
Programa
Engenheiro de machine learning
44 h
Todo mundo sabe que os Transformers viraram essenciais no processamento de linguagem natural e agora estão ganhando força na visão computacional. Os Vision Transformers (ViTs) oferecem uma nova abordagem para a compreensão de imagens, usando os mesmos princípios usados em modelos baseados em texto: os Large Language Models.
Os ViTs foram apresentados pela primeira vez em 2020 pela Google Research no artigo “An Image is Worth 16×16 Words” (Uma imagem vale 16×16 palavras), mostrando que os transformadores treinados em grandes conjuntos de dados de imagens podem igualar ou superar as CNNs. Desde então, variantes práticas como DeiT e Swin ampliaram seu uso em muitas tarefas de visão.
Neste tutorial, vou te mostrar os conceitos básicos, os componentes arquitetônicos e as aplicações práticas dos transformadores de visão (a versão original). No final, vamos entender não só como os ViTs funcionam, mas também como implementá-los em nossos próprios projetos de visão computacional. Também recomendo dar uma olhada no meu outro guia sobre atenção multi-head.
Vamos começar apresentando os transformadores de visão.
Esses modelos tratam uma imagem como uma sequência de dados, parecido com o jeito que um modelo de linguagem processa palavras em uma frase. Então, a imagem é dividida em partes de tamanho fixo, cada uma delas é achatada e colocada em um vetor.
Esses vetores são então passados por um codificador transformador padrão, que modela as relações entre os patches globalmente usando o mecanismo de atenção.
Isso é bem diferente dasredes neurais convolucionais (CNNs), que se concentram em características locais e dependem da extração hierárquica de características.
Já que estamos falando sobre CNNs, vamos ver quais são as diferenças entre elas e as ViTs:
|
Recurso |
Redes Neurais Convolucionais (CNNs) |
Transformadores de Visão (ViTs) |
|
Arquitetura |
Usa camadas de convolução + pooling |
Usa o Transformer Encoder com Autoatenção |
|
Campo receptivo |
Campo receptivo local, mas que se expande com a profundidade |
Global desde o início |
|
Consciência posicional |
Implícito através da estrutura |
Explícito por meio de codificações posicionais |
|
Requisitos de dados |
Bastante eficaz com conjuntos de dados menores |
Precisa de conjuntos de dados bem grandes |
|
Viés indutivo |
Forte |
Minimalista, mas mais flexível |
|
Potencial de paralelismo |
Moderado |
Muito alto |
|
Escalonamento do modelo |
Menos escalável para modelos grandes |
Altamente escalável |
|
Interpretabilidade |
Através da combinação de camadas, mas ainda assim difícil. |
Pode ser melhorado com visualização da atenção, mas também é bem difícil. |
É claro que ainda não falamos sobre transformadores de visão em detalhes, mas é legal revisar alguns pontos que podem não fazer sentido logo de cara.
Por exemplo, viés indutivo e campos receptivos são termos importantes, mas que talvez você nunca tenha ouvido falar antes.
Viés indutivo são as suposições que um modelo faz para ajudar a aprender com os dados. Isso parece bem confuso, mas deve fazer sentido depois de ler essa analogia.
Imagina que estamos montando um quebra-cabeça juntos. Podemos pensar que as peças se encaixam com base na forma e na cor. Essa suposição nos ajuda a juntar as peças mais rápido. É assim que funciona um modelo CNN.
Ele faz suposições inteligentes, achando que as partes próximas em uma imagem estão relacionadas, tipo como as peças de um quebra-cabeça próximas umas das outras geralmente pertencem à mesma parte da imagem. Também assume que, se mudarmos uma forma de lugar, ela continua sendo a mesma forma. Essas suposições úteis são chamadas de fortes vieses indutivos.
Agora imagina que nos deram uma grande pilha de peças de quebra-cabeça, mas não fazemos ideia de como será a imagem final. A gente nem sabe se deve olhar para a forma, a cor ou talvez algo completamente diferente. Então começamos a tentar tudo e, aos poucos, descobrimos o que funciona.
É isso que um modelo Transformer faz. Não faz suposições fortes. Ele aprende padrões analisando muitos dados. Isso é chamado de viés indutivo mínimo. Isso dá mais liberdade ao modelo, mas precisa de mais dados e tempo para aprender.

A imagem acima agora mostra como o campo receptivo de um modelo CNN muda. Lembre-se de que há várias camadas convolucionais em uma CNN e, à medida que nos aprofundamos na rede, os neurônios de cada camada são influenciados por uma região cada vez maior da entrada.
Esse campo receptivo em expansão campo receptivo permite que camadas mais profundas detectem características mais complexas e globais, como mostrado na figura acima (da orelha ao rosto e ao cão inteiro).
Isso é bem diferente do campo receptivo de um Vision Transformer:
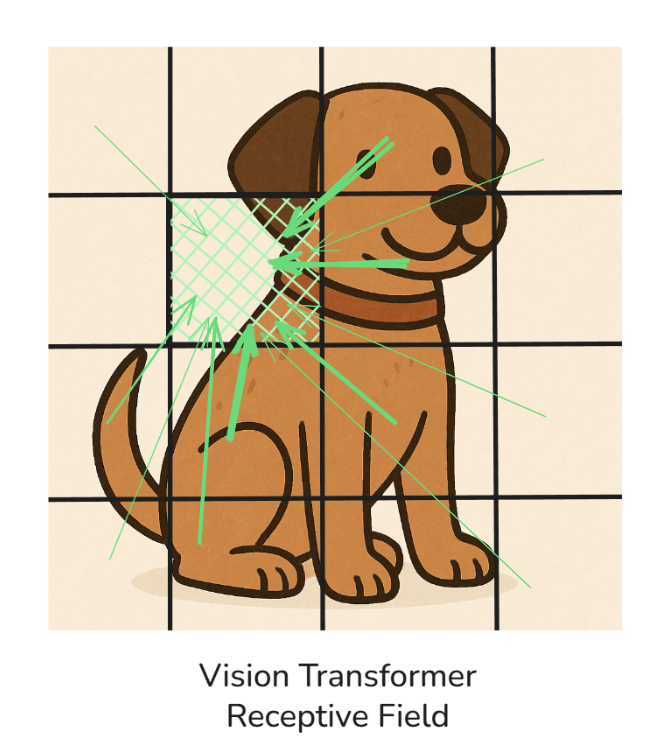
Na ilustração acima, dá pra ver que o campo receptivo em um ViT (vanilla) é global, então todos os patches se relacionam entre si em diferentes magnitudes (mostradas pela espessura das setas).
Para simplificar, mostrei que o patch (colorido em verde) está sendo atendido pelas outras manchas, mas, na verdade, todas as manchas se atendem mutuamente (teria ficado muito confuso desenhar isso!).
Entender quando usar uma CNN em vez de um transformador de visão é bem importante pra fazer escolhas arquitetônicas eficazes em nossos fluxos de trabalho de visão computacional.
Os dois modelos têm seus pontos fortes (e fracos!), mas funcionam melhor em condições diferentes, dependendo do tamanho dos dados. tamanho dos dados, recursos computacionais e da complexidade dos padrões visuais que estamos tentando modelar.
Gosto de pensar nesses pontos quando estou tentando escolher entre eles:
Você deve usar CNNs quando:
Você deve usar Vision Transformers quando:
Resumindo, se você se encontrar em um ambiente com poucos recursos ou precisar de resultados rápidos e confiáveis com dados limitados, as CNNs são a escolha mais segura e eficiente.
Por outro lado, se o seu projeto precisa de um raciocínio global profundo em todo o espaço visual e você tiver o poder de computação para sustentá-lo, os transformadores de visão são a melhor opção.
Vamos agora mergulhar na arquitetura real do Vision Transformer. Como tem várias etapas (cinco, pra ser mais exato), vamos ver cada uma delas.
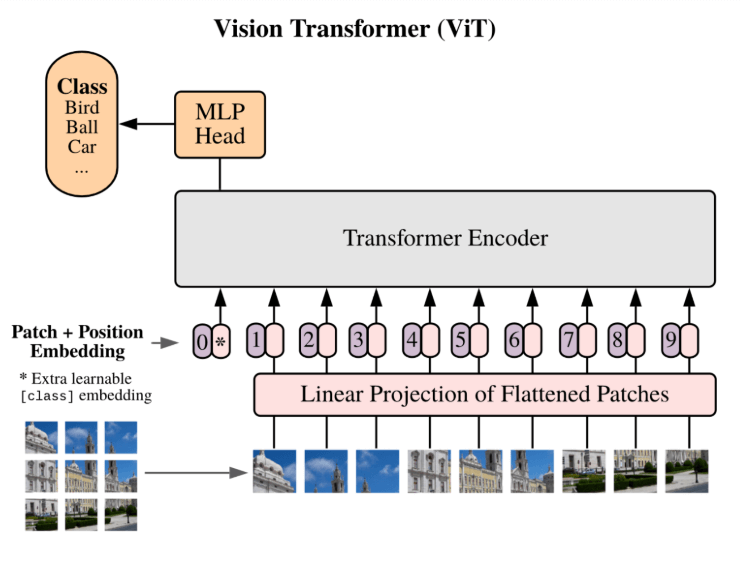
Essa é a primeira etapa da transformação, onde a gente precisa converter uma imagem pra um formato que o transformador consiga entender.
Digamos que temos uma imagem de 224x224. Em vez de alimentá-lo inteiro, a gente divide em pedaços menores e de tamanho fixo. Se cada patch tiver 16x16 (como proposto no artigo original), a imagem será dividida em 14×14 = 196 patches, já que (224/16 =14).
Uma maneira bem fácil de entender isso é pensar em cortar uma foto em quadrados perfeitamente iguais. Cada patch tem informações específicas e funciona como uma “palavra” numa frase.

Na ilustração acima, dá pra ver que a imagem de um lobo é dividida em quadrados menores (e iguais) — 196, pra ser exato.
Você pode ter uma dúvida aqui, no entanto:
A imagem é RGB, então o que rola com os três canais de cor?”
É importante notar que cada patch é, na verdade, um bloco de dados que, no nosso caso, tem a forma de 16x16x3. 16x16 é a altura e a largura, e 3 são os canais de cor, tornando cada patch um tensor tridimensional.
Isso faz com que cada patch seja uma representação compacta tanto do espacial e informação de uma região local da imagem.
Essa divisão em manchas transforma a estrutura espacial 2D da imagem em uma sequência 1D de dados multidimensionais, adequada para um modelo transformador.
Depois, precisamos transformar cada trecho da imagem em uma representação numérica que o transformador possa usar.
Cada patch RGB 16x16 é achatado em um único vetor. No nosso exemplo, 16×16×3 = 768 valores. Basicamente, estamos transformando todos os valores de pixels e cores em uma única linha de números.
Esses vetores brutos, embora informativos, ainda não estão em um espaço adequado para o aprendizado. Então, a gente passa cada um por uma camada de projeção linear treinável. Pense nisso como uma camada densa que mapeia cada entrada de 768 dimensões em um novo espaço de incorporação de tamanho D (muitas vezes também 768, mas nem sempre).
Por quê?
Essa projeção é importante porque alinha todos os tokens de patch em um formato consistente e aprendível que o codificador transformador espera. Até agora, a gente teve uma sequência de vetores de comprimento fixo, onde cada vetor representa um pedaço da imagem.
Todo esse processo transforma trechos espaciais e ricos em cores em uma sequência unificada de “tokens” (semelhante a embeddings de palavras em NLP), permitindo que o transformador trate a imagem como uma série estruturada de entidades aprendíveis.
Tem mais uma coisa a fazer antes de mandarmos esses tokens pro nosso codificador. Você já deve ter percebido isso se já falou sobre LLMs antes!
Os transformadores são, por natureza, independentes da posição..
Isso quer dizer que eles tratam sequências de entradas como coleções sem ordem, ou seja, não têm um mecanismo embutido para entender a ordem ou posição dos tokens. E isso é um problema bem grande na análise de imagens, onde tanto a estrutura espacial quanto o layout são essenciais!
Vamos falar sobre isso em detalhes.
No contexto das imagens, cada patch representa uma região específica da imagem original. Se a gente alimentar o modelo com uma sequência de incorporações de patches sem dizer de onde cada patch veio, ele não vai saber se um patch veio do canto superior esquerdo ou do canto inferior direito.
Essa falta de consciência espacial limitaria a capacidade do nosso modelo de entender padrões, formas, estruturas, etc.
Para resolver isso, adicionamos algo chamado codificação posicional a cada incorporação de patch. É um vetor que funciona como uma marca espacial; um vetor que codifica a posição original do patch dentro da imagem. Esses vetores posicionais são adicionados diretamente às incorporações de patch antes que a sequência entre no transformador.
Existem dois tipos comuns de codificações posicionais:
Se você está confuso neste momento, uma maneira muito fácil de entender esse conceito é pensar nas codificações posicionais como coordenadas GPS para os patches.
Eles informam ao transformador a posição original do token. Ao incluir essas informações, permitimos que o mecanismo de autoatenção modele tanto o conteúdo de cada patch quanto sua posição relativa ou absoluta dentro da imagem.
Essa etapa é super importante — sem ela, o Vision Transformer não conseguiria reconstruir a estrutura de uma imagem, por mais poderoso que fosse o mecanismo de atenção.
Agora chegamos ao ponto em que todo o aprendizado profundo acontece — descoberta de padrões, modelagem de contexto e fusão de recursos.
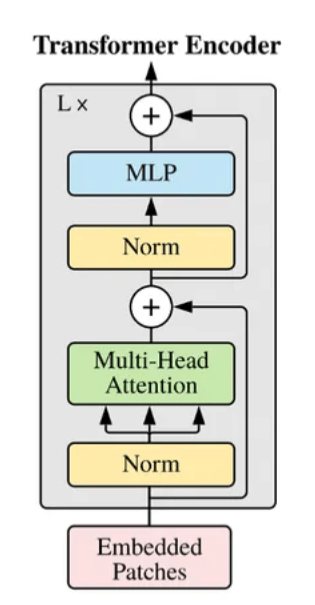
Agora, tem vários desses blocos Encoder empilhados uns sobre os outros para formar o Vision Transformer Encoder completo. Vamos ver o que cada bloco do codificador tem:
No geral, esses blocos de codificadores são empilhados em camadas (por exemplo, 12 no ViT-Base), onde, a cada camada, aprendem representações de imagem mais profundas.
Estamos quase lá! Agora vamos passar para a última e definitiva etapa do ViT (vanilla).
Depois de todas as camadas do codificador, precisamos de uma maneira de resumir tudo e fazer uma previsão.
Então, a gente coloca um token especial [CLS] no começo da sequência de patches. É uma incorporação que dá pra aprender e que interage com todos os outros tokens durante a codificação.
À medida que passa pelas camadas do transformador, ele coleta informações globais. No final, a gente pega esse token e passa por outro perceptron multicamadas (MLP), que geralmente é um par de camadas densas seguidas por um softmax (para classificação).
Essa etapa final nos dá o rótulo previsto, como dizer “essa imagem é um cachorro” com base nas informações coletadas pelo token [CLS]. É super importante notar que é só o [token CLS] que vai para esse MLP Head final e, por isso, é usado para classificação, e não os outros tokens!
Vamos agora dar uma olhada em algumas arquiteturas revolucionárias do Vision Transformer.
Agora, na maioria das vezes, não vamos treinar um ViT do zero! Então, vamos ver como podemos usar modelos ViT pré-treinados de bibliotecas populares de deep learning.
Uma das maneiras mais fáceis e confiáveis de usar transformadores de visão é através da biblioteca Hugging Face Transformers. Ele oferece modelos ViT pré-treinados que estão prontos para usar com só algumas linhas de código.
Escrevi um código aqui para baixar e usar o modelo ViT Base original:
# Imports neededfrom transformers import ViTImageProcessor, ViTForImageClassificationfrom PIL import Imageimport torchimport requests# Here I am loading and preprocessing an image - but you can use any image of your choiceimage = Image.open(requests.get(https://huggingface.co/datasets/huggingface/cats-image?image-viewer=ED6CB286C90CF5F1FAF278077DF091477DF05416', stream=True).raw)# Here, we load and process the ViT modelprocessor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')# Preprocessing the image so it gets it into the necessary formatinputs = processor(images=image, return_tensors='pt')# Forward pass - with no backpropagationwith torch.no_grad(): outputs = model(**inputs)# Here we get the predicted labels (since we are performing classification)logits = outputs.logits predicted_class = logits.argmax(-1) # Selects the index of the class with the highest logit score (highest predicted probability)print(f"Predicted class index: {predicted_class.item()}")Vamos falar sobre esse código com mais detalhes. Primeiro, você pode estar se perguntando por que precisa baixar dois componentes separados. São coisas diferentes, mas se complementam:
ViTImageProcessor – Isso é o que faz o pré-processamento da imagem antes de ela ir para o modelo. Ele cuida do redimensionamento, da normalização e da conversão da imagem para o formato que o transformador de visão espera. A melhor maneira de pensar nisso é como o equivalente visual de um tokenizador em NLP!ViTForImageClassification – Esse é o modelo real que faz a inferência. Ele espera entradas em um formato tensor específico e gera previsões (por exemplo, logits ou probabilidades de classe).Outra dúvida que você pode ter é sobreoutput.logits e, mais especificamente, sobre o que são logits.
Nos modelos de machine learning — principalmente nos modelos de classificação — os logits são os valores brutos produzidos pela camada final do modelo antes de aplicar qualquer função de ativação, como o softmax. Representam pontuações não normalizadas para cada classe.
Uma boa maneira de pensar sobre eles é como os níveis de confiança internos do modelo para cada classe. Esses valores podem ser positivos ou negativos e não precisam somar um.
Para transformar logits em probabilidades, a gente tem que usar o função softmax , que transforma os valores numa distribuição de probabilidade.
Então, quando usamos argmax(logits, -1), estamos só escolhendo o índice (classe) com a maior pontuação bruta, que geralmente é igual àquela com a maior probabilidade depois do softmax.
Outra biblioteca incrível e famosa para usar transformadores de visão étimm(por Ross Wightman). Ele também oferece várias variantes pré-treinadas do ViT e é ótimo pra fazer experimentos rápidos ou ajustes finos. Veja como podemos carregar e usar um modelo ViT para inferência:
# Relevant importsimport timmimport torchfrom torchvision import transformsfrom PIL import Imageimport requests# Loading an imageurl = 'https://huggingface.co/datasets/huggingface/cats-image?image-viewer=ED6CB286C90CF5F1FAF278077DF091477DF05416'image = Image.open(requests.get(url, stream=True).raw)# Here we have defined the transformation we are going to do on the imagetransform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])image_tensor = transform(image).unsqueeze(0) # Adding batch dimension# Loading the ViT modelmodel = timm.create_model('vit_base_patch16_224', pretrained=True)model.eval() # Setting it to evaluation mode# Inference componentwith torch.no_grad(): outputs = model(image_tensor) predicted_class = outputs.argmax(dim=1) # Obtaining the class with the highest probabilityprint(f"Predicted class index: {predicted_class.item()}")Agora você deve conseguir ver a semelhança entre atransformersbibliotecatimm e a biblioteca. Ambos oferecem modelos ViT pré-treinados, permitem o processamento de imagens (emboratimmtenhamos usado o código PyTorch padrão) e, no final, a gente consegue a classe com o logit mais alto.
No geral, os transformadores de visão mudaram a visão computacional, transformando imagens em “frases” de patches e usando a autoatenção para capturar o contexto global desde a primeira camada. Neste tutorial, a gente aprendeu sobre:
Para continuar aprendendo, recomendo que você dê uma olhada neste artigo sobre Como funcionam os transformadores, que vai te ensinar sobre a teoria por trás dos transformadores. Para consolidar isso, recomendo explorar como construir um transformador do zero.
Se você quer aprender os dois ao mesmo tempo enquanto coloca a mão na massa, então nosso curso sobre Modelos Transformadores com PyTorch é o lugar certo pra você.
Cursos mais populares do DataCamp
Programa
Programa
Curso