
Programa
Engenheiro associado de IA para cientistas de dados
40 h
After Fable 5 and Mythos 5 were shut down, open-source developers began experimenting with smaller local models trained on high-quality synthetic coding and agentic data. Fable 5-Enhanced Gemma 4 is one example.
It is a Gemma 4 12B fine-tune trained on datasets generated by Fable 5 and Composer 2.5. The goal is to transfer useful coding and agentic behaviors into a smaller model that can run locally.
Its training focuses on practical workflows, such as understanding a task, reading files, using tools, editing code, running commands, and verifying the final result.
In this guide, I will show you how to run the Fable 5-enhanced Gemma 4 model locally on an RTX 5070 Ti using llama.cpp.
We will install llama.cpp, download the GGUF model and MTP draft model, launch an OpenAI-compatible local server, and test it with cURL and the built-in WebUI.
Finally, we will connect the model to Pi Coding Agent and give it a real coding task. The main question is whether this compact 12B model can deliver useful coding-agent behavior and compete with larger local models such as Qwen 3.6 27B or Gemma 4 31B.
Fable 5-Enhanced Gemma 4 is a compact coding and agentic model based on Google’s Gemma 4 12B instruction model. It was created by Yuxin Lu and released in GGUF format for local use with llama.cpp and other compatible tools.
Source: yuxinlu1 (Yuxin Lu)
This guide uses the v2 release. It continues the v1 coding model but adds a stronger focus on agentic technical work.
Instead of only generating code, it is designed to inspect files, reason through problems, use tools, edit code, run commands, and verify the final result.
The original model was fine-tuned on verified Python coding data generated by Composer 2.5 and Fable 5.
The main training set uses Composer 2.5 reasoning traces and code solutions for Python tasks with deterministic tests. Only examples where the generated code passed the tests were retained.
Fable 5 was used for harder tasks where Composer 2.5 failed. It generated a new reasoning process and corrected solutions for these examples, which were also verified through execution before being added to the training data.
For v2, the model adds multi-step terminal and tool-use trajectories. These teach it to follow a read, reason, act, and verify workflow instead of producing one answer and stopping.
After Fable 5 became unavailable, some missing Fable 5-style reasoning traces were rebuilt with Opus 4.8.
--jinja enabled in llama.cpp so the model can use Gemma 4’s intended chat template and tool-call format.In a local tau2-bench telecom comparison, the v2 model reached about 55%, compared with roughly 15% for the base Gemma 4 12B instruction model.
This suggests that the main improvement comes from agentic behavior. The fine-tuned model is better at inspecting a task, taking the next action, using tools, and verifying results instead of stopping after an initial response.
This is the fastest and simplest way to install llama.cpp on a Linux machine. Instead of cloning the repository and compiling it from source, the installer downloads a prebuilt binary and sets it up for you.
Run the following command in your terminal:
curl -LsSf https://llama.app/install.sh | shWithin a few seconds, the installer will download the llama.cpp binary and complete the setup.
Next, add llama.cpp to your PATH so that you can run the llama command from any directory, even after restarting the terminal:
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcFinally, verify that the installation worked:
llama helpYou should now see the available llama.cpp commands.

Next, install the Hugging Face CLI and hf-xet. This lets you download the model files directly from Hugging Face, including repositories that use Xet storage for large files.
pip install -U "huggingface_hub[cli]" hf-xet Create a directory for the model files:
MODEL_DIR="/workspace/Fable5-Gemma4"
mkdir -p "$MODEL_DIR" Enable faster Xet downloads, then download only the files required for this guide:
export HF_XET_HIGH_PERFORMANCE=1
hf download \
yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF \
--include "gemma4-v2-Q4_K_M.gguf" \
--include "MTP/gemma-4-12B-it-MTP-Q8_0.gguf" \
--local-dir "$MODEL_DIR"![]()
This downloads two files:
gemma4-v2-Q4_K_M.gguf, the main Fable 5 Enhanced Gemma 4 model.MTP/gemma-4-12B-it-MTP-Q8_0.gguf, the draft model used later for MTP speculative decoding.The Q4_K_M model is about 7 GB. Download time will depend on your internet connection, but using Xet can improve transfer performance for large model files.
Once the download is complete, your files should be stored here:
/workspace/Fable5-Gemma4Now start the local server with the main model and the MTP draft model:
MODEL_DIR="/workspace/Fable5-Gemma4"
llama serve \
--model "$MODEL_DIR/gemma4-v2-Q4_K_M.gguf" \
--alias Fable5-Gemma4 \
--model-draft "$MODEL_DIR/MTP/gemma-4-12B-it-MTP-Q8_0.gguf" \
--spec-type draft-mtp \
--spec-draft-n-max 2 \
-ngl 99 \
-ngld 99 \
--ctx-size 262144 \
--parallel 1 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--flash-attn on \
--jinja \
--temp 1.0 \
--top-p 0.95 \
--top-k 64 \
--repeat-penalty 1.1 \
--host 0.0.0.0 \
--port 8910
The --model-draft argument loads the MTP draft model.
MTP means Multi Token Prediction. The smaller draft model predicts a few upcoming tokens first, and the main model verifies them in parallel. This can improve generation speed without changing the role of the main model.
--spec-type draft-mtp enables this MTP speculative decoding setup. --spec-draft-n-max 2 lets the draft model propose up to two tokens at a time. Two is a sensible starting point because larger values do not always produce a speed improvement.
-ngl 99 moves the main model to the GPU, while -ngld 99 does the same for the MTP draft model. The value 99 simply means to offload all available layers.
--ctx-size 262144 sets a maximum 256K token context window. This is useful for larger codebases and long terminal sessions, but it also requires more VRAM. --parallel 1 reserves the full context for one active request instead of splitting it across multiple users.
The Q8 KV-cache settings reduce the memory required for the long context window. --flash-attn on helps make attention calculations more efficient, especially with long prompts.
Keep --jinja enabled. It applies the model’s built-in chat template so prompts, reasoning, and tool calls are formatted correctly.
The remaining sampling settings control how the model generates text. --temp 1.0, --top-p 0.95, and --top-k 64 allow varied responses, while --repeat-penalty 1.1 helps reduce repeated text.
Once the server has loaded, open the WebUI:
http://localhost:8910 You can also check GPU use from a second terminal:
nvidia-smi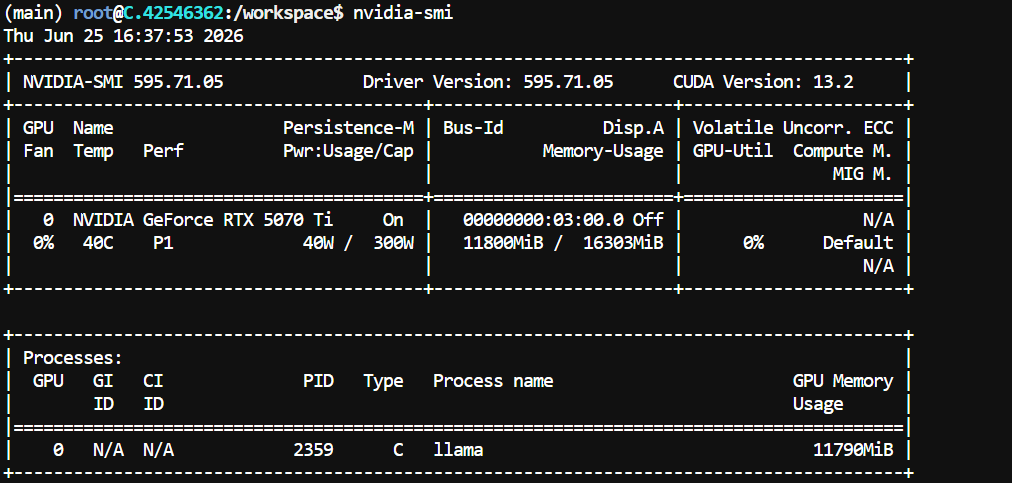
On my RTX 5070 Ti setup, the model used about 11.8 GB of VRAM with the 256K context configuration, leaving more than 4 GB available.
Your memory use may vary depending on the llama.cpp build, GPU driver, and context settings.
Keep the llama serve terminal running, then open a third terminal to test the local API.
curl http://127.0.0.1:8910/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "Fable5-Gemma4",
"max_tokens": 512,
"messages": [
{
"role": "user",
"content": "Create a simple Python script that prints Hello, I am running locally! "
}
]
}'The response should contain the model’s generated text, along with its thinking output. In this test, the model returned the following Python code:
print("Hello, I am running locally!")A JSON response confirms that the local server is working correctly. In my quick test, the model generated at about 54 tokens per second.
You can also use the built-in chat interface. Open the following address in your browser:
http://localhost:8910The WebUI works like a normal chat application. Select the Fable5-Gemma4 model, write a prompt, and send it to the local server.
For a larger coding test, use this prompt:
Create a calming, premium spa treatment center website in one self-contained HTML file
with all CSS and JavaScript included inline, elegant booking CTAs, treatment packages,
therapist profiles, testimonials, and high-quality spa imagery.
For this longer HTML generation task, I saw roughly 66 to 70 tokens per second. Longer coding tasks can sometimes produce better speculative-decoding performance because the model generates a more continuous sequence of predictable code tokens.
The first result below was generated with reasoning set to Medium. It created a clean spa landing page with a minimal layout, navigation links, and a large booking call to action.
The second result was generated without reasoning. It produced a different visual direction, with a larger headline and a more editorial landing-page style.

Both results were visually polished, but the reasoning-enabled version gave a more structured result in this test.
Token speed can vary depending on the prompt length, output style, GPU load, and how often the main model accepts the draft tokens proposed by MTP.
Pi is a lightweight terminal coding agent. It can connect to the local Fable 5-Enhanced Gemma 4 server and use it to read files, edit code, run commands, and complete coding tasks.
Open a fourth terminal and install Pi:
curl -fsSL https://pi.dev/install.sh | sh The installer may ask to install Node.js. Accept the prompt and wait for the installation to finish.
The installer may ask to install Node.js. Accept the prompt and wait for the installation to finish.
Reload your terminal configuration, then confirm that Pi is available:
source ~/.bashrc
pi --versionNext, install the pi-llama plugin:
pi install git:github.com/huggingface/pi-llamaThis plugin connects Pi to a running llama.cpp server and automatically discovers the available local models.
By default, the plugin looks for llama.cpp on port 8080. Our server uses port 8910, so set the correct local API address before starting Pi:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"Create a new project directory, initialize Git, and start Pi:
mkdir -p /workspace/data-app
cd /workspace/data-app
git init
piInside Pi, type:
/modelSelect the “Fable5-Gemma4” model.
Next, give the agent a practical coding task:
Create a simple data analytics dashboard using Streamlit that lets users
upload a CSV file, view the data, and explore clear visualizations.
Include a sample CSV file and test the full app to make sure it works correctly.
The model eventually created a working Streamlit dashboard with CSV upload support and visualizations.
However, the process was far more difficult than expected.
It struggled repeatedly with tool calls, terminal commands, and writing project files.
It often failed to complete the next action after planning what to do, so I had to keep guiding it through errors and retrying commands.
I could not confirm whether this was caused by the model, the Pi integration, local permissions, or a combination of these issues.
After roughly 20 minutes of retries, it produced a working result. For a relatively simple Streamlit task, this felt too slow and unreliable.
The same task took about one minute with GLM 5.2 in my separate test.
It is not entirely fair to compare a 12B local model with a much larger frontier model.
However, the gap was still noticeable.
Fable 5-Enhanced Gemma 4 can produce polished code and strong single-turn outputs, but its real agentic performance was inconsistent in this test. It needed too much intervention for a task that a capable coding agent should complete quickly and independently.
My takeaway is that the model is interesting for local experimentation, private code generation, and lightweight workflows.
But based on this test, I would not rely on it yet for dependable multi-step coding-agent tasks.
While this guide provides a simple way to test the model, you may face issues depending on your hardware, local setup, and llama.cpp build.
If the server crashes while loading the MTP draft model and shows an error such as:
invalid vector subscriptThe issue may be your llama.cpp build rather than the model files.
The model repository reports that llama.cpp build b9553 works with the Gemma 4 MTP draft model, while newer builds such as b9702 and b9717 can fail during draft-model loading.
As a quick fallback, remove the MTP arguments from the server command and run only the main model. The model will still work correctly, but generation may be slower.
Remove these lines:
--model-draft "$MODEL_DIR/MTP/gemma-4-12B-it-MTP-Q8_0.gguf"
--spec-type draft-mtp
--spec-draft-n-max 2
-ngld 99If you see tokens such as <|tool_call> or <|channel> in the response, the client is not applying Gemma 4's native tool-call format correctly.
Make sure your server command includes:
--jinjaThen restart the server. This applies the correct chat template for the model's reasoning and structured tool calls.
First, check that the llama.cpp server is still running:
curl http://127.0.0.1:8910/v1/modelsYou should see Fable5-Gemma4 in the response.
Next, make sure Pi is pointed to port 8910 rather than the default llama.cpp port 8080:
export LLAMA_BASE_URL="http://127.0.0.1:8910/v1"
piRun both commands in the same terminal session.
Start Pi inside a writable project directory:
cd /workspace/data-app
piYou can test whether the current directory allows file creation:
touch write-test.txt && rm write-test.txtIf this command fails, the issue is a workspace permission problem rather than the model itself. Move to a writable directory before launching Pi.
If the model starts repeating text, numbers, or symbols, check the sampling settings in your server command.
Use these values:
--temp 1.0 \
--top-p 0.95 \
--top-k 64 \
--repeat-penalty 1.1The repetition penalty is particularly important. Without it, the model can produce repeated or garbled output.
A 256K context window requires a large KV cache. If the server runs out of VRAM, reduce the context size first:
--ctx-size 32768You can also disable the MTP draft model to free more VRAM. Check your current GPU memory usage with:
nvidia-smiThe model can generate strong code, but it may still struggle to complete longer tasks without intervention. In my testing, it sometimes planned the correct actions but failed while running commands, writing files, or continuing after an error.
For better results, split large requests into smaller tasks:
This gives the model a smaller goal at each step and makes it easier to identify whether a failure comes from the model, Pi, the server, or workspace permissions.
I do not think the hype around this model is fully justified, at least based on my testing. With and without MTP, I was getting almost the same speed for general tasks. During coding tasks, MTP did help, and I saw around a 20% to 30% speed boost. That is useful, but it does not fix the bigger problem: reliability.
I also tested the model in the WebUI.
Sometimes, while writing code for a file, it would just stop for no clear reason. When I asked it to continue, it wrote the continuation as text in the next chat response instead of actually continuing the file.
I also noticed that enabling thinking sometimes made the output worse, which was surprising.
I tested it with Claude Code, too, and that experience was even more frustrating.
The model kept creating extra files, temporary files, and other irrelevant things that a simple project did not need. It eventually completed the task, but it took far too much guidance and too much time.
I know comparing a 12B local model with GPT-5.5 or GLM 5.2 is not completely fair. But even compared with smaller local models, I was not impressed.
In my experience, Qwen3.6 27B is much better for coding and agentic tasks, even though it is larger.
For now, I see this model as an interesting experiment rather than a dependable coding agent.
I am more interested in the upcoming Fable-tuned Qwen3.6 27B model from the same creator. I have also seen several other open-source contributors release similar distilled coding models, but so far, I have not seen a major improvement in real coding-agent tasks.
The model can generate good-looking code and polished single-turn outputs. But when you ask it to work like an agent, use tools, create files, fix errors, and verify the result, it still feels inconsistent and frustrating to use.
Top DataCamp Courses
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
François Aubry
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
