Cours
Introduction à la Data Science en Python
4 h
498.3K
La récente révolution de l'IA a poursuivi la croissance significative des volumes de données observée au cours des années précédentes. Les données nous permettent d'être mieux informés et peuvent contribuer à améliorer les processus décisionnels des entreprises, des gouvernements et des citoyens. Cependant, pour transformer les données en informations pertinentes, nous avons besoin de professionnels compétents dans la gestion, l'analyse et l'extraction d'informations. C'est ici que les compétences en science des données prennent toute leur importance.
Le marché mondial du big data devrait atteindre 273,4 milliards de dollars d'ici 2026, soit plus du double de sa taille prévue en 2018. En d'autres termes : Le big data représente un secteur d'activité considérable. Malgré une demande croissante, les entreprises du monde entier sont confrontées à une pénurie de professionnels qualifiés dans le domaine des données.
L'une des raisons expliquant cette pénurie réside dans les difficultés rencontrées par les entreprises pour trouver des scientifiques des données possédant les compétences requises. Cela n'est pas surprenant, car les scientifiques des données sont des professionnels dotés de compétences variées que l'on ne trouve généralement pas chez une seule et même personne. C'est pourquoi les scientifiques des données sont souvent qualifiés de « licornes ».
Quelles sont les compétences les plus importantes pour un data scientist ? Il s'agit d'une question importante que se posent les aspirants data scientists et les professionnels qui souhaitent améliorer leurs perspectives de carrière.
Les scientifiques des données sont des professionnels polyvalents et aux multiples facettes. Compte tenu de la nature de leurs responsabilités, ils doivent posséder un ensemble équilibré de compétences techniques et de leadership. Cet article traite des compétences les plus recherchées dans le secteur de la science des données. Nous vous fournirons également des ressources qui vous aideront à développer les compétences nécessaires pour devenir data scientist.
Ci-dessous, nous avons répertorié certaines des compétences techniques essentielles dont les data scientists ont besoin pour réussir dans ce secteur.
Python est l'un des langages de programmation les plus populaires, occupant la première place dans plusieurs indices de popularité, tels que l'indice TIOBE et l'indice PYPL.
L'une des raisons de son adoption à l'échelle mondiale réside dans sa pertinence pour les tâches d'analyse de données. Bien qu'il n'ait pas été initialement conçu pour la science des données, Python a évolué au fil des ans pour devenir le leader incontesté du secteur.
Python est un pilier central dans les piles technologiques de nombreuses entreprises. Grâce à des bibliothèques puissantes et prêtes à l'emploi, telles que pandas, NumPy et matplotlib, vous pouvez facilement effectuer toutes sortes d'opérations sur les données, de la manipulation et le nettoyage des données à l'analyse statistique et la visualisation des données.
Il convient également de mentionner la prédominance de Python dans les sous-domaines avancés de la science des données, notamment l'apprentissage automatique et l'apprentissage profond. Ici, des packages et des frameworks populaires tels que scikit-learn, Keras et TensorFlow fournissent les outils nécessaires pour créer et entraîner des algorithmes.
Grâce à sa syntaxe intuitive qui imite la langue anglaise, Python est un excellent langage à apprendre pour les programmeurs débutants.
Développez vos compétences en Python
Vous pouvez débuter votre apprentissage du Python grâce à nos cours en ligne, Introduction à Python ou Introduction à la science des données avec Python.
Si Python est considéré comme le leader dans le domaine de la science des données, R est souvent perçu comme un outil complémentaire. Développé en 1992, R est un langage de programmation open source spécialement conçu pour l'analyse statistique et informatique.
Largement utilisé dans la recherche scientifique et le milieu universitaire, ainsi que dans des secteurs tels que la finance et les affaires, R vous permet d'effectuer de nombreux types d'analyses de données. Cela est principalement dû à la vaste collection de paquets pour la science des données disponibles dans le Comprehensive R Archive Network (CRAN).
Certaines des bibliothèques les plus populaires de R, telles que tidyr et ggplot2, font partie de tidyverse, une collection réputée d'outils de science des données dans R.
La demande en programmeurs R est en forte croissance. Cependant, comparé aux utilisateurs de Python, le nombre de scientifiques des données possédant des compétences en R est plus restreint. Par conséquent, les programmeurs R comptent parmi les professionnels les mieux rémunérés dans les domaines de l'informatique et de la science des données.
Développez vos compétences en R
Si vous débutez dans le domaine de la science des données, vous devrez tôt ou tard apprendre à coder. Nous vous recommandons de commencer par choisir R ou Python. Découvrez les bases dans notre cours Introduction à R, puis passez au niveau supérieur avec le cours R intermédiaire. Ensuite, découvrez comment un ensemble dédié d'outils R peut vous aider à organiser et à visualiser vos données dans Introduction à Tidyverse.
Il n'est pas nécessaire d'avoir des connaissances mathématiques pour commencer à étudier la science des données, mais il est important de se familiariser avec certains concepts mathématiques et statistiques pour progresser dans sa carrière.
Il est essentiel de bien maîtriser les statistiques pour choisir et appliquer les différentes techniques disponibles en matière de données, construire des modèles de données robustes et bien comprendre les données que vous traitez.
En plus des notions mathématiques fondamentales enseignées dans le cadre d'un programme scolaire classique, il est recommandé de consacrer du temps à l'apprentissage des bases du calcul, des probabilités, des statistiques et de l'algèbre linéaire. La théorie bayésienne constitue également un atout si vous travaillez dans le domaine de l'intelligence artificielle et des techniques d'apprentissage automatique.
Développez vos compétences en statistiques et en mathématiques
Commencez par suivre un cours d'introduction aux statistiques sans code avant de vous attaquer à des concepts plus avancés. DataCamp propose plus de 70 cours axés sur les statistiques et les probabilités, vous permettant ainsi de choisir votre technologie préférée et de perfectionner vos techniques statistiques.
Bien qu'il existe depuis les années 60, le langage SQL (Structured Query Language) reste une compétence indispensable pour les scientifiques des données. SQL est l'outil standard dans l'industrie pour gérer et communiquer avec les bases de données relationnelles.
Les bases de données relationnelles nous permettent de stocker des données structurées dans des tableaux qui sont reliés entre eux par certaines colonnes communes. Une grande partie des données dans le monde, en particulier les données propres aux entreprises, est stockée dans des bases de données relationnelles. Par conséquent, SQL est une compétence indispensable pour tout data scientist. Heureusement, comparé à Python et R, SQL est un langage simple et relativement facile à apprendre.
Développez vos compétences en SQL
Développez vos compétences en matière de requêtes de bases de données relationnelles grâce à l'introduction au langage SQL ou apprenez à créer votre propre base de données dans le cours Introduction aux bases de données relationnelles en SQL.
Si SQL est l'outil idéal pour traiter les données structurées stockées dans des tableaux avec des lignes et des colonnes, les choses peuvent se compliquer lorsqu'il s'agit de données non structurées. La majorité des données générées aujourd'hui (par exemple, les fichiers audio, vidéo, les images satellites, les journaux de serveurs Web) sont non structurées, ce qui rend leur stockage et leur traitement difficiles selon le modèle relationnel traditionnel.
Pour traiter les différents types de données non structurées, d'autres types de bases de données sont disponibles. Les bases de données dites nosql (acronyme de « Not only SQL ») sont capables de traiter de grandes quantités de données complexes et non structurées. Parmi les exemples de bases de données nosql, on peut citer MongoDB, Neo4j et Cassandra.
Développez vos compétences en nosql
Les bases de données nosql sont à la pointe de l'innovation dans le domaine de la science des données. Initiez-vous à cette technologie très demandée grâce à notre cours sur les concepts nosql.
Une partie essentielle du travail d'un data scientist consiste à communiquer les résultats de l'analyse des données. Ce n'est que si les décideurs et les parties prenantes comprennent les conclusions de l'analyse des données que celles-ci peuvent être transformées en actions. L'une des techniques les plus efficaces pour atteindre cet objectif consiste à recourir à la visualisation des données.
La visualisation des données implique l'utilisation de représentations graphiques des données, telles que des graphiques, des tableaux et des cartes. Ces représentations permettent aux scientifiques des données de résumer des milliers de lignes et de colonnes de données complexes, et de les présenter dans un format compréhensible et accessible.
Le sous-domaine de la visualisation des données évolue rapidement, grâce aux contributions importantes de disciplines telles que la psychologie et les neurosciences, qui aident les scientifiques des données à identifier la meilleure façon de communiquer des informations par le biais de supports visuels.
Il existe de nombreux outils permettant de créer des visualisations attrayantes, notamment les bibliothèques Python telles que matplotlib, les bibliothèques R telles que ggplot2 et les logiciels de veille stratégique populaires tels que Tableau et Power BI.
Développez vos compétences en visualisation de données
Veuillez suivre une introduction sans code à la visualisation des données ou explorer la gamme complète de cours sur la visualisation des données proposés par DataCamp. De Plotly à Power BI, vous trouverez des cours couvrant vos outils et technologies préférés.
L'apprentissage automatique et l'intelligence artificielle sont parmi les sujets les plus pertinents dans le domaine de la science des données. L'apprentissage automatique est une branche de l'intelligence artificielle qui se concentre sur le développement d'algorithmes capables d'apprendre à effectuer des tâches sans avoir été explicitement programmés.
Des recommandations Netflix aux filtres Instagram, l'apprentissage automatique est intégré dans votre quotidien. L'utilisation croissante des systèmes d'apprentissage automatique entraîne une demande accrue de scientifiques des données possédant des compétences en apprentissage automatique. Les statistiques de 2020 indiquent que 82 % des entreprises recherchaient des personnes possédant des compétences en apprentissage automatique, tandis que seulement 12 % estimaient que l'offre de professionnels dans ce domaine était suffisante.
Développez vos compétences en apprentissage automatique et en intelligence artificielle
Familiarisez-vous avec les principes fondamentaux grâce à notre cours Comprendre l'apprentissage automatique ou découvrez comment cette technologie est utilisée pour améliorer les activités commerciales dans le cours L'apprentissage automatique pour les entreprises. Pour l'intelligence artificielle, veuillez consulter notre cursus de compétences « Principes fondamentaux de l'IA » et notre article sur la manière d'apprendre l'IA à partir de zéro.
Une étape supplémentaire pour les praticiens du machine learning est le deep learning. L'apprentissage profond est un sous-domaine de l'apprentissage automatique qui se concentre sur des algorithmes puissants, appelés réseaux neuronaux artificiels, inspirés de la structure et du fonctionnement du cerveau humain.
La plupart des progrès réalisés dans le domaine de l'intelligence artificielle au cours des dernières années sont issus de l'apprentissage profond. Les réseaux neuronaux sont à l'origine de certaines des applications les plus révolutionnaires et les plus impressionnantes, notamment les voitures autonomes, les assistants virtuels, la reconnaissance d'images et les robots.
La maîtrise de la théorie et de la pratique des réseaux neuronaux devient rapidement un facteur déterminant lors du recrutement ou de la promotion des scientifiques des données. Cependant, il est juste de dire que l'apprentissage profond est une discipline complexe qui nécessite un niveau avancé en mathématiques et en programmation. C'est pourquoi les professionnels des données spécialisés dans l'apprentissage profond comptent parmi les mieux rémunérés du secteur de la science des données.
Développez vos compétences en apprentissage profond
Commencez votre parcours d'apprentissage en découvrant comment créer des réseaux neuronaux dans certains des frameworks les plus populaires pour le deep learning. Nous vous invitons à essayer nos cours « Introduction au Deep Learning avec Keras » et « Introduction à TensorFlow dans R ».
Les êtres humains communiquent principalement entre eux par le langage et l'écriture. Il n'est donc pas surprenant qu'une grande partie des données que nous collectons se présente sous ce format. Le traitement du langage naturel (NLP) est un sous-domaine de l'intelligence artificielle qui se concentre sur l'extraction d'informations significatives à partir du langage naturel et du texte.
Le NLP est en pleine expansion dans le secteur des données. Les techniques de traitement automatique du langage naturel (TALN) basées sur l'apprentissage automatique et l'apprentissage profond alimentent certaines des applications les plus répandues, telles que les moteurs de recherche, les chatbots et les systèmes de recommandation.
Développez vos compétences en PNL et en apprentissage automatique
Découvrez comment Python peut vous aider à extraire des informations à partir de textes dans le cursus de compétences « Traitement du langage naturel en Python » ou perfectionnez vos compétences en R avec « Introduction au traitement du langage naturel en R ».
Lorsqu'il s'agit de traiter de grandes quantités de données complexes à grande vitesse, il peut s'avérer insuffisant de s'appuyer uniquement sur Python ou R. L'écosystème du Big Data englobe des outils et des technologies en pleine expansion, conçus pour effectuer des analyses de données volumineuses de manière plus rapide, évolutive et fiable. Ces tâches vont des processus ETL et de la gestion des bases de données à l'analyse des données en temps réel et à la planification des tâches.
Développez vos compétences en matière de mégadonnées
Découvrez les principes fondamentaux de la gestion et du traitement distribués des données grâce à notre cursus Big Data avec PySpark, ou apprenez à planifier des workflows de données avec notre cours Introduction à Airflow en Python.
Parallèlement à l'évolution de l'écosystème du Big Data, les services cloud deviennent rapidement une option incontournable pour de nombreuses entreprises qui souhaitent tirer le meilleur parti de leur infrastructure de données.
Le secteur du cloud computing est dominé par les grandes entreprises technologiques, à savoir Amazon Web Services, Microsoft, Azure et Google Cloud. Ces fournisseurs proposent des solutions sur mesure en fonction de la situation du client et de nombreux outils de données qui nous permettent de mener à bien le processus de science des données sans quitter le cloud.
Développez vos compétences en matière d'AWS et de cloud computing
Découvrez les bases grâce à nos cours sans code : Comprendre le cloud computing et les concepts du cloud AWS. Ensuite, découvrez comment optimiser vos flux de travail dans Introduction à AWS Boto en Python.
Bien que les compétences techniques constituent une part importante des aptitudes requises pour devenir data scientist, il existe également des compétences moins tangibles qui vous seront nécessaires pour réussir dans ce secteur.
Les données ne sont rien d'autre que des informations. En tant qu'êtres humains, notre corps recueille constamment des informations par le biais de nos sens. Cependant, pour donner un sens à ces informations, il est nécessaire de comprendre leur signification et leurs implications. Il en va de même pour l'analyse de grandes quantités de données. Pour extraire des informations pertinentes à partir des données, il est nécessaire de commencer par comprendre les données avec lesquelles nous travaillons.
Outre les compétences techniques mentionnées précédemment, les data scientists doivent également posséder une solide compréhension commerciale du secteur ou de l'industrie dans lequel ils travaillent, qu'il s'agisse de la finance, de la santé, du marketing ou autre. Ces connaissances spécifiques au domaine sont essentielles pour donner du sens aux données et réaliser de meilleures analyses.
La science des données ne se limite pas aux mathématiques et à la programmation ; elle consiste également à présenter et à communiquer les conclusions tirées de l'analyse des données. Si les gens ne comprennent pas les résultats d'une analyse, votre travail en tant que scientifique n'aura pas de valeur pour une entreprise.
Pour transformer les données en décisions, les scientifiques des données doivent être capables de communiquer correctement leurs conclusions. De plus, les scientifiques des données devraient être en mesure de présenter les données de manière captivante. Pour ce faire, des approches et des cadres de communication innovants, tels que la narration de données, peuvent faire une grande différence.
La technologie en soi est neutre. Cependant, son utilisation ne l'est pas. Ces dernières années, certaines entreprises axées sur les données ont été mises en avant pour avoir développé des pratiques et des applications susceptibles d'avoir des répercussions négatives sur les individus et la société. Cela a ébranlé la crédibilité et la confiance que les citoyens accordent aux entreprises et, plus largement, à la technologie.
Afin de garantir que les données aient des répercussions positives, les scientifiques des données doivent développer une conscience éthique. Cela implique de se familiariser avec des concepts importants, tels que la confidentialité des données, les biais algorithmiques et les boucles de rétroaction, et de s'efforcer de développer des algorithmes équitables, transparents et responsables. Il pourrait également être utile de vous familiariser avec l'éthique de l'IA, car cela pourrait devenir un enjeu majeur dans les années à venir.
Le monde est confronté à une crise climatique sans précédent. Le changement climatique et la perte rapide de biodiversité compromettent les conditions qui rendent la vie humaine possible. Bien que cela soit souvent négligé, l'industrie numérique, y compris la science des données, doit prendre en compte son impact environnemental.
Le stockage et le traitement de grandes quantités de données ainsi que l'entraînement des algorithmes d'apprentissage automatique nécessitent une quantité d'énergie considérable, ce qui entraîne des émissions supplémentaires de CO2 dans l'atmosphère. Par exemple, en 2019, on estimait que la formation d'un modèle d'apprentissage profond de grande envergure pouvait émettre plus de 626 000 livres d'équivalent dioxyde de carbone, soit près de cinq fois les émissions totales d'une voiture américaine moyenne, y compris celles liées à la fabrication. De plus, les centres de données, où la plupart des données sont stockées et traitées, consomment également beaucoup d'eau pour refroidir les serveurs.
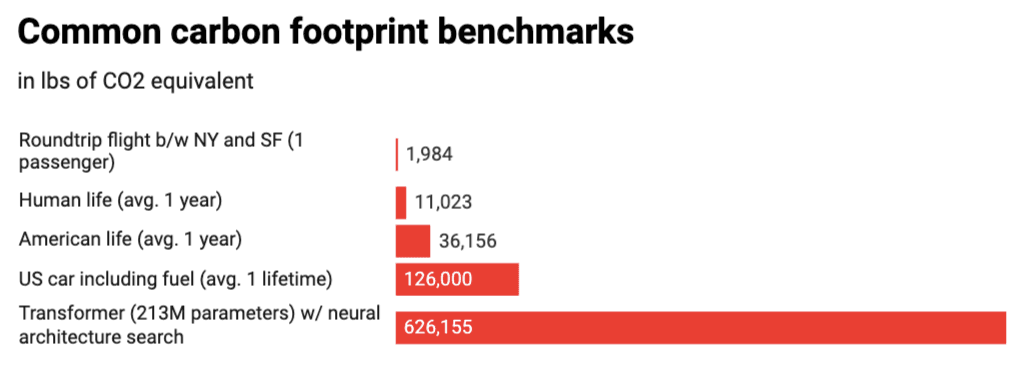
Graphique : MIT Technology Review. Source : Strubell et ses collègues.
Pour faire face à la crise climatique, les scientifiques des données doivent être conscients de l'impact environnemental de leur travail et, plus largement, de l'industrie de la science des données. Cela pourrait contribuer à optimiser et à réduire la consommation d'énergie et à développer des pratiques plus durables.
Cet article traitait des 15 compétences les plus recherchées chez les data scientists. Apprendre toutes ces notions peut s'avérer difficile, voire intimidant, surtout si vous débutez dans le domaine de la science des données. Cependant, il n'y a pas lieu de s'inquiéter. Très peu de scientifiques des données disposent d'une boîte à outils aussi complète.
Il est recommandé de commencer par acquérir certaines compétences de base, notamment en Python, R et/ou SQL, ainsi que quelques notions fondamentales en statistiques, puis de progresser progressivement vers d'autres sujets.
Quelles compétences en science des données devriez-vous acquérir ensuite ? Il n'existe pas de réponse précise à cette question. Votre parcours d'apprentissage dépendra très probablement des exigences de votre poste. Par exemple, si vous optez pour un fournisseur de services cloud, vous devrez probablement acquérir des compétences en matière de cloud computing. D'un autre côté, si votre entreprise se concentre sur l'apprentissage automatique, vous savez déjà ce dont vous avez besoin pour obtenir une promotion.
Enfin, si vous souhaitez simplement améliorer vos compétences, notre conseil est simple : apprenez les compétences qui vous intéressent le plus. Veuillez consulter notre guide sur la manière de devenir data scientist pour obtenir des conseils supplémentaires sur la manière de poursuivre cette carrière passionnante. Commencez dès aujourd'hui à vous former grâce à notre cursus professionnel Data Scientist avec Python.
Développez vos compétences en tant que data scientist
Cours
Cours
Cours