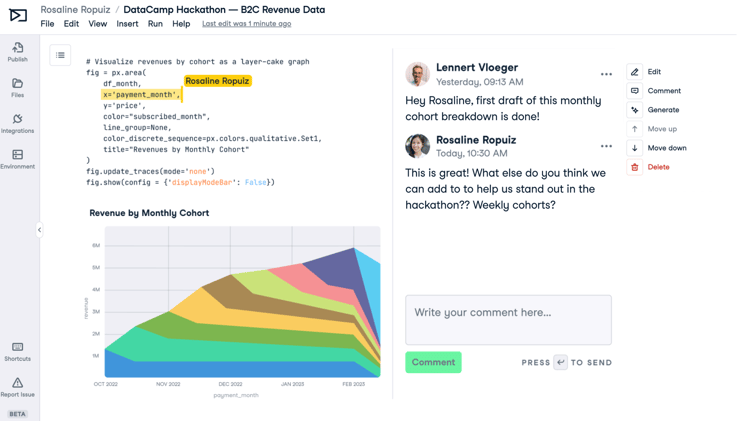
Why we’re building a collaboration product for data professionals and data-fluent teams
When we started DataCamp, we wanted to make it easy, enjoyable, and affordable for everyone to learn data science online. Today, we’ve reached over 7 million learners and actively helped increase the data fluency of more than 1,600 organizations. Over 150,000 subscribers have access to DataCamp today and even more for free through DataCamp Donates and DataCamp for the Classroom. However, almost all of them face significant struggles as they start actually doing data work.
The struggle of data professionals and data teams—and why it matters
Just like learning data science, doing data science work should be easy, enjoyable, and collaborative. Even as the number of data professionals has exploded, there are almost no tools that are easy to use, easy to scale, and that take into account the reality that different people prefer different technologies and integrated development environments, or IDEs.
As a consequence, data scientists today are not as productive as they could be. Let’s face it, many of us data scientists waste a lot of time doing infrastructure and engineering work, whether that’s setting up a machine, finding and accessing the right data, or deploying dashboards and reports. We hear these struggles from our learners and our customers, and we’ve faced many of these struggles ourselves at DataCamp.
Moreover, data scientists don’t work alone. Doing data science work in a team setting should not be as painful as it is today. Most tools used by data scientists lack even the most basic collaboration features. Shockingly, collaboration among data teams often happens by sharing code and data through email, Slack, or other messaging tools. Version control is done through tools that are tailored to the workflow of software engineers and are not intuitive for data scientists—and don’t get me started on the lack of quality control on most data teams. Knowing which analysis, dashboard, or report is still accurate is critical for a team. The struggles of data professionals are real and typically start on day one of joining a team.
Organizations also lose as they lack a central place where all insights are gathered and where data professionals can learn from each other. Some insights live in notebooks, some in PDF reports, yet others in proprietary analytics tools like Looker and Metabase, and the list goes on. This leads to insights getting lost and efforts being duplicated, and creates frustration with business users and leadership interacting with data professionals.
This lack of proper tooling stands in the way of truly productive data professionals and data fluent organizations. While it is true that there’s been a lot of innovation for more BI-style users, this is often not true for data professionals who want to dig deeper and use the power of Python and R to generate their insights.
What DataCamp is working toward
We want to enable anyone, from anywhere and on any device, to access relevant data online, and to create visualizations, reports, and dashboards from their favorite tool or IDE and share it with fellow data professionals. We want to enable teams to seamlessly collaborate online in real time as well as asynchronously. We want teams to have basic version and quality control automatically built in. The end result should be a centralized insights layer for organizations of any size.
In other words, we want to make it as easy to do data science on your own (or your company's) data as it is to take a DataCamp course.
How we’ll get there
Rome wasn’t built in a day. We’re currently building this product and are planning a phased rollout in the next 12 to 18 months.
First, we want to make it super easy for our learners to take their learnings from DataCamp—be it in the form of projects or courses—to a popular IDE like Jupyter. Working with the tools that are already widely used in industry and academia is a key step toward applying acquired skills in a realistic environment. In addition, users will be able to publish and share the work they’re doing in a workspace.
Next, we’ll make it seamless to connect your data and upload datasets, enabling users to start using DataCamp for day-to-day data science work. Furthermore, when users invite collaborators to review or edit their work, code and environment will be linked and self-contained, so the concerns around using the right package versions across projects and between different users becomes a thing of the past.
We’ll also focus on vastly improving real-time and async collaboration for data teams. Almost any team product today allows for real-time collaboration, commenting, and tagging. There’s no reason data teams should be deprived of that functionality, but they often are today.
Finally, as the product matures, we’ll continue to add features for organizations, leveraging the extensive user management architecture that we’ve already built for our enterprise learning platform. As an example, admins will only have to specify a database connection once, and manage who has access to which data. On the receiving end, data scientists will have the right data connections in place when they start their analyses.
Improving data fluency and democratizing data science is the core of DataCamp’s mission. This product is a key step toward achieving that goal, and why we also believe the basic version of this product should be free forever.
If you’re interested in changing the way data teams collaborate, email us at rocketship@datacamp.com. You can also reach out directly to Filip Schouwenaars, who’s taking the lead on building this new product, or our CTO, Dieter De Mesmaeker. We’re always looking for talented engineers to join our team. Apply now!