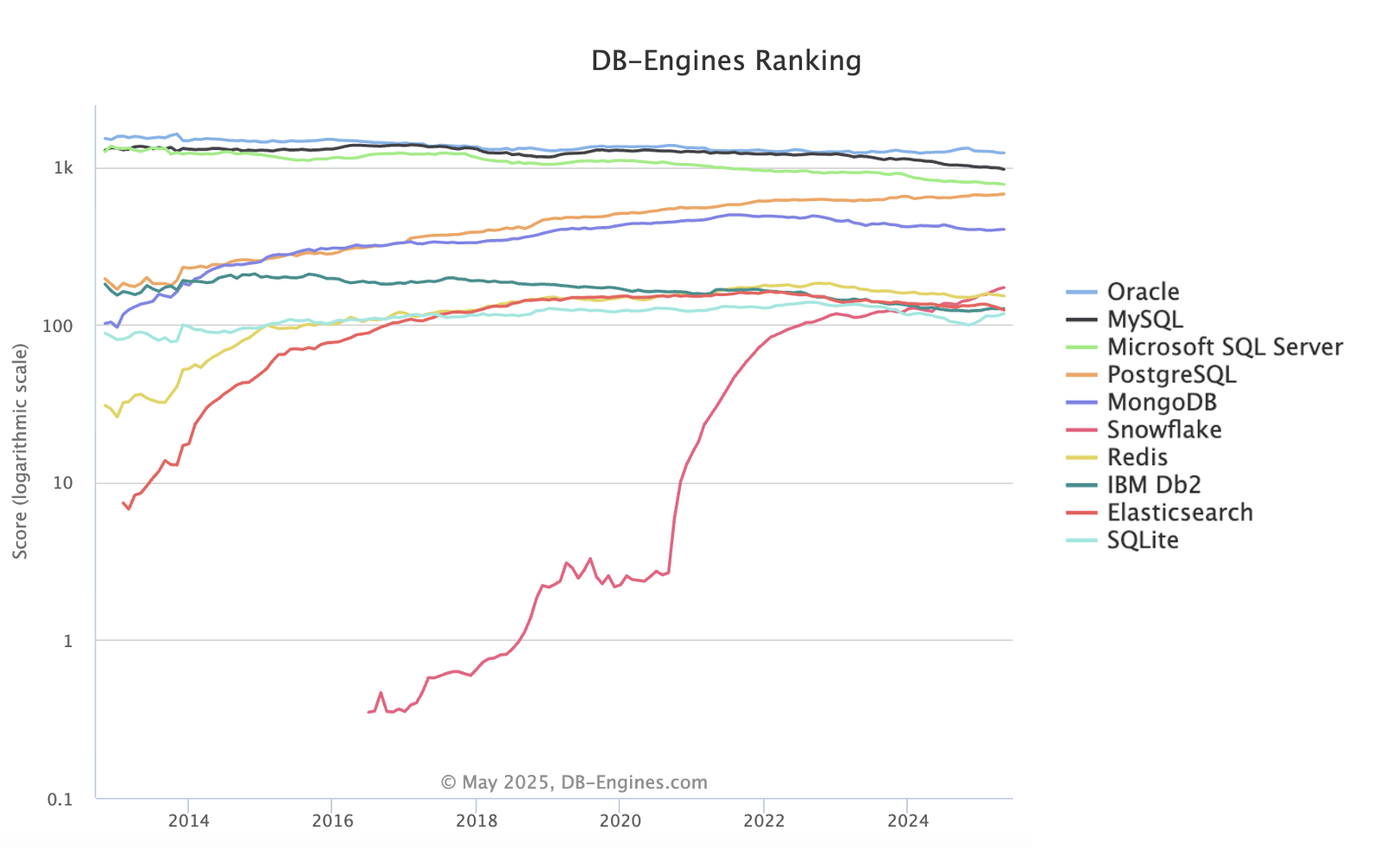
Source: db-engines
While relational database management systems are still dominant (including PostgreSQL, which ranks 4th), the graph also reveals a notable shift in recent years, with NoSQL databases like MongoDB and Redis experiencing significant growth. This upward trajectory reflects the increasing adoption of these flexible and scalable solutions for managing unstructured data and accommodating high-traffic applications.
Here is a great table summarizing the differences between MongoDB databases and PostgreSQL:
|
Feature |
MongoDB |
PostgreSQL |
|
Data Structure |
Stores data as documents (e.g., JSON, BSON), allowing for flexible, hierarchical structures. |
Stores data in tables with rows and columns, following a predefined schema. |
|
Schema Flexibility |
Schema-less: Documents can have varying structures, allowing different fields and data types. |
Fixed schema: Requires a predefined schema with specific columns and data types. |
|
Query Language |
Uses MongoDB Query Language (MQL) or similar, which is object-based and more flexible. |
Uses SQL (Structured Query Language) for querying structured data. |
|
Joins |
Avoids joins by embedding related data inside documents (denormalization). |
Supports complex joins across tables (normalization). |
|
Performance |
Faster reads and writes for unstructured or semi-structured data. Avoids overhead from joins. |
Strong performance for structured data, but joins can slow down queries. |
|
Scalability |
Horizontally scalable: Can distribute data across multiple servers using sharding. |
Typically vertically scalable: Relies on more powerful hardware, though some support horizontal scaling (e.g., with partitions). |
|
Transaction Support |
Supports multi-document ACID transactions (from MongoDB 4.0 and above), but was initially designed for non-transactional operations. |
Full support for ACID-compliant transactions, providing strong consistency and reliability. |
|
Use Cases |
Best for unstructured or semi-structured data like user profiles, logs, catalogs, and flexible data structures. |
Ideal for structured data with clear relationships, such as financial records or enterprise resource planning (ERP). |
|
Data Relationships |
Supports embedded data (denormalization), which makes it easy to retrieve related information from a single query. |
Relational databases rely on foreign keys to establish relationships across tables (normalization). |
|
Indexing |
Supports indexing but lacks the variety and sophistication of indexing available in relational databases. |
Strong indexing capabilities, supporting multiple index types (e.g., B-tree, hash) for better performance optimization. |
|
Consistency |
Provides eventual consistency in distributed setups but also offers strong consistency when needed (via ACID transactions). |
Ensures strong consistency in most cases due to ACID transactions and relational integrity. |
|
Scaling Data Volume |
Easily scales to accommodate large amounts of data by adding servers (sharding). |
Can scale vertically, but horizontal scaling requires more complex configuration (e.g., partitioning). |
|
Data Integrity |
Data integrity is managed within each document, but managing relationships between documents can be more challenging. |
Strong built-in support for data integrity through primary and foreign keys, as well as constraints like UNIQUE and NOT NULL. |
|
Developer Friendliness |
Developer-friendly: Flexible data modeling, works well with modern applications (e.g., JSON, REST APIs). |
Rigid data modeling but well-understood by developers familiar with SQL and structured data. |
MongoDB and PostgreSQL are two of the most popular databases out there. They are great examples of SQL and NoSQL databases, and by comparing them, we can shed some light on the differences, strengths, and varying use cases where these databases may be useful.
There’s a lot to learn about SQL and NoSQL databases. At DataCamp, we want to help you with the most comprehensive and updated courses and tutorials. Check out some of our dedicated database material here:
Top DataCamp Courses
Course
Course
Course
blog
Jake Roach
8 min
blog
Abiodun Eesuola
8 min
blog
Moez Ali
9 min
blog
Karen Zhang
15 min
blog
Mona Khalil
5 min
Tutorial
Sayak Paul
