
Lernpfad
Wissenschaftler für maschinelles Lernen in Python
85 Std.
NVIDIAs cuML ist eine GPU-beschleunigte Bibliothek für maschinelles Lernen, die Teil des RAPIDS AI Ökosystems ist. Und jetzt, in der offenen Beta-Version, ermöglicht cuML 25.02 die GPU-Beschleunigung in scikit-learn, UMAP und HDBSCAN, ohne dass du deinen Python-Code ändern musst. Das ist eine sehr interessante Neuigkeit für Python-Ingenieure für maschinelles Lernen, Daten- und Forschungswissenschaftler, Entwickler und viele andere Fachleute, die sich auf eine Leistungssteigerung ihrer Modelle freuen.
Mach dir keine Sorgen, wenn du dich mit cuML oder der Idee der GPU-Beschleunigung noch nicht so gut auskennst. Am Ende dieses Artikels wirst du in der Lage sein, die GPU-Beschleunigung für deine Regressions-, Klassifizierungs-, Dimensionalitätsreduktions- oder Clustering-Probleme zu nutzen.
Nehmen wir uns einen kurzen Moment Zeit, um alle Teile an den richtigen Platz zu bringen.
NVIDIA entwickelt Spitzentechnologien, die High-Performance-Computing, KI und Data Science ermöglichen. Du erinnerst dich vielleicht daran, dass Deepseek viel in den Nachrichten war, als Deepseek den Deepseek-R1 einstellte und die Leute fragten, ob Deepseek NVIDIA-Chips verwendet.
Nun, NVIDIA ist wieder in den Schlagzeilen, dieses Mal wegen der Innovationen in seinem RAPIDS KI-Ökosystem. RAPIDS AI ist eine Open-Source-Suite von GPU-beschleunigten Bibliotheken zur Beschleunigung von Data Science- und Machine Learning-Workflows. RAPIDS basiert auf CUDA (Compute Unified Device Architecture), einer Plattform für paralleles Rechnen und einem API-Modell, das ebenfalls von NVIDIA entwickelt wurde. Zu den RAPIDS-Bibliotheken mit GPU-Beschleunigung gehören:
Nun zu cuML: cuML bietet hochoptimierte Implementierungen klassischer Algorithmen für maschinelles Lernen. Weil NVIDIA die besten KI-Chips hat, haben diese Algorithmen, die auf NVIDIA-GPUs laufen, einen erheblichen Geschwindigkeitszuwachs. Im Gegensatz zu CPUs können GPUs hervorragend parallel rechnen, was praktisch bedeutet, dass sie Tausende von Berechnungen gleichzeitig durchführen können, was sie ideal für Aufgaben wie (du hast es erraten) Deep Learning und maschinelles Lernen macht.
Wenn du mit scikit-learn noch nicht vertraut bist und dich ernsthaft mit maschinellem Lernen und Data Science beschäftigst, solltest du dich unbedingt für unseren Kurs Supervised Learning with scikit-learn anmelden. Ich sage das, weil scikit-learn die beliebteste Bibliothek für tabellarische Daten in der beliebtesten Programmiersprache für maschinelles Lernen ist. Außerdem ist scikit-learn relativ leicht zu erlernen und hat eine einfache API, und es funktioniert auch gut mit Pandas und NumPy. Es ist daher keine Überraschung, dass sich das RAPIDS-KI-Team auf Scikit-Learn-Algorithmen als strategische und natürliche Wahl konzentriert.
NVIDIA und cuML bieten jetzt die große Innovation für scikit-learn und auch UMAP und HDBSCAN, nämlich einen massiven Geschwindigkeitsschub. Nach Angaben des RAPIDS AI-Teams bedeutet dies eine bis zu 50-fache Geschwindigkeit bei der Verwendung von scikit-learn, 60-fach für UMAP und 175-fach für HDBSCAN.
Ich habe mir ausgerechnet, dass ein Algorithmus, für den Scikit-Learn fünf Minuten braucht, theoretisch in nur sechs Sekunden ausgeführt werden könnte. Das ist ein großer Unterschied. Ich werde mich weiter unten bei den Benchmarks etwas ausführlicher damit befassen.
Wenn das alles kompliziert klingt, mach dir keine Sorgen. RAPIDS AI hat sich verpflichtet, keine Änderungen am API-Code für scikit-learn vorzunehmen. Eigentlich musst du nur die Erweiterung laden, etwa so:
%load_ext cuml.accel
$ python -m cuml.accel script.pyDas ist keine so große Veränderung deines gewohnten Arbeitsablaufs, das ist ja der Sinn der Sache. Es kann vorkommen, dass du den Kernel neu starten und die Erweiterung erneut laden musst.
Dieser Null-Code-Änderungs-Aspekt ist meiner Meinung nach auf den ersten Blick ein wirklich spannender Anspruch. Die Idee dahinter ist, dass du deine bereits erstellten Scikit-Learn-Skripte nicht ändern musst - nicht beim ersten Mal, aber auch nicht immer. cuML würde automatisch kompatible Komponenten auf NVIDIA-GPUs beschleunigen, aber wenn in deinem Code etwas passiert, das nicht mit NVIDIAs GPUs kompatibel ist, fällt dein Skript auf die "normale" CPU-Ausführung zurück. Du als Programmierer siehst nur das Ergebnis und musst dich nicht um die Fehlerbehandlung oder andere Dinge kümmern.
Trotzdem würde ich immer noch mit Randfällen rechnen, die möglicherweise Anpassungen erfordern. Beim Programmieren können Dinge schiefgehen, und nichts ist so einfach, wie es scheint. In der Referenzdokumentation gibt es einige Dinge, die die Behauptung "keine Code-Änderungen" fast widerlegen oder zumindest ein wenig erschweren. Du musst Listen in NumPY-Arrays oder Pandas DataFrames umwandeln, und String-Beschriftungen werden nicht unterstützt, sodass die Benutzer kategorische Beschriftungen vorcodieren müssen. Du machst diese Dinge vielleicht sowieso, aber es gibt noch andere Dinge, an die du dich gewöhnen musst, außer die Erweiterung zu laden.
Wenn du eine einfache lineare Regression mit dem mtcars-Datensatz durchführen würdest, würde es nicht viel nützen, die GPU-Beschleunigung zu nutzen, um die Steigung und den Achsenabschnitt der Linie ein wenig schneller zu finden. Die Einsparung von Sekundenbruchteilen wäre es nicht einmal wert, die Erweiterung zu laden, wirklich. Aber wenn du stattdessen einen komplexeren Algorithmus ausführen würdest, ist die Zeitersparnis aus zwei Gründen wirklich wichtig.
Zum einen ist die Zeit, die du einsparst, für viele Arbeitsabläufe erheblich. Ich habe bereits erwähnt, dass ein 50-facher Geschwindigkeitszuwachs eine Trainingszeit von fünf Minuten hypothetisch auf sechs Sekunden reduzieren würde. Das ist eine Ersparnis von fast fünf Minuten. Aber bedenke den Arbeitsablauf eines Ingenieurs für maschinelles Lernen, der das Modell vielleicht ein paar Mal ausführen muss, um es richtig zu machen. Wenn man von Zeitersparnis bei jedem Durchlauf spricht, bedeutet das, dass man über die Gesamtproduktivität eines Datenwissenschaftlers spricht.
Zweitens, und damit zusammenhängend, könnte der Wissenschaftler oder Ingenieur nun anfangen, komplexere Modelle zu versuchen. Im vorherigen Beispiel gehen wir von einer Zeitgeschwindigkeit für ein Modell aus, das den gleichen Grad an Genauigkeit liefert. Aber was wäre, wenn du glaubst, dass du mit einem komplexeren Modell eine höhere Genauigkeit erzielen würdest? Stell dir vor, du machst eine Rastersuche mit verschiedenen Modellparametern und trainierst ein Modell. (Ich versuche es mit meinem eigenen Mini-Beispiel, weiter unten). Die Permutationen wachsen exponentiell an, was die Rechenkosten auf einer CPU untragbar macht. Aber das ist kein Problem, wenn du einen 50-fachen Geschwindigkeitszuwachs hast.
Diese Vorteile gehören zusammen. Wenn du dein Projekt richtig einrichtest, hast du vielleicht ein genaueres Modell, das auch schneller erstellt wird, oder, wie es ein Ingenieur für maschinelles Lernen ausdrücken könnte, eine ausgefeiltere Modellarchitektur ohne übermäßige Trainingszeiten.
NVIDIA gibt sich Mühe, darüber zu sprechen, wie die GPUs numerisch gleichwertige Ergebnisse liefern würden. Das ist gut zu hören, denn es bedeutet, dass die Vorteile nicht mit Nachteilen in Bezug auf die Modellgenauigkeit einhergehen.
Aber das hat mich auch zum Nachdenken gebracht: Warum sind die Ergebnisse numerisch gleichwertig und nicht identisch? Wahrscheinlich gibt es aufgrund der Parallelverarbeitung kleine Unterschiede in der Ausgabe oder in der numerischen Stabilität einer bestimmten Methode. Im Fall von UMAP ist die UMAP-Projektion vielleicht etwas anders. Ich erwähne das für den Fall, dass du subtile Unterschiede in der Ausgabe zwischen dem CPU- und dem GPU-Lauf feststellen solltest. NVIDIA scheint zu sagen, dass du damit rechnen solltest und dass das normal ist.
Wenn du dich selbst wirklich herausforderst und ein Modell auf GPUs laufen lässt, weil das Modell so komplex ist, dass CPUs praktisch nicht funktionieren, wird es schwierig, die Ergebnisse des Modells mit einem CPU-Äquivalent zu vergleichen.
Ich habe bereits erwähnt, dass es in dieser cuML 25.02 Version nun Unterstützung für scikit-learn, UMAP und HDBSCAN gibt. Aber wenn du mit scikit-learn vertraut bist, weißt du, dass es viele verschiedene Algorithmen in scikit-learn gibt. Derzeit unterstützt RAPIDS AI einige der Bibliotheken, aber nicht alle. Hier sind die wichtigsten Punkte, die das Team genannt hat:
In dieser Liste würde ich mich am meisten über einen Geschwindigkeitsschub bei den k-Nächsten Nachbarn freuen, die bekanntermaßen sehr rechenintensiv sind, weil du die Abstände zwischen allen Datenpunkten berechnen musst.
Die folgende Tabelle zeigt dir die Schätzer, die größtenteils oder vollständig mit cuML ausgeführt werden.
| Algorithmus | Bibliothek / Funktion Name | Kategorie |
|---|---|---|
| UMAP | umap.UMAP |
Dimensionalitätsreduktion |
| PCA (Principal Component Analysis) | sklearn.decomposition.PCA |
Dimensionalitätsreduktion |
| Abgeschnittene SVD | sklearn.decomposition.TruncatedSVD |
Dimensionalitätsreduktion |
| t-SNE | sklearn.manifold.TSNE |
Dimensionalitätsreduktion |
| HDBSCAN | hdbscan.HDBSCAN |
Clustering |
| K-Means | sklearn.cluster.KMeans |
Clustering |
| DBSCAN | sklearn.cluster.DBSCAN |
Clustering |
| Random Forest Klassifikator | sklearn.ensemble.RandomForestClassifier |
Klassifizierung |
| Logistische Regression | sklearn.linear_model.LogisticRegression |
Klassifizierung |
| K-Nächste-Nachbarn-Klassifikator | sklearn.neighbors.KNeighborsClassifier |
Klassifizierung |
| Zufallsforst Regressor | sklearn.ensemble.RandomForestRegressor |
Regression |
| Lineare Regression | sklearn.linear_model.LinearRegression |
Regression |
| Elastisches Netz | sklearn.linear_model.ElasticNet |
Regression |
| Ridge Regression | sklearn.linear_model.Ridge |
Regression |
| Lasso-Regression | sklearn.linear_model.Lasso |
Regression |
| Kernel Ridge Regression | sklearn.kernel_ridge.KernelRidge |
Regression |
| K-Nächste Nachbarn Regressor | sklearn.neighbors.KNeighborsRegressor |
Regression |
| Suche nach den nächstgelegenen Nachbarn | sklearn.neighbors.NearestNeighbors |
Suche nach den nächstgelegenen Nachbarn |
Eine vollständige Liste der unterstützten Methoden findest du in der RAPIDS AI-Dokumentation. Wir erwarten, dass bald weitere Algorithmen hinzugefügt werden. (Du kannst dem Team auch Feedback geben, damit es Prioritäten setzen kann). Einige, die ich vermisse, sind: Support Vector Regressor (sklearn.svm.SVR), Theil-Sen Regressor (sklearn.linear_model.TheilSenRegressor), Mean Shift Clustering (sklearn.cluster.MeanShift) und Multidimensional Scaling (sklearn.manifold.MDS).
Du fragst dich vielleicht, wie das alles funktioniert. Aus 30k Fuß Entfernung solltest du wissen, dass moderne Bibliotheken mehr und mehr so entwickelt werden, dass sie automatisch die beste verfügbare Hardware erkennen und nutzen, egal ob es sich um eine CPU oder eine GPU handelt. Wir sehen jetzt, dass die Software beim Aufruf einer Funktion in scikit-learn (wenn cuml.accel aktiviert ist) prüft, ob ein kompatibler Grafikprozessor verfügbar ist und die Ausführung auf eine GPU-beschleunigte Version umleitet, wenn dies der Fall ist.
RAPIDS AI spricht über diesen Mechanismus, damit cuml.accel wie Sklearn als Kompatibilitätsschicht funktioniert. In diesem Fall ermöglicht die Kompatibilitätsschicht von cuML, dass Scikit-Learn-Code ohne Änderungen auf NVIDIA-GPUs läuft. Es ist als Drop-in-Ersatz gebaut und fungiert als Proxy, der Funktionsaufrufe an scikit-learn abfängt und an cuML weiterleitet.
Das RAPIDS AI Team von NVIDIA stellt eine hilfreiche Grafik zur Verfügung, die ich hier ebenfalls teilen möchte:
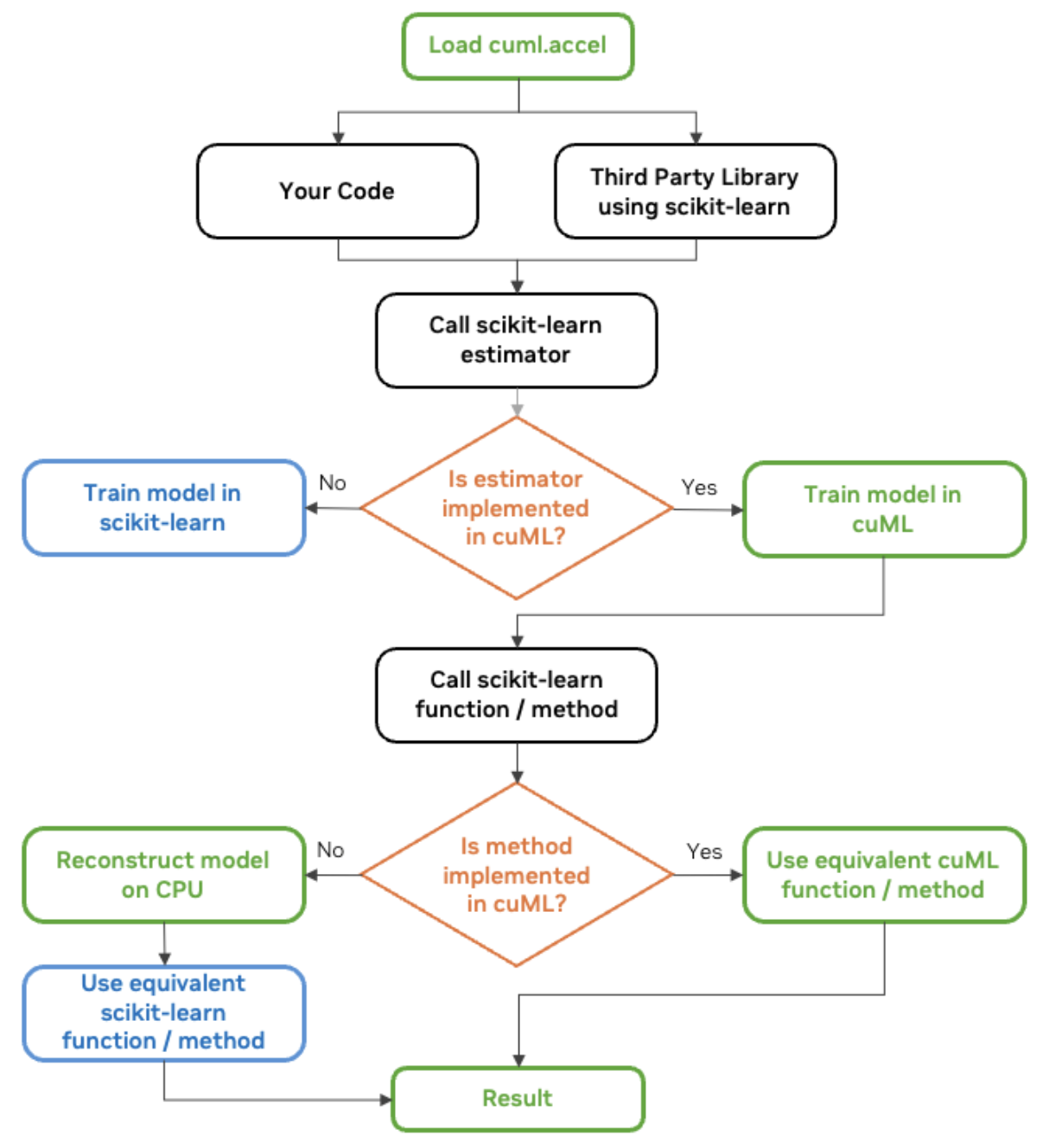
cuML scikit-learn workflow diagram. Quelle: NVIDIA
cuML ist in Google Colab bereits vorinstalliert, aber wenn du ein Jupyter-Notebook verwendest, aktiviere es mit diesem Befehl, bevor du scikit-learn importierst:
%load_ext cuml.accel
import sklearnUnser Python-Code mit Sklearn wird dir bekannt vorkommen, und das ist auch gut so. Hier ist ein Beispiel für eine OLS-Regression.
# Import necessary libraries
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Generate synthetic regression data
X, y = make_regression(n_samples=500000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Create and train an OLS regression model
ols = LinearRegression()
ols.fit(X_train, y_train)Wenn ich sehen möchte, welche Teile auf der GPU statt auf der CPU gelaufen sind, kann ich logger verwenden.
%load_ext cuml.accel
from cuml.common import logger;
logger.set_level(logger.level_enum.debug)cuML: Installed accelerator for sklearn.
cuML: Successfully initialized accelerator.
cuML: Performing fit in GPUDu verstehst schon. Versuchen wir jetzt ein überzeugenderes Beispiel. Die lineare Regression ist ohnehin nicht besonders parallelisierbar, da das Lösen der Normalgleichung oder QR-Zerlegung einige sequenzielle Operationen beinhaltet.
Eine komplexere Erweiterung der OLS-Regression ist die Ridge-Regression. Bei der Ridge-Regression in Python werden durch den Aufruf von Ridge() Standard-Hyperparameter verwendet, die möglicherweise nicht optimal sind. Der Wert alpha legt fest, wie stark die Regularisierung durchgeführt wird. Zu klein und das Modell passt nicht, zu groß und das Modell passt nicht.
%load_ext cuml.accel
import sklearn
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Generate synthetic data
X, y = make_regression(n_samples=100000, n_features=50, noise=0.1, random_state=0)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Train a Ridge Regression model with default settings
ridge_default = Ridge()
ridge_default.fit(X_train, y_train)
# Make predictions and evaluate
y_pred_default = ridge_default.predict(X_test)
mse_default = mean_squared_error(y_test, y_pred_default)
Der obige Code trainiert ein Modell mit einem einzigen Alphawert und Solver. (Ich glaube, die Voreinstellung ist 'auto'.) Das funktioniert zwar, optimiert aber nicht die Stärke der Regularisierung oder die Wahl des Solvers.
Anstatt uns auf die Standardwerte zu verlassen, könnten wir etwas anderes versuchen. Wir könnten eine Rastersuche erstellen, die mehrere Hyperparameterkombinationen testet und die beste auswählt.
from sklearn.model_selection import GridSearchCV
# Define Ridge Regression model
ridge = Ridge()
# Define a grid of hyperparameters to search
param_grid = {
'alpha': [0.01, 0.1, 1.0, 10.0, 100.0], # Different regularization strengths
'solver': ['auto', 'svd', 'cholesky', 'lsqr', 'saga'] # Test multiple solvers
}
# Perform Grid Search with cross-validation
grid_search = GridSearchCV(ridge, param_grid, scoring='neg_mean_squared_error', cv=2, n_jobs=-1)
grid_search.fit(X_train, y_train)
# Get the best model from the search
best_ridge = grid_search.best_estimator_
# Make predictions and evaluate
y_pred_best = best_ridge.predict(X_test)
mse_best = mean_squared_error(y_test, y_pred_best)
Unsere Rastersuche testet hier alle möglichen Kombinationen von Hyperparametern. Wenn wir 5 Werte für Alpha ([0.01, 0.1, 1.0, 10.0, 100.0]), 5 Solver-Optionen (['auto', 'svd', 'cholesky', 'lsqr', 'saga']) festlegen und eine 2-fache Kreuzvalidierung verwenden, beträgt die Gesamtzahl der erforderlichen Modelltrainings 5x5x2, also 50. Das bedeutet, dass wir nicht nur ein Modell trainieren, sondern 50 Modelle. Das ist viel, viel komplexer. Deshalb werden GPUs so toll sein, weil sie viel, viel schneller sind. Da sklearn (bis zu) 50 Mal schneller ist, kann das Training dieser 50 Modelle genauso viel Zeit in Anspruch nehmen wie das Training eines einzigen Modells. (Ich habe diese Zahlen absichtlich gewählt, um diesen Punkt zu verdeutlichen. Mir ist klar, dass nicht alle Modelle den gleichen Geschwindigkeitszuwachs haben werden).
NVIDIA verglich die Leistung von Scikit-Learn-Algorithmen, die auf Intel-CPUs laufen, mit seinen eigenen NVIDIA-GPUs. Sie untersuchten verschiedene Workloads für maschinelles Lernen, darunter Klassifizierung und Regression.
Das Ergebnis ist, dass einfache Modelle wie Random Forests von Minuten Trainingszeit auf CPUs auf Sekunden Trainingszeit auf GPUs gesunken sind und komplexere Modelle wie Clustering von Stunden Trainingszeit auf Minuten gesunken sind. Die Arbeitsabläufe waren in jedem Fall schneller, aber bei den rechenintensiven Modellen mit hochdimensionalen Daten waren die Vorteile noch deutlicher. THier glänzen die GPUs, denn sie nutzen die parallele Verarbeitung und das macht bekanntermaßen einen großen Unterschied bei Modellen, die umfangreiche Matrixoperationen, Abstandsberechnungen oder eine iterative Optimierung erfordern.
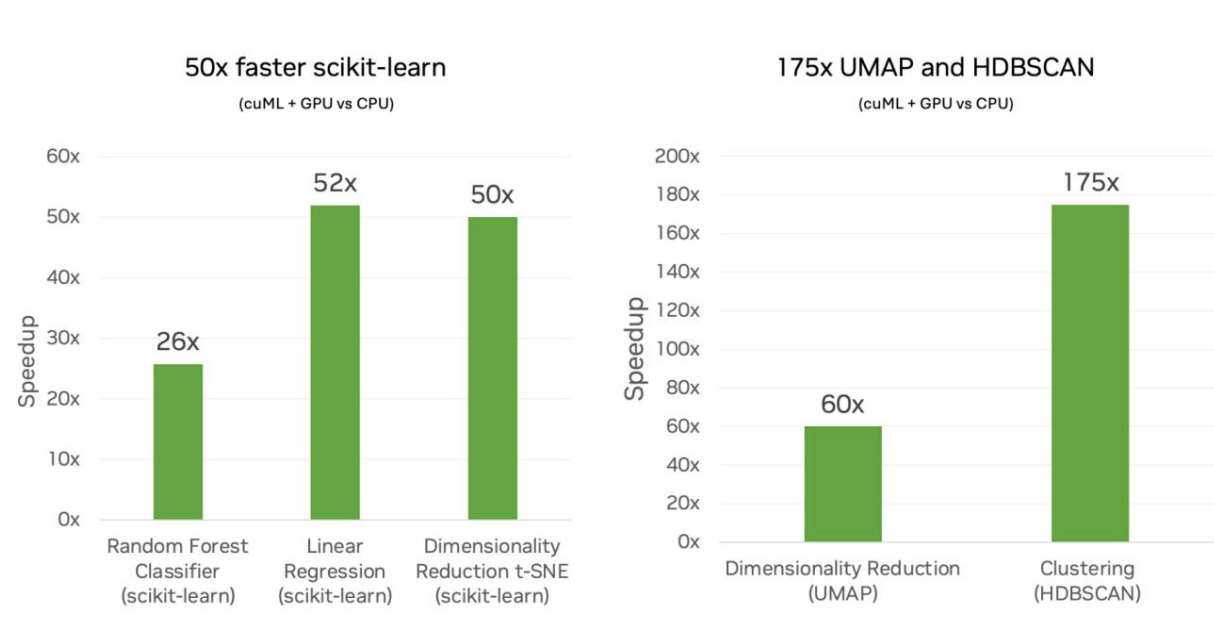
cuML scikit-learn auf GPU vs. scikit-learn auf CPU. Quelle: NVIDIA
Ich habe die lineare Regression in dem früheren Code-Beispiel aufgegeben, weil ich dachte, ich sollte etwas anderes ausprobieren, um die Leistungsfähigkeit zu zeigen. Aber hier sehe ich eine 52-fache Beschleunigung für die lineare Regression. Ich gebe zu, ich bin überrascht, denn das klingt nach einem großen Vielfachen. Das ist eine gute Erinnerung daran, dass NVIDIA auch andere fortschrittliche Dinge tut, wie zum Beispiel dafür zu sorgen, dass verschiedene Schritte verschachtelt werden können, damit die GPU nicht im Leerlauf ist.
Dank cuML Version 25.02ist es jetzt nicht mehr allzu schwierig, einen Scitkit-Lernalgorithmus mit GPUs auszuführen. Du musst nur die Erweiterung laden, wie ich bereits gezeigt habe. Wenn du jedoch tiefer in den Arbeitsablauf einsteigst und das Beste aus der GPU-Beschleunigung herausholen willst, musst du ganz bestimmte Dinge beachten.
NVIDIA empfiehlt, den Datentransfer zwischen den CPUs und GPUs als Teil deiner Pipeline zu minimieren. Mit anderen Worten: Führe die Vorverarbeitungs-, Trainings- und Inferenzschritte in den GPUs durch, bevor du die Ergebnisse zurück in den Hauptspeicher schickst. Vermische die Schritte nicht, indem du die Vorverarbeitung in den CPUs und die Inferenz in den GPUs durchführst.
Um die Effizienz zu maximieren, solltest du auch CUDA-X in Betracht ziehen, eine Sammlung von GPU-beschleunigten Bibliotheken, die von NVIDIA entwickelt wurden. Für Random Forests könntest du z.B. die Forest Inference Library von cuML anstelle der Bibliothek von scikit-learn verwenden.
Die Arbeit des RAPIDS-KI-Teams ist komplex, daher wird es einige Probleme geben. Zum Glück ist die Dokumentation für bekannte Einschränkungen gut geführt. Ich möchte hier nicht unbedingt alle oder auch nur einige der Einschränkungen aufzählen, denn viele der Probleme liegen ziemlich genau im Bereich der spezifischen Algorithmen. Außerdem sind die Updates oder Patches sehr schnell. Stattdessen nenne ich dir die allgemeineren Kategorien von Dingen, die du beachten solltest.
Es gibt einige Einschränkungen, die für alle cuML gelten, nicht nur für bestimmte Algorithmen. Beispiele hierfür sind Einschränkungen bei Dateneingabeformaten (einige Probleme mit Python-Listen), Versionskompatibilität und Speicherbehandlung.
Für einzelne Algorithmen des maschinellen Lernens gibt es einige einzigartige Einschränkungen. Diese Unterschiede können sich darauf auswirken, wie die Modelle trainiert werden, wie sich die Parameter verhalten oder wie die Ergebnisse berechnet werden. Der Random-Forest-Algorithmus in cuML verwendet zum Beispiel eine andere Methode zur Auswahl der Split-Schwellenwerte, was zu leicht unterschiedlichen Baumstrukturen führt.
Es gibt einige Unterschiede bei den Parametern, Solvern und Initialisierungsmethoden, die unterstützt werden. PCA unterstützt zum Beispiel "volle" und "automatische" SVD-Löser, aber keine "randomisierten". Und KNN unterstützt Minkowski-Metriken, aber nicht Mahalanobis.
Es kann vorkommen, dass die Ergebnisse aufgrund von Parallelität oder Unterschieden bei den Solvern leicht abweichen. Ich habe es bereits erwähnt. Die UMAP-Einbettungen können zum Beispiel nicht identisch sein, aber die Vertrauenswürdigkeit sollte trotzdem hoch sein. In anderen Fällen können sich die Vorzeichen der PCA-Komponenten umkehren, was eine Normalisierung erfordert. Auch hier gilt: Wenn du einen bestimmten Algorithmus ausführst, solltest du dich auf die aktuelle Dokumentation beziehen.
Ich bin begeistert von der Aussicht auf eine einfach zu nutzende GPU-Beschleunigung für die bekannten Algorithmen in den gängigsten Python-Bibliotheken für maschinelles Lernen. Das wird einen großen Unterschied in der Modellgenauigkeit machen und ist bequem und nicht schwer umzusetzen.
Bleib auf dem Laufenden über das Neueste im Bereich des maschinellen Lernens. Nimm an unserem Lernpfad für Machine Learning Scientist in Python teil, um dich mit den richtigen Techniken vertraut zu machen. Mach das, damit du die neuesten Fortschritte optimal nutzen kannst. Abonniere auch unseren DataFramed-Podcast. Wir haben sogar eine Folge mit Jean-Francois Puget, Distinguished Engineer bei NVIDIA & Chris Deotte, Senior Data Scientist bei NVIDIA, die unter anderem über die Auswirkungen der GPU-Beschleunigung sprechen.
Lerne Python und scikit-Learn mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
DataCamp Team
Tutorial
Matt Crabtree
Tutorial
Stephen Gruppetta
